摘要:又雙叒叕種草了家裝新風格?想要嘗試卻又怕踩雷?如果能夠輕松Get量身定制的家裝風格圖,那該多好啊,現在,這一切都成為了可能!
本文分享自華為云社區《又雙叒叕種草了新家裝風格?AI幫你家居換裝!》,作者:Emma_Liu,
Control Stable Diffusion with M-LSD 修改建筑及家居裝修風格
你是否曾經想過,如果能夠輕松地看到自己家居的不同風格,該有多好呢?現在,這一切都變得可能了!
讓你的眼睛仔細觀察這些圖片,你會發現它們展現了不同的風格和氛圍,從現代簡約到古典優雅,從溫馨舒適到時尚前衛,應有盡有,但是,你知道嗎?這些圖片都是由AI生成的!

它們看起來非常逼真,仿佛是真實的照片一樣,這就是人工智能的奇妙之處,讓我們可以輕松地預覽不同的家居風格,不必實際進行裝修,讓我們一起來感受AI技術的魅力吧!
裝修風格參考

現代極簡風臥室
圖一是原圖,我要基于圖一的裝修布局重新裝修一下,圖二是M-LSD線段檢測器的輸出影像,圖三是加入prompt為:現代極簡風臥室生成影像,圖四再補充一些prompt:現代極簡風臥室,床是黃色的,墻是淺咖色,不得不說效果真不錯!

衛生間
圖一這種簡單布局的衛生間我很是喜歡,康康其他風格的侘寂風衛生間 - 圖二、三

客廳
換裝ing——奶油風客廳——無名(不填prompt也可以生成不錯的圖片,很多驚喜誒)

別墅
我已經在幻想住上大別墅了?看看別墅的效果怎么樣
浪漫的海邊別墅、新中式別墅

我想嘗試用建筑設計圖來看看能不能生成…哇,絕絕子——簡約風,現代風

其他建筑
建模圖變——歐式建筑

廠房變辦公樓、大型超市、別墅(這樣式的別墅)

好神奇,它是怎么做到的呢,來看看模型的介紹,
0.模型介紹
建筑的穩定擴散 | ControlNet模型-MLSD,隨意創建建筑物、房間內部或外部以及獨特的場景
ControlNet 最早是在L.Zhang等人的論文《Adding Conditional Control to Text-to-Image Diffusion Model》中提出的,目的是提高預訓練的擴散模型的性能,它引入了一個框架,支持在擴散模型 (如 Stable Diffusion ) 上附加額外的多種空間語意條件來控制生成程序,為穩定擴散帶來了前所未有的控制水平,
Mobile LSD (M-LSD): 《Towards Light-weight and Real-time Line Segment Detection》是用于資源受限環境的實時和輕量級線段檢測器,M-LSD利用了極其高效的LSD體系結構和新的訓練方案,包括SoL增強和幾何學習方案,模型可以在GPU、CPU甚至移動設備上實時運行,
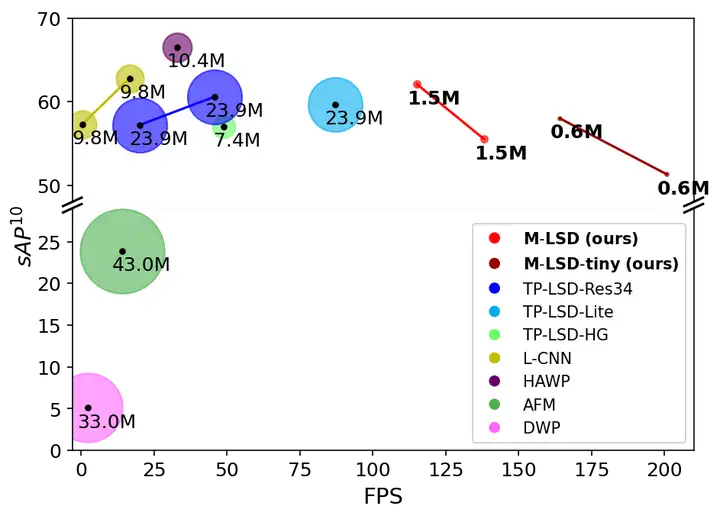
圖1 GPU上M-LSD和現有LSD方法的比較
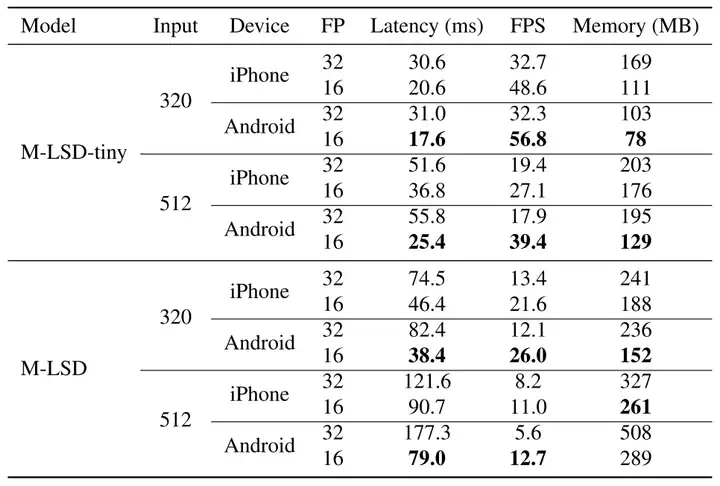
圖2 移動設備上的推理速度和記憶體使用情況.
案例以分享至AI Gallery - AI建筑風格修改: ControlNet-MLSD,一起來運行代碼,實作你的新裝吧,
1.裝包
!pip install transformers==4.29.0 !pip install diffusers==0.16.1 !pip install accelerate==0.17.1 !pip install gradio==3.32.0 !pip install translate==3.6.1
2.下載模型
使用mlsd, sd-controlnet-mlsd, stable-diffusion-v1-5預訓練模型,為方便大家使用,已轉存到華為云OBS中,
import os import moxing as mox pretrained_models = ['mlsd', 'sd-controlnet-mlsd', 'stable-diffusion-v1-5'] for pretrained_model in pretrained_models: model_dir = os.path.join(os.getcwd(), pretrained_model) if not os.path.exists(model_dir): mox.file.copy_parallel(f'obs://modelarts-labs-bj4-v2/case_zoo/ControlNet/ControlNet_models/{pretrained_model}', model_dir) if os.path.exists(model_dir): print(f'{pretrained_model} download success') else: raise Exception(f'{pretrained_model} download Failed') else: print(f"{pretrained_model} already exists!")
3.加載模型
import torch from PIL import Image from mlsd import MLSDdetector from translate import Translator from diffusers.utils import load_image from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler mlsd = MLSDdetector() controlnet = ControlNetModel.from_pretrained("sd-controlnet-mlsd", torch_dtype=torch.float16) pipe = StableDiffusionControlNetPipeline.from_pretrained("stable-diffusion-v1-5", controlnet=controlnet, safety_checker=None, torch_dtype=torch.float16) pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config) pipe.enable_model_cpu_offload()
4.生成影像
首先,傳入的圖片會通過mlsd detector輸出黑白線條圖,然后基于此mlsd影像,通過controlnet和stable diffusion生成影像,
from PIL import Image import matplotlib.pyplot as plt import numpy as np ori = Image.open("1920245540.jpg") mlsd = MLSDdetector() mlsd_img = mlsd(ori, thr_v=0.1, thr_d=0.1, detect_resolution=512, image_resolution=512, return_pil=True) trans = Translator(from_lang="ZH",to_lang="EN-US") prompt = "現代極簡風臥室,床是黃色的,墻是淺咖色" en_prompt = trans.translate(prompt) gen_img = pipe(en_prompt, mlsd_img, num_inference_steps=20).images[0] fig = plt.figure(figsize=(25, 10)) ax1 = fig.add_subplot(1, 3, 1) plt.title('Orignial image', fontsize=16) ax1.axis('off') ax1.imshow(ori) ax2 = fig.add_subplot(1, 3, 2) plt.title('ML Detector image', fontsize=16) ax2.axis('off') ax2.imshow(mlsd_img) ax3 = fig.add_subplot(1, 3, 3) plt.title('Generate image', fontsize=16) ax3.axis('off') ax3.imshow(gen_img) plt.show()
5.Gradio可視化部署
Gradio應用啟動后可在下方頁面上傳圖片根據提示生成影像,您也可以分享public url在手機端,PC端進行訪問生成影像,
引數說明
img_path:輸入影像路徑
prompt:提示詞(建議填寫)
n_prompt: 負面提示(可選)
num_inference_steps: 采樣步數,一般15-30,值越大越精細,耗時越長
image_resolution: 對輸入的圖片進行最長邊等比resize
detect_resolution:Hough Resolution,檢測解析度,值越小-線條越粗糙
value_threshold: Hough value threshold (MLSD),值越大-檢測線條越多,越詳細
distance_threshold: Hough distance threshold (MLSD),值越大-距離越遠,檢測到的線條越少
對比一下引數value_threshold,distance_threshold,當value_threshold值變大時,如圖二所示,檢測到的線段越少,獲取到的資訊也就越少,對控制生成后的影像來說,會缺失掉很多的細節;當distance_threshold值變大時,如圖三所示,越遠處的物體,提取到的線段越少,影像會更專注于前面的部分,這對于來調整生成的影像是一個很好的參考,

thr_v=0.1, thr_d=0.1

thr_v=0.5, thr_d=0.1
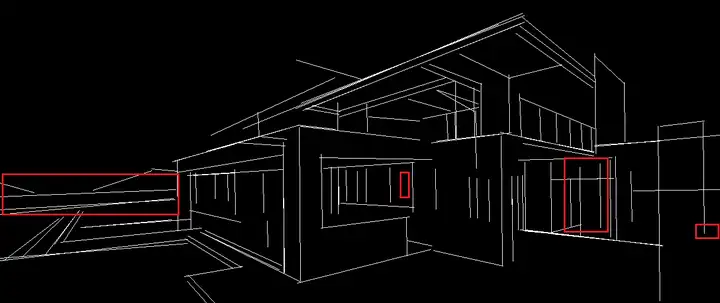
thr_v=0.1, thr_d=20
import gradio as gr def mlsd(img, prompt, num_inference_steps, thr_v, thr_d, n_prompt, detect_resolution, image_resolution): trans = Translator(from_lang="ZH",to_lang="EN-US") prompt = trans.translate(prompt) n_prompt = trans.translate(n_prompt) mlsd = MLSDdetector() mlsd_img = mlsd(img, thr_v=0.1, thr_d=0.1, detect_resolution=512, image_resolution=512, return_pil=True) gen_img = pipe(prompt, mlsd_img, num_inference_steps=20, negative_prompt=n_prompt).images[0] result = [mlsd_img, gen_img] return result block = gr.Blocks().queue() with block: with gr.Row(): gr.Markdown("## Control Stable Diffusion with MLSD") with gr.Row(): with gr.Column(): input_image = gr.Image(source='upload', type="numpy") prompt = gr.Textbox(label="描述") run_button = gr.Button(label="Run") with gr.Accordion("高級選項", open=False): num_inference_steps = gr.Slider(label="影像生成步數", minimum=1, maximum=100, value=https://www.cnblogs.com/huaweiyun/p/20, step=1) value_threshold = gr.Slider(label="Hough value threshold (MLSD)", minimum=0.01, maximum=2.0, value=https://www.cnblogs.com/huaweiyun/p/0.1, step=0.01) distance_threshold = gr.Slider(label="Hough distance threshold (MLSD)", minimum=0.01, maximum=20.0, value=https://www.cnblogs.com/huaweiyun/p/0.1, step=0.01) n_prompt = gr.Textbox(label="否定提示", value='lowres, extra digit, fewer digits, cropped, worst quality, low quality') detect_resolution = gr.Slider(label="Hough Resolution", minimum=128, maximum=1024, value=https://www.cnblogs.com/huaweiyun/p/512, step=1) image_resolution = gr.Slider(label="Image Resolution", minimum=256, maximum=768, value=https://www.cnblogs.com/huaweiyun/p/512, step=64) with gr.Column(): result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery").style(columns=2, height='auto') ips = [input_image, prompt, num_inference_steps, value_threshold, distance_threshold, n_prompt, detect_resolution, image_resolution] run_button.click(fn=mlsd, inputs=ips, outputs=[result_gallery]) block.launch(share=True)
參考文獻
- Paper: 《Adding Conditional Control to Text-to-Image Diffusion Model》
- Paper: 《Towards Light-weight and Real-time Line Segment Detection》
- Model:sd-controlnet-mlsd, stable-diffusion-v1-5
- 案例代碼地址:AI Gallery - AI建筑風格修改: ControlNet-MLSD 免費體驗
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/554166.html
標籤:其他
上一篇:自然語言處理(NLP) - 前預訓練時代的自監督學習
下一篇:返回列表