資料來自于一個不完全清楚的程序,以投擲硬幣為例,嚴格意義上講,我們無法預測任意一次投硬幣的結果是正面還是反面,只能談論正面或反面出現的概率,在投擲程序中有大量會影響結果的不可觀測的變數,比如投擲的姿勢、力度、方向,甚至風速和地面的材質都會影響結果,也許這些變數實際上是可以觀測的,但我們對這些變數對結果的影響缺乏必要的認知,所以退而求其次,把投擲硬幣作為一個隨機程序來建模,并用概率理論對其進行分析,
概率有時也被解釋為頻率或可信度,但是在日常生活中,人們討論的概率經常包含著主觀的因素,并不總是能等同于頻率或可信度,比如有人分析中國足球隊打進下次世界杯的概率是10%,并不是說出現的頻率是10%,因為下次比賽還沒有開始,我們實際上是說這個結果出現的可能性,由于是主觀的,因此不同的人將給出不同的概率,
在數學上,概率研究的是隨機現象背后的客觀規律,我們對隨機沒有興趣,感興趣的是通過大量隨機試驗總結出的數學模型,當某個試驗可以在完全相同的條件下不斷重復時,對于任意事件E(試驗的可能結果的集合,事件是集合,不是動作),結果在出現在E中的次數占比趨近于某個常量,這個常數極限是事件E的概率,用P(E)表示,
我們需要對現實世界建模,將現實世界的動作映射為函式,動作結果映射為數,比如把投硬幣看作f(z),z是影響結果的一系列不可觀測的變數,x 表示投硬幣的結果,x = f(z),f是一個確定的函式,如果能夠得到該函式的形態,我們就能對結果進行精確預測,但由于我們對x和z之間的映射關系缺少了解,所以無法對f建模,只能定義X來描述該程序是由概率分布P(X=x)抽取的隨機變數,
在討論貝葉斯決策之前先來復習一下概率的基礎知識,
隨機變數和概率分布
隨機變數通常用實數表示概率事件,它具有隨機性,會隨環境而改變,對于隨機變數的每一個取值,都有一個與之唯一對應的概率,通常用大X表示隨機變數,比如X={投擲硬幣的結果},X={公司第一季度的銷售額},
離散型變數和概率質量函式
離散型變數的概率分布可以用概率質量函式(probability mass function,PMF)來描述,通常用大寫的P來表示概率質量函式,概率質量函式把隨機變數能夠取得的每個值都映射到該值對應的概率,比如P(X=x)表示隨機變數等于x的概率,這里X表示隨機變數本身,x表示某一個固定的取值,
離散型隨機變數是的取值是有限的,比如投骰子的結果,X=每次投骰子的結果,每個隨機變數都有一個與之對應的概率,比如投骰子時P(X=1)=1/6,P(X=3)=1/6;再比如P(X=1)=1/4,1表示“今年會發年終獎”,
對于任意實數a,離散型隨機變數X的概率分布函式是:
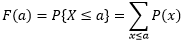
其中P是概率質量函式,P(a) = P(X=a),可以簡單地把概率分布理解為概率的累加,
隨機變數可能不止一個,比如{X=汽車發動機功率,Y=汽車價格},我們對多個隨機變數以及它們之間的關系同樣感興趣,它們的聯合分布是:
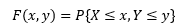
假設有兩個離散型隨機變數X和Y,并且已知P(X,Y),可以用下式定義X=x的邊緣概率:
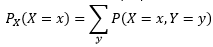
連續型變數和概率密度函式
連續型隨機變數的取值是連續的,比如水杯中水的真物體積,它的值可能是從0~1000ml中的任意取值(包括小數),我們用概率密度函式(probability density function,PDF)而不是質量函式來描述它的概率分布,通常用小寫字母p表示概率密度函式,p的定義域是所有隨機變數的可能的取值,一個常見的密度函式是正態分布函式,
對于單變數連續型概率分布來說:
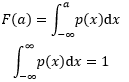
p和表示概率的質量函式P不同,p不是概率,p(x)dx才是概率,
對于二維隨機變數來說,p(x,y)是密度函式,聯合概率分布是:
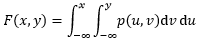
邊緣密度自然是固定一個變數,對另一個做積分:
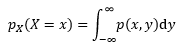
實際上這與離散型類似,只不過用積分代替了求和,邊緣密度也不是概率,px(a)dx才是概率,
期望
隨機變數X的期望是指大量試驗中X的加權平均值,用E[X]表示:
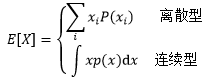
伯努利分布
如果隨機試驗僅有兩個可能的結果,那么這兩個結果可以用0和1表示,此時隨機變數X將是一個0/1的變數,其分布是單個二值隨機變數的分布,稱為伯努利分布,注意伯努利分布關注的是結果只有0和1,而不管觀測條件是什么,
設p是隨機變數等于1的概率,伯努利分布有一些特殊的性質:
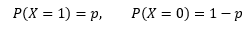
將上面的兩個式子合并:
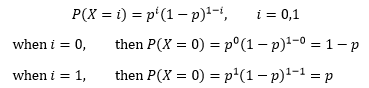
伯努利變數是離散型,并且是一個0/1變數,它的數學期望是:
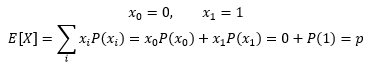
方差是:
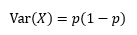
條件概率
很多時候,我們感興趣的是某個事件在給定其它事件時出現的概率,這種概率稱為條件概率,給定X=x,Y=y,在x條件下下發生y的概率是P(y|x):
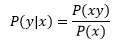
這實際上是由下式推導來的:
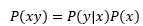
x和y同時發生的概率等于x條件下發生y的概率(這里x和y都是給定的值,x條件下還可以發生其他事件)乘以x發生的概率,這里并未強調X和Y是獨立的,所以P(x|y)≠P(y|x),只有當二者互相獨立時,P(y|x)=p(xy)=P(x|y),
貝葉斯規則
貝葉斯公式常見的一個版本:
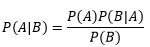
很多時候,求P(A|B)很困難,但求P(B|A)卻很容易,上面的公式實際上是條件概率公式簡單的推導:
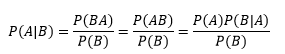
當兩個變數聯合分布時:
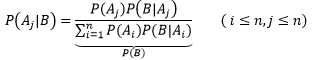
分母實際上是隨機變數Y=B時的邊緣概率:
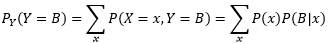
先驗與后驗
人們一直通過尋找證據的方式來排除陌生領域的不確定性,并在不確定的條件下進行決策,而概率正是根據有意義的證據進行推理的一種方式,
假設我們有一個關于小汽車的樣本集,其中包含m個樣本,每個樣本都有發動機功率和價格兩個特征,這些汽車可分為兩類,跑車和普通家用車,在這個集合中,汽車的型別可以用伯努利隨機變數C表示,C=1表示家用車,C=0表示豪華車,發動機功率和價格作為可觀測的條件,是一個二維隨機變數,X=(x1; x2),如果我們能夠知道質量函式,當面對一組觀測條件的向量x=(x1; x2)時,就可以做出類似下面的預判:
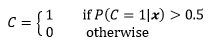
在x條件下,當汽車是家用車的概率大于50%時,判斷該汽車是家用車,否則判斷為豪華車,
現在的問題是如何求得P(C|x)的分布模型,根據貝葉斯規則:
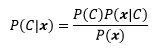
P(C|x)是后驗概率,意思是根據觀測條件判斷C取值型別的概率,是我們的目標,
P(C)是預先知道的,它是根據資料集中m個樣本的標簽統計而來的,與x無關,這里“無關”的意思是說,我們只通過標簽就可以計算出P(C),而不是說特征真的和標簽無關——要是真的無關也就沒必要建立模型了,由于我們在看到x前就已經知道了P(C),因此稱P(C)為先驗概率,并且有P(C = 0) + P(C = 1) = 1,
P(x|C)是似然,P(x|C=1)表示在家用車的前提下,發動機功率和價格有多大可能性是x,P(x|C)也可以通過訓練資料得到(具體方法將在后續文章詳細講述),值得注意的是,在實際應用中,x通常是更多維的,且每一維度都有很多取值,因此隨機變數的取值空間遠遠大于訓練集的樣本數,這就導致觀測條件的許多取值沒有出現在訓練樣本中,而“沒有出現”和“出現的概率是0”并不是一回事,這意味著P(x|C)實際上也無法通過已知的資料求得(變通方法將在后續文章詳細講述),
P(x)是證據,是可觀測條件X=x的邊緣概率:
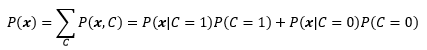
可以看到,P(x)實際上就是x出現在資料集中的概率,與C有多少個取值無關,證據的一個作用是使后驗概率規范化,使得:
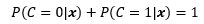
也許代入具體的公式會更清晰:
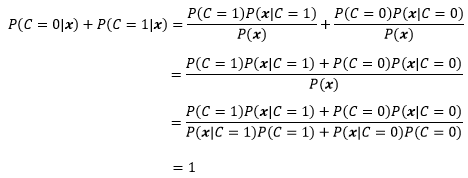
貝葉斯規則告訴我們:
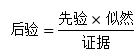
只要知道了后驗概率,就可以根據觀測條件做出決策,
決策、損失與風險
以手寫數字識別為例,隨機變數X是手寫輸入的影像,Ci(i=1,2,…,10)表示被識別出數字的分類,C1~C9表示1~9,C10表示數字0,共10個分類,K = 10,資料集中已經有了大量的影像和對應的分類:

多分類的決策
對于先驗概率P(Ci)來說:
假設先驗和似然是已知的,對于任意一個輸入x,被識別為Ci類的概率是:
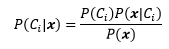
對于每個輸入,都能得到K=10個后驗概率,現在有一個潦草的輸入:

暫且認為是地球文字,并且 中第一個字符的真實含義是7,對于該字符的識別將產生10個后驗概率:
中第一個字符的真實含義是7,對于該字符的識別將產生10個后驗概率:
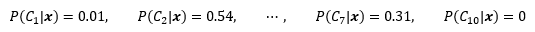
其中最大的一個值是P(C2|x),因此選擇C2作為最終決策:
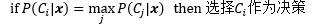
損失與風險
在這個例子中,由于字跡潦草,識別系統對x做出了錯誤的決策,對于醫療診斷來說,決策是至關重要的,也許把每7天檢查一次看成2天檢查一次沒什么大不了,但是反過來就可能耽誤患者的治療,這意味著每個決策對應的風險是不同的,
為了判斷風險的大小,需要將其數字化,我們定義R(Ci|x)是把輸入x指派到Ci類的決策所帶來的風險,λik是x實際上屬于Ck時把x指派到Ci的損失,比如本例中字符的真實含義是7(x屬于C7),但識別系統將x指派到了C2,此時的損失是λ27,結合期望的概念,期望風險(expected risk)R(Ci|x)是:
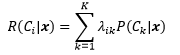
期望風險的另一個名稱是期望損失(expected loss),在決策論中通常用“期望風險”一詞,λik是根據領域知識定義的,搶銀行失敗的風險和考試失敗的風險當然不同,
我們選擇期望風險最小的決策作為最終決策:
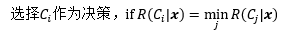
正確的決策沒有損失,即λii=0,但錯誤的損失各不相同,把2天服藥一次看作3天服藥一次也許損失不大,但是看作7天服藥一次可就要命了,
一種最簡單的損失函式是0-1損失函式:
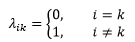
在0-1損失函式下,結合①,把輸入x指派到Ci的決策帶來的期望風險是:
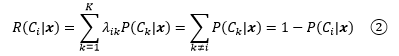
“正確的決策沒有損失”這句話并不完全正確,因為存在例外,比如在“老媽和女朋友同時掉進水中先救誰”這種送命題中,無論怎么選會有損失,此時你可以讓“最佳決策”有一個相對較小的損失,鑒于送命題的答案是一個玄學問題,我們姑且認為在絕大多數情況下,正確的決策沒有損失,
疑惑動作
P(C2|x)=0.54是所有P(Ci|x)中最大的一個,表示x有比一半多一點的概率是C2,近似于瞎蒙,這意味著這是一個確定性很低(或錯誤率很高)的決策,在醫療診斷中,錯誤的決策往往意味著極高的代價,因此對這些確定性很低的決策可能需要更高級別的處理,比如人工干預,這就需要定義一個拒絕(reject)或疑惑(doubt)動作d,此時帶有疑惑動作的0-1損失函式是:
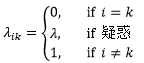
λ是疑惑動作的損失(注意λ和λik不是一回事),疑惑的風險是:
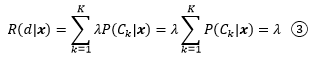
值得注意的是,我們處理的仍然是K分類,疑惑動作和其他的普通決策雖然站在一起,但并不等價,之所以定義d,是由于對所有P(Ci|x),1 ≤ i ≤ K來說,即使最大的一個P(Ci|x)仍然可能只有很低的置信度,①仍然成立,把x劃分到Ci的風險仍然是②,
對于帶有疑惑的決策來說:
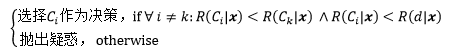
把②和③代入的第一個分式:
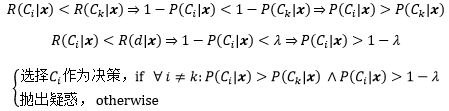
λ的取值應該在(0, 1)之間,如果λ ≤ 0,那么對于第一個分式來說,P(Ci|x) > 1 – λ 永遠不會成立,這意味著識別系統總是對輸入產生疑惑;如果λ ≥ 1,則永遠不會拒絕,加入疑惑動作就沒有意義了,
出處:微信公眾號 "我是8位的"
本文以學習、研究和分享為主,如需轉載,請聯系本人,標明作者和出處,非商業用途!
掃描二維碼關注作者公眾號“我是8位的”

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/55447.html
標籤:其他