正則化
虛擬對抗訓練是一種正則化方法,正則化在深度學習中是防止過擬合的一種方法,通常訓練樣本是有限的,而對于深度學習來說,搭設的深度網路是可以最大限度地擬合訓練樣本的分布的,從而導致模型與訓練樣本分布過分接近,還把訓練樣本中的一些噪聲也擬合進去了,甚至于最極端的,訓練出來的模型只能判斷訓練樣本,而測驗樣本變成了隨機判斷,所以為了讓模型泛化地更好,正則化是很有必要的,
最常見的正則化是直接對模型的引數的大小進行限制,比如將引數(整合為向量$\theta$)的$L_2$范數:
$\displaystyle J(\theta)=\frac{1}{n}\sum\limits_i^n\theta_i^2$
作為正則項加入損失函式中,得到總的損失函式:
$\displaystyle L(\theta)=\frac{1}{N}\sum\limits_{i=1}^NL(y_i, x_i,\theta) + \lambda J(\theta)$
從而約束引數不會很大而過于復雜,使模型符合奧卡姆剃刀原理:所有合適的模型中應該選擇最簡單的那個,
然而,這種正則化僅僅符合了奧卡姆剃刀而已,而且它的定義是很模糊的,因為你不知道什么模型才是“簡單”的,而且僅僅用范數來限制也不一定就會產生“簡單”的模型,甚至于,“簡單”的模型也未必就是泛化能力強的模型,
對抗訓練
相較于范數型別的正則項,論文中參考了另一篇論文,這篇論文從另一個角度來看待正則化,基于這樣一個假設$A$:對于輸入樣本的微小變動,模型對它的預測輸出也應該不會有很大的改變,這個對于連續函式來說是理所當然的(排除一些梯度特別大的連續函式),但是對于一些神經網路模型來說,它們內部層與層之間的互動是有閾值的,超過這個閾值才能把資訊傳到下一層,導致函式不連續,從而輸入的微小改變就會對后面的輸出產生巨大的影響(論文中指出,僅僅使用$L_p$范數做正則項就容易產生這樣的問題),它的正則項定義如下:
$\displaystyle J(\theta) = \frac{1}{N}\sum\limits_{i=1}^NL_{adv}(x_i,\theta)$
${\rm where}\,L_{adv}(x_i,\theta) = D[q(y|x_i),p(y|x_i+r_{adv_i},\theta)]$
${\rm where}\,r_{adv_i}= \mathop{\arg\max}\limits_{r;||r||_2\leq\epsilon} D[q(y|x_i),p(y|x_i+r,\theta)]$
這個公式假設模型是生成模型,因為判別模型可以轉化為生成模型,所以不另外添加公式了,其中,$D[q,p]$表示分布$q$和$p$的差異,用交叉熵、相對熵(KL散度)等表達;$q(y|x_i)$表示訓練樣本$x_i$的標簽真實分布;$p(y|x_i,\theta)$表示模型引數為$\theta$時對$x_i$的標簽預測分布;$r_{adv_i}$表示能使$x_i$預測偏差最大化的擾動向量(范數很小),
因此,這個正則項的定義就是:在每一個訓練樣本點的周圍(固定范圍$\epsilon$),找一個預測分布和這個樣本點標簽的真實分布相差最大的樣本點($x_i+r_{adv_i}$),然后優化模型引數$\theta$來減小這個偏差,在每一次迭代優化$\theta$減小損失函式$L(\theta)$之前,都要先計算一次$r_{adv_i}$,即獲取當前$\theta$下使每個$x_i$偏差最大的擾動向量,進而獲取當前擾動的最大偏差作為正則項,如此看來好像是在對抗損失函式的減小,因此叫對抗訓練,而 $r_{adv_i}$則叫對抗方向,
因為實際上樣本點的真實連續分布并不能獲得,所以使用離散的概率來作為分布,論文中使用one hot vector $h(y=y_{real})$來表達,這個向量是一串0-1編碼,真實標簽對應的向量元素為1,其它向量元素都為0,比如標簽有:貓、狗、汽車,則$h(y = 狗)=[0,1,0]$,使用one hot vector的好處之一就是切斷了不同標簽之間在連續數值上的聯系,
于是我們很容易能想到,對抗方向應該在$L_{adv}(x_i,\theta) $對$x_i$求梯度時能取到近似(因為在梯度方向函式變化率最大),即:
$\displaystyle r_{adv_i}\approx\epsilon\frac{g_i}{||g_i||_2},\,{\rm where}\,g_i=\nabla_{x}D[h(y=y_{x_i}),p(y|x,\theta)]|_{x=x_i}$
因為需要訓練樣本的真實標簽分布,所以對抗訓練只適用于監督學習,
論文指出,使用對抗方向來進行擾動的表現是比隨機擾動要好的,隨機擾動就是在$x_i$周圍$\epsilon$內隨機找一個較小的擾動$r_{rad_i}$代替$r_{adv_i}$,盡管隨機擾動的目標也是假設A,但是最終的訓練結果是比對抗擾動差很多的,
虛擬對抗訓練
虛擬對抗訓練(VAT Visual adversarial training)是基于對抗訓練改進的正則化演算法,它主要對對抗訓練進行了兩個地方的改進:
區域平滑度
在$L_{adv}(x_i,\theta)$定義中的標簽真實分布$q(y|x_i)$被換成了當前迭代下的標簽預測分布$p(y|x_i,\hat{\theta})$($\hat{\theta}$表示當前梯度下降下的$\theta$的具體值,而$\theta$則是在損失函式中用來求梯度進行梯度下降的自變數),另外還給$L_{adv}(x_i,\theta)$換了個名字——LDS(Local distributional smoothness 區域分布平滑度),定義如下:
${\rm LDS}(x_i,\theta) = D[p(y|x_i,\hat{\theta}),p(y|x_i+r_{vadv_i},\theta)]$
$\,{\rm where}\,r_{vadv_i}=\mathop{\arg\max}\limits_{r;||r||_2\leq\epsilon} D[p(y|x_i,\hat{\theta}),p(y|x_i+r,\hat{\theta})]$
我們可能會疑惑,為什么計算$r_{vadv}$用$\hat{\theta}$,而不用$\theta$,明顯用$\theta$更精確,論文中也沒有給出明確的說明,可能它忘了說明這一點,不過這個細節也的確不容易察覺,在后面我會說一下我的理解,
可以發現,${\rm LDS}(x_i,\theta)$并不需要$x_i$的標簽真實分布,所以即使$x_i$是沒有真實標記的樣本點,同樣可以加入訓練,因此VAT不但適用于監督學習,還適用于半監督學習,以下是使用VAT的簡化的損失函式($\mathcal{D_l,D_{ul}}$分別為有標記樣本和無標記樣本集):
$\displaystyle L(\theta)=\sum\limits_{(x,y)\in\mathcal{D_l}}L(y, x,\theta) +\lambda \frac{1}{N_l+N_{ul}}\sum\limits_{x\in\mathcal{D_l,D_{ul}}}{\rm LDS}(x,\theta)$
快速計算rvadv
對于計算$r_{vadv}$,論文并不直接使用關于$x_i$的梯度,因為顯然$D[p(y|x_i,\hat{\theta}),p(y|x_i+r,\hat{\theta})]$在$r=0$時,兩個分布完全相同,熵為0,如果可導,那么$x_i$就在極小值點上,從而梯度為0,于是論文換了一個思考角度,要求$D(r,x_i,\hat{\theta})$(簡化寫法)最大化,不一定只能從梯度的角度考慮,將它關于$r$在0處進行泰勒展開后,因為一階導數(梯度)為0,發現有如下近似:
$\displaystyle D(r,x_i,\hat{\theta})\approx\frac{1}{2}r^THr+O(r^2)$
其中$O(r^2)$是$r^2$的高階無窮小,$H=\nabla\nabla_rD(r,x_i,\hat{\theta})|_{r=0}$是Hessian矩陣,由Hessian矩陣的定義可知,該矩陣是實對稱矩陣,一定有對應維數個相互線性無關的特征向量,由特征值和特征向量的定義得,對于范數大小固定的$r$,當$r$是最大特征值對應的特征向量時,能取得$r^THr$最大,又因為$r$的范數很小,后面的高階無窮小可以忽略不計,相應地,$D(r,x_i,\hat{\theta})$也取得最大,所以:
$r_{vadv}\approx\mathop{\arg\max}\limits_{r;||r||_2\leq\epsilon}r^THr=\epsilon\overline{u}$
其中$\overline{u}$表示$H$的最大特征值對應的單位特征向量,但是,計算高維的Hessian矩陣是很困難的,更不用說再計算它的特征值和特征向量了,所以,論文使用冪法(冪迭代法,具體演算法看此鏈接)來計算矩陣最大特征值對應的特征向量,即隨機取一個同維度的向量$d$(假設用特征向量表達$d$時,$u$的系數不為0),進行以下迭代:
$d=\overline{Hd}$
迭代到后期,$d$會無限接近于$\overline{u}$,然后,論文又用所謂的有限差分法,來避免計算 Hessian矩陣,有限差分法就是用所謂的差商代替微商來近似計算導數,差商就是用比較小的因變數除以對應的自變數,微商就是用因變數的極限(無限小)除以對應自變數的極限,于是,0處的“二階導數”$H$乘上一個較小的自變數$\xi d$,就可以近似0到$\xi d$處的一階導數(梯度)的變化量:
$\xi Hd\approx\nabla_rD(r,x_i,\hat{\theta})|_{r=\xi d}-\nabla_rD(r,x_i,\hat{\theta})|_{r=0}$
由于$r=0$處的梯度為0:
$\displaystyle Hd\approx\frac{\nabla_rD(r,x_i,\hat{\theta})|_{r=\xi d}}{\xi}$
所以迭代式變為:
$d=\overline{\nabla_rD(r,x_i,\hat{\theta})|_{r=\xi d}}$
論文中實驗,迭代一次就能獲取很好的近似$u$的效果,即:
$\displaystyle r_{vadv}\approx\epsilon\frac{g}{||g||_2}$
${\rm where}\,g=\nabla_rD[p(y|x_i,\hat{\theta}),p(y|x_i+r,\hat{\theta})]|_{r=\xi d}$
我覺得迭代一次的原因應該是:相較迭代獲取精度更高的虛擬對抗方向,計算力省下來用于梯度下降,更快地收斂整個模型更好,或者梯度下降前期迭代近似$r_{vadv}$次數少一些,后期再逐漸增加迭代次數增加收尾時的精度,
說一下我對為什么要用$\hat{\theta}$,而不用$\theta$的理解,因為需要計算$r=\xi d$處的梯度并進行迭代,如果使用不能當具體數值參與計算的引數$\theta$,就只能把整個迭代寫成一次性計算的算式形式了,而且不能動態改變迭代的次數,并且隨著迭代次數增多,引數$\theta$的數量會指數式上升,當然,如果和上面一樣只迭代一次,我覺得是可以使用$\theta$的,不過論文第6頁左上角好像說明了這點,當時沒看懂,說的應該就是這個意思:

額外正則項
另外,在實驗中,論文除了LDS正則項外,還添加了條件熵作為額外的正則項,定義如下:
$\displaystyle\mathcal{H}(Y|X)=-\frac{1}{N_l+N_{ul}}\sum\limits_{x\in \mathcal{D_l,D_{ul}}}\sum\limits_{y}p(y|x,\theta)\log p(y|x,\theta)$
表示除了相似輸入應該有相似輸出外(減小LDS),輸出標簽的概率分布還應該越集中越好(減小$\mathcal{H}(Y|X)$),因為在$X$條件下$Y$的混亂度(熵)代表了輸出概率分布的不集中度的平均值,所以優化條件熵越小,輸出概率分布越集中、越確定,而預測地越明確越好自然是我們想要的,
VAT效果
下圖展示了使用VAT進行半監督訓練的程序:
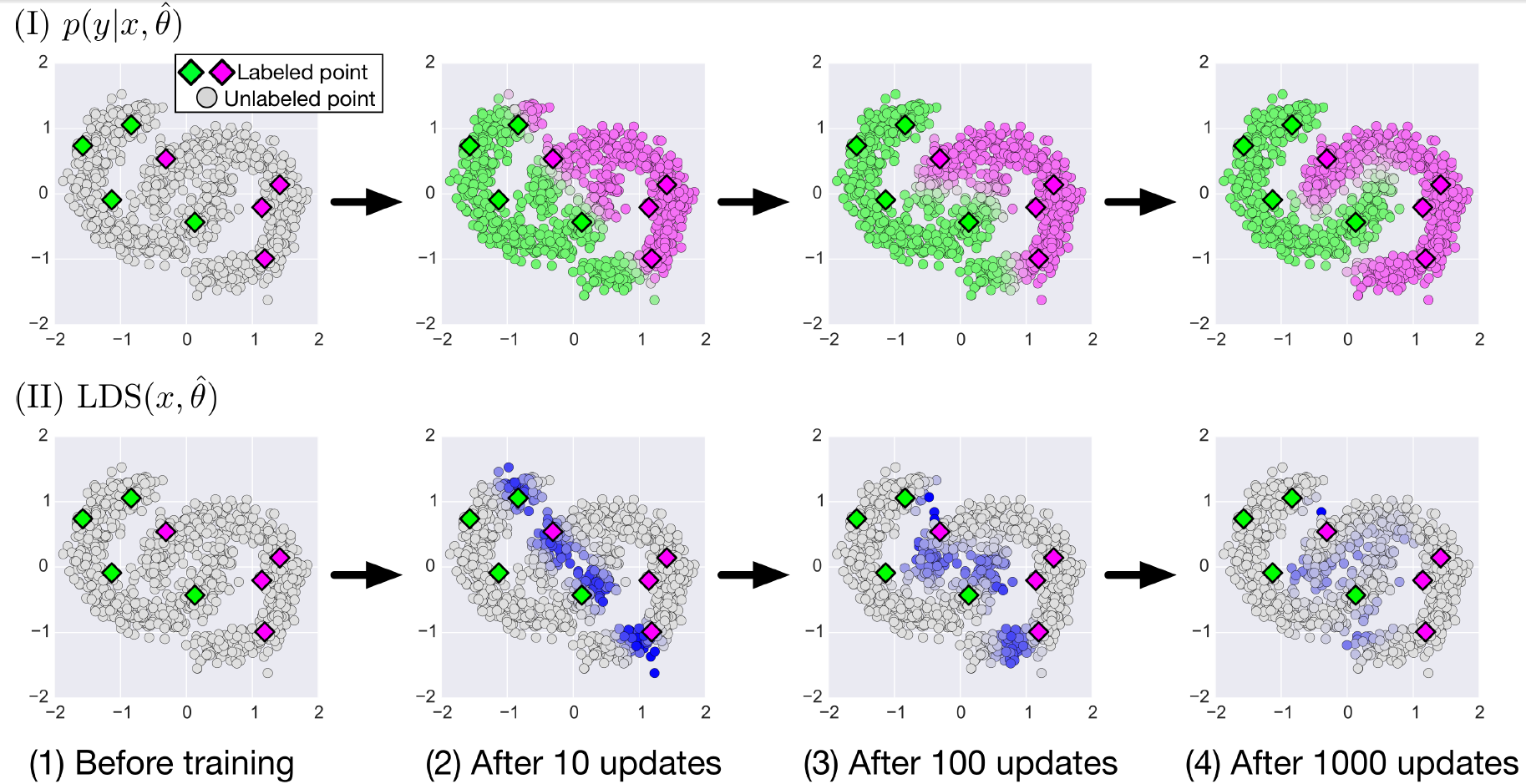
圖中方形圖示是有標簽訓練樣本,圓形圖示是無標簽訓練樣本,分成上下兩部分,分別展示了在訓練之前、訓練更新(梯度下降)10次、100次、1000次時,模型對無標簽訓練樣本的預測情況$({\rm I})$,和無標簽訓練樣本的LDS$({\rm II})$,樣本的輸入為二維,分別用橫縱坐標表示,模型預測輸出為一維,從綠到灰,再到紫,用連續的顏色過渡來表示預測標簽為某個類別的概率(紫色概率為1,綠色概率為0,灰色為0.5),如$({\rm I})$所示,$({\rm II})$用灰色到紫色表示無標簽樣本的LDS大小,越紫說明該樣本點在當前模型下的LDS越大,說明對這個樣本點進行小擾動會使當前模型的預測出現大偏差,
$({\rm I})$可以看出,隨著不斷的更新,無標簽樣本的預測從有標簽樣本“傳染”出去(因為遵循相近的樣本預測相同的理念),直到停在無標簽樣本稀疏的地方(因為沒有樣本再進行減小LDS的“傳染”,而稀疏的地方也正好就是兩個類別的分界線),最終形成了兩個鑲嵌著的半圓環,這個“傳染”的效果是我之前沒想到的,我以為減小LDS的效果僅僅局限在有標簽樣本的周圍,但是加了大量的無標簽樣本后,這些樣本對模型進行了總體的“把控”,而少量的有標簽樣本則對這個總體進行了“固定”,二者聯動,使得VAT半監督學習的學習效果很好,
$({\rm II})$顯示LDS隨著模型的更新,越來越小,最后LDS較大大的樣本點都分布在兩個標簽的分界線處,
論文資訊
Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/55441.html
標籤:其他
上一篇:高德網路定位演算法的演進
下一篇:貝葉斯決策理論(1)