原文標題:Focal Loss for Dense Object Detection
概要
目標檢測主要有兩種主流框架,一級檢測器(one-stage)和二級檢測器(two-stage),一級檢測器,結構簡單,速度快,但是準確率卻遠遠比不上二級檢測器,作者發現主要原因在于前景和背景這兩個類別在樣本數量上存在很大的不平衡,作者提出了解決這種不平衡的方法,改進了交叉熵損失,使其對容易分類的樣本產生抑制作用,使得損失集中在數量較少的難分類樣本上,同時,作者提出了著名的RetinaNet,這個網路不僅速度快,而且精度不比二級檢測器低,是個一出色的目標檢測網路,
focal loss
一般來講,如果對一個樣本進行分類,這個樣本分類很容易,比如說概率為98%,它的損失相應來講也會很小,但是有一種情況,如果樣本中存在極大的不平衡,這個容易分類的樣本數量占很大的比例,那么它所產生的損失也會占大部分比例,就會使得難分類的樣本占的損失比例較少,使得模型難以訓練,
作者由此提出了focal loss,來解決樣本不平衡的問題,
$ FL(p_t)=-(1-p_t)^rlog(p_t) $
RetinaNet 網路結構
retinaNet 是一個簡單,一致的網路,它有一個主干網路(backbone)以及兩個具有特殊任務的子網路,主干網路用來提取特征,有好多現成的,可以直接用,第一個子網路執行分類任務,第二個字網路執行回顧任務,
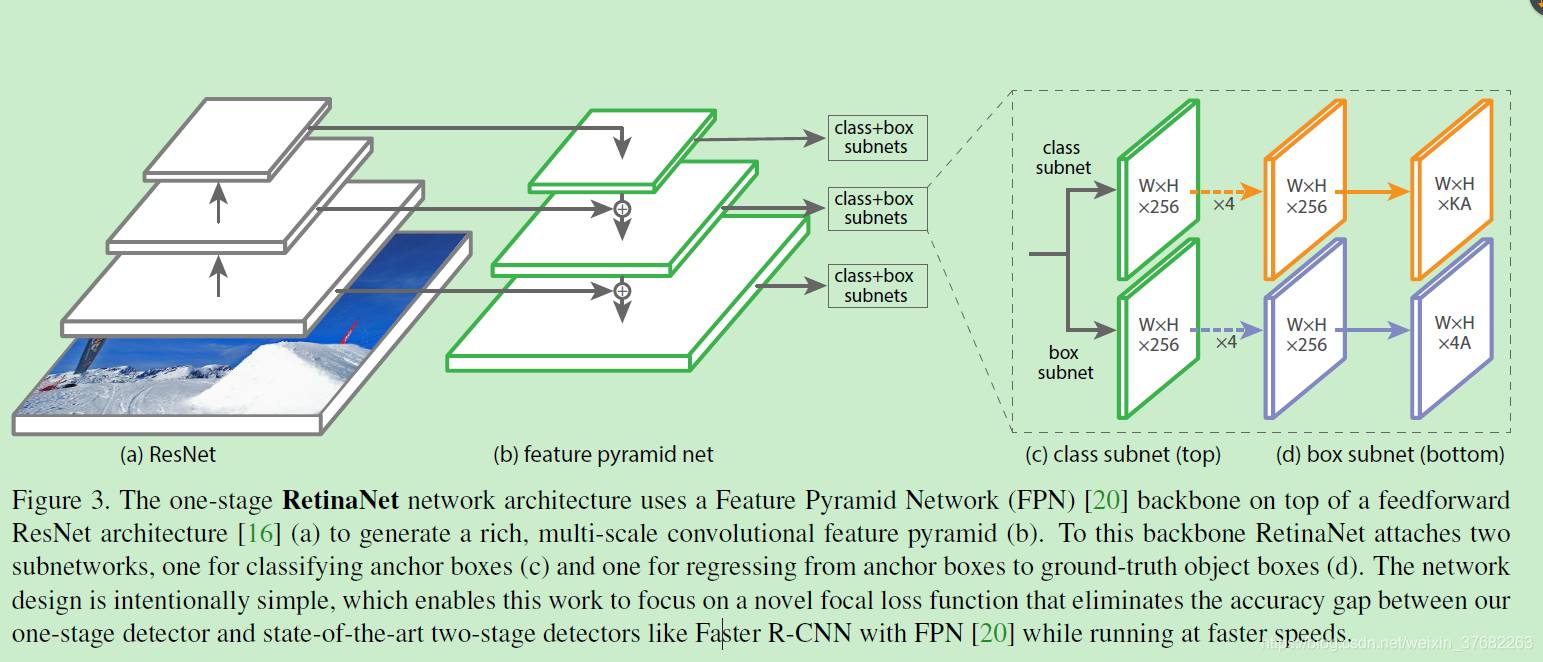
1.backbone
使用了特征金字塔(FPN)作為backbone,它可以提取不同尺度的特征,金字塔的每一層都可以用來檢測物體,小特征可以檢測大物體,大特征可以檢測小物體,
將FPN建立在resnet的基礎上,構成了從P3到P7的金字塔,(\(P_l\)比輸入的圖片尺寸小\(2^l\)倍),所有的金字塔層,都有256個通道,
2.Anchors
- 使用具有平移不變特性的Anchors,它們的大小從\(32^2\)到\(512^2\),對應P3到P7,Anchors使用3種長寬比,{1:2,1:1,2:1},使用3種大小比例{\(2^0,2^{1/3},2^{2/3}\)}.這樣的設定可以提高AP,每個位置中anchor 的個數A= 3X3=9,
- 每個Anchor都會分配一個長度為K的one-hot編碼,K是類別的數量,包含背景類,并且分配一個長度為4的向量,代表框子的大小和定位,
- 設定前景是IoU大于0.5的框,背景是IoU小于0.4的框,其他的忽略掉,每個Anchor都有一個one-hot編碼,對應類別為1,其他為0.
3.分類子網路
這是一個小的全卷積神經網路,每個空間位置都會產生KA個預測,K是類別數,A是Anchor個數(9),
注意:只有一個分類子網路,金字塔的所有層都共享這一個網路中的引數,步驟如下:從金字塔中提取出C(256)通道的特征,然后子網路有4個卷積層,每個卷積層都使用3X3的卷積核.最后在跟著一個(KA)通道的卷積層,
4.回歸子網路
這也是一個全卷積神經網路,與分類子網路并行存在著,它的任務是對預測框與距離最近的標注框(真實值,如果有的話)進行回歸,它在每個空間位置有4A個預測,與其他方式不同,這種回歸方式對于分類,是獨立的,不可知的,這使用了更少的引數,但是同樣有效,
推斷與訓練
推斷
為了提高速度,把閾值設定為0.05,最多使用前1000個最高分的回歸框預測,最后融合所有層級的預測結果,使用非極大值抑制,閾值為0.5.
focal loss
r=2的時候效果好,focal loss 將用在每張圖片的10萬個anchors上,也就是說,focal loss是這10 萬個anchor(經過歸一化)產生的損失的和,引數a也有一個穩定的范圍,這兩個引數成反比關系,
初始化
除了最后一個卷積層,所有的卷積層都用b=0,高斯權重0.01.對于最后一個卷積層,b的設定有所不同,這是為了避免在訓練開始的時候,出現不穩定現象
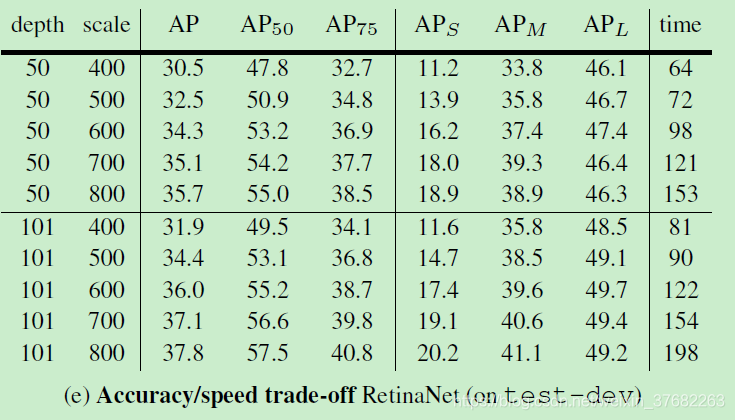
實驗結果
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/55457.html
標籤:其他