一、數學優化
1.1 定義
Mathematical Optimization(數學優化)問題,亦稱最優化問題,是指在一定約束條件下,求解一個目標函式的最大值(或最小值)問題,

根據輸入變數 ?? 的值域是否為實數域,數學優化問題可以分為離散優化問題和連續優化問題.
在連續優化問題中,根據是否有變數的約束條件,可以將優化問題分為無約束優化問題和約束優化問題.
1.2 線性優化和非線性優化
- 如果目標函式和所有的約束函式都為線性函式,則該問題為線性規劃(Linear Programming)問題,
- 相反,如果目標函式或任何一個約束函式為非線性函式,則該問題為非線性規劃(Nonlinear Programming)問題,
1.3 凸優化

1.3.1 凸集和凸函式
在凸優化問題中,變數 ?? 的可行域為凸集(Convex Set),即對于集合中任意兩點,它們的連線全部位于集合內部,
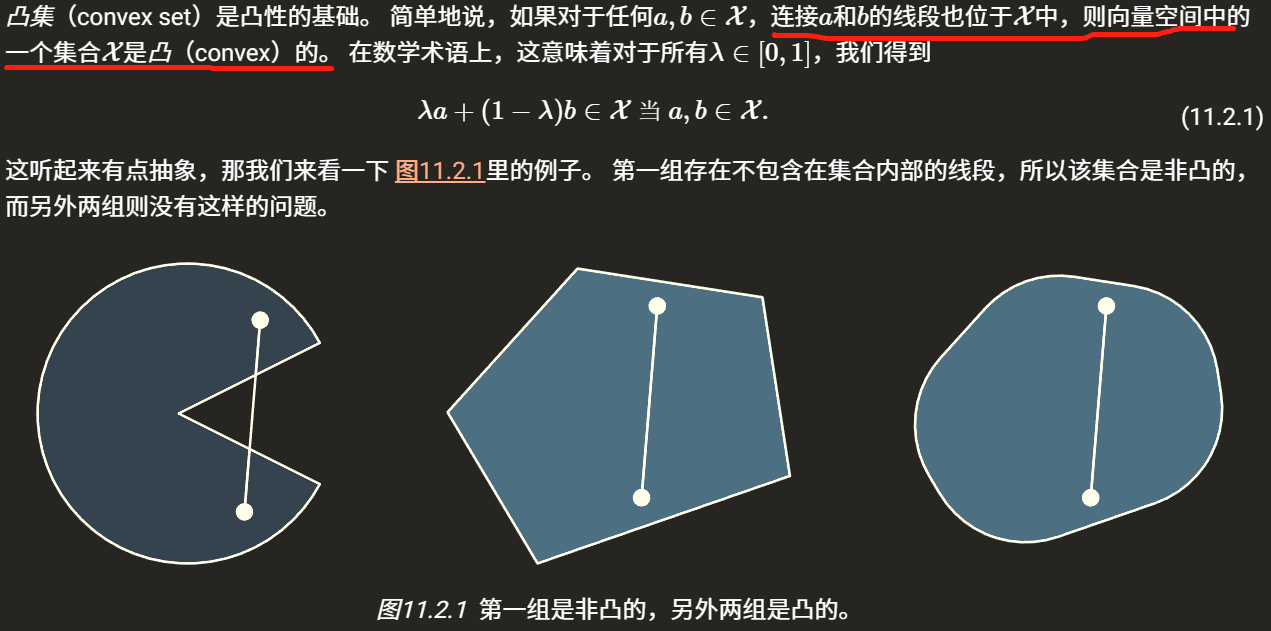

目標函式 ?? 也必須為凸函式, 即滿足 
凸函式: 給定任意兩個點,函式的取值在兩點之間的取值,總是小于此兩點
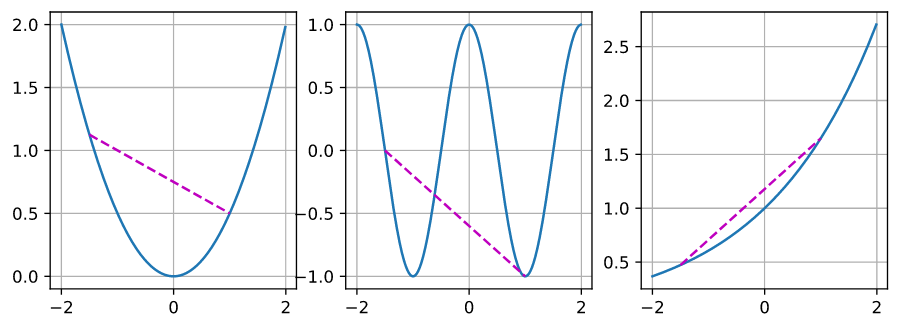
1.3.2 其他性質



凸優化要求優化目標是凸函式,然而深度學習建模的往往是非凸的問題,因而,只在演算法收斂性證明性上有用,但實際訓練中用處不大,
1.4 深度學習優化
深度學習中大多數目標函式都很復雜,沒有決議解,所以必須使用數值優化演算法,
深度學習優化中最令人煩惱的是區域最小值、鞍點和梯度消失,
區域最小值
對于任何目標函式f(x),如果在處x對應的值f(x)小于在x附近任意其他點的值,那么f(x)可能是區域最小值
鞍點(saddle point)
指函式的所有梯度都為0,但既不是全域最小值也不是區域最小值的任何位置,
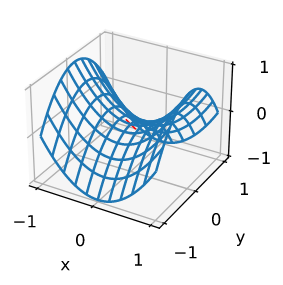
假設函式輸入是k維向量,其輸出是標量,因此其Hessian矩陣將有k個特征值,函式的解可能是區域最小值、區域最大值或函式梯度為零位置處的鞍點:
- 當函式在零梯度位置處的Hessian矩陣的特征值全部為正值時(正定),我們有該函式的區域最小值;
- 當函式在零梯度位置處的Hessian矩陣的特征值全部為負值時,我們有該函式的區域最大值;
- 當函式在零梯度位置處的Hessian矩陣的特征值為負值和正值時,我們有該函式的一個鞍點
這就是多變數微積分的結論,
二、梯度下降
2.1 方向導數推導GD
方向導數即,一個函式在給定方向的變化率(斜率,>0增加,<0減少),其實就是導數推廣到單位方向:簡而言之,給定函式點x,選擇在任意一個單位方向都求一個斜率來看函式的變化程度Δf(x+Δx)/Δx,
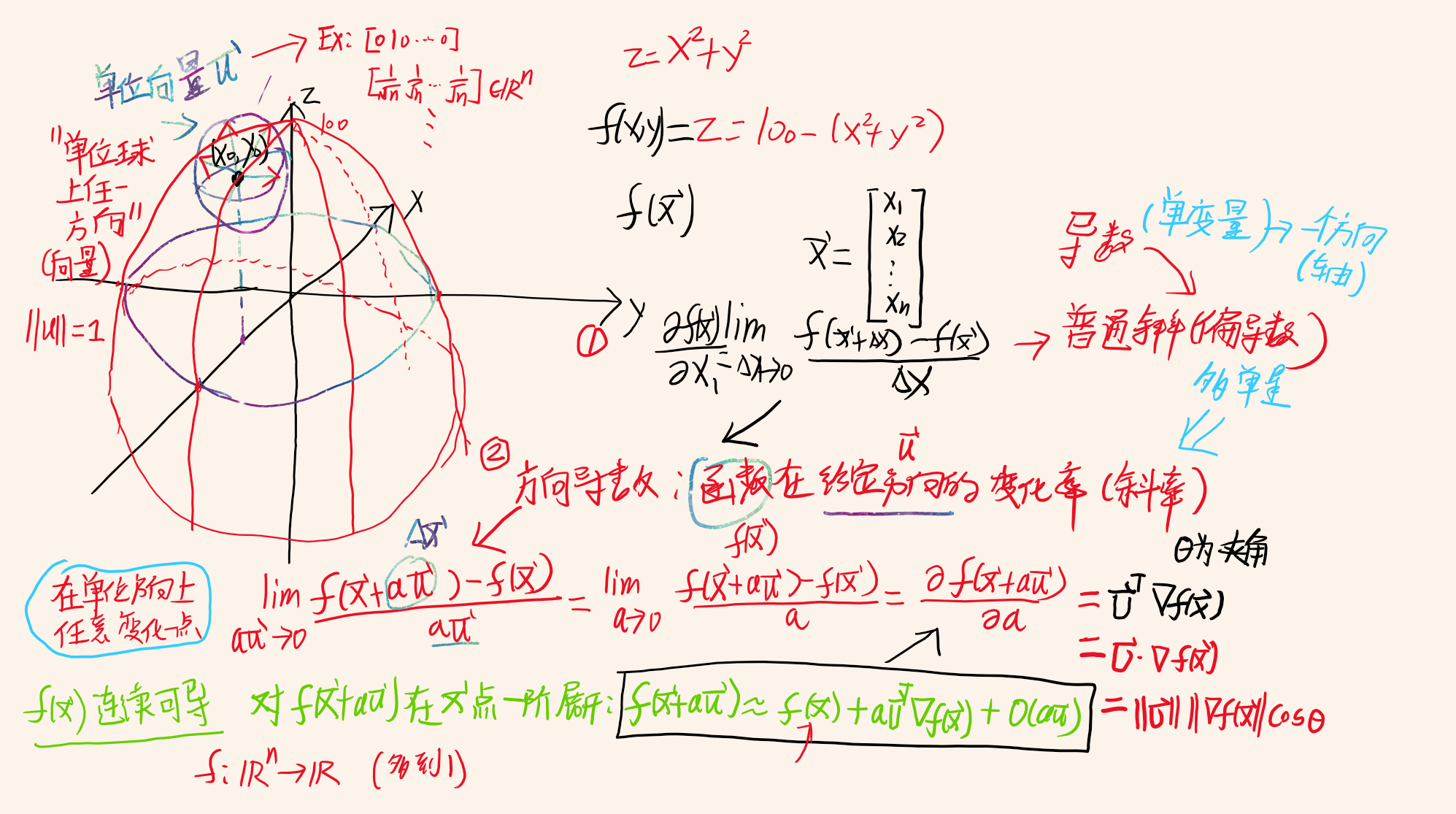
方向導數相當于是算,在給定點和方向的變化率,
如果你要爬升(上山),那么可定選最陡的方向,給定點,通過求方向的極值得到最優方向(區域),
梯度是方向導數取最大值的方向(負梯度,是衰減最厲害的方向)
2.2 泰勒級數啟發式推導GD
總結:泰勒一階展開,基于負梯度針對 \epsilon 構造遞減序列
方向導數:梯度是方向導數最大的方向,而負梯度則是函式值下降最快的方向
梯度下降啟發式
考慮一類連續可微實值函式 $ f: \mathbb{R} \rightarrow \mathbb{R} $,利用泰勒展開,可以得到
\[f(x + \epsilon) = f(x) + \epsilon f'(x) + \mathcal{O}(\epsilon^2) \]即在一階近似中,\(f(x + e)\)可通過x處的函式值f(x)和及其一階導數得出,
現在我們試圖構造出一個讓\(f(x)\)遞減的序列:
\[f(x + \epsilon) f(x) \]\[f(x + \epsilon) - f(x) =\epsilon f'(x) + \mathcal{O}(\epsilon^2) \]可以試圖將,$epsilon $設定為一個負的極小值 \(\eta\) 乘以梯度:
$ \epsilon = -\eta f'(x) $ 那么有,\(\eta\)設為固定步長,將其代入泰勒展開式以得到:$$ f(x - \eta f'(x)) = f(x) - \eta f'^2(x) + \mathcal{O}(\eta^2 f'^2(x))
$$
如果$ f(x)$ 的導數沒有消失,就能繼續展開,這是因為:$ f'^2(x)$ 此外,總是可令 $\eta $小到足以使高階項變得不相關,因此:
\[f(x - \eta f'(x)) - f(x) \]那么有, \(x\)為\(f(x)\)的引數,那么梯度下降則有:
\[x \leftarrow x - \eta f'(x) \]可假設\(x\)在負梯度方向上移動的會減少函式值,
學習率
在梯度下降中,我們首先選擇初引數始值和學習率常數,然后使用它們連續迭代,直到停止條件達成,
學習率(learning rate)決定目標函式能否收斂到區域最小值,以及何時收斂到最小值,
若學習率太小,將導致的更新非常緩慢代

若學習率太大,將導致的更新震蕩

import torch
import numpy as np
def f(x):
# 目標函式
f(x) = x^2
return x ** 2
def f_grad(x):
# 目標函式的梯度(導數)
return 2 * x
def gd(eta, f_grad):
x = 10.0 # 初始引數值
results = [x]
for i in range(10):
x = x - eta * f_grad(x)
results.append(float(x))
print(f'epoch 10, x: {x:f}')
return results
results = gd(0.2, f_grad)

2. 3多元梯度下降
多變數情況下的梯度下降,
考慮多元連續可微實值函式,輸入為
即目標函式將向量映射成標量 \(f: \mathbb{R}^d \to \mathbb{R}\),相應地,它的梯度也是一個由個偏導陣列成的向量:$$ \nabla f(\mathbf{x}) = \bigg[\frac{\partial f(\mathbf{x})}{\partial x_1}, \frac{\partial f(\mathbf{x})}{\partial x_2}, \ldots, \frac{\partial f(\mathbf{x})}{\partial x_d}\bigg]^\top.$$
對多變數函式使用相應的一階泰勒近似來思考, 具體來說
\[f(\mathbf{x} + \boldsymbol{\epsilon}) = f(\mathbf{x}) + \mathbf{\boldsymbol{\epsilon}}^\top \nabla f(\mathbf{x}) + \mathcal{O}(\|\boldsymbol{\epsilon}\|^2). \]在epsilon的二階項中,函式下降最陡的方向由負梯度得出:$ -\nabla f(\mathbf{x})$ ,即在近似中,$ f(x + e)$ 可通過\(x\)處的函式值\(f(x)\)和一階導數\(f`(x)\)得出,
現在試圖,構造出一個讓f(x)遞減的序列:
可以試圖將 設定為一個負的極小值 \(\eta\) 乘以梯度:

未完待續
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551633.html
標籤:其他
下一篇:返回列表