摘要
將2D大核的成功推廣到3D感知具有挑戰性,因為:
- 1.處理3D資料的三次增加的開銷;
- 2. 資料的稀缺性和稀缺性給優化帶來了困難,
以前的作業通過引入塊共享權重,已經邁出了將內核大小從3 × 3 × 3尺度到7×7×7的第一步,但是,為了減少塊內的特征變化,它只使用了適度的塊大小,并沒有獲得像21 × 21 × 21這樣更大的核,為了解決這一問題,我們提出了一種新的方法,稱為LinK,以一種類似卷積的方式實作更大范圍的感知接受域,有兩個核心設計,第一種方法是用線性核生成器替代靜態核矩陣,該生成器只自適應地為非空體素提供權值,第二種方法是在重疊塊中重用預先計算的聚合結果,以降低計算復雜度,該方法成功地使每個體素在21 × 21 × 21的范圍內感知背景關系,在3D目標檢測和三維語意分割兩個基本感知任務上的大量實驗證明了該方法的有效性,值得注意的是,我們在nuScenes (LiDAR track)的3D檢測基準的公共排行榜上排名第一,這只是簡單地將LinK-based的backbone整合到基本檢測器CenterPoint中,我們還將強分割基線的mIoU在SemanticKITTI測驗集中提高了2.7%,代碼可以在https://github.com/MCG-NJU/LinK上找到,
簡介
有一個共識,一個大的感受野對許多下游的視覺任務有積極的貢獻,例如,Transformer[2,3]從自注意的全域關系中獲益良多,成為分類[2]、分割[4]、檢測[5]的領先課題,然而,自注意力并不是通往廣闊感受野的唯一途徑,之前的作業,如RepLKNet[6]和SLaK[7],研究了通過大型卷積核獲得大范圍資訊的潛力,它們與基于Transformer的方法取得了相似的結果,考慮到卷積算子對現有芯片架構更加友好,大的卷積核方法在實際應用中是有效的,這在3D感知中提出了一個直接的問題:大的卷積核的范式能否推廣到3D任務中?
答案是肯定的,LargeKernel3D[1]邁出了第一步,成功地實作了更好的分割和檢測指標,時間和空間的消耗是擴展程序中的核心問題,因為它們在3D任務中呈立方增長,LargeKernel3D[1]引入空間共享卷積核,將三維卷積核尺度擴大到7×7×7,限制引數量的快速增長,然而,與2D版相比,后者已經開發了龐大的31×31[6]甚至51×51 [7], 7×7×7似憾訓不夠大,因此只能受益于有限的背景關系,至少有兩個原因阻礙了它的尺寸擴展:第一,雖然引數數量在控制之下,但每個體素的總操作量仍在立方級增加;其次,其外部部分可以共享block-wise權重的假設太強而不能在較大的塊中良好地作業,因此,如何有效、高效地擴大三維核尺寸仍然是一個具有挑戰性的問題,
為了處理這些問題,我們提出了一種名為LinK的新方法,以類似卷積的方式實作更大范圍的感知,該方法由兩個核心設計組成,第一種方法是用線性核生成模塊替換靜態核權值,以便僅為那些非空區域提供權值,因為3D輸入非常稀疏,同時,該模塊是分層共享的,這避免了分配給空白空間的一些權重在一次迭代中未被優化的情況,第二種方法是在重疊的塊中重用預先計算的聚合結果,這使得計算復雜度與卷積核大小無關,換句話說,我們可以基于提議的LinK實作任意大小的內核,而開銷是一致的,本文方法與其他方法的簡單比較如圖1所示,
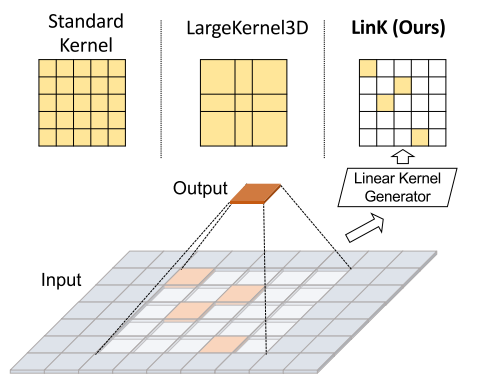
圖1,比較標準卷積核、LargeKernel3D的[1]塊共享卷積核和來自生成器的LinK卷積核,LinK沒有存盤密集的核矩陣,而是根據輸入資料在線生成稀疏核,可學習引數的數量不會隨著內核大小的增加而增加,這使得更大的內核可以按比例增加,
在3D檢測和語意分割任務的公共基準上的大量實驗證明了LinK的有效性,值得注意的是,我們在著名的3D檢測排行榜nuScenes (LiDAR track)[8]上獲得了第一名,只需用基于link的骨干取代經典檢測方法的骨干,對于分割任務,在SemanticKITTI測驗split[9]中,我們將強基線的mIoU提高了2.7%,我們將在下面幾節詳細介紹,
相關作業
略
方法
本節介紹我們方法的所有設計,我們首先從兩個背景來闡明3.1節中我們作業的創新之處,然后,在第3.2節中提供了詳細的程式,最后,我們將在3.3節中展示如何將提出的主干融合到兩個基本的3D感知任務中:目標檢測和語意分割,
3.1 背景
3.1.1 三維稀疏卷積入門
基于卷積的方法在預先指定的范圍內聚合加權影響,權值由卷積中心的區域相對位置確定,公式1為三維卷積算子的一般處理程序[14,15],
$$g_p=\sum\limits_{n\in\mathbb{N}}w_n\cdot f_{p+n},(1)$$
其中$p$是卷積中心,$\mathbb{N}$表示指定范圍內的非空鄰居,$f_{\ast}$和$g_{\ast}$分別是輸入和輸出特征,$w_n$為相對位置$n$對應的核,與二維影像不同,激光雷達資料具有空間稀疏性,這意味著分配給空體素的核將不會參與到卷積計算中,使得它們在反傳時不能被更新,這減慢了優化程序,同時,不管輸入是什么,每個位置的內核都必須為潛在的呼叫而存盤,這將導致大型3D內核中的引數數量呈立方倍增長,例如,對于一個內核大小為$21^3$,$C_{in}=32,C_{out}=64$的單個卷積層,有超過18M的可學引數在等待呼叫,盡管在推理程序中它們中的大多數將是空閑的,
3.1.2 Push-Pull策略介紹
卷積運算的核心功能是引入空間相互作用,當卷積視窗在feature map上滑動時,該視窗所覆寫的位置將被kernel計算,重疊區域重復參與計算,引入冗余,針對點云任務中的這一問題,APP-Net提出了一種所謂的APP算子,將空間互動分解為三個步驟:
- 1. 推: $\gamma\left(p_{i} \rightarrow\right. proxy)$,將 $ p_{i}$ 的特征推入各簇 (cluster) 共享的代理(proxy) 中;
- 2. 聚合:在代理中融合簇的資訊;
- 3. 拉: $\lambda\left(\operatorname{prox} y \rightarrow p_{j}\right) $,將每個點 $ p_{j}$ 從輔助代理中拉出特征,
3.2 三維線性核
根據3.1.1節,我們可以得出這樣的結論:存盤每個離散位置的內核值既不節約記憶體,也不利于三維大型核的優化程序,因此,我們提出采用神經網路模塊$w(n)$在線生成核,而不是存盤靜態核值$w_n$,這使得可學習引數的數量不會隨著核大小的增加而增加,此外,空體素不會減慢優化程序,
雖然解決了存盤成本和優化問題,但在3D大型內核中采用生成模塊仍存在挑戰,卷積核和特征圖之間的計算引入了立方次增加的開銷,為了解決這個問題,我們在以下幾個部分提供了兩個關鍵的設計:
- 線性核生成器(Linear Kernel Generator)
- 基于塊的聚合(Block Based Aggregation)
整個程序如圖2所示:
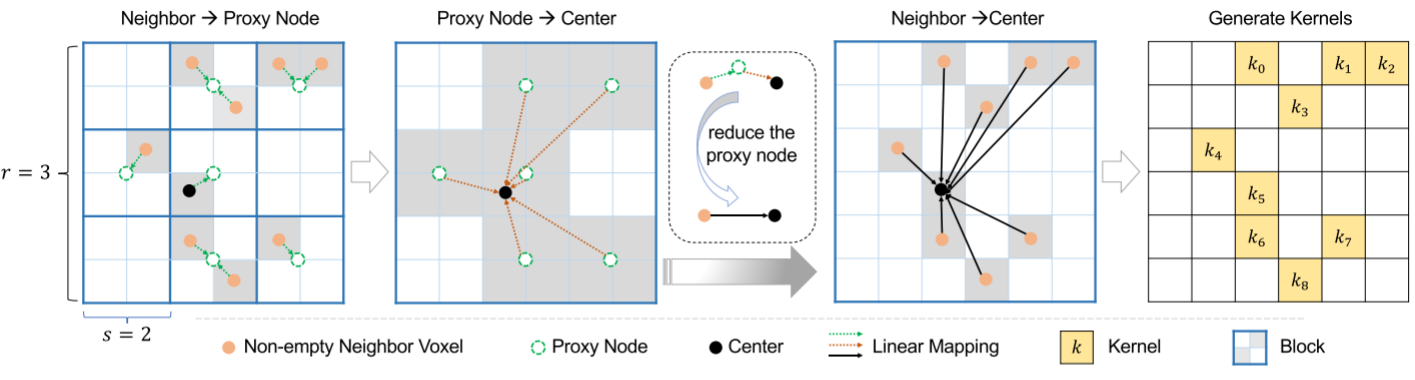
圖2, LinK的程序, 輸入被劃分成不重疊的塊(塊大小為$s^3$), 每個非空體素將其特征推送到block-wise proxy,然后中心體素只從neighbor proxies中提取特征(鄰居范圍為$r^3$), push和pull行程是以一種可簡化的方式驅動的(詳細資訊見3.2.2),這樣block-wise proxy就支持對每個潛在呼叫的重用, 得到的矩陣作為卷積核來對鄰居進行加權,
3.2.1 線性核生成器
更大的內核提取輸入資訊的代價是對每個區域進行更多的處理,我們致力于在重疊區域中尋找可重用的公共部件,以減少開銷,
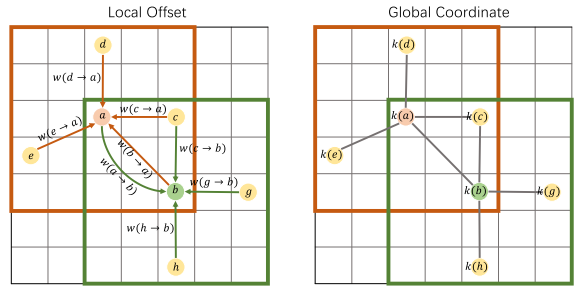
圖3,區域偏移建模與全域坐標建模的比較,$w(x?y)$通過建模$x$到$y$的偏移量主動度量$x$如何影響$y$,$k(x)$使用$x$的全域坐標生成$x$的核,當$y$查詢鄰居特征時,$x$和$y$之間的關系可以由$k(x)$和$k(y)$組成,
我們通過一個toy示例開始分析,給定兩個塊$A=\{a,b,c,d,e\}$和$B=\{a,b,c,g,h\}$,其中每個元素代表一個體素,重疊區域為$O = \{a, b, c\}$,如圖3所示,我們嘗試使用區域偏移將A的特征聚合為a, B的特征聚合為b,重疊部分的影響如下:
$$\left\{\begin{array}{l}{f_{O\rightarrow a}=w(a-a)f_{a}+w(b-a)f_{b}+w(c-a)f_{b}}\\ {f_{O\rightarrow b}=w(a-b)f_{a}+w(b-b)f_{b}+w(c-b)f_{c}}\\ \end{array}\right.$$
由上式公式(3)可知,O中的每個元素對a和b的貢獻使用了不同的偏移量,所以我們不能通過建模區域偏移量來重用重疊的聚合結果,
考慮到每個體素的全域坐標是固定且唯一的,我們考慮將區域偏移分解為全域坐標的組合,具體來說,我們首先定義一個新的kernel生成器,如下所示:
$$k(x)=\Psi(\sigma(x)),(4)$$
其中$\sigma(x)=W \times x$是一個線性映射函式,$W\in\mathbb{R}^{C_{in}\times3}$,$\Psi(*)$是一個激活函式,受APP-Net[26]的啟發,我們采用了三角函式作為激活函式,例如:
$$\{k^{(0)}(x)=\cos(\sigma(x)),k^{(1)}(x)=\sin(\sigma(x))\},(5)$$
由和積公式得到如下關系式:
$$k^{(0)}(x-y)=\cos(\sigma(x))\cdot\cos(\sigma(y))+\sin(\sigma(x))\sin(\sigma(y))=k^{(0)}(x)k^{(1)}(y)+k^{(1)}(x)k^{(0)}(y),(6)$$
其中$x$和$y$是全域坐標,$x?y$是區域偏移,公式(6)將區域偏移量分解為全域位置,
然后對重疊區域計算以下兩個輔助聚合:
$$\left\{\begin{array}{l}f_O^{(0)}=k^{(0)}(a)\cdot f_a+k^{(0)}(b)\cdot f_b+k^{(0)}(c)\cdot f_c,\\ f_O^{(1)}=k^{(1)}(a)\cdot f_a+k^{(1)}(b)\cdot f_b+k^{(1)}(c)\cdot f_c.\end{array}\right.\quad(7)$$
$f_O^{(0)}$和$f_O^{(1)}$在A和B之間可重用,因為它們是基于固定的全域位置計算的,為了得到中心體素a重疊區域的最終聚合,我們通過以下方式利用輔助聚合:
$$f_{O\to a}=f_O^{(0)}\cdot k^{(0)}(a)+f_O^{(1)}\cdot k^{(1)}(a)=\sum\limits_{p\in\mathcal{Q}}k^{(0)}(p-a)\cdot f_{a+(p-a)}\cdot(8)$$
結合公式(7)和公式(6),$f_{O\to a}$對區域偏移量進行建模,公式(8)是公式(1)中卷積算子的一個實體(使用$k^{(0)}(\ast )$替換$w(\ast )$),為了強調核心部分的線性映射,我們將此程序稱為Linear Kernel Generator,
3.2.2 基于塊的聚合
上面的線性核可以重用重疊的區域,然后又出現了一個新的問題:如何設定重疊區域?受ViT[2]的激勵,我們將整個輸入空間劃分為幾個非重疊塊,具體來說,對于輸入場景點云$P\in\mathbb{Z}^{N\times3}$,我們將每個體素$p$的坐標使用塊大小$s$來量化,并計算相應的哈希編碼$l$,如下所示:
$$l=Hash(\lfloor\frac{p(0)}{s}\rfloor,\lfloor\frac{p(1)}{s}\rfloor,\lfloor\frac{p(2)}{s}\rfloor).\quad(9)$$
擁有相同哈希碼的體素將被分組到相同的塊中,塊集合表示為$B = \{B_0, B_1,\cdots, B_m\}$,根據公式(7),我們進行了如下的block-wise proxy聚合來實作重用:
$$\left\{\begin{array}{l}f_{B_i}^{(0)}=\sum_{x\in B_i}k^{(0)}(x)\cdot f_x,\\ f_{B_i}^{(1)}=\sum_{x\in B_i}k^{(1)}(x)\cdot f_x.\end{array}\right.\quad(10)$$
則$f_{B_{i}}^{(0)}$與$f_{B_{i}}^{(1)}$含有$s^{3}$感受野內的資訊, 為增大感受野,為每個塊查詢$r^{3}$鄰域內塊的聚合結果,記塊$B_{i}$的鄰域塊集合為$\mathbb{B}_{i}$,則擴展塊聚合可按下式計算: $$\begin{aligned}&\begin{cases}\pmb{g}_{\mathbb{B}_i}^{(0)}=\sum_{j\in\mathbb{B}_i}f_{B_j}^{(0)},\\ \pmb{g}_{\mathbb{B}}^{(1)}=\sum_{j\in\mathbb{B}_i}f_{B_j}^{(1)}.\end{cases}&&& (11) \\
\end{aligned}$$ 其中$g_{\mathbb{B}_{i}}^{(0)}$和$g_{\mathbb{B}_{i}}^{(1)}$含有$(r \times s)^{3}$感受野內的資訊,對塊$B_{i}$內的體素$x$,最終的特征為: $$g_{x}=\frac{1}{N_{\mathbb{B}_{i}}}\left[g_{\mathbb{B}_{i}}^{(0)} \cdot k^{(0)}(x)+g_{\mathbb{B}_{i}}^{(1)} \cdot k^{(1)}(x)\right],(12)$$ 其中$N_{\mathbb{B}_{i}}$是非空體素數,則體素$x$以卷積方式聚合了其$(r \times s)^{3}$鄰域內的所有資訊,
3.2.3 內核生成的增強
為了增強表示,從不同的角度提出了兩種簡單的策略來改進內核生成,為了增強模型的能力,我們在基于cos和基于sin的激活模型的基礎上,引入了兩種改進方法:通道級的可學習引數$\alpha$來調整頻率,以及$\text{單位項}+x$來保留空間資訊,
增強的激活函式如下:
$$\Psi'(x)=\Psi(\alpha\cdot x)+x\quad(13)$$
分組共享權重,通過基于塊的聚合,有效的感受野得到了顯著的擴大,由于每個體素只對核的生成做出一次貢獻,大的核范圍使得學習每個偏移量的核很困難,為方便優化,我們采用分組共享策略,具體來說,對于$C_{i n}$個輸入通道,我們只生成$\frac{C_{i n}}{\#g r o u p s}$通道的核,并讓每個$\#groups$通道共享相同的權重,因此,每個權重將有更多的機會被更新,我們在實踐中使用$\#groups = 2$,
3.3 網路結構
3.3.1 LinK模塊
由于LinK以逐通道的方式聚合空間資訊,我們在將輸入特征發送給LinK算子之前對其進行$1\times1\times1$卷積,以引入通道混合[53,54],同時,按照之前的做法[1,6],我們添加了一個并行的$3\times3\times3$卷積分支,以保留詳細的結構,這個操作也穩定了優化程序,得到的架構如圖5所示,與LargeKernel3D[1]中的選擇不同,我們沒有為$3\times3\times3$分支采用$dilation > 1$,我們將BatchNormalization[55]替換為LayerNormalization[56],以加強這些資訊通道,
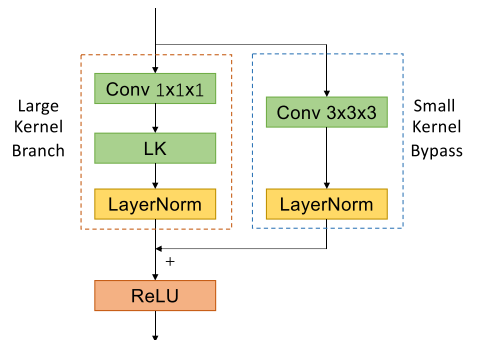
圖5,LinK模塊的結構,LK分支負責較大的內核大小,而Conv3 × 3 × 3旁路彌補了微妙的區域結構,
3.3.2 Applications in Perception Tasks
LinK被納入兩個基本的感知任務:三維物體檢測和三維語意分割,我們選擇了兩個有代表性的架構,這兩個任務,并直接取代他們的SparseConv為基礎的骨干為基于LinK的骨干,并保持其分割頭和檢測器的原始設計,詳細架構如圖4所示,
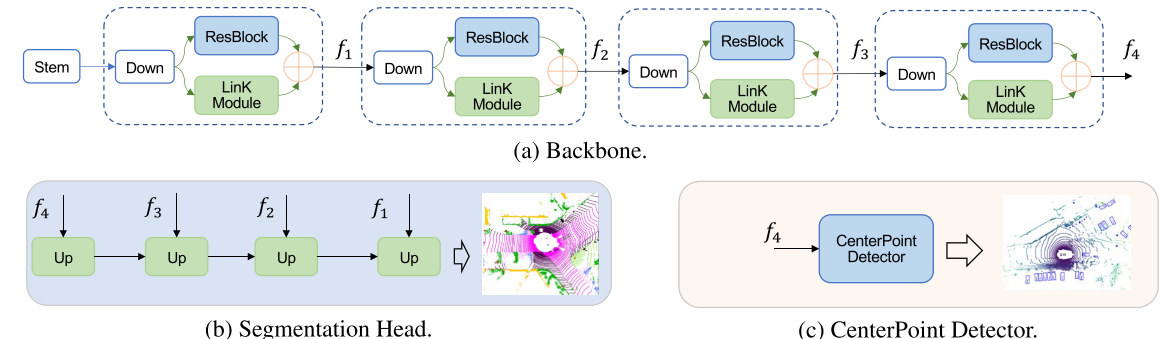
圖4,(a)基于LinK的骨干結構;(b)構建的三維語意分割網路;(c)構建的3D目標檢測網路,
4. 實驗
本文來自博客園,作者:辭柏LNG,轉載請注明原文鏈接:https://www.cnblogs.com/ymzcch12/p/17417760.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/553091.html
標籤:其他
上一篇:云原生周刊:2023 年可觀測性狀態報告發布 | 2023.5.22
下一篇:返回列表