在我看來,機器學習即對資料有意義的演算法的應用和科學,是所有計算機科學中最令人興奮的領域!利用機器學習領域的自學演算法,我們可以將這些資料轉化為知識,
在本章中,我們將涵蓋以下主題:
- 機器學習的一般概念
- 三種型別的學習和基本術語
- 成功設計機器學習系統的基石
- 安裝和設定用于資料分析和機器學習的Python
- 構建智能機器,將資料轉化為知識
機器學習的一般概念
在這個現代技術的時代有大量的結構化和非結構化資料,在20世紀下半葉,機器學習作為人工智能(AI)的子領域發展起來,涉及到自學演算法,從資料中得出知識,進行預測,
與其要求人類從分析大量資料中手動推匯出規則并建立模型,機器學習提供了更有效的替代方案,捕捉資料中的知識,逐步提高預測模型的性能,做出資料驅動的決策,
由于機器學習,我們享有強大的電子郵件垃圾郵件過濾器,方便的文本和語音識別軟體,可靠的網路搜索引擎,娛樂性電影的觀看建議,移動支票存款,估計送餐時間,以及更多,希望不久之后,我們將把安全高效的自動駕駛汽車添加到這個串列中,此外,在醫療應用方面也取得了明顯的進展;例如,研究人員證明,深度學習模型可以以接近人類的準確度檢測皮膚癌,另一個里程碑是最近由DeepMind的研究人員取得的,他們使用深度學習來預測三維蛋白質結構,比基于物理學的方法要好得多,研究人員設計了提前四天預測COVID-19患者的氧氣需求的系統,以幫助醫院為需要的人分配資源,我們這個時代的另一個重要話題是氣候變化,它是最大和最關鍵的挑戰之一,研究人員旨在設計基于計算機視覺的機器學習系統,以優化資源配置,盡量減少肥料的使用和浪費,
機器學習的三種不同型別
在本節中,我們將看一下機器學習的三種型別:監督學習、無監督學習和強化學習,我們將了解這三種不同的學習型別之間的根本區別,并利用概念性的例子,對它們可以應用的實際問題領域進行了解:
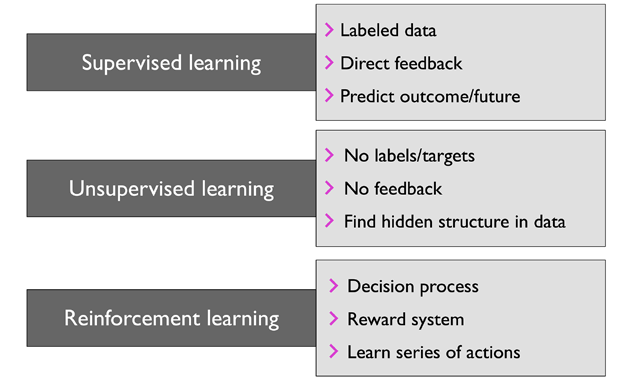
- 用監督學習對未來進行預測
監督學習的主要目標是從標記的訓練資料中學習一個模型,使我們能夠對未見的或未來的資料進行預測,在這里,術語 "監督 "指的是一組訓練實體(資料輸入),其中所需的輸出信號(標簽)已經知道,監督下的學習是對資料輸入和輸出之間的關系進行建模的程序, 因此,我們也可以把監督學習看作是 "標簽學習",
下圖總結了典型的監督學習作業流程:標記的訓練資料被傳遞給機器學習演算法,用于擬合預測模型,該模型可以對新的、未標記的資料輸入進行預測:
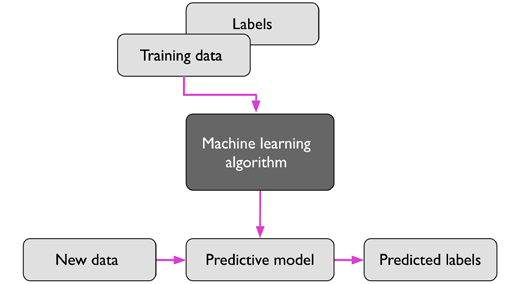
我們可以使用監督機器學習演算法在已標記的郵件語料庫上訓練一個模型,這些郵件被正確地標記為垃圾郵件或非垃圾郵件,以預個新郵件是否屬于這兩個類別,有離散類標簽的監督學習任務,如前面的垃圾郵件過濾例子,也被稱為分類任務,監督學習的另一個子類別是回歸,其中結果信號是一個連續值,
分類是監督學習的子類別,其目標是根據過去的觀察結果來預測新實體或資料點的分類標簽,這些類標簽是離散的、無序的值,可以理解為資料點的組別成員,前面提到的垃圾郵件檢測的例子代表了二元分類任務的典型例子,機器學習演算法學習了一套規則來區分兩個可能的類別:垃圾郵件和非垃圾郵件,
下圖說明了給定30個訓練實體的二元分類任務的概念;15個訓練實體被標記為A類,15個訓練實體被標記為B類,在這種情況下,我們的資料集是二維的,這意味著每個實體有兩個與之相關的值:x1和x2,現在,我們可以使用監督下的機器學習演算法來學習一條規則--用虛線表示的決策邊界--它可以將這兩個類別分開,并將新的資料分類到這兩個類別中,因為它的值是x1和x2,
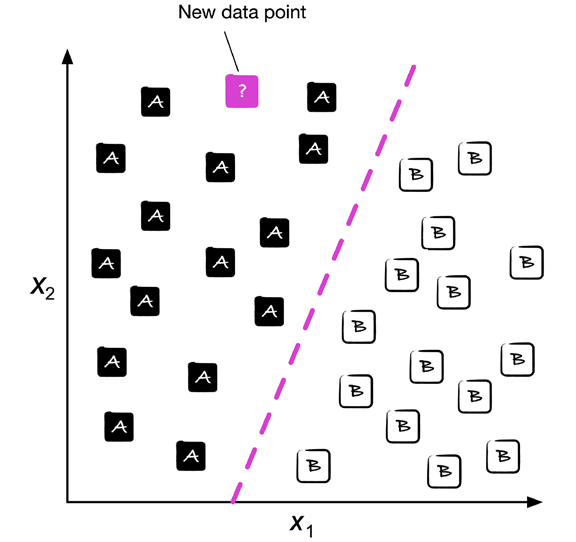
類標簽的集合不一定是二進制性質的,由監督學習演算法學習的預測模型可以將訓練資料集中出現的任何類別標簽分配給新的、未標記的資料點或實體,
多類分類任務的典型例子是手寫字符識別,我們可以收集一個訓練資料集,其中包括字母表中每個字母的多個手寫例子,這些字母("A"、"B"、"C"等)將代表我們想要預測的不同無序類別或類標簽,現在,如果用戶通過輸入設備提供新的手寫字符,我們的預測模型將能夠以一定的準確性預測出字母表中的正確字母,然而,我們的機器學習系統將無法正確識別0到9之間的任何數字,如果它們不是訓練資料集的一部分,
第二種型別的監督學習是預測連續結果,這也被稱為回歸分析,在回歸分析中,我們得到一些預測(解釋)變數和連續的回應變數(結果),我們試圖找到這些變數之間的關系,使我們能夠預測結果,
注意,在機器學習領域,預測變數通常被稱為 "特征",而回應變數通常被稱為 "目標變數",
例如,讓我們假設我們對預測學生的數學SAT分數感興趣,(SAT是美國大學錄取時經常使用的一種標準化考試),如果學習考試的時間和最終的分數之間有關系,我們可以用它作為訓練資料來學習一個模型,用學習時間來預測未來計劃參加這個考試的學生的考試分數,
他觀察到,父母的身高并沒有傳給他們的孩子,相反,他們的孩子的身高會向人群的平均水平倒退,
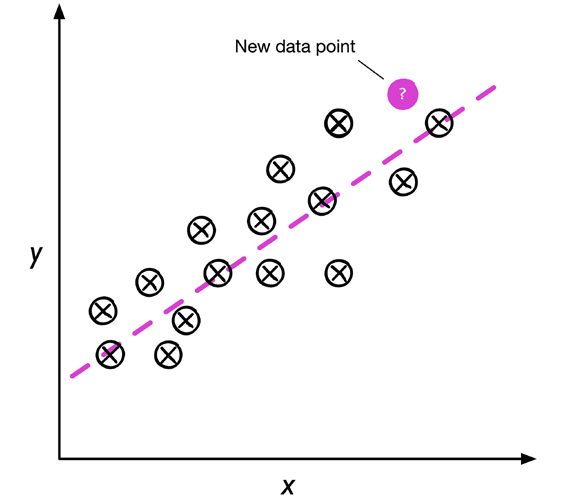
下圖說明了線性回歸的概念,給定特征變數x和目標變數y,我們對這個資料擬合一條直線,使資料點和擬合線之間的距離最小--最常見的是平均平方距離,
- 用強化學習解決互動問題
在強化學習中,目標是開發一個系統(代理),根據與環境的互動作用來提高其性能,由于關于環境當前狀態的資訊通常還包括獎勵信號,我們可以認為強化學習是監督學習有關的領域,然而,在強化學習中,這種反饋不是正確的基礎真理標簽或價值,而是衡量該行動被獎勵函式所衡量的程度,通過與環境的互動,代理可以使用強化學習來學習一系列的行動,通過探索性的試錯方法或深思熟慮的規劃來使這個獎勵最大化,
強化學習的流行的例子是國際象棋程式,在這里,代理人根據棋盤(環境)的狀態來決定一系列的動作,獎勵可以定義為游戲結束時的贏或輸:
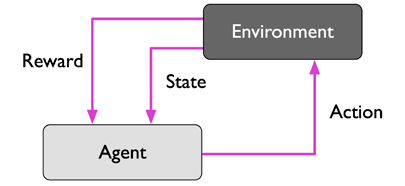
強化學習有許多不同的子型別,然而普遍的方案是,強化學習中的代理人試圖通過與環境的一系列互動來實作獎勵的最大化,每個狀態都可以與正或負的獎勵相關聯,獎勵可以被定義為完成一個總體目標,如贏或輸一盤棋,例如,在國際象棋中,每一步棋的結果可以被認為是環境的不同狀態,
為了進一步探討國際象棋的例子,我們可以認為訪問棋盤上的某些配置與更有可能導致勝利的狀態有關--例如,從棋盤上移走對手的棋子或威脅到皇后,而其他位置則與更有可能導致輸掉比賽的狀態有關,例如在下一回合輸給對手一個棋子,現在,在國際象棋游戲中,獎勵(贏棋的正面獎勵或輸棋的負面獎勵)將在游戲結束時才會給出,此外,最后的獎勵也將取決于對手如何下棋,例如,對手可能會犧牲皇后,但最終贏得比賽,
總之,強化學習關注的是學會選擇一系列行動,使總獎勵最大化,獎勵可以在采取行動后立即獲得,也可以通過延遲的反饋獲得,
- 用無監督學習發現隱藏結構
在監督學習中,當我們訓練一個模型時,我們事先知道正確的答案(標簽或目標變數),而在強化學習中,我們為代理進行的特定行動定義了獎勵的措施,然而,在無監督學習中,我們要處理的是沒有標簽的資料或未知結構的資料,使用無監督學習技術,我們能夠探索資料的結構,在沒有已知的結果變數或獎勵函式的指導下提取有意義的資訊,
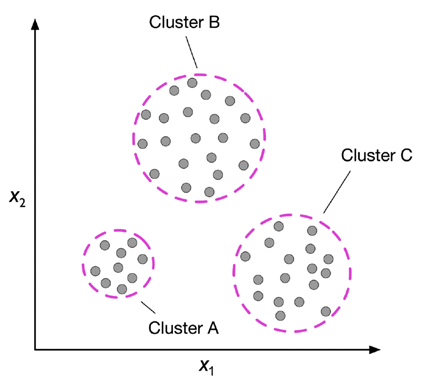
聚類是一種探索性的資料分析或模式發現技術,它允許我們將一堆資訊組織成有意義的子組(聚類),而不需要事先了解它們的組員身份,在分析程序中產生的每個聚類定義了一組具有一定程度相似性的物件,但與其他聚類中的物件更不相似,這就是為什么聚類有時也被稱為無監督分類,聚類是一種構造資訊和從資料中得出有意義關系的偉大技術,例如,它允許營銷人員根據客戶的興趣來發現客戶群,以便制定不同的營銷方案,
下圖說明了聚類是如何應用于將無標簽的資料根據其特征x1和x2的相似性組織成三個不同的群體或聚類(A、B和C,順序任意):
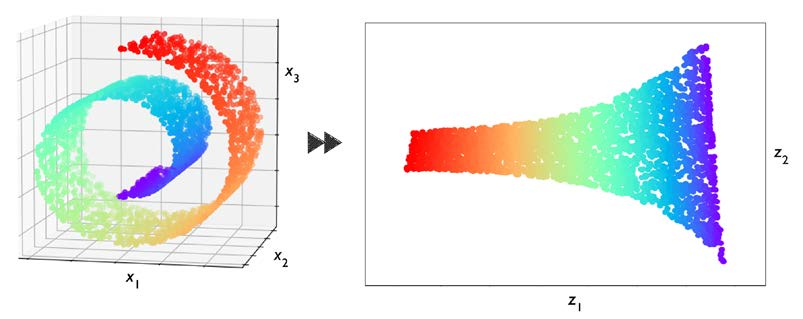
無監督學習的另一個子領域是降維,通常情況下,我們要處理的是高維資料--每個觀察值都有大量的測量值--這對有限的存盤空間和機器學習演算法的計算性能是一個挑戰,無監督的降維是特征預處理中常用的方法,可以去除資料中的噪音,這可能降低某些演算法的預測性能,降維將資料壓縮到較小的維度子空間,同時保留大部分相關資訊,
有時,降維對于資料的可視化也很有用;例如,高維特征集可以被投射到一維、二維或三維特征空間上,通過二維或三維散點圖或直方圖進行可視化,下圖顯示了一個應用非線性降維的例子,將三維瑞士卷壓縮到一個新的二維特征子空間:
基本術語和記號的介紹
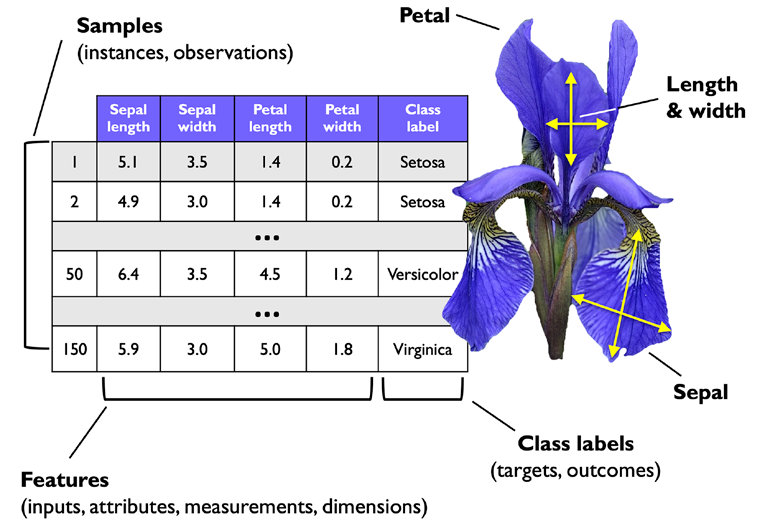
下圖Iris資料集的節選,這是機器學習領域的一個經典案例(更多資訊可以在https://archive.ics.uci.edu/ml/datasets/iris),鳶尾花資料集包含來自三個不同品種的150朵鳶尾花的測量結果--Setosa, Versicolor, 和Virginica,
在這里,每個花的例子代表我們資料集中的一行,以厘米為單位的花的測量值被存盤為列,我們也稱之為資料集的特征:
為了使符號和實作簡單而有效,我們將利用線性代數的一些基礎知識,在下面的章節中,我們將使用矩陣符號來指代我們的資料,我們將遵循常見的慣例,將每個例子表示為特征矩陣X中的一個單獨的行,其中每個特征被存盤為一個單獨的列,
Iris資料集由150個例子和4個特征組成,因此可以寫成150×4的矩陣,形式上表示為 :
我們將使用上標i指代第i個訓練實體,下標j指代訓練資料集的第j個維度,
我們將使用小寫的粗體字來指代向量,大寫的粗體字來指代矩陣,為了指代向量或矩陣中的單個元素,我們將用斜體字寫字母,
例如,指的是花例150的第一個維度,即萼片長度,矩陣X中的每一行代表一個花的實體,可以寫成一個四維行向量, :
而每個特征維度是一個150維的列向量, ,舉例來說:
同樣,我們可以把目標變數(這里是指類標簽)表示為150維的列向量:
機器學習是一個龐大的領域,也是非常跨學科的領域,因為它匯集了許多來自其他研究領域的科學家,恰好,許多術語和概念被重新發現或重新定義,可能已經為你所熟悉,但以不同的名稱出現,為了方便起見,在下面的串列中,你可以找到一些常用的術語和它們的同義詞,你在閱讀本書和一般的機器學習文獻時可能會發現它們很有用:
訓練實體: 表中代表資料集的一行,與觀察、記錄、實體或樣本同義(在大多數情況下,樣本是指訓練實體的集合),
訓練: 模型擬合,對于引數模型類似于引數估計,
特征,縮寫為x: 資料表或資料(設計)矩陣中的一列,與預測器、變數、輸入、屬性或協變數同義,
目標,縮寫為y: 與結果、輸出、回應變數、因果變數、(類)標簽和基本事實同義,
損失函式: 通常與成本函式同義使用,有時損失函式也被稱為誤差函式,在一些文獻中,"損失 "一詞指的是針對單個資料點測量的損失,而成本是計算整個資料集的損失(平均或加總)的測量,
構建機器學習系統的路線圖
在前面的章節中,我們討論了機器學習的基本概念和三種不同的學習型別,在本節中,我們將討論機器學習系統中伴隨著學習演算法的其他重要部分,
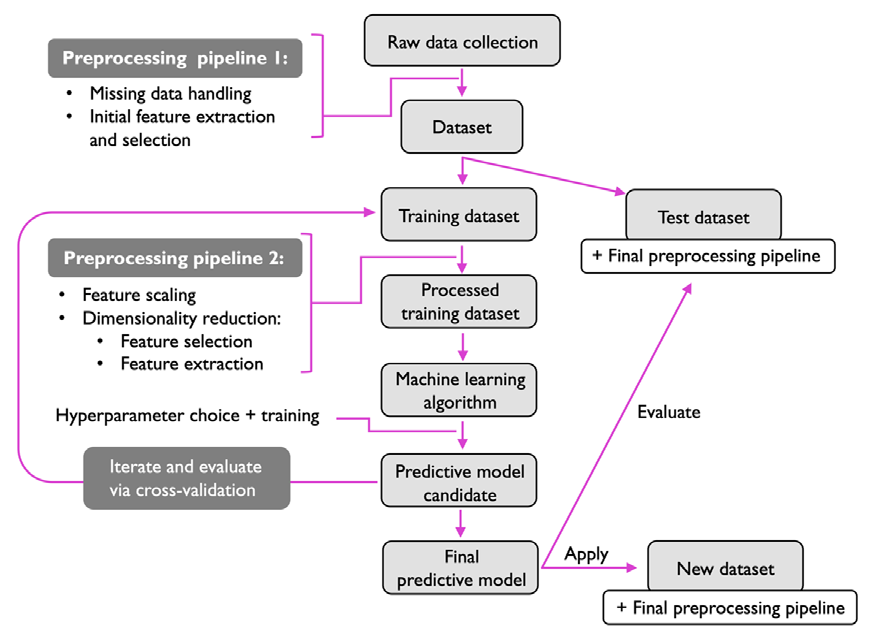
- 預處理--使資料成型
原始資料很少以學習演算法的最佳性能所需的形式和形狀出現,因此,資料的預處理是任何機器學習應用中最關鍵的步驟之一,
如果我們以上一節中的鳶尾花資料集為例,我們可以把原始資料看成是一系列的花卉影像,我們要從中提取有意義的特征,有用的特征可以圍繞花的顏色或花的高度、長度和寬度,
許多機器學習演算法還要求所選特征在同一尺度上以獲得最佳性能,這通常是通過在[0, 1]范圍內轉換特征或具有零平均值和單位方差的標準正態分布來實作,
一些被選中的特征可能是高度相關的,因此在一定程度上是多余的,在這些情況下,降維技術對于將特征壓縮到較低維度的子空間是很有用的,降低特征空間的維度需要更少的存盤空間,而且學習演算法可以運行得更快,在某些情況下,如果資料集包含大量不相關的特征(或噪聲);也就是說,如果資料集的信噪比很低,降維也可以提高模型的預測性能,
為了確定我們的機器學習演算法不僅在訓練資料集上表現良好,而且對新資料也有很好的泛化作用,我們還想把資料集隨機分成獨立的訓練和測驗資料集,我們使用訓練資料集來訓練和優化我們的機器學習模型,而將測驗資料集保留到最后以評估最終模型,
- 訓練和選擇預測模型
每種分類演算法都有其固有的偏見,如果我們不對任務做任何假設,沒有任何分類模型有優勢,因此,在實踐中,必須至少比較一些不同的學習演算法,以訓練和選擇性能最好的模型,但在比較不同的模型之前,我們首先要決定衡量性能的指標,常用的指標是分類精度,它被定義為正確分類的實體比例,
如果我們不使用這個測驗資料集進行模型選擇,而是保留它進行最終的模型評估,我們怎么知道哪個模型在最終的測驗資料集和真實世界的資料上表現良好?為了解決這個問題中蘊含的問題,可以使用被總結為 "交叉驗證 "的不同技術,在交叉驗證中,我們將資料集進一步劃分為訓練子集和驗證子集,以估計模型的泛化性能,
最后,我們也不能指望軟體庫提供的不同學習演算法的默認引數對我們的具體問題任務來說是最優的,因此,我們將經常使用超引數優化技術,幫助我們在后面的章節中對模型的性能進行微調,
我們可以把這些超引數看作不是從資料中學習出來的引數,而是代表模型的旋鈕,我們可以轉動它來提高其性能,在后面的章節中,當我們看到實際的例子時,這將變得更加清晰,
- 評估模型和預測未見過的資料實體
在我們選擇了一個在訓練資料集上擬合的模型后,我們可以使用測驗資料集來估計它在這些未見過的資料上的表現,以估計所謂的泛化誤差,如果我們對它的表現感到滿意,我們現在可以用這個模型來預測新的、未來的資料,需要注意的是,前面提到的程式的引數,如特征縮放和降維,完全是從訓練資料集中獲得的,同樣的引數后來被重新應用于轉換測驗資料集,以及任何新的資料實體--否則在測驗資料上測量的性能可能過于樂觀了,
使用Python進行機器學習
- Anaconda
Python是資料科學中最流行的編程語言,由于其非常活躍的開發者和開源社區,已經開發了大量有用的科學計算和機器學習的庫,
盡管Python等解釋型語言在計算密集型任務方面的性能不如低級別的編程語言,但NumPy和SciPy等擴展庫已經被開發出來,它們建立在低級別的Fortran和C實作之上,用于對多維陣列進行快速矢量操作,
對于機器學習編程任務,我們將主要參考scikit-learn庫,它是目前最流行和最容易獲得的開源機器學習庫之一,在后面的章節中,當我們關注機器學習的一個子領域--深度學習時,我們將使用最新版的PyTorch庫,它專門通過利用顯卡非常有效地訓練所謂的深度神經網路模型,
強烈推薦的用于科學計算背景下安裝Python的開源軟體包管理系統是Continuum Analytics的Conda,Conda是免費的,并在許可性的開源許可證下授權,它的目標是幫助資料科學、數學和工程的Python包在不同的作業系統上進行安裝和版本管理,如果你想使用conda,它有不同的版本,即Anaconda、Miniconda和Miniforge:
Anaconda預裝了許多科學計算軟體包,Anaconda的安裝程式可以在https://docs.anaconda.com/anaconda/install/,而Anaconda的快速入門指南可以在https://docs.anaconda.com/anaconda/user-guide/getting-started/,
Miniconda是Anaconda的一個更精簡的替代品(https://docs.conda.io/en/latest/miniconda.html),本質上,它與Anaconda相似,但沒有預裝任何軟體包,許多人(包括作者)都喜歡這樣,
Miniforge與Miniconda類似,但由社區維護,并使用與Miniconda和Anaconda不同的包庫(conda-forge),我們發現Miniforge是Miniconda的很好的替代品,下載和安裝說明可以在GitHub倉庫中找到:https://github.com/conda-forge/miniforge,
在通過 Anaconda、Miniconda 或 Miniforge 成功安裝 conda 后,我們可以使用以下命令安裝新的 Python 包:
conda install SomePackage
conda update SomePackage
不能通過官方conda渠道獲得的軟體包可能會通過社區支持的conda-forge專案(https://conda-forge.org)獲得,這可以通過-channel conda-forge標志指定,比如說
conda install SomePackage --channel conda-forge
不能通過默認的conda通道或conda-forge獲得的軟體包可以通過pip安裝,如前所述,比如說
pip install SomePackage
- 用于科學計算、資料科學和機器學習的軟體包
在本書的前半部分,我們將主要使用NumPy的多維陣列來存盤和處理資料,偶爾,我們會使用pandas,這是建立在NumPy之上的庫,它提供了額外的高級資料操作工具,使處理表格資料更加方便,為了增強你的學習體驗,并將定量資料可視化,這對理解資料往往非常有用,我們將使用非常可定制的Matplotlib庫,
NumPy
SciPy
Scikit-learn
Matplotlib
pandas
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551628.html
標籤:其他
上一篇:vCenter報錯:Log Disk Exhaustion on 10
下一篇:返回列表