摘要:本文介紹了一種MATLAB實作的目標檢測系統代碼,采用 YOLOv4 檢測網路作為核心模型,用于訓練和檢測各種任務下的目標,并在GUI界面中對各種目標檢測結果可視化,文章詳細介紹了YOLOv4的實作程序,包括演算法原理、MATLAB 實作代碼、訓練資料集、訓練程序和圖形用戶界面,在GUI界面中,用戶可以選擇各種圖片、視頻、攝像頭進行檢測識別,可更換檢測模型,本文提供了完整的 MATLAB 代碼和使用教程,適合新入門的朋友參考,完整代碼資源檔案請參見文末的下載鏈接,
目錄- 1. 引言
- 2. 系統界面演示效果
- 3. 資料集格式介紹
- 4. 模型訓練代碼
- 5. 系統實作
- 6. 總結與展望
- 下載鏈接
- 結束語
- 參考文獻
?點擊跳轉至文末所有涉及的完整代碼檔案下載頁?
完整代碼下載:https://mbd.pub/o/bread/ZJiYm51v
參考視頻演示:https://www.bilibili.com/video/BV15a4y1G7yJ/
1. 引言
十年前博主在初學人工智能時,經常發現網上可供參考的高質量的完整教程或博客很少,要實作一個復雜點的代碼基本無從參考,自己很多時候都是在瞎摸索,撰寫這篇博客的初衷是為了分享技術知識,為初學者提供啟發,我希望通過博客的實體和解釋,激發讀者的興趣和熱情,幫助他們更好地理解和應用相關技術,正所謂“博學而篤志,切問而近思”,也希望讀者在閱讀博客的程序中,不要停止思考,在掌味訓本原理和技術之后,嘗試自己解決問題,提出新的觀點和想法,在學習的程序中,可能會遇到挑戰和困難,一個Bug的解決或許正是提高技能、拓展知識邊界的時機,本博客內容為博主原創,相關參考和參考文獻我已在文中標注,考慮到可能會有相關專業人員看到,博主的博客這里盡可能以學術期刊的格式撰寫,如需參考可參考本博客格式如下:
[1] 思緒無限. 基于YOLOv4的目標檢測系統(附MATLAB代碼+GUI實作)[J/OL]. CSDN, 2023.05. https://wuxian.blog.csdn.net/article/details/130470598.
[2] Wu, S. (2023, May). Object Detection System Based on YOLOv4 (with MATLAB Code and GUI Implementation) [J/OL]. CSDN. https://wuxian.blog.csdn.net/article/details/130470598.
目標檢測作為計算機視覺領域的一個重要研究方向,旨在從影像或視頻中識別和定位特定類別的物體(Redmon et al., 2016)[1],在過去的幾年里,隨著深度學習技術的發展,基于卷積神經網路(CNN)的目標檢測方法取得了顯著的進步,一些經典的目標檢測方法包括R-CNN(Girshick et al., 2014)[2]、Fast R-CNN(Girshick, 2015)[3]、Faster R-CNN(Ren et al., 2015)[4]、SSD(Liu et al., 2016)[5]和RetinaNet(Lin et al., 2017)[6],這些方法在各種基準資料集上取得了不俗的成績,如PASCAL VOC(Everingham et al., 2010)[7]、COCO(Lin et al., 2014)[8]和ImageNet(Russakovsky et al., 2015)[9],YOLO系列演算法(Redmon et al., 2016; Redmon & Farhadi, 2017; Redmon & Farhadi, 2018; Bochkovskiy et al., 2020)[1, 10-12]相較于其他方法,更注重檢測速度和實時性,因此在許多實際應用場景中具有較大優勢,
盡管上述方法在目標檢測領域取得了顯著成果,但每種方法都存在一定的局限性,例如,R-CNN系列方法在檢測精度上表現優異,但計算復雜度較高,導致檢測速度較慢(Girshick et al., 2014; Girshick, 2015; Ren et al., 2015)[2-4],相比之下,SSD和RetinaNet等一階段檢測方法在檢測速度上有所改進,但精度相對較低(Liu et al., 2016; Lin et al., 2017)[5, 6],YOLO系列演算法在檢測速度和精度之間取得了較好的平衡(Redmon et al., 2016; Redmon & Farhadi, 2017; Redmon & Farhadi, 2018; Bochkovskiy et al., 2020)[1, 10-12],尤其是YOLOv4演算法,憑借其較高的檢測精度和速度成為了目標檢測領域的一種重要方法(Bochkovskiy et al., 2020)[12],
目前,許多研究者和工程師已經成功地將YOLOv4應用于各種實際場景,如無人駕駛(Geiger et al., 2012)[13]、視頻監控(Sindhu et al., 2021)[14]、醫學影像(Shewajo et al., 2023)[15]等,然而,盡管YOLOv4在目標檢測任務中取得了令人矚目的成果,但在MATLAB環境中實作YOLOv4的相關研究仍相對較少(MathWorks, 2021)[16],基于MATLAB實作YOLOv4目標檢測系統具有較強的實用性,可以為計算機視覺和影像處理領域的研究人員和工程師提供便捷的開發和除錯工具,因此,本博客的主要貢獻點如下:
- 提供一個基于MATLAB實作的YOLOv4目標檢測系統,該系統具有用戶友好的界面,支持多種檢測模式,如圖片檢測、批量檢測、視頻檢測和實時攝像頭檢測;
- 詳細介紹在MATLAB環境中準備YOLOv4模型訓練所需的資料集格式,以及給出一個自定義動物識別資料集的實體;
- 提供YOLOv4模型的訓練代碼,并通過訓練曲線和模型評估結果展示其性能;
- 結合GUI界面,詳細闡述系統的設計框架和實作原理,
2. 系統界面演示效果
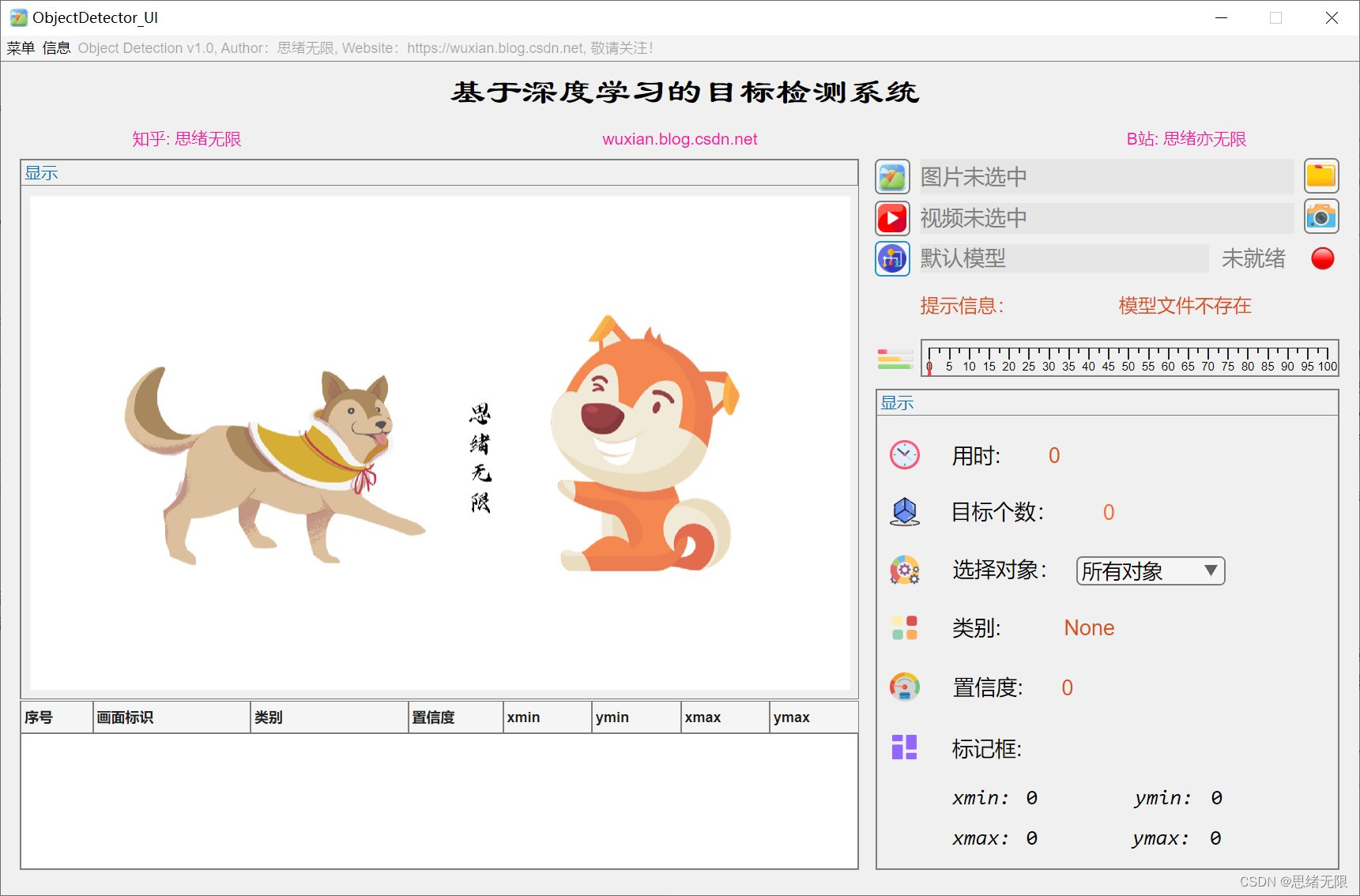
為了方便用戶進行目標檢測,我們基于MATLAB開發了一個具有用戶友好界面的YOLOv4目標檢測系統,該系統支持以下功能:
(1)選擇圖片檢測:用戶可以選擇單張圖片進行目標檢測,系統將識別圖片中的物體并在圖片上標注出物體的邊界框和類別,
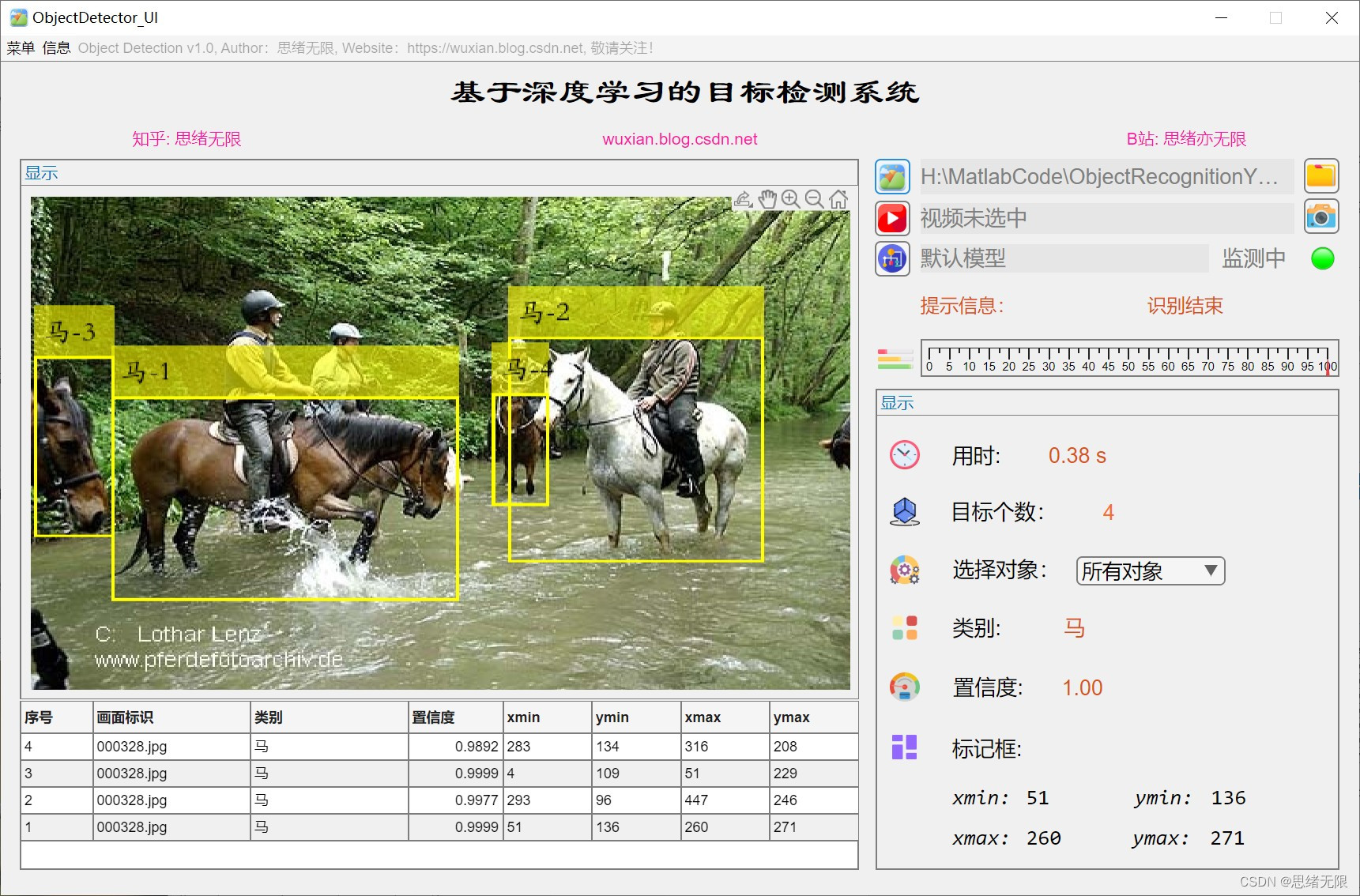
(2)選擇檔案夾批量檢測:用戶可以選擇一個檔案夾進行批量檢測,系統將自動識別檔案夾中的所有圖片,并將檢測結果保存到指定的輸出檔案夾中,
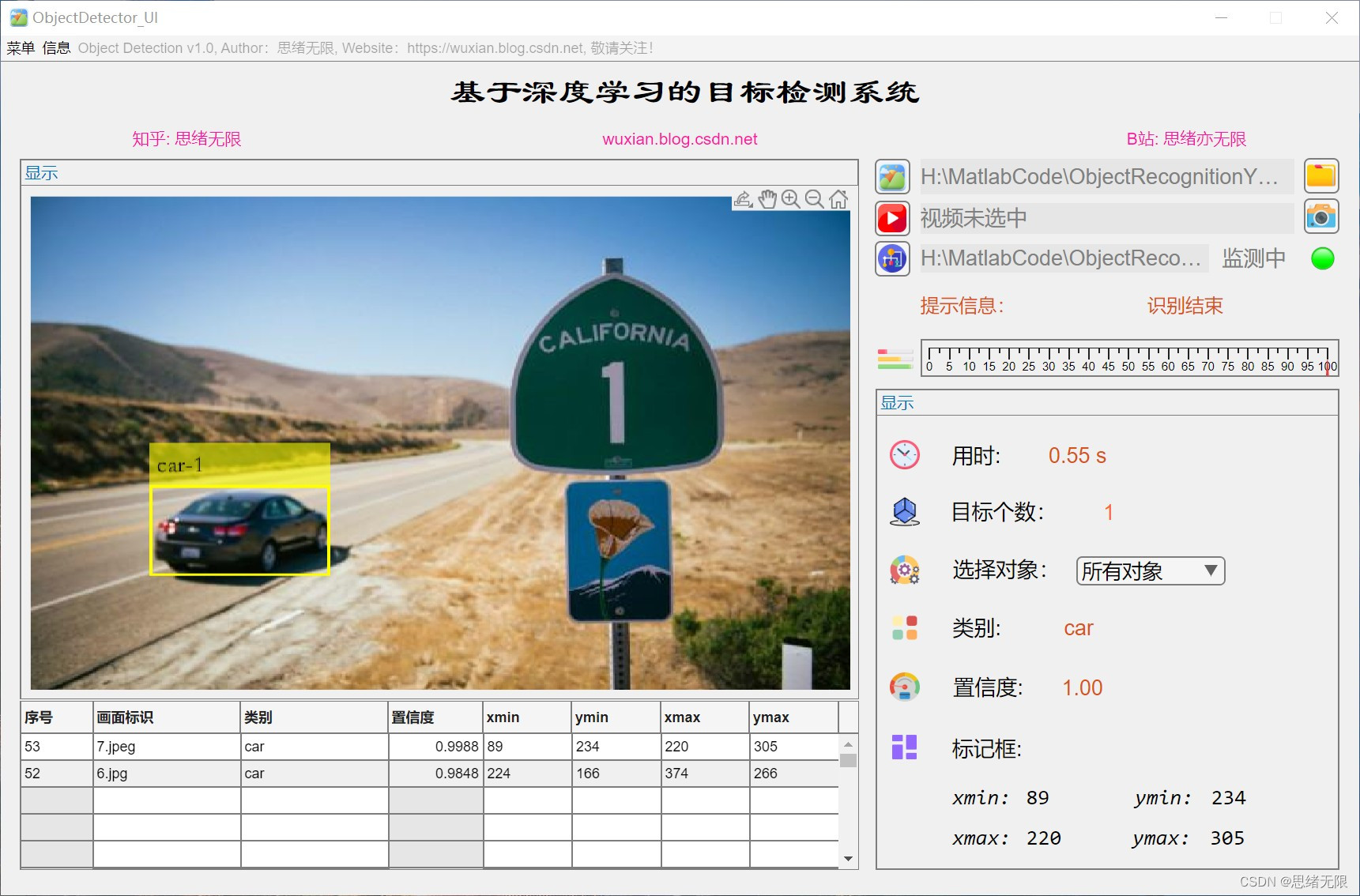
(3)選擇視頻檢測:用戶可以選擇一個視頻檔案進行目標檢測,系統將實時識別視頻中的物體并在視頻畫面上標注出物體的邊界框和類別,
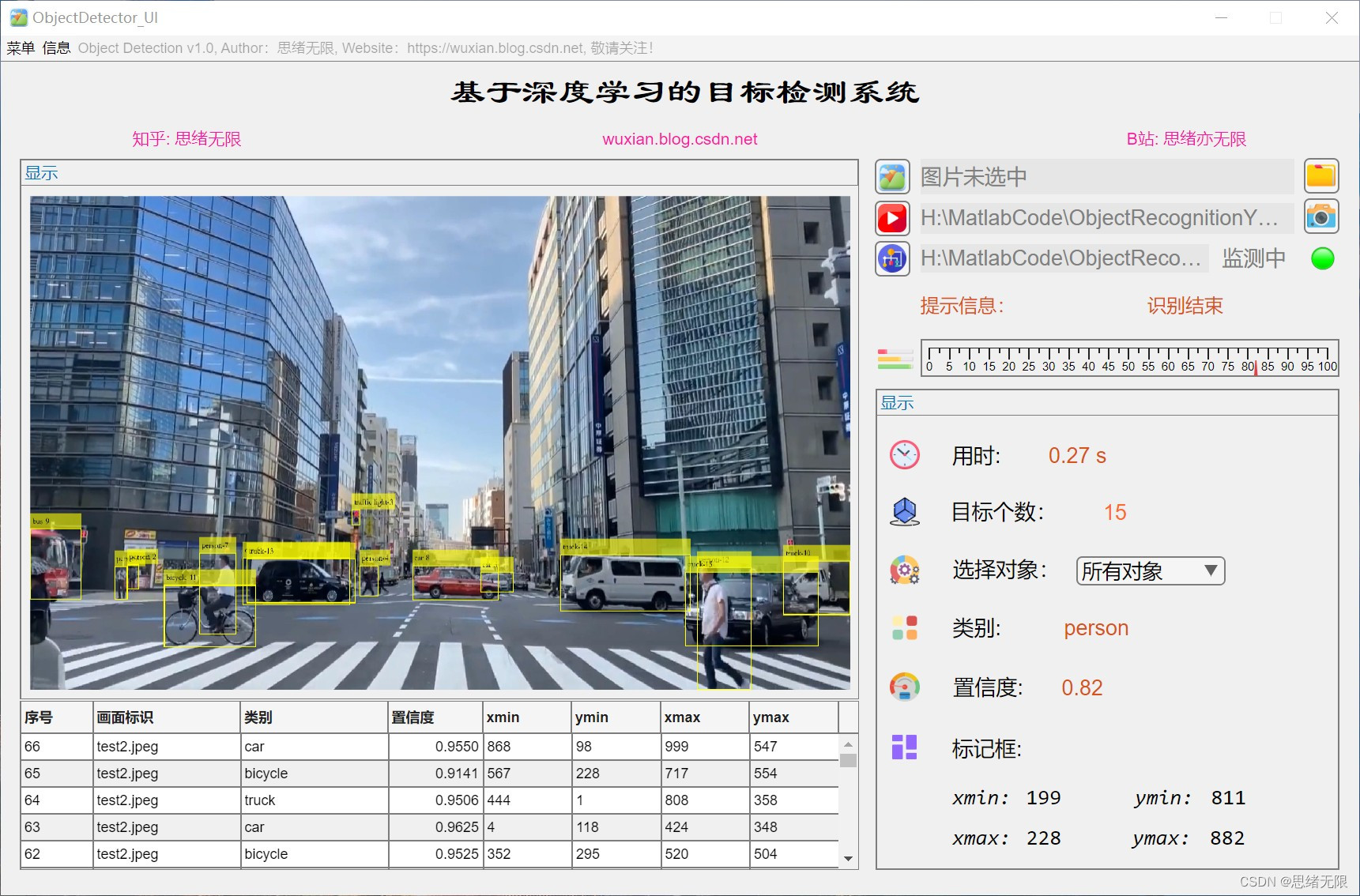
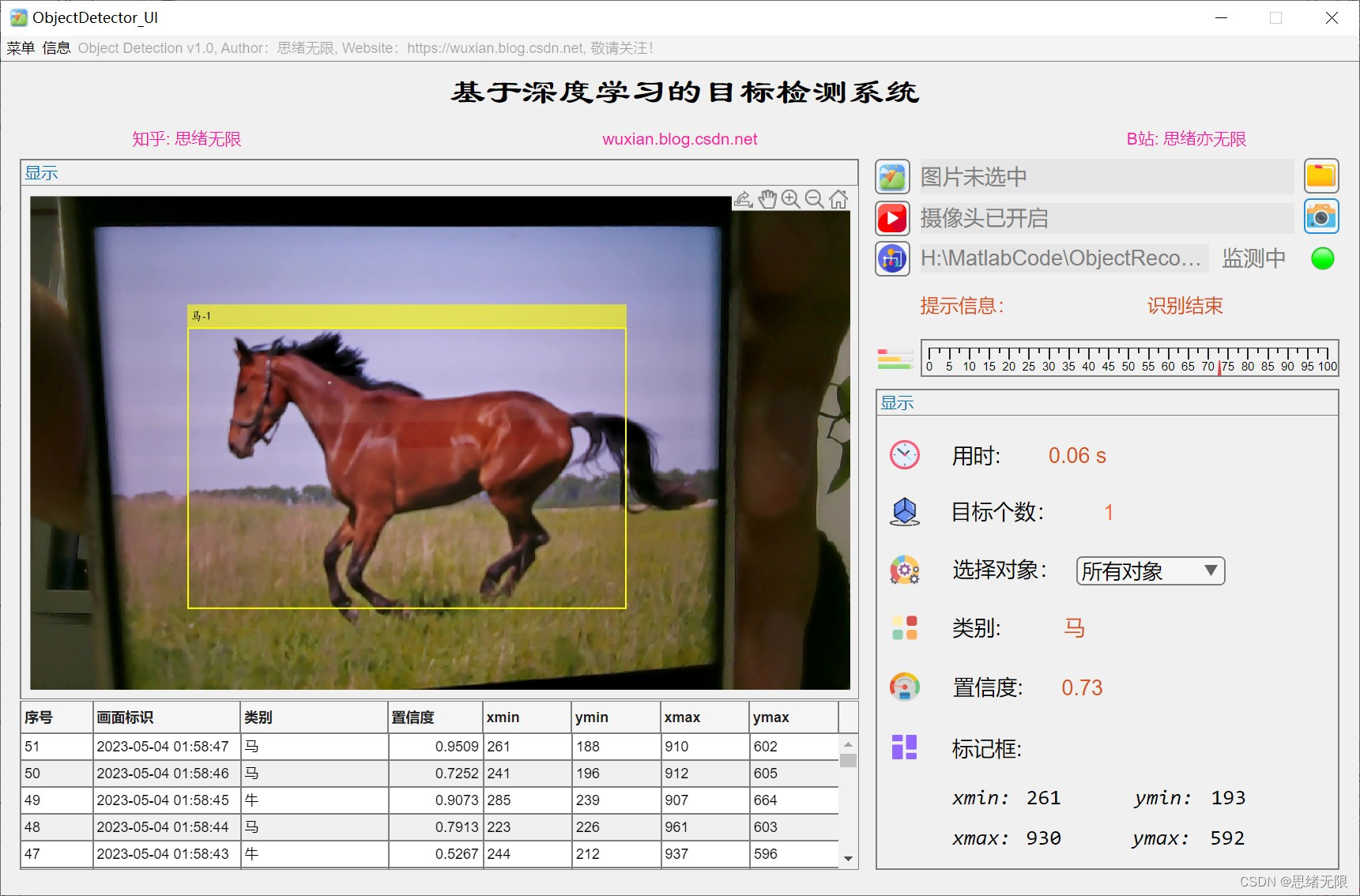
(4)呼叫攝像頭檢測:用戶可以啟用計算機攝像頭進行實時目標檢測,系統將實時識別攝像頭捕捉到的畫面中的物體,并在畫面上標注出物體的邊界框和類別,
(5)更換不同網路模型:用戶可以根據需要選擇不同的YOLOv4預訓練模型進行目標檢測,以適應不同的檢測任務和性能要求,
(6)通過界面顯示結果和可視化:系統的界面將直觀地展示檢測結果,包括物體的邊界框、類別以及置信度得分,同時,用戶可以通過界面查看檢測程序的可視化效果,以便更好地了解模型的檢測性能,
3. 資料集格式介紹
在MATLAB環境中訓練YOLOv4模型,首先需要準備一個合適的資料集,資料集應包含大量標注的圖片,以便訓練模型學會識別不同類別的物體,本節將詳細介紹MATLAB官方支持的YOLOv4模型訓練所需的資料集標注檔案格式,以及如何創建一個自定義的動物識別資料集作為示例,
在MATLAB中,YOLOv4訓練所需的資料集標注資訊采用table型別進行存盤,每個table的行表示一個樣本(即一張圖片),每一列對應一個特定的資訊,第一列為圖片檔案的路徑,而從第二列開始,每一列對應一個特定類別的標注資訊,每個類別的標注資訊包括在該類別下的邊界框坐標,如果一張圖片中有多個邊界框屬于同一類別,則使用二維陣串列示這些邊界框,若某類別在圖片中沒有出現,則用空陣列([])表示,
自定義動物識別資料集為例,可以看到資料集的結構如下:

在這個示例中,有6個類別:鳥(bird)、貓(cat)、牛(cow)、狗(dog)、馬(horse)和羊(sheep),每個類別的標注資訊包括邊界框的左上角坐標(x, y)以及邊界框的寬度和高度(w, h),
4. 模型訓練代碼
在本節中,將介紹如何使用MATLAB進行YOLOv4模型的訓練,我們將使用在前面部分準備好的自定義動物識別資料集,首先,需要加載訓練集、驗證集和測驗集的資料,并添加影像檔案的完整路徑,以下是加載資料集的MATLAB代碼:
% 加載資料集
data = https://www.cnblogs.com/sixuwuxian/archive/2023/05/04/load("data/Animal_dataset_train.mat");
trainData = data.Dataset; % 訓練集
data = https://www.cnblogs.com/sixuwuxian/archive/2023/05/04/load("data/Animal_dataset_val.mat");
validData = data.Dataset; % 驗證集
data = https://www.cnblogs.com/sixuwuxian/archive/2023/05/04/load("data/Animal_dataset_test.mat");
testData = https://www.cnblogs.com/sixuwuxian/archive/2023/05/04/data.Dataset; % 測驗集
% 為資料集添加完整路徑
dataDir = fullfile(pwd,'data');
trainData.imageFilename = fullfile(dataDir, trainData.imageFilename);
validData.imageFilename = fullfile(dataDir, validData.imageFilename);
testData.imageFilename = fullfile(dataDir, testData.imageFilename);
接下來,使用imageDatastore和boxLabelDatastore創建資料存盤,以便在訓練和評估期間加載影像和標簽資料,
% 創建資料存盤
imdsTrain = imageDatastore(trainData{:,"imageFilename"});
bldsTrain = boxLabelDatastore(trainData(:, 2:end));
imdsValidation = imageDatastore(validData{:,"imageFilename"});
bldsValidation = boxLabelDatastore(validData(:, 2:end));
imdsTest = imageDatastore(testData{:,"imageFilename"});
bldsTest = boxLabelDatastore(testData(:, 2:end));
% 整合圖片和標簽
trainingData = https://www.cnblogs.com/sixuwuxian/archive/2023/05/04/combine(imdsTrain, bldsTrain);
validationData = combine(imdsValidation, bldsValidation);
testData = combine(imdsTest, bldsTest);
為了訓練YOLOv4模型,需要調整輸入影像的大小,并根據錨框數量估計錨框,
inputSize = [320 224 3]; % 輸入尺寸
classes = {'bird', 'cat', 'cow', 'dog', 'horse', 'sheep'};
numAnchors = 6;
% 預處理資料
trainingDataForEstimation = transform(trainingData, @(data)preprocessData(data, inputSize));
[anchors, meanIoU] = estimateAnchorBoxes(trainingDataForEstimation, numAnchors);
% 計算每層的錨框
area = anchors(:,1) .* anchors(:,2);
[~, idx] = sort(area, "descend");
anchors = anchors(idx, :);
anchorBoxes = {anchors(1:3, :); anchors(4:6, :)};
接下來使用COCO資料集上訓練的預訓練YOLOv4檢測網路創建YOLOv4物件檢測器,在此之前,可以選擇性地應用資料增強方法,例如隨機水平翻轉、隨機縮放和顏色變換等,然后,設定訓練引數,如學習率、批量大小和最大迭代次數等,
% 使用 COCO 資料集上訓練的預訓練 YOLO v4 檢測網路創建YOLOv4物件檢測器
detector = yolov4ObjectDetector("tiny-yolov4-coco",classes,anchorBoxes,InputSize=inputSize);
if flag_augment % 進行資料增強
augmentedTrainingData = https://www.cnblogs.com/sixuwuxian/archive/2023/05/04/transform(trainingData, @augmentData); % 為資料配置增強操作
% 展示增強效果
augmentedData = cell(4,1);
for k = 1:4
data = read(augmentedTrainingData);
augmentedData{k} = insertShape(data{1},"rectangle",data{2});
reset(augmentedTrainingData);
end
figure
montage(augmentedData,BorderSize=10) % 演示資料增強效果
end
% 訓練引數設定
options = trainingOptions("adam", ...
ExecutionEnvironment=exe_env,...
GradientDecayFactor=0.9,...
SquaredGradientDecayFactor=0.999,...
InitialLearnRate=0.001,...
LearnRateSchedule="none",...
MiniBatchSize=16,...
L2Regularization=0.0005,...
MaxEpochs=300,...
BatchNormalizationStatistics="moving",...
DispatchInBackground=true,...
ResetInputNormalization=false,...
Shuffle="every-epoch",...
VerboseFrequency=20,...
CheckpointPath='./checkPoint/',...
CheckpointFrequency=10, ...
ValidationData=https://www.cnblogs.com/sixuwuxian/archive/2023/05/04/validationData, ...
OutputNetwork='best-validation-loss' ...
);
% options = trainingOptions("sgdm", ...
% ExecutionEnvironment=exe_env, ...
% InitialLearnRate=0.001, ...
% MiniBatchSize=16,...
% MaxEpochs=300, ...
% BatchNormalizationStatistics="moving",...
% ResetInputNormalization=false,...
% VerboseFrequency=30);
% 執行訓練程式
if doTraining
% Train the YOLO v4 detector.
if flag_augment % 是否資料增強
[detector,info] = trainYOLOv4ObjectDetector(augmentedTrainingData,detector,options);
else
if if_checkPoint % 是否使用checkpoint
load(checkpoint_path);
[detector,info] = trainYOLOv4ObjectDetector(trainingData, net, options);
else
[detector,info] = trainYOLOv4ObjectDetector(trainingData,detector,options);
end
end
else
% 否則使用預訓練模型
pretrained = load('yolov4_tiny.mat');
detector = pretrained.detector;
end
訓練程序中的輸出資訊如下:
*************************************************************************
Training a YOLO v4 Object Detector for the following object classes:
* bird
* cat
* cow
* dog
* horse
* sheep
Epoch Iteration TimeElapsed LearnRate TrainingLoss ValidationLoss
_____ _________ ___________ _________ ____________ ______________
Starting parallel pool (parpool) using the 'local' profile ...
Connected to the parallel pool (number of workers: 6).
1 20 00:01:40 0.001 62.356
1 40 00:01:48 0.001 25.72
1 60 00:02:01 0.001 19.095
1 80 00:02:08 0.001 21.819
2 100 00:02:29 0.001 14.169 0.67991
2 120 00:02:43 0.001 19.108
...
在這個程序中,首先選擇是否進行資料增強,然后,設定訓練引數,例如執行環境(GPU)、學習率、批量大小、最大迭代次數等,接下來,根據選擇進行訓練或使用預訓練模型,訓練完成后,將模型保存為animal_tiny_yolov4.mat,最后,使用訓練好的模型在測驗集上進行檢測,評估檢測精度,保存測驗結果和訓練曲線,整個訓練程序涉及預處理資料、資料增強、設定訓練引數、進行訓練、評估檢測精度等步驟,以上代碼示例展示了如何使用MATLAB實作這些步驟,以實作YOLOv4模型的訓練和評估,
5. 系統實作
在本節中,將詳細介紹如何將YOLOv4目標檢測器與圖形用戶界面(GUI)相結合,以實作一個友好、易于使用的動物識別系統,結合GUI可以讓用戶更方便地上傳圖片、選擇模型引數,以及查看識別結果,以下是設計框架和實作原理,系統實作主要包括以下幾個部分:
- 圖形用戶界面(GUI):提供用戶與系統互動的界面,包括圖片上傳、模型引數選擇、結果展示等功能,
- 影像處理模塊:對用戶上傳的圖片進行預處理,以適應YOLOv4模型的輸入要求,
- 檢測器模塊:使用訓練好的YOLOv4動物目標檢測器進行動物類別識別,
- 結果處理模塊:對檢測結果進行后處理,以便在GUI上展示,
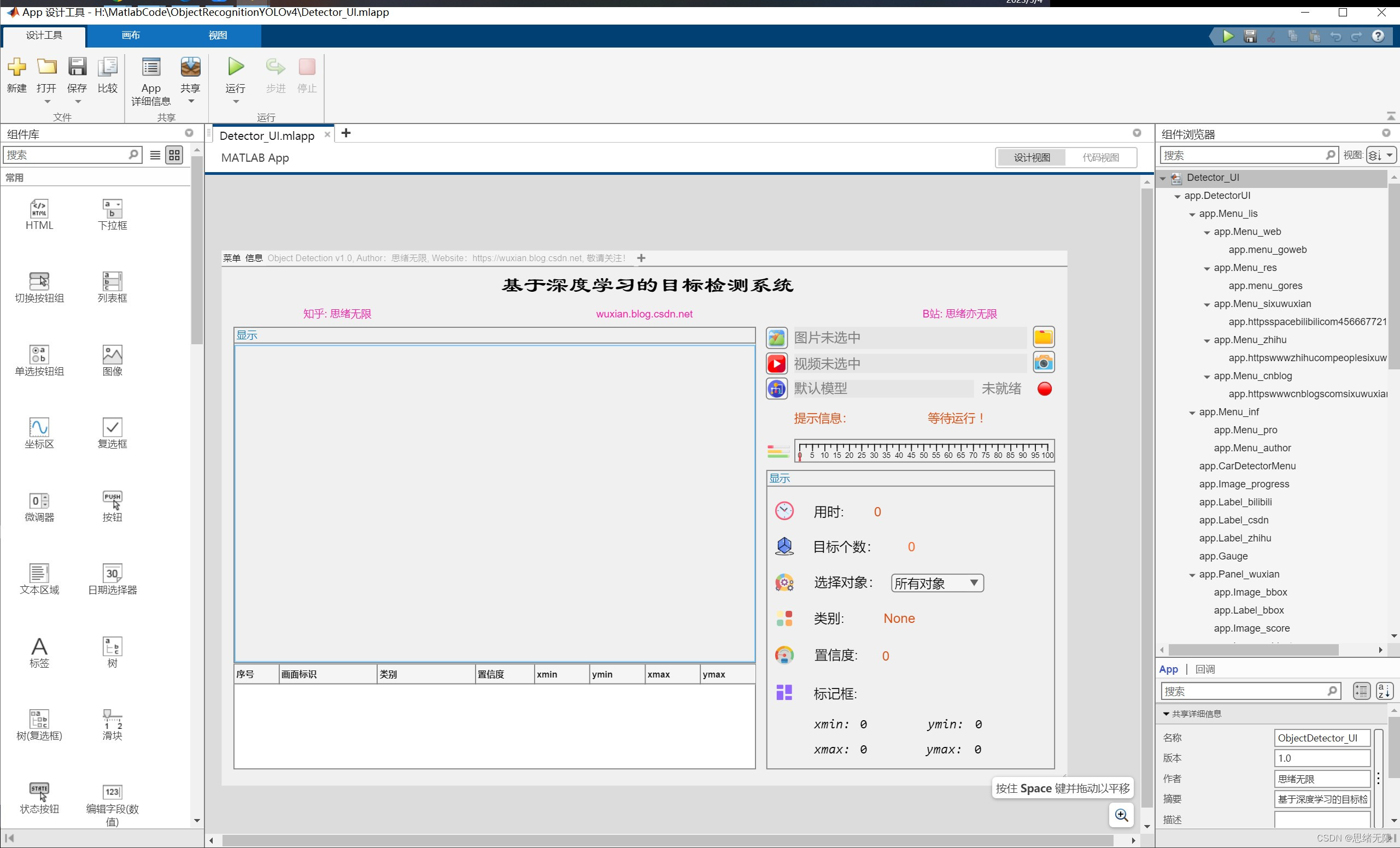
我們的GUI設計旨在為用戶提供一個簡潔、直觀的操作界面,主要元素包括選單欄、圖片顯示區域、引數設定區域和結果顯示區域,將這些元素布局得緊湊而有序,以便用戶能夠方便地進行圖片上傳、引數設定和結果查看,以下是GUI中涉及的主要控制元件:
- 圖片選擇按鈕:用戶點擊此按鈕后,系統將打開檔案選擇器以便用戶選擇一張圖片,選定圖片后,圖片將在影像顯示坐標系中展示,
- 視頻選擇按鈕:用戶點擊此按鈕后,系統將打開檔案選擇器以便用戶選擇一個視頻檔案,選定視頻后,視頻將在影像顯示坐標系中播放并實時顯示識別結果,
- 攝像頭開啟按鈕:用戶點擊此按鈕后,系統將開啟計算機攝像頭并實時捕獲視頻流,捕獲的視頻將在影像顯示坐標系中展示并實時顯示識別結果,
- 更換模型按鈕:用戶點擊此按鈕后,系統將彈出一個對話框,讓用戶選擇新的模型檔案,選定新模型后,系統將使用新模型進行后續的識別任務,
- 影像顯示坐標系:用于實時顯示用戶上傳的圖片、選定的視頻或捕獲的攝像頭視頻流,以及在影像上顯示識別結果,
- 結果顯示區域:用于展示檢測到的動物類別、置信度等資訊,用戶可以在這個區域查看識別結果,
為了實作GUI的互動功能,需要撰寫一系列回呼函式,以下是主要的回呼函式及其功能:
- 圖片選擇回呼函式:當用戶點擊圖片選擇按鈕時,此函式將被觸發,它負責打開檔案選擇器,讓用戶選擇一張圖片,并將圖片顯示在影像顯示坐標系中,
- 視頻選擇回呼函式:當用戶點擊視頻選擇按鈕時,此函式將被觸發,它負責打開檔案選擇器,讓用戶選擇一個視頻檔案,并在影像顯示坐標系中播放視頻,同時實時顯示識別結果,
- 攝像頭開啟回呼函式:當用戶點擊攝像頭開啟按鈕時,此函式將被觸發,它負責開啟計算機攝像頭,捕獲視頻流并在影像顯示坐標系中實時顯示識別結果,
- 更換模型回呼函式:當用戶點擊更換模型按鈕時,此函式將被觸發,它負責彈出一個對話框,讓用戶選擇新的模型檔案,并將新模型應用于后續的識別任務,
通過以上設計,實作了一個易于使用、功能齊全的圖形用戶界面,用戶可以通過這個界面方便地進行圖片上傳、視頻選擇、攝像頭開啟、模型更換和結果查看,從而實作動物識別任務,
6. 總結與展望
本文主要介紹了一種基于YOLOv4的目標檢測系統,首先,詳細闡述了資料集的標注格式及預處理程序,包括影像的標注、資料的劃分等,接著,使用 YOLOv4 檢測網路構建了動物識別模型,并詳細描述了訓練程序中的引數設定、錨框估計、資料增強等關鍵環節,隨后,討論了系統實作的關鍵技術,包括網路設計、GUI設計等,并展示了一個基于 MATLAB 的圖形用戶界面,方便用戶進行動物識別任務,
盡管本文所提出的動物識別系統已經取得了較好的效果,但仍存在一些可以改進和優化的地方,在未來的研究中,我們將關注以下幾個方面:
- 更豐富的資料集:為了提高模型的泛化能力,可以通過收集更多動物種類和場景的影像資料來擴展資料集,同時,可以嘗試使用半監督或無監督學習方法,以充分利用未標注資料,
- 更先進的檢測演算法:隨著深度學習技術的發展,可以嘗試將更先進的檢測演算法應用于動物識別任務中,以提高模型的準確性和實時性,
- 多模態資訊融合:考慮到動物識別程序中可能涉及多種模態資訊,如聲音、行為等,可以研究如何將這些資訊融合到模型中,以提高識別性能,
- 實時識別與跟蹤:針對實時視頻流的動物識別和跟蹤任務,可以研究更高效的演算法和技術,以降低延遲并提高跟蹤穩定性,
- 模型部署與優化:為了在不同平臺上實作高效的動物識別,可以研究模型壓縮、硬體加速等技術,以滿足不同場景的需求,
下載鏈接
若您想獲得博文中涉及的實作完整全部程式檔案(包括測驗圖片、視頻,mlx, mlapp檔案等,如下圖),這里已打包上傳至博主的面包多平臺,見可參考博客與視頻,已將所有涉及的檔案同時打包到里面,點擊即可運行,完整檔案截圖如下:
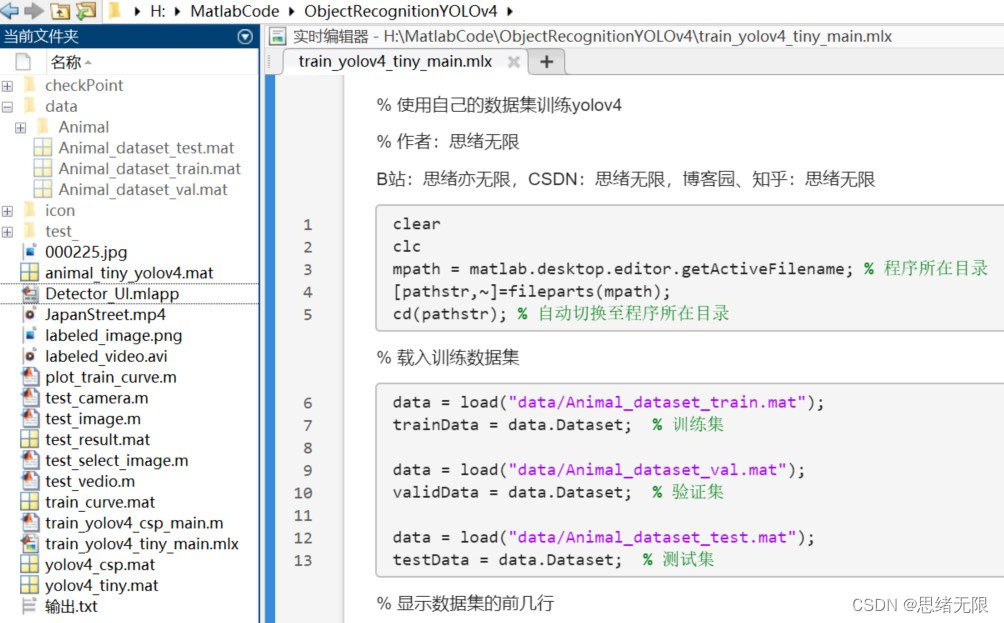
在檔案夾下的資源顯示如下圖所示:
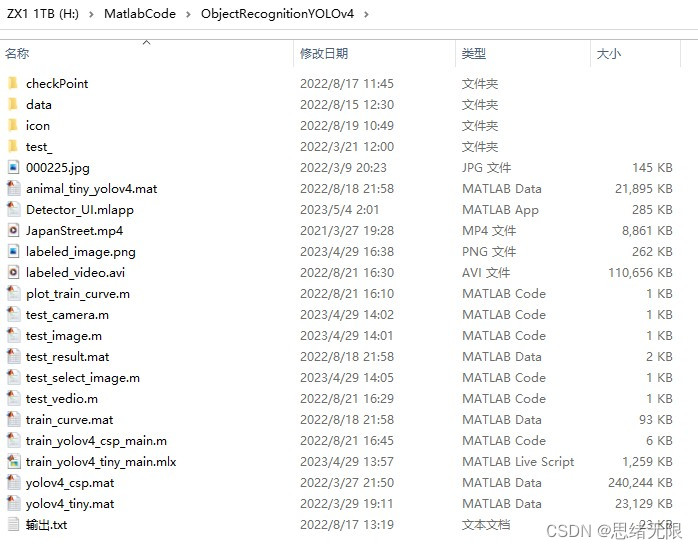
注意:該代碼采用MATLAB R2022a開發,經過測驗能成功運行,運行界面的主程式為Detector_UI.mlapp,測驗視頻腳本可運行test_video.m,測驗攝像頭腳本可運行test_camera.m,為確保程式順利運行,請使用MATLAB2022a運行并在“附加功能管理器”(MATLAB的上方選單欄->主頁->附加功能->管理附加功能)中添加有以下工具,
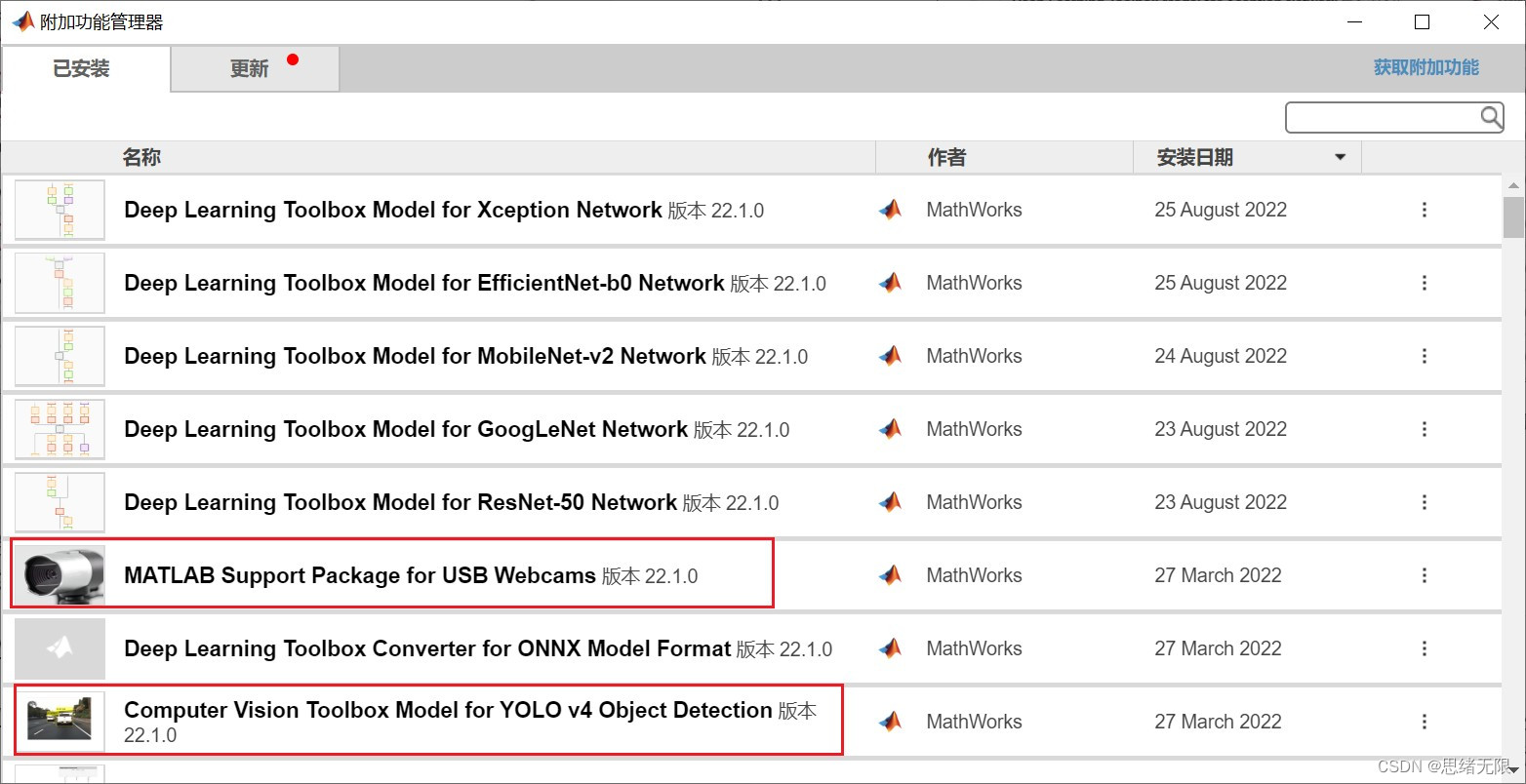
完整資源中包含資料集及訓練代碼,環境配置與界面中文字、圖片、logo等的修改方法請見視頻,專案完整檔案下載請見參考博客文章里面,或參考視頻的簡介處給出:???
參考博客文章:https://zhuanlan.zhihu.com/p/626659942/
參考視頻演示:https://www.bilibili.com/video/BV1ts4y1X71R/
結束語
任何絕對的宣告程式無Bug都是不可能的,盡管我們已經努力除錯程式,確保在目前的運行環境下沒有發現Bug,但計算機配置、作業系統、MATLAB版本等多種因素都可能影響程式的運行,如果在運行程序中遇到問題,希望讀者冷靜思考、認真檢查操作流程、科學合理尋找解決方案,不要讓浮躁和偏激影響了學習的熱忱,
由于博主能力有限,博文中提及的方法即使經過試驗,也難免會有疏漏之處,希望您能熱心指出其中的錯誤,以便下次修改時能以一個更完美更嚴謹的樣子,呈現在大家面前,同時如果有更好的實作方法也請您不吝賜教,
參考文獻
[1] Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 779-788).
[2] Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 580-587).
[3] Girshick, R. (2015). Fast R-CNN. In Proceedings of the IEEE international conference on computer vision (pp. 1440-1448).
[4] Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems (pp. 91-99).
[5] Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., & Berg, A. C. (2016). SSD: Single shot multibox detector. In European conference on computer vision (pp. 21-37). Springer, Cham.
[6] Lin, T. Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2017). Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision (pp. 2980-2988).
[7] Everingham, M., Van Gool, L., Williams, C. K., Winn, J., & Zisserman, A. (2010). The Pascal visual object classes (VOC) challenge. International journal of computer vision, 88(2), 303-338.
[8] Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., ... & Zitnick, C. L. (2014). Microsoft COCO: Common objects in context. In European conference on computer vision (pp. 740-755). Springer, Cham.
[9] Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., ... & Berg, A. C. (2015). Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3), 211-252.
[10] Redmon, J., & Farhadi, A. (2017). YOLO9000: better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7263-7271).
[11] Redmon, J., & Farhadi, A. (2018). YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767.
[12] Bochkovskiy, A., Wang, C. Y., & Liao, H. Y. M. (2020). YOLOv4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934.
[13] Geiger, A., Lenz, P., & Urtasun, R. (2012). Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3354-3361).
[14] Sindhu V S. Vehicle identification from traffic video surveillance using YOLOv4[C]//2021 5th International Conference on Intelligent Computing and Control Systems (ICICCS). IEEE, 2021: 1768-1775.
[15] Shewajo F A, Fante K A. Tile-based microscopic image processing for malaria screening using a deep learning approach[J]. BMC Medical Imaging, 2023, 23(1): 1-14.
[16] MathWorks. (2021). Object Detection Using YOLO v2 Deep Learning. Retrieved from https://www.mathworks.com/help/vision/ug/object-detection-using-yolo-v2-deep-learning.html.
人工智能博主,機器學習及機器視覺愛好者,公眾號主及B站UP主,專注專業知識整理與專案總結約稿、軟體專案開發、原理指導請聯系微信:sixuwuxian(備注來意),郵箱:[email protected],微信公眾號:“AI技術研究與分享”,轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551643.html
標籤:其他
上一篇:cPanel XSS漏洞分析研究(CVE-2023-29489)
下一篇:返回列表