感知機(Perceptron)
1.感知機模型
1.1感知機定義
? 輸入空間$ \mathcal{X} \subseteq \mathbb{R}^n$ ,輸出空間\(\mathcal{Y}\)={+1, -1} ;
? 輸入\(x \in \mathcal{X}\)表示的實體的特征向量,對應于輸入空間的點,輸出\(y \in \mathcal{Y}\)表示的實體的類別;
由輸入空間到輸出空間的如下函式:
? f(x) = sign($ \omega \cdot x$+b)
? \(\omega\) : 權值,b : 偏置;
? \(\omega \cdot x\) : \(\omega\)和x的內積;
? sign為符號函式;
1.2感知機幾何解釋
線性方程\(\omega \cdot x + b = 0\)對應于特征空間\(\mathbb{R}^n\)中的一個超平面S,其中ω是超平面的法向量,b是超平面的截距,這個超平面將特征空間劃分為兩個部分,位于兩部分的點分別被分為正負兩類,因此,S成為分類超平面,
2.感知機學習策略
2.1資料集的線性可分性
給定一個資料集T, 如果存在某個超平面S: \(\omega \cdot x + b = 0\)能夠將資料集的正實體點和負實體點完全正確的劃分到超平面的兩側,即yi\((\omega \cdot x + b) \ge 0\),則稱資料集T為線性可分資料集,
2.2 感知機的學習策略
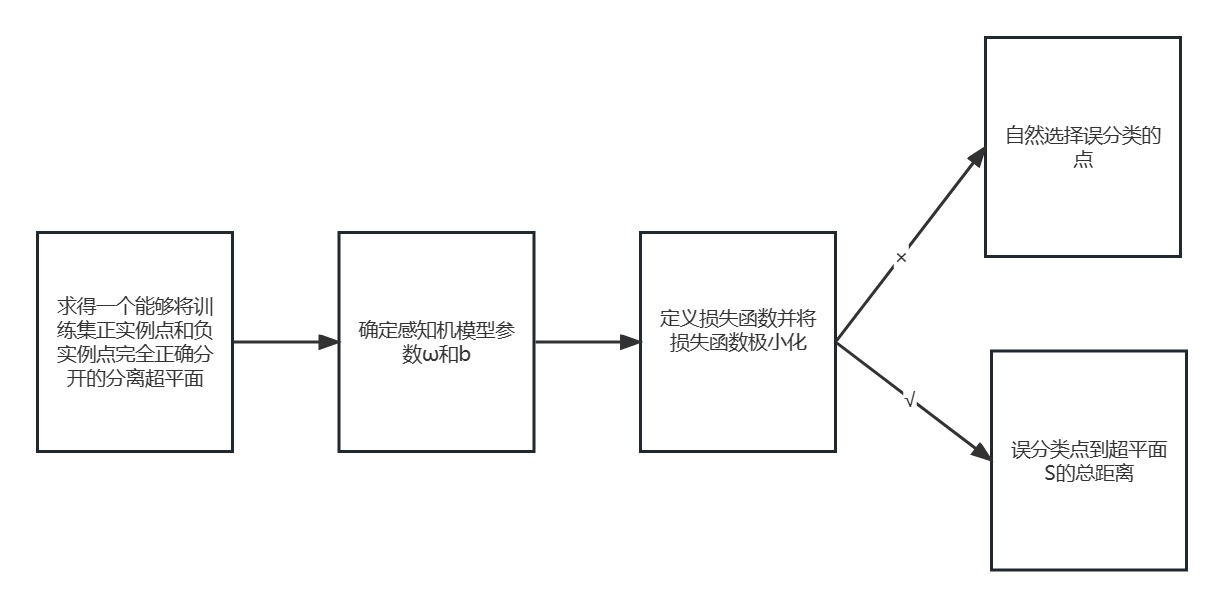
首先,輸入空間\(\mathbb{R}\)n 中任一點x0到超平面S的距離d:\(\frac{1}{||\omega||}|\omega \cdot x_0 + b|\)
證明如下:
在超平面S(\(\omega \cdot x + b = 0\))任選一點v1,所需公式\(\vec{v_0v_1} = ||v_0||||v_1||\cos\theta\)
? d = \(||\vec{v_0v_1}||\cos(\vec{v_0v_1}, \omega)\)
? = \(||\vec{v_0v_1}|| \frac{|\vec{v_0v_1} \cdot \omega|}{||\vec{v_0v_1}||||\omega||}\)
? = \(\frac{|(x_1 - x_0) \cdot \omega|}{||\omega||}\)
? = \(\frac{|-b - x_0\cdot \omega|}{||\omega||}\)
? = \(\frac{1}{||\omega||}|\omega \cdot x_0 + b|\)
其次,對于誤分類的資料(xi,yi)來說,\(-y_i(\omega \cdot x_i + b) > 0\),因此,誤分類點xi到超平面S的距離是\(-y_i\frac{1}{||\omega||}|\omega \cdot x_i + b|\),假設超平面S所有誤分類點的集合為M,則所有誤分類點的總距離為\(-\frac{1}{||\omega||}\sum_{x_i \in M}y_i|\omega \cdot x_i + b|\),因此可得出損失函式為\(L(\omega, b) = - \sum_{x_i \in M}y_i(\omega \cdot x_i + b)\)
2.3 感知機演算法
2.3.1原始形式(隨機梯度下降法)
輸入:訓練資料集T = {(x1, y1), (x2, y2), ....., (xN,yN)},其中\(x_i \in \mathcal{X} = \mathbb{R}^n\),\(y_i \in \mathcal{Y} = {+1, -1}, i = 1,2,...,N;\) 學習率\(\theta(0 < \theta \le 1);\)
輸出:\(\omega\),b;感知機模型\(f(x) = sign(\omega \cdot x + b),\)
程序:
? 1.選取初值ω0, b0;
? 2.在訓練集中選取資料(xi, yi);
? 3.如果\(y_i(\omega \cdot x_i + b) \le0\),\(\omega \leftarrow \omega + \theta y_ix_i\),\(b \leftarrow b+\theta y_i\),
? 4.轉至2,直至訓練集中沒有誤分類點,
注:感知機學習演算法由于采取不同的初值或選取不同的誤分類點,解可以不同,
2.3.2演算法的收斂性
證明:經過有限次迭代可以得到一個將訓練資料集完全正確劃分的分離超平面及感知機模型,
為了敘述與推導,\(\hat \omega = (\omega^T,b)^T, \hat x = (x^T, 1)^T,\hat \omega \cdot \hat x = \omega \cdot x + b\),
訓練資料集T = {(x1, y1), (x2, y2), ....., (xN,yN)},其中\(x_i \in \mathcal{X} = \mathbb{R}^n\),\(y_i \in \mathcal{Y} = {+1, -1}, i = 1,2,...,N;\) 則
? (1)存在滿足條件\(||\hat \omega_{opt}|| = 1\)的超平面\(\hat \omega_{opt} \cdot \hat x = \omega_{opt} \cdot x + b_{opt} = 0\) 將訓練資料集完全正確分開;且存在\(\gamma > 0\), 對所有的i= 1,2,...,N,\(y_i(\hat \omega \cdot \hat x) = y_i(w_{opt} \cdot x_i + b_{opt}) \ge \gamma\),
證明如下:
由于訓練集是線性可分的,故存在一分離超平面,不妨設改平面為\(\hat \omega \cdot \hat x = w_{opt} \cdot x_{opt} + b_{opt} = 0\),使\(||\hat \omega_{opt}|| = 1\),
于是對于所有有限的i,均有\(y_i(w_{opt} \cdot x_i + b_{opt}) > 0\),
取\(\gamma > 0\),則\(\gamma = min_{i}{(y_i(\omega_{opt} \cdot x_i+b_{opt}))}\),
所以,(1)得證,
? (2)令\(R = max_{1 \le i \le N}||\hat x||\),則在\(f(x) = sign(\omega \cdot x + b)\)在訓練資料集上的誤分類次數k滿足不等式\(k \le {(\frac{R}{\gamma})}^2\)
證明:\(\hat \omega_{k} \cdot \hat \omega_{opt} \ge k\gamma\eta\),$\hat w_{k} $是第k個誤分類點實體的擴充權重向量,
\(\hat \omega_k \cdot \hat \omega_{opt} = (\hat \omega_{k-1} + \eta y_i \hat x_i)\hat \omega_{opt} \\ \ge \hat \omega_{k-1} \cdot \hat \omega_{opt} + \eta \gamma \\ = (\hat \omega_{k-2} + \eta y_i \hat x_i)\hat \omega_{opt} \\ \ge \hat \omega_{k-2} \cdot \hat \omega_{opt} + \eta \gamma \\ \ge... \\ \ge k\eta\gamma\)
證明:\(||\hat \omega_{k}||^2 \le k \eta^2R^2\)
\(||\hat \omega_k||^2 = ||\hat \omega_k||^2 + 2\eta y_i \hat \omega_{k-1} \cdot \hat x_i + \eta^2||\hat x_i|| \\ \le ||\hat \omega_{k-1}||^2 + \eta^2||\hat x_i|| \\ \le ||\hat \omega_{k-1}||^2 + \eta^2R^2 \\ \le ||\hat \omega_{k-1}||^2 + 2\eta^2R^2 \\ \le ... \\ \le k\eta^2R^2\)
由上述可得,\(k\eta\gamma \le \hat \omega_k \cdot \hat \omega_{opt} \le ||\hat \omega_k|| ||\hat \omega_{opt}|| \le \sqrt k \eta R \rightarrow k^2\gamma^2 \le k R^2 \rightarrow k \le (\frac{R}{\gamma})^2\)
定理表明,誤分類次數k是有上界的,經過有限次搜索可以找到分離超平面,即當訓練資料集線性可分時,感知機學習演算法原始形式迭代時收斂的,
2.3.3 對偶形式
輸入:訓練資料集T = {(x1, y1), (x2, y2), ....., (xN,yN)},其中\(x_i \in \mathbb{R}^n\),\(y_i \in {+1, -1}, i = 1,2,...,N;\) 學習率\(\eta(0 < \eta \le 1);\)
輸出:\(\alpha\),b;感知機模型\(f(x) = sign(\sum_{j=1}^N \alpha_j y_j x_j \cdot x + b),\)
程序:
? 1.\(\alpha \leftarrow0, b \leftarrow 0\);
? 2.在訓練集中選取資料(xi, yi);
? 3.如果\(y_i(\sum_{j=1}^N \alpha_j y_j x_j \cdot x_i + b) \le0\),\(\alpha_i \leftarrow \alpha_i + \eta\),\(b \leftarrow b+\eta y_i\),
? 4.轉至2,直至訓練集中沒有誤分類資料,
注:Gram矩陣:訓練集中實體間的內積計算并以矩陣形式存盤,該矩陣為Gram矩陣,記為\(\mathtt{G} = [x_i \cdot x_j]_{N \ast N}\),
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/552628.html
標籤:其他
上一篇:云端煉丹,算力白嫖,基于云端GPU(Colab)使用So-vits庫制作AI特朗普演唱《國際歌》
下一篇:返回列表