Extreme Learning Machine
作者:凱魯嘎吉 - 博客園 http://www.cnblogs.com/kailugaji/
1. ELM
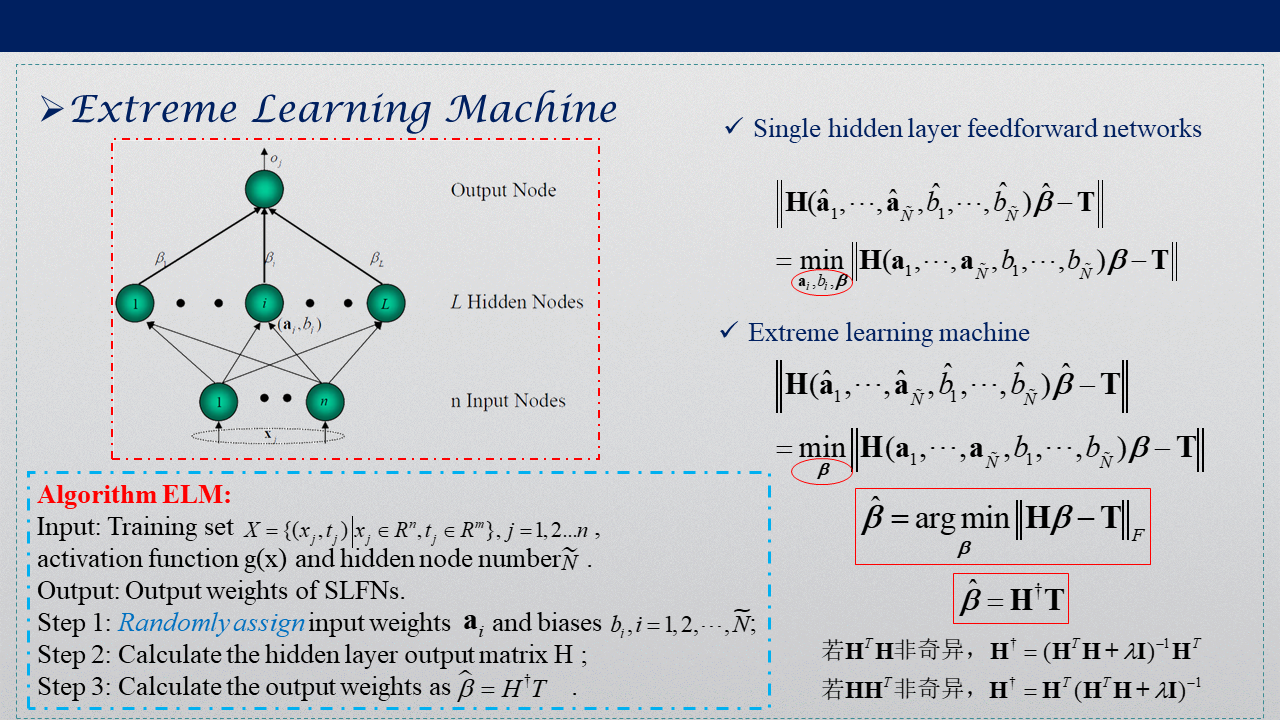
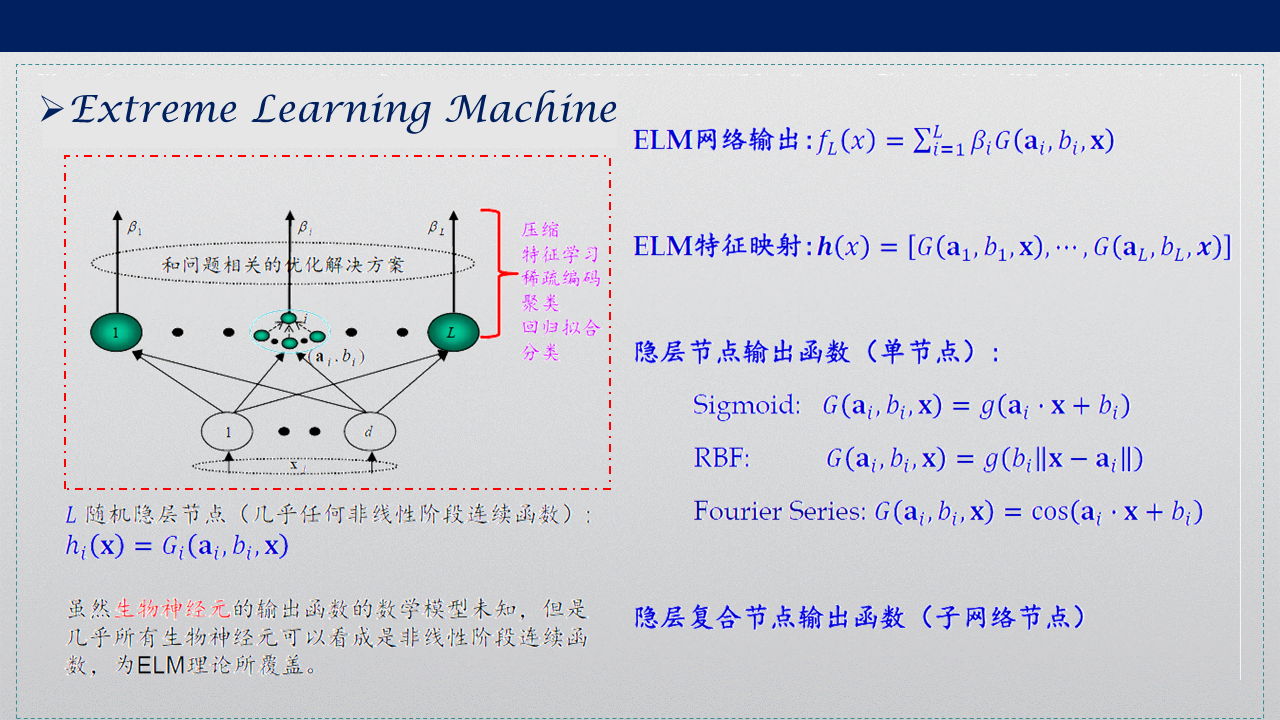
2004年南洋理工大學黃廣斌提出了ELM演算法,極限學習機(ELM Extreme Learning Machine)是一種快速的的單隱層前饋神經網路(SLFN)訓練演算法,
該演算法的特點是在網路引數的確定程序中,隱層節點引數(a,b)隨機選取,在訓練程序中無需調節,只需要設定隱含層神經元的個數,便可以獲得唯一的最優解;而網路的外權(即輸出權值)是通過最小化平方損失函式得到的最小二乘解(最侄訓歸成求解一個矩陣的 Moore-Penrose 廣義逆問題).這樣網路引數的確定程序中無需任何迭代步驟,從而大大降低了網路引數的調節時間,與傳統的訓練方法相比,該方法具有學習速度快、泛化性能好等優點,
2. H-ELM
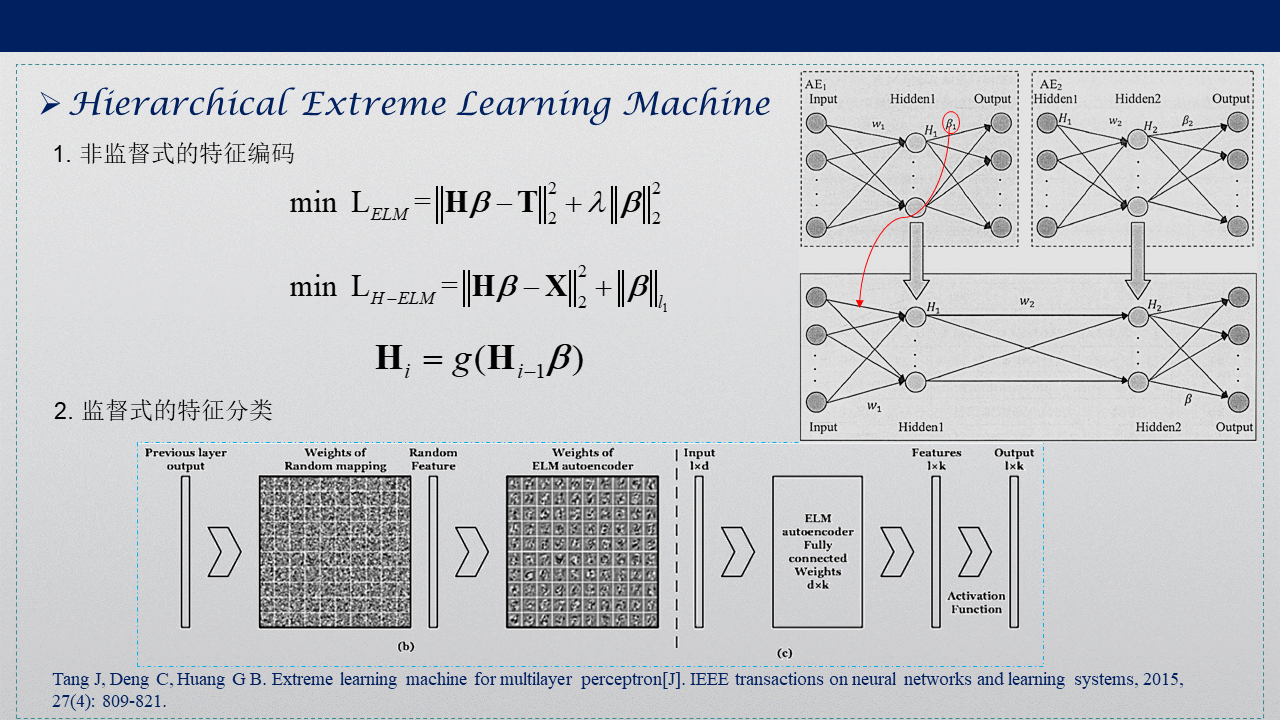
Hierarchical Extreme Learning Machine (H-ELM)是2015年提出的一個ELM的改進演算法,分為兩個階段:
1. 非監督式的特征編碼,在第一階段,基于ELM的稀疏自編碼器被設計用來從輸入資料中抽取多層的稀疏特征,通過逐層自編碼獲得每層的權重矩陣,權重確定后,無需微調,
2. 監督式的特征分類,在第二階段,第一階段獲得的高層次特征(維度可能比原始資料大)將被一個隨機矩陣打散,將打散后的資料作為原始ELM的輸入,最后用原始ELM來解決分類或者回歸問題,
與ELM的區別在于自編碼階段,權重矩陣的懲罰項用的是L1范數,引數的更新公式用Fast Iterative Shrinkage-thresholding (FISTA)求解,而ELM的權重懲罰項用的L2范數,用嶺回歸求解,


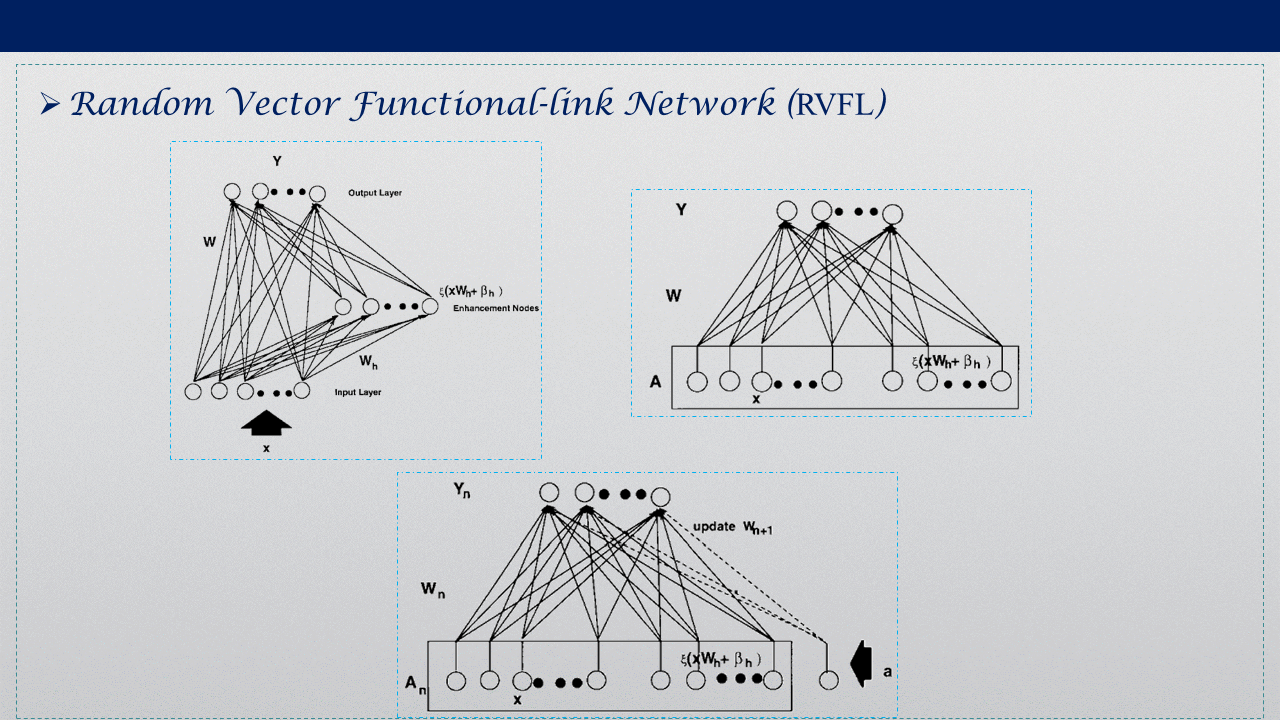
3. RVFL
Random Vector Functional-link Network (RVFL)演算法是1994年提出的演算法,與ELM相比,它增加了從輸入層到輸出層的連接權重,輸入層到隱層的權重與隱層的偏置還是隨機賦權,只有輸入層到輸出層與隱層到輸出層的權重需要用最小二乘法或者其他方法求解,
4. 參考
[1] ELM官方網址:Extreme Learning Machines
[2] Huang G B, Zhu Q Y, Siew C K. Extreme learning machine: theory and applications[J]. Neurocomputing, 2006, 70(1-3): 489-501.
[3] MATLAB程式:ELM極速學習機
[4] 論戰Yann LeCun:誰能解釋極限學習機(ELM)牛X在哪里?
[5] Tang J, Deng C, Huang G B. Extreme learning machine for multilayer perceptron[J]. IEEE transactions on neural networks and learning systems, 2015, 27(4): 809-821.
[6] Pao Y H, Park G H, Sobajic D J. Learning and generalization characteristics of the random vector functional-link net[J]. Neurocomputing, 1994, 6(2): 163-180.
[7] 偽逆總結 - CSDN
[8] 對ELM的質疑:Extreme Learning Machine: Duplicates Others' Papers from 1988-2007
[9] 王常飛. 融合分層極限學習機演算法研究[D]. 湘潭大學, 2018.
[10] 軟閾值迭代演算法(ISTA)和快速軟閾值迭代演算法(FISTA)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/55458.html
標籤:其他
上一篇:論文閱讀|Focal loss
下一篇:機器學習(01)——機器學習簡介