作者:京東零售 牛曉光
根據現有調研和實踐,由OpenAI提供的ChatGPT/GPT-4模型和CodeX模型能夠很好的理解和生成業界大多數編程語言的邏輯和代碼,其中尤其擅長Python、JavaScript、TypeScript、Ruby、Go、C# 和 C++等語言,
然而在實際應用中,我們經常會在編碼時使用到一些私有框架、包、協議和DSL等,由于相關模型沒有學習最新網路資料,且這些私有資料通常也沒有發布在公開網路上,OpenAI無法根據這些私有資訊生成對應代碼,
一、OpenAI知識學習方式
OpenAI提供了幾種方式,讓OpenAI模型學習私有知識:
1. 微調模型
OpenAI支持基于現有的基礎模型,通過提供“prompt - completion”訓練資料生成私有的自定義模型,
使用方法
在執行微調作業時,需要執行下列步驟:
1. 準備訓練資料:資料需包含prompt/completion,格式支持CSV, TSV, XLSX, JSON等,
- 格式化訓練集:
openai tools fine_tunes.prepare_data -f <LOCAL_FILE> LOCAL_FILE:上一步中準備好的訓練資料,
2. 訓練模型微調:openai api fine_tunes.create -t <LOCAL_FILE> -m <BASE_MODULE> --suffix "<MODEL_SUFFIX>"
LOCAL_FILE:上一步中準備好的訓練集,BASE_MODULE:基礎模型的名稱,可選的模型包括ada、babbage、curie、davinci等,MODEL_SUFFIX:模型名稱后綴,
3. 使用自定義模型
使用成本
在微調模型方式中,除了使用自定義模型進行推理時所需支付的費用外,訓練模型時所消耗的Tokens也會對應收取費用,根據不同的基礎模型,費用如下:
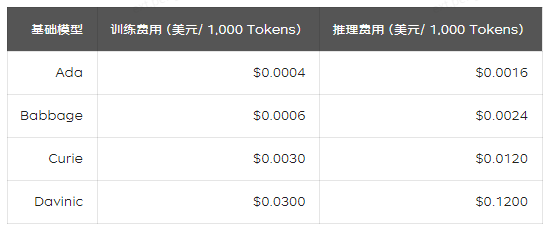
結論
使用微調模型進行私有知識學習,依賴于大量的訓練資料,訓練資料越多,微調效果越好,
此方法適用于擁有大量資料積累的場景,
2. 聊天補全
GPT模型接收對話形式的輸入,而對話按照角色進行整理,對話資料的開始包含系統角色,該訊息提供模型的初始說明,可以在系統角色中提供各種資訊,如:
-
助手的簡要說明
-
助手的個性特征
-
助手需要遵循的指令或規則
-
模型所需的資料或資訊
我們可以在聊天中,通過自定義系統角色為模型提供執行用戶指令所必要的私有資訊,
使用方法
可以在用戶提交的資料前,追加對私有知識的說明內容,
openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{ role: "system", content: "你是一款智能聊天機器人,幫助用戶回答有關內容管理系統低代碼引擎CCMS的技術問題,智能根據下面的背景關系回答問題,如果不確定答案,可以說“我不知道”,\n\n" +
"背景關系:\n" +
"- CCMS通過可視化配置方式生成中后臺管理系統頁面,其通過JSON資料格式描述頁面資訊,并在運行時渲染頁面,\n" +
"- CCMS支持普通串列、篩選串列、新增表單、編輯表單、詳情展示等多種頁面型別,\n" +
"- CCMS可以配置頁面資訊、介面定義、邏輯判斷、資料系結和頁面跳轉等互動邏輯,"
},
{ role: "user", content: "CCMS是什么?" }
]
}).then((response) => response.data.choices[0].message.content);
使用成本
除了用戶所提交的內容外,系統角色所提交的關于私有知識的說明內容,也會按照Tokens消耗量進行計費,
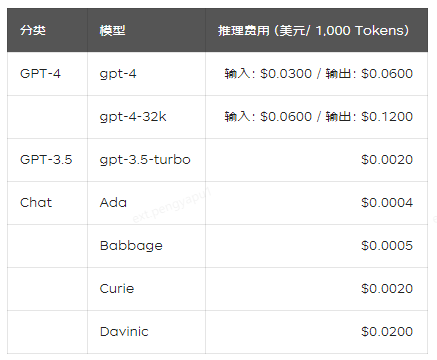
結論
使用聊天補全進行私有知識學習,依賴于系統角色的資訊輸入,且此部分資料的Tokens消耗會隨每次用戶請求而重復計算,
此方法適用于私有知識清晰準確,且內容量較少的場景,
二、私有知識學習實踐
對于私有框架、包、協議、DSL等,通常具備比較完善的使用檔案,而較少擁有海量的用戶使用資料,所以在當前場景下,傾向于使用聊天補全的方式讓GPT學習私有知識,
而在此基礎上,如何為系統角色提供少量而精確的知識資訊,則是在保障用戶使用情況下,節省使用成本的重要方式,
3. 檢索-提問解決方案
我們可以在呼叫OpenAI提供的Chat服務前,使用用戶所提交的資訊對私有知識進行檢索,篩選出最相關的資訊,再進行Chat請求,檢索Tokens消耗,
而OpenAI所提供的嵌入(Embedding)服務則可以解決檢索階段的作業,
使用方法
1. 準備搜索資料(一次性)
-
收集:準備完善的使用檔案,如:https://jd-orion.github.io/docs
-
分塊:將檔案拆分為簡短的、大部分是獨立的部分,這通常是檔案中的頁面或章節,
-
嵌入:為每一個分塊分別呼叫OpenAI API生成Embedding,
await openai.createEmbedding({
model: "text-embedding-ada-002",
input: fs.readFileSync('./document.md', 'utf-8').toString(),
}).then((response) => response.data.data[0].embedding);
- 存盤:保存Embedding資料,(對于大型資料集,可以使用矢量資料庫)
2. 檢索(每次查詢一次)
-
為用戶的提問,呼叫OpenAI API生成Embedding,(同1.3步驟)
-
使用提問Embedding,根據與提問的相關性對私有知識的分塊Embedding進行排名,
const fs = require('fs');
const { parse } = require('csv-parse/sync');
const distance = require( 'compute-cosine-distance' );
function (input: string, topN: number) {
const knowledge: { text: string, embedding: string, d?: number }[] = parse(fs.readFileSync('./knowledge.csv').toString());
for (const row of knowledge) {
row.d = distance(JSON.parse(row.embedding), input)
}
knowledge.sort((a, b) => a.d - b.d);
return knowledge.slice(0, topN).map((row) => row.text));
}
3. 提問(每次查詢一次)
- 給請求的系統角色插入與問題最相關的資訊
async function (knowledge: string[], input: string) {
const response = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{
role: 'system',
content: "你是一款智能聊天機器人,幫助用戶回答有關內容管理系 統低代碼引擎CCMS的技術問題,\n\n" + knowledge.join("\n")
},
{
role: 'user',
content: input
}
]
}).then((response) => response.data.choices[0].message.content);
return response
}
- 回傳GPT的答案
使用成本
使用此方法,需要一次性的支付用于執行Embedding的費用,
三、低代碼自然語言搭建案例
解決了讓GPT學習私有知識的問題后,就可以開始使用GPT進行私有框架、庫、協議和DSL相關代碼的生成了,
本文以低代碼自然語言搭建為例,幫助用戶使用自然語言對所需搭建或修改的頁面進行描述,進而使用GPT對描述頁面的組態檔進行修改,并根據回傳的內容為用戶提供實時預覽服務,
使用方法
OpenAI呼叫組件
const { Configuration, OpenAIApi } = require("openai");
const openai = new OpenAIApi(new Configuration({ /** OpenAI 配置 */ }));
const distance = require('compute-cosine-distance');
const knowledge: { text: string, embedding: string, d?: number }[] = require("./knowledge")
export default function OpenAI (input, schema) {
return new Promise((resolve, reject) => {
// 將用戶提問資訊轉換為Embedding
const embedding = await openai.createEmbedding({
model: "text-embedding-ada-002",
input,
}).then((response) => response.data.data[0].embedding);
// 獲取用戶提問與知識的相關性并排序
for (const row of knowledge) {
row.d = distance(JSON.parse(row.embedding), input)
}
knowledge.sort((a, b) => a.d - b.d);
// 將相關性知識、原始代碼和用戶提問發送給GPT-3.5模型
const message = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{
role: 'system',
content: "你是編程助手,需要閱讀協議知識,并按照用戶的要求修改代碼,\n\n" +
"協議知識:\n\n" +
knowledge.slice(0, 10).map((row) => row.text).join("\n\n") + "\n\n" +
"原始代碼:\n\n" +
"```\n" + schema + "\n```"
},
{
role: 'user',
content: input
}
]
}).then((response) => response.data.choices[0].message.content);
// 檢查回傳訊息中是否包含Markdown語法的代碼塊標識
let startIndex = message.indexOf('```');
if (message.substring(startIndex, startIndex + 4) === 'json') {
startIndex += 4;
}
if (startIndex > -1) {
// 回傳訊息為Markdown語法
let endIndex = message.indexOf('```', startIndex + 3);
let messageConfig;
// 需要遍歷所有代碼塊
while (endIndex > -1) {
try {
messageConfig = message.substring(startIndex + 3, endIndex);
if (
/** messageConfig正確性校驗 */
) {
resolve(messageConfig);
break;
}
} catch (e) {
/* 本次失敗 */
}
startIndex = message.indexOf('```', endIndex + 3);
if (message.substring(startIndex, startIndex + 4) === 'json') {
startIndex += 4;
}
if (startIndex === -1) {
reject(['OpenAI回傳的資訊不可識別:', message]);
break;
}
endIndex = message.indexOf('```', startIndex + 3);
}
} else {
// 回傳訊息可能為代碼本身
try {
const messageConfig = message;
if (
/** messageConfig正確性校驗 */
) {
resolve(messageConfig);
} else {
reject(['OpenAI回傳的資訊不可識別:', message]);
}
} catch (e) {
reject(['OpenAI回傳的資訊不可識別:', message]);
}
}
})
}
低代碼渲染
import React, { useState, useEffect } from 'react'
import { CCMS } from 'ccms-antd'
import OpenAI from './OpenAI'
export default function App () {
const [ ready, setReady ] = useState(true)
const [ schema, setSchema ] = useState({})
const handleOpenAI = (input) => {
OpenAI(input, schema).then((nextSchema) => {
setReady(false)
setSchema(nextSchema)
})
}
useEffect(() => {
setReady(true)
}, [schema])
return (
<div style={{ width: '100vw', height: '100vh' }}>
{ready && (
<CCMS
config={pageSchema}
/** ... */
/>
)}
<div style={{ position: 'fixed', right: 385, bottom: 20, zIndex: 9999 }}>
<Popover
placement="topRight"
trigger="click"
content={
<Form.Item label="使用OpenAI助力搭建頁面:" labelCol={{ span: 24 }}>
<Input.TextArea
placeholder="請在這里輸入內容,按下Shift+回車確認,"
defaultValue=https://www.cnblogs.com/Jcloud/archive/2023/05/04/{defaultPrompt}
onPressEnter={(e) => {
if (e.shiftKey) {
handleOpenAI(e.currentTarget.value)
}
}}
/>
}
>
四、資訊安全
根據OpenAI隱私政策說明,使用API方式進行資料訪問時:
- 除非明確的授權,OpenAI不會使用用戶發送的資料進行學習和改進模型,
- 用戶發送的資料會被OpenAI保留30天,以用于監管和審查,(有限數量的授權OpenAI員工,以及負有保密和安全義務的專業第三方承包商,可以訪問這些資料)
- 用戶上傳的檔案(包括微調模型是提交的訓練資料),除非用戶洗掉,否則會一直保留,
另外,OpenAI不提供模型的私有化部署(包括上述微調模型方式所生成的自定義模型),但可以通過聯系銷售團隊購買私有容器,
文中所使用的訓練資料、私有框架知識以及低代碼框架均源自本團隊開發并已開源的內容,用戶使用相關服務時也會進行資料安全提示,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551639.html
標籤:其他
上一篇:【手記】翻新顯卡安裝驅動程式
下一篇:返回列表