摘要:輸入一個影像,通過Segment Anything模型即可獲得影像所有目標的分割點位置,再通過位置將影像進行分割保存,
本文分享自華為云社區《一鍵分割影像》,作者:雨落無痕 ,
Segment Anything
Segment Anything Model(SAM)通過點或框等輸入提示生成高質量的物件分割區域,并且可以用于為影像中的所有物件生成分割區域,它已經在1100萬張影像和11億個分割區域的資料集上進行了訓練,并且在各種分割任務上具有強大的零樣本性能,


SAM 的作業原理:可提示分割
在自然語言處理和最近的計算機視覺領域,最令人興奮的發展之一是基礎模型的發展,這些基礎模型可以使用提示技術(prompting)對新資料集和任務執行零樣本和小樣本學習,我們從這類作業中汲取了靈感,
我們訓練 SAM 為任何提示回傳有效的分割掩碼,其中提示可以是前景/背景點、粗框或掩碼、自由格式文本,或者一般來說,提示影像中要分割的內容的任何資訊,有效掩碼的要求僅僅意味著即使提示不明確并且可能指代多個物件(例如,襯衫上的一個點可能表示襯衫或穿著它的人),輸出也應該是一個合理的掩碼物件之一,此任務用于預訓練模型并通過提示解決一般的下游分割任務,
我們觀察到預訓練任務和互動式資料收集對模型設計施加了特定的限制,特別是,該模型需要在Web瀏覽器的CPU上實時運行,以允許我們的標注者實時互動地使用 SAM 以高效地進行標注,雖然運行時限制意味著質量和運行時之間的權衡,但我們發現簡單的設計在實踐中會產生良好的結果,具體地,影像編碼器為影像生成一次性嵌入向量,而輕量級編碼器將任何提示實時轉換為嵌入向量,然后將這兩個資訊源組合在一個預測分割掩碼的輕量級解碼器中,在計算影像嵌入后,SAM 可以在 50 毫秒內根據網路瀏覽器中的任何提示生成一個分割,
SAM模型總體上分為3部分:
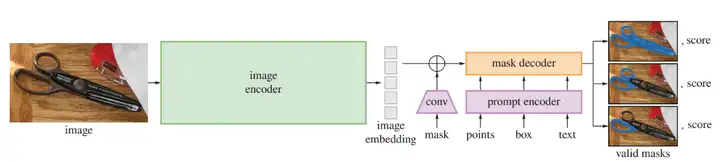
綠色的影像編碼器,基于可擴展和強大的預訓練方法,我們使用MAE預訓練的ViT,最小限度地適用于處理高解析度輸入,影像編碼器對每張影像運行一次,在提示模型之前進行應用,
紫色的提示編碼器,考慮兩組prompt:稀疏(點、框、文本)和密集(掩碼),我們通過位置編碼來表示點和框,并將對每個提示型別的學習嵌入和自由形式的文本與CLIP中的現成文本編碼相加,密集的提示(即掩碼)使用卷積進行嵌入,并通過影像嵌入進行元素求和,
橙色的提示編碼器,掩碼解碼器有效地將影像嵌入、提示嵌入和輸出token映射到掩碼,該設計的靈感來自于DETR,采用了對(帶有動態掩模預測頭的)Transformer decoder模塊的修改,
Segment Anything適配ModelArts
使用方法:
輸入一個影像,通過Segment Anything模型即可獲得影像所有目標的分割點位置,再通過位置將影像進行分割保存,
本案例需使用 Pytorch-1.8 GPU-P100 及以上規格運行
點擊Run in ModelArts,將會進入到ModelArts CodeLab中,這時需要你登錄華為云賬號,如果沒有賬號,則需要注冊一個,且要進行實名認證,參考《ModelArts準備作業_簡易版》 即可完成賬號注冊和實名認證,登錄之后,等待片刻,即可進入到CodeLab的運行環境
出現 Out Of Memory ,請檢查是否為您的引數配置過高導致,修改引數配置,重啟kernel或更換更高規格資源進行規避???
1.環境準備
為了方便用戶下載使用及快速體驗,本案例已將代碼及segment-anything預訓練模型轉存至華為云OBS中,模型下載與加載需要幾分鐘時間,
import os import torch import os.path as osp import moxing as mox path = osp.join(os.getcwd(),'segment-anything') if not os.path.exists(path): mox.file.copy_parallel('obs://modelarts-labs-bj4-v2/case_zoo/segment-anything', path) if os.path.exists(path): print('Download success') else: raise Exception('Download Failed') else: print("Model Package already exists!")
check GPU & 安裝依賴
大約耗時1min
%cd segment-anything !pip install --upgrade pip !pip install torch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 !pip install opencv-python matplotlib !python setup.py install import numpy as np import matplotlib.pyplot as plt import cv2 import copy import torch import torchvision print("PyTorch version:", torch.__version__) print("Torchvision version:", torchvision.__version__) print("CUDA is available:", torch.cuda.is_available())
2.加載模型
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor sam_checkpoint = "sam_vit_h_4b8939.pth" model_type = "vit_h" device = "cuda" sam = sam_model_registry[model_type](checkpoint=sam_checkpoint) sam.to(device=device) mask_generator = SamAutomaticMaskGenerator( model=sam, #points_per_side=32, #pred_iou_thresh=0.86, #stability_score_thresh=0.92, #crop_n_layers=1, #crop_n_points_downscale_factor=2, #min_mask_region_area=100, # Requires open-cv to run post-processing )
3.一鍵分割所有目標
def show_anns(anns,image): segment_image = copy.copy(image) segment_image.astype("uint8") if len(anns) == 0: return sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True) for ann in sorted_anns: mask_2d = ann['segmentation'] h,w = mask_2d.shape mask_3d_color = np.zeros((h,w,3), dtype=np.uint8) mask = (mask_2d!=0).astype(bool) rgb = np.random.randint(0, 255, (1, 3), dtype=np.uint8) mask_3d_color[mask_2d[:, :] == 1] = rgb segment_image[mask] = segment_image[mask] * 0.5 + mask_3d_color[mask] * 0.5 return segment_image image = cv2.imread('images/dog.jpg') image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) masks = mask_generator.generate(image) segment_image = show_anns(masks,image) fig = plt.figure(figsize=(25, 10)) ax1 = fig.add_subplot(1, 2, 1) plt.title('Original image', fontsize=16) ax1.axis('off') ax1.imshow(image) ax2 = fig.add_subplot(1, 2, 2) plt.title('Segment image', fontsize=16) ax2.axis('off') ax2.imshow(segment_image) plt.show()

4.保存所有分割的圖片
將所有識別出來的分割位置進行分割,并保存成圖片,
def apply_mask(image, mask, alpha_channel=True):#應用并且回應mask if alpha_channel: alpha = np.zeros_like(image[..., 0])#制作掩體 alpha[mask == 1] = 255#興趣地方標記為1,且為白色 image = cv2.merge((image[..., 0], image[..., 1], image[..., 2], alpha))#融合影像 else: image = np.where(mask[..., None] == 1, image, 0) return image def mask_image(image, mask, crop_mode_=True):#保存掩蓋部分的影像(感興趣的影像) if crop_mode_: y, x = np.where(mask) y_min, y_max, x_min, x_max = y.min(), y.max(), x.min(), x.max() cropped_mask = mask[y_min:y_max+1, x_min:x_max+1] cropped_image = image[y_min:y_max+1, x_min:x_max+1] masked_image = apply_mask(cropped_image, cropped_mask) else: masked_image = apply_mask(image, mask) return masked_image def save_masked_image(image, filepath): if image.shape[-1] == 4: cv2.imwrite(filepath, image, [cv2.IMWRITE_PNG_COMPRESSION, 9]) else: cv2.imwrite(filepath, image) print(f"Saved as {filepath}") def save_anns(anns,image,path): if len(anns) == 0: return sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True) index = 1 for ann in sorted_anns: mask_2d = ann['segmentation'] segment_image = copy.copy(image) masked_image = mask_image(segment_image, mask_2d) filename = str(index) + '.png' filepath = os.path.join(path, filename) save_masked_image(masked_image, filepath) index = index + 1 save_path = 'result/' if not os.path.exists(save_path): os.mkdir(save_path) image = cv2.imread('images/dog.jpg') masks = mask_generator.generate(image) save_anns(masks,image,save_path)
5. Gradio可視化部署
為了方便大家使用一鍵分割案例,當前增加了Gradio可視化部署案例演示,
運行如下代碼,Gradio應用啟動后可在下方頁面進行一鍵分割影像,您也可以分享public url在手機端,PC端進行訪問生成影像,
示例效果如下:
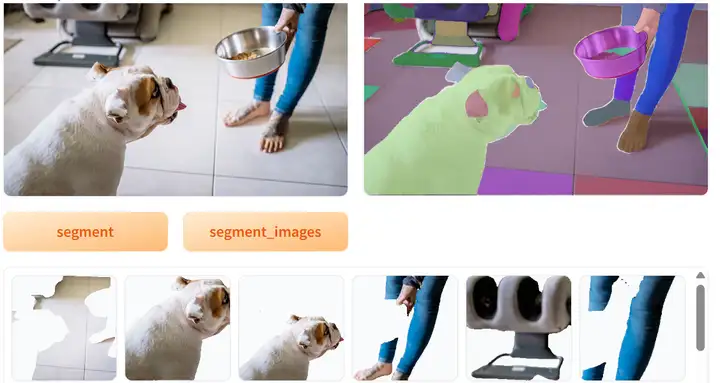
!pip install gradio==3.24.1 def segment_image(image): masks = mask_generator.generate(image) return show_anns(masks,image) def show_image(image): masks = mask_generator.generate(image) if len(masks) == 0: return sorted_anns = sorted(masks, key=(lambda x: x['area']), reverse=True) index = 1 image_list = [] for ann in sorted_anns: mask_2d = ann['segmentation'] segment_image = copy.copy(image) masked_image = mask_image(segment_image, mask_2d) image_list.append(masked_image) return image_list import gradio as gr with gr.Blocks() as demo: with gr.Row(): with gr.Column(): img_in = gr.Image(source='upload') with gr.Row(): segment_button = gr.Button("segment",variant="primary") save_button = gr.Button("segment_images",variant="primary") with gr.Row(): with gr.Column(): img_out = gr.Image() with gr.Row(): result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery").style(grid=6, height='auto') segment_button.click(segment_image, inputs= [img_in], outputs=[img_out]) save_button.click(show_image, inputs= [img_in], outputs=[result_gallery]) demo.launch(share=True)
相關鏈接:
Notebook案例地址:一鍵分割影像
AI Gallery:https://developer.huaweicloud.com/develop/aigallery/home.html
速來體驗!
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/553098.html
標籤:其他
上一篇:GPS北斗校時服務器(時間同步裝置)助力橋梁檢測系統建設
下一篇:返回列表