摘要:本文將使用ModelBox端云協同AI開發套件(RK3568)實作攝像頭虛擬背景AI應用的開發,
本文分享自華為云社區《ModelBox開發案例 - RK3568實作攝像頭虛擬背景【玩轉華為云】》,作者:AI練習生 ,
本文將使用ModelBox端云協同AI開發套件(RK3568)實作攝像頭虛擬背景AI應用的開發,

最終運行效果如下:
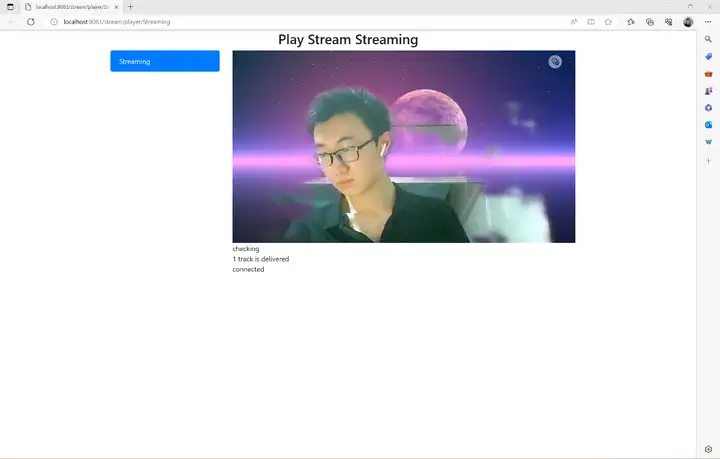
RK3568
本應用采用RK開發套件完成,需要具備RK3568開發板,本硬體可以通過以下鏈接購買:https://marketplace.huaweicloud.com/contents/2b73a21b-91c5-4c58-a61a-5a5460afeaf7 ,規格包含:RK3568開發板×1、A2 WiFi模塊×1、外殼×1、電源線和電源插頭×1、散熱片×1,
模型訓練
Notebook:
模型推理
Notebook:
onnx結構:

模型轉換
Notebook:
rknn結構:

原生onnxruntime推理
我們準備了(1080p, 30fps)的視頻,使用原生的onnxruntime進行推理,幀率最高是7:
實作代碼:
""" OpenCV 讀取攝像頭視頻視頻流,使用原生的onnxruntime推理 """ # 匯入OpenCV import cv2 import time import drawUtils import numpy as np import onnxruntime # cap = cv2.VideoCapture(0) cap = cv2.VideoCapture('test.mp4') if not cap.isOpened(): print('檔案不存在或編碼錯誤') else: i = 0 fps = 30 start_time = time.time() font = cv2.FONT_HERSHEY_PLAIN image_background = cv2.imread('R-C.jpg') width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) onnx_model = onnxruntime.InferenceSession('linknet.onnx') image_background = cv2.resize(image_background, (width, height)) writer = cv2.VideoWriter('test_result.mp4',cv2.VideoWriter_fourcc(*'X264'),fps,(width,height)) image_background = image_background/255. while cap.isOpened(): ret,frame = cap.read() if ret: img = cv2.resize(frame, (256, 256)) img = img[...,::-1]/255. img = img.astype(np.float32) img = np.transpose(img, (2, 0, 1)) data = np.expand_dims(img, axis=0) onnx_input ={onnx_model.get_inputs()[0].name: data} pred_mask = onnx_model.run(None, onnx_input) pred_mask = np.array(pred_mask) pred_mask = pred_mask[0][0][0] pred_mask = cv2.resize(pred_mask, (width, height)) pred_mask = pred_mask.reshape((height, width, 1)) img_multi = pred_mask*frame/255. mask_layer = np.ones((height, width)).reshape(height, width, 1)-pred_mask mask_layer = image_background*mask_layer image_add = img_multi+mask_layer image_add = image_add*255 image_add = image_add.astype(np.uint8) # 計算FPS i += 1 now = time.time() fps_text = int(1 / ( now - start_time)) start_time = now print('linknet post ' + str(i)) # 添加中文(首先匯入模塊) img_add = drawUtils.cv2AddChineseText(image_add, '幀率:'+str(fps_text), (20,50), textColor=(0, 255, 0), textSize=30) # 顯示畫面 # cv2.imshow('demo',img_add) writer.write(img_add) # 退出條件 if cv2.waitKey(1) & 0xFF == ord('q'): break else: break cap.release() cv2.destroyAllWindows()
修改使用編為0攝像頭(默認為PC自帶的攝像頭)進行實時檢測:
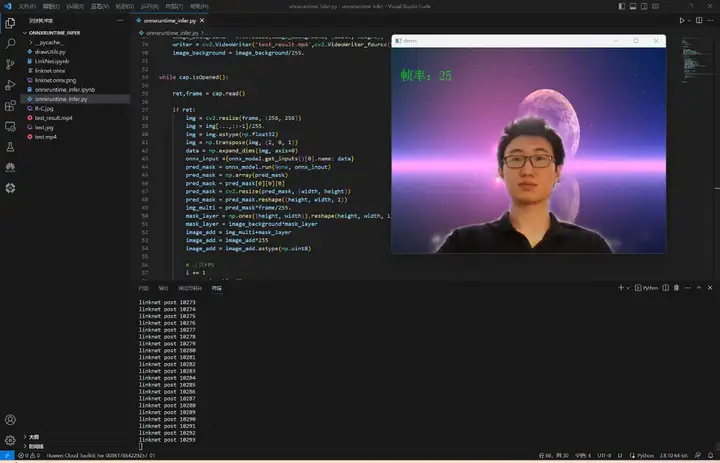
ModelBox AI應用開發
直接使用工程
1)下載案例
本案例所需資源(代碼、模型、測驗資料等)均可從網盤鏈接下載,
2)運行應用
將virtual_background檔案夾拖到工程目錄workspace目錄下面,開啟性能統計:
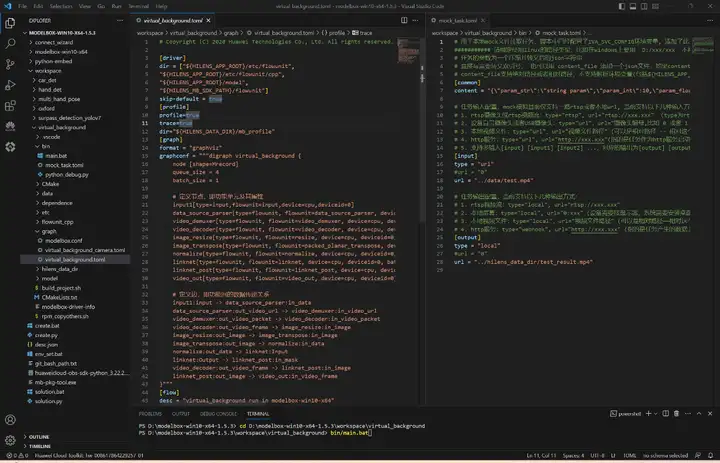
切換到工程目錄,執行bin/main.bat運行應用,生成的視頻和性能統計檔案都在hilens_data_dir檔案夾下面:
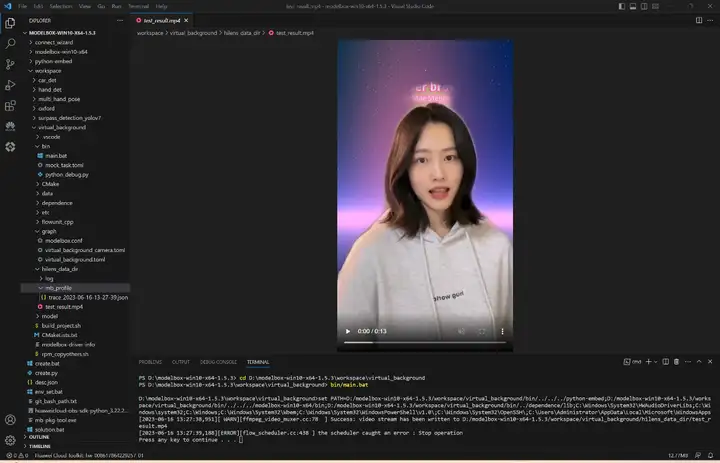
3)性能統計
在Chrome瀏覽器chrome://tracing中加載性能統計檔案:
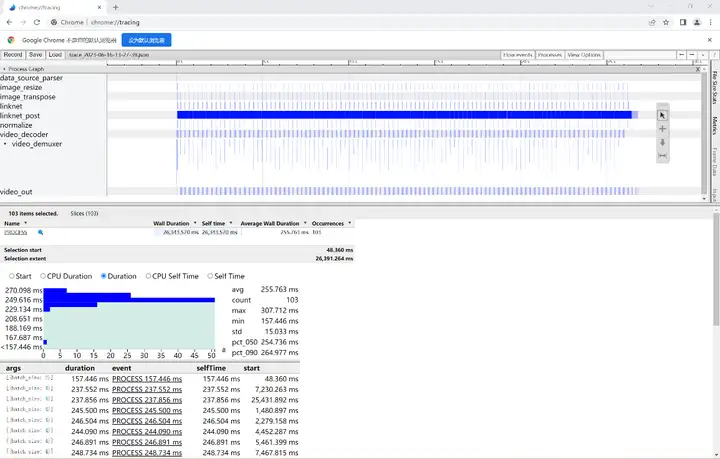
該AI應用輸入1080p的視頻,batch_size=4耗時約為256ms,平均每幀處理速度為64ms,fps=1000/64≈16,接下來我們給出該AI應用在ModelBox中的完整開發程序(以開發套件為例),
4)攝像頭檢測
打開工程目錄bin/mock_task.toml檔案,修改其中的任務輸入和任務輸出,配置為如下內容:
# 用于本地mock檔案讀取任務,腳本中已經配置了IVA_SVC_CONFIG環境變數, 添加了此檔案路徑 ########### 請確定使用linux的路徑型別,比如在windows上要用 D:/xxx/xxx 不能用D:\xxx\xxx ########### # 任務的引數為一個壓縮并轉義后的json字串 # 直接寫需要轉義雙引號, 也可以用 content_file 添加一個json檔案,如果content和content_file都存在content會被覆寫 # content_file支持絕對路徑或者相對路徑,不支持決議環境變數(包括${HILENS_APP_ROOT}、${HILENS_DATA_DIR}等) [common] content = "{\"param_str\":\"string param\",\"param_int\":10,\"param_float\":10.5}" # 任務輸入配置,mock模擬目前僅支持一路rtsp或者本地url, 當前支持以下幾種輸入方式: # 1. rtsp攝像頭或rtsp視頻流:type="rtsp", url="rtsp://xxx.xxx" (type為rtsp的時候,支持視頻中斷自動重連) # 2. 設備自帶攝像頭或者USB攝像頭:type="url",url="攝像頭編號,比如 0 或者 1 等" (需配合local_camera功能單元使用) # 3. 本地視頻檔案:type="url",url="視頻檔案路徑" (可以是相對路徑 -- 相對這個mock_task.toml檔案, 也支持從環境變數${HILENS_APP_ROOT}所在目錄檔案輸入) # 4. http服務:type="url", url="http://xxx.xxx"(指的是任務作為http服務啟動,此處需填寫對外暴露的http服務地址,需配合httpserver類的功能單元使用) # 5. 支持多輸入[input] [input1] [input2] ...,對應的輸出為[output] [output1] [output2] ...,如果使用videoout功能單元輸出,則輸入和輸出個數必須匹配,同時url不能重名 [input] type = "url" url = "0" #url = "../data/test.mp4" # 任務輸出配置,當前支持以下幾種輸出方式: # 1. rtsp視頻流:type="local", url="rtsp://xxx.xxx" # 2. 本地螢屏:type="local", url="0:xxx" (設備需要接顯示幕,系統需要安裝桌面) # 3. 本地視頻檔案:type="local",url="視頻檔案路徑" (可以是相對路徑——相對這個mock_task.toml檔案, 也支持輸出到環境變數${HILENS_DATA_DIR}所在目錄或子目錄) # 4. http服務:type="webhook", url="http://xxx.xxx" (指的是任務產生的資料上報給某個http服務,此處需填寫上傳的http服務地址) [output] type = "local" url = "0" #url = "../hilens_data_dir/test_result.mp4"
執行.\bin\main.bat camera運行應用,將會自動彈出實時的人像分割畫面:
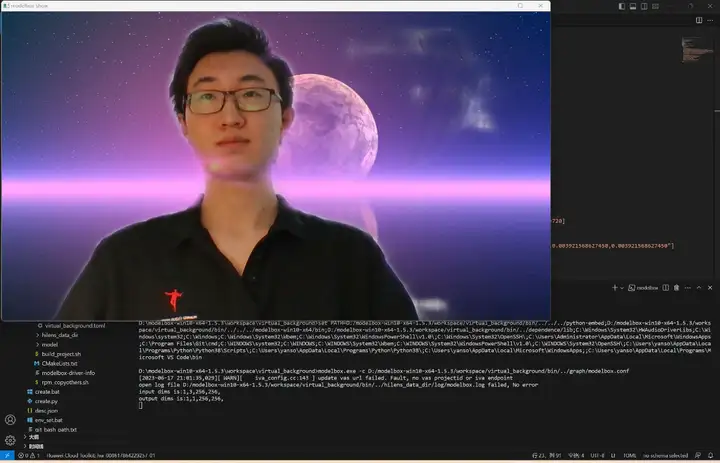
從零開發工程
如果你對專案開發感興趣,可以通過本章進一步了解,
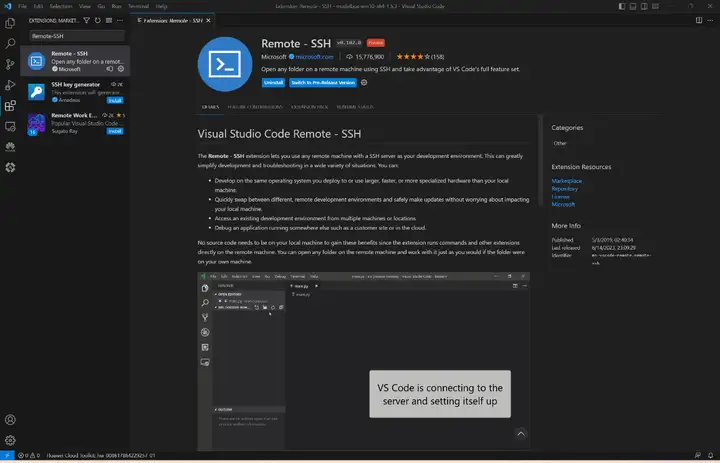
1)遠程連接開發板
我們推薦在PC端使用VS Code遠程連接開發板來對設備進行操作,安裝Remote-SSH:
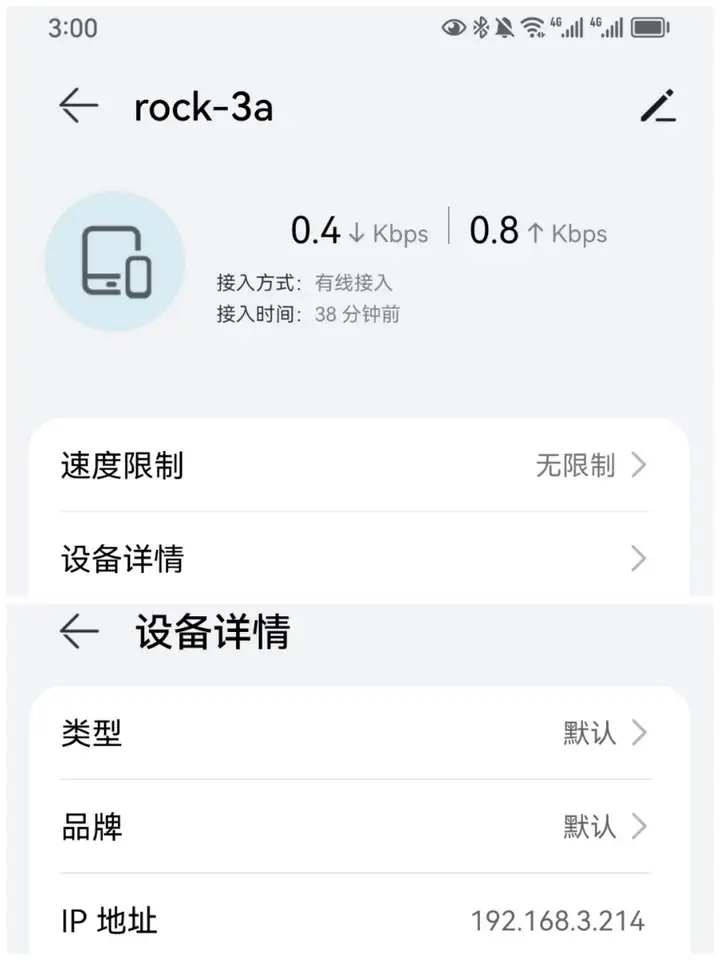
2)查看設備ip地址
可以在APP應用智慧生活上查看設備的ip地址:
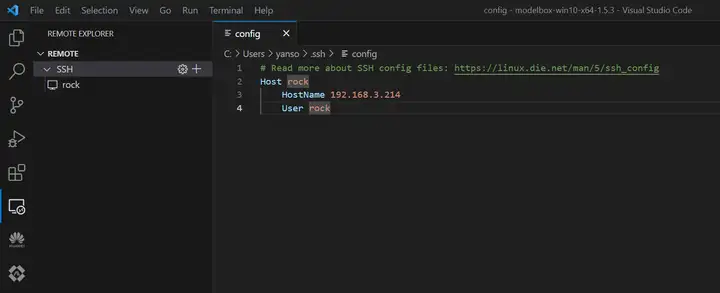
3)配置SSH連接
電腦和設備處于同一WiFi下,在VS Code中使用Remote-SSH遠程登陸:
RK3568應用開發
創建工程
在SDK目錄下使用create.py腳本創建工程,我決定工程取名為virtual_background:
rock@rock-3a:~$ cd /home/rock/modelbox rock@rock-3a:~/modelbox$ ./create.py -t server -n virtual_background sdk version is modelbox-rk-aarch64-1.5.3 success: create virtual_background in /home/rock/modelbox/workspace
創建推理功能單元
rock@rock-3a:~/modelbox$ ./create.py -t infer -n linknet_infer -p virtual_background sdk version is modelbox-rk-aarch64-1.5.3 success: create infer linknet_infer in /home/rock/modelbox/workspace/virtual_background/model/linknet_infer
可以看到推理功能單元創建在了專案工程的model目錄下面:
將我們轉換好的模型linknet.rknn拖到linknet_infer目錄下,接著編輯.toml組態檔,主要修改模型的路徑與輸入輸出,由于我們模型有一個來自rknpu的uint8的型別輸入和一個float型別的輸出,所以對組態檔編輯如下:
# Copyright (C) 2020 Huawei Technologies Co., Ltd. All rights reserved. [base] name = "linknet_infer" device = "rknpu" version = "1.0.0" description = "your description" entry = "./linknet.rknn" # model file path, use relative path type = "inference" virtual_type = "rknpu2" # inference engine type: rockchip now support rknpu, rknpu2(if exist) group_type = "Inference" # flowunit group attribution, do not change is_input_contiguous = "false" # rk do not support memory combine, fix, do not change # Input ports description [input] [input.input1] # input port number, Format is input.input[N] name = "Input" # input port name type = "uint8" # input port data type ,e.g. float or uint8 device = "rknpu" # input buffer type: use rknpu for zero-copy, cpu also allow # Output ports description [output] [output.output1] # output port number, Format is output.output[N] name = "Output" # output port name type = "float" # output port data type ,e.g. float or uint8
可以看到該模型有1個輸入節點,1個輸出節點,需要注意其中的virtual_type配置與npu類別有關,RK3568需配置為rknpu2;輸入節點的device配置建議設為與該推理功能單元的上一個功能單元相同,
ModelBox內置了rknn推理引擎和推理邏輯,開發者只需要準備好模型檔案、編輯好組態檔,即可使用該模型進行推理,無需撰寫推理代碼,
另外,本案例使用的人像分割模型是由Pytorch框架訓練得到,我們事先使用rknn-toolkit2工具將它轉換為RK3568支持的模型格式,感興趣的話可以在RK3568模型轉換查看模型轉換程序,
創建后處理功能單元
我們需要一個后處理功能單元來對模型推理結果進行解碼,依然是萬能的create.py腳本:
rock@rock-3a:~/modelbox$ ./create.py -t python -n linknet_post -p virtual_background sdk version is modelbox-rk-aarch64-1.5.3 success: create python linknet_post in /home/rock/modelbox/workspace/virtual_background/etc/flowunit/linknet_post
可以看到在專案工程的etc/flowunit目錄下面已經生成了該功能單元,存放.toml組態檔與.py功能代碼檔案:
接下來補充該功能單元的邏輯代碼,如果對此不感興趣,可以將我們資源包中的代碼CtrlC+V速通本節,
首先補充后處理功能單元的組態檔,對于后處理功能單元,我們需要知道模型推理的shape,因此需要對config欄位進行配置,此外,我們還需要修改輸入輸出,接收一個float型別的推理結果與一個uint8型別的原圖,輸出融合后的新圖:
# Copyright (c) Huawei Technologies Co., Ltd. 2022. All rights reserved. # Basic config [base] name = "linknet_post" # The FlowUnit name device = "cpu" # The flowunit runs on cpu version = "1.0.0" # The version of the flowunit type = "python" # Fixed value, do not change description = "description" # The description of the flowunit entry = "linknet_post@linknet_postFlowUnit" # Python flowunit entry function group_type = "Generic" # flowunit group attribution, change as Input/Output/Image/Generic ... # Flowunit Type stream = false # Whether the flowunit is a stream flowunit condition = false # Whether the flowunit is a condition flowunit collapse = false # Whether the flowunit is a collapse flowunit collapse_all = false # Whether the flowunit will collapse all the data expand = false # Whether the flowunit is a expand flowunit # The default Flowunit config [config] mask_h = 256 mask_w = 256 # Input ports description [input] [input.input1] # Input port number, the format is input.input[N] name = "in_mask" # Input port name type = "float" # Input port type [input.input2] # Input port number, the format is input.input[N] name = "in_image" # Input port name type = "uint8" # Input port type # Output ports description [output] [output.output1] # Output port number, the format is output.output[N] name = "out_image" # Output port name type = "uint8" # Output port type
后處理代碼:
# Copyright (c) Huawei Technologies Co., Ltd. 2022. All rights reserved. #!/usr/bin/env python # -*- coding: utf-8 -*- import _flowunit as modelbox import numpy as np import cv2 class linknet_postFlowUnit(modelbox.FlowUnit): # Derived from modelbox.FlowUnit def __init__(self): super().__init__() self.image_background = cv2.imread('data/R-C.jpg') self.image_background = cv2.cvtColor(self.image_background,cv2.COLOR_BGR2RGB) self.image_background = self.image_background/255. def open(self, config): # Open the flowunit to obtain configuration information self.mask_h = config.get_int('mask_h', 256) self.mask_w = config.get_int('mask_w', 256) self.index = 0 return modelbox.Status.StatusCode.STATUS_SUCCESS def process(self, data_context): # Process the data in_mask = data_context.input("in_mask") in_image = data_context.input("in_image") out_image = data_context.output("out_image") # linknet_post process code. # Remove the following code and add your own code here. for buffer_mask, buffer_image in zip(in_mask, in_image): # 獲取輸入Buffer的屬性資訊 width = buffer_image.get('width') height = buffer_image.get('height') channel = buffer_image.get('channel') # 將輸入Buffer轉換為numpy物件 image_background = cv2.resize(self.image_background, (width, height)) mask_data = np.array(buffer_mask.as_object(), copy=False) mask_data = mask_data.reshape(self.mask_h, self.mask_w) mask_data = cv2.resize(mask_data, (width, height)) mask_data = mask_data.reshape(height, width, 1) image_data = np.array(buffer_image.as_object(), dtype=np.uint8, copy=False) image_data = image_data.reshape(height, width, channel) img_multi = mask_data*image_data/255. mask_layer = np.ones((height, width)) mask_layer = mask_layer.reshape(height, width, 1) mask_layer = mask_layer-mask_data mask_layer = image_background*mask_layer image_add = img_multi+mask_layer image_add = image_add*255 image_add = image_add.astype(np.uint8) # frame計數 self.index += 1 print("linknet_post " + str(self.index)) # 將業務處理回傳的結果資料轉換為Buffer add_buffer = modelbox.Buffer(self.get_bind_device(), image_add) # 設定輸出Buffer的Meta資訊,此處直接拷貝輸入Buffer的Meta資訊 add_buffer.copy_meta(buffer_image) # 將輸出Buffer放入輸出BufferList中 out_image.push_back(add_buffer) return modelbox.Status.StatusCode.STATUS_SUCCESS def close(self): # Close the flowunit return modelbox.Status() def data_pre(self, data_context): # Before streaming data starts return modelbox.Status() def data_post(self, data_context): # After streaming data ends return modelbox.Status() def data_group_pre(self, data_context): # Before all streaming data starts return modelbox.Status() def data_group_post(self, data_context): # After all streaming data ends return modelbox.Status()
搭建流程圖
修改virtual_background.toml內容:
# Copyright (C) 2020 Huawei Technologies Co., Ltd. All rights reserved. [driver] dir = ["${HILENS_APP_ROOT}/etc/flowunit", "${HILENS_APP_ROOT}/etc/flowunit/cpp", "${HILENS_APP_ROOT}/model", "${HILENS_MB_SDK_PATH}/flowunit"] skip-default = true [profile] profile=true trace=true dir="${HILENS_DATA_DIR}/mb_profile" [graph] format = "graphviz" graphconf = """digraph virtual_background { node [shape=Mrecord] queue_size = 1 batch_size = 1 # 定義節點,即功能單元及其屬性 input1[type=input, flowunit=input, device=cpu, deviceid=0] data_source_parser[type=flowunit, flowunit=data_source_parser, device=cpu, deviceid=0] video_demuxer[type=flowunit, flowunit=video_demuxer, device=cpu, deviceid=0] video_decoder[type=flowunit, flowunit=video_decoder, device=rknpu, deviceid=0, pix_fmt="rgb"] image_resize[type=flowunit, flowunit=resize, device=rknpu, deviceid=0, image_width=256, image_height=256] linknet_infer[type=flowunit, flowunit=linknet_infer, device=rknpu, deviceid=0] linknet_post[type=flowunit, flowunit=linknet_post, device=cpu, deviceid=0] video_out[type=flowunit, flowunit=video_out, device=rknpu, deviceid=0] # 定義邊,即功能間的資料傳遞關系 input1:input -> data_source_parser:in_data data_source_parser:out_video_url -> video_demuxer:in_video_url video_demuxer:out_video_packet -> video_decoder:in_video_packet video_decoder:out_video_frame -> image_resize:in_image image_resize:out_image -> linknet_infer:Input linknet_infer:Output -> linknet_post:in_mask video_decoder:out_video_frame -> linknet_post:in_image linknet_post:out_image -> video_out:in_video_frame }""" [flow] desc = "virtual_background run in modelbox-rk-aarch64"
其中,profile欄位設為true啟用性能統計功能,
運行應用
應用的輸入和輸出可以在專案工程的bin/mock_task.toml中進行配置:
配置應用的輸入輸出,接下來就可以進入專案進行構建和運行了:
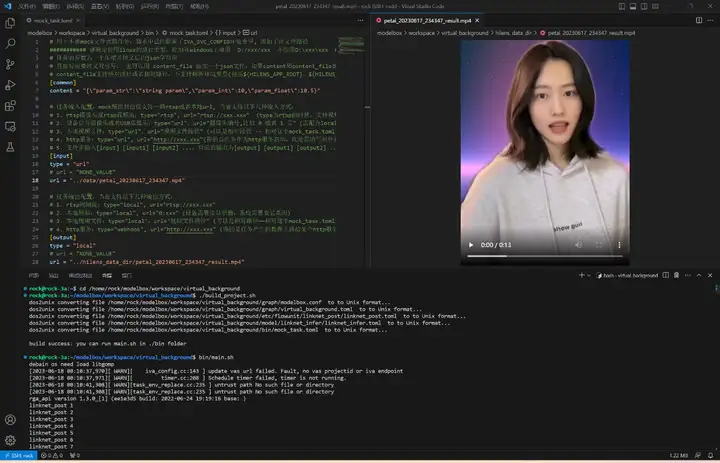
執行bin/main.sh運行應用,生成的視頻和性能統計檔案在hilens_data_dir檔案夾:
可以右鍵下載查看性能統計檔案:
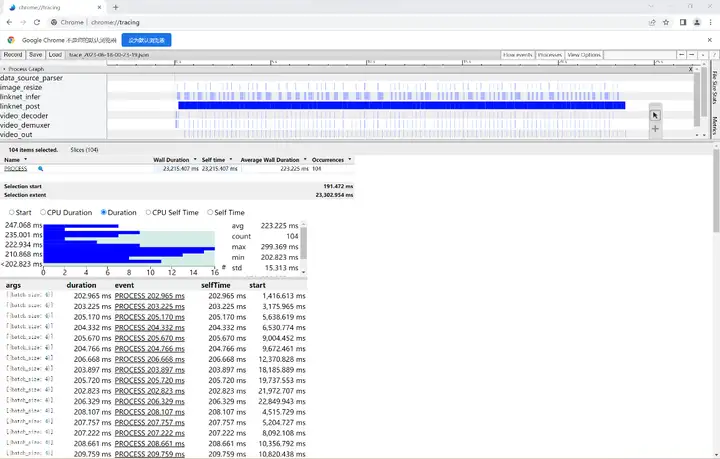
可以看到模型推理確實很快,平均每4次推理耗時223ms,fps約等于18幀每秒,
開發板攝像頭檢測
創建virtual_background_cameral.toml檔案,編輯內容如下:
# Copyright (C) 2020 Huawei Technologies Co., Ltd. All rights reserved. [driver] dir = ["${HILENS_APP_ROOT}/etc/flowunit", "${HILENS_APP_ROOT}/etc/flowunit/cpp", "${HILENS_APP_ROOT}/model", "${HILENS_MB_SDK_PATH}/flowunit"] skip-default = true [profile] profile=false trace=false dir="${HILENS_DATA_DIR}/mb_profile" [graph] format = "graphviz" graphconf = """digraph virtual_background { node [shape=Mrecord] queue_size = 1 batch_size = 1 # 定義節點,即功能單元及其屬性 input1[type=input, flowunit=input, device=cpu, deviceid=0] data_source_parser[type=flowunit, flowunit=data_source_parser, device=cpu, deviceid=0] local_camera[type=flowunit, flowunit=local_camera, device=rknpu, deviceid=0, pix_fmt="rgb", cam_width=1280, cam_height=720] image_resize[type=flowunit, flowunit=resize, device=rknpu, deviceid=0, image_width=256, image_height=256] linknet_infer[type=flowunit, flowunit=linknet_infer, device=rknpu, deviceid=0] linknet_post[type=flowunit, flowunit=linknet_post, device=cpu, deviceid=0] video_out[type=flowunit, flowunit=video_out, device=rknpu, deviceid=0] # 定義邊,即功能間的資料傳遞關系 input1:input -> data_source_parser:in_data data_source_parser:out_video_url -> local_camera:in_camera_packet local_camera:out_camera_frame -> image_resize:in_image image_resize:out_image -> linknet_infer:Input linknet_infer:Output -> linknet_post:in_mask local_camera:out_camera_frame -> linknet_post:in_image linknet_post:out_image -> video_out:in_video_frame }""" [flow] desc = "virtual_background run in modelbox-rk-aarch64"
打開工程目錄下bin/mock_task.toml檔案,修改任務輸入和任務輸出:
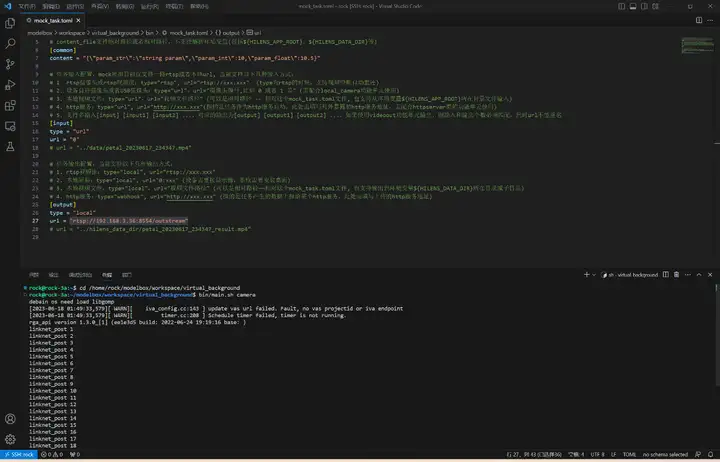
執行bin/main.sh camera運行應用,使用rtsp推流到本地進行查看:
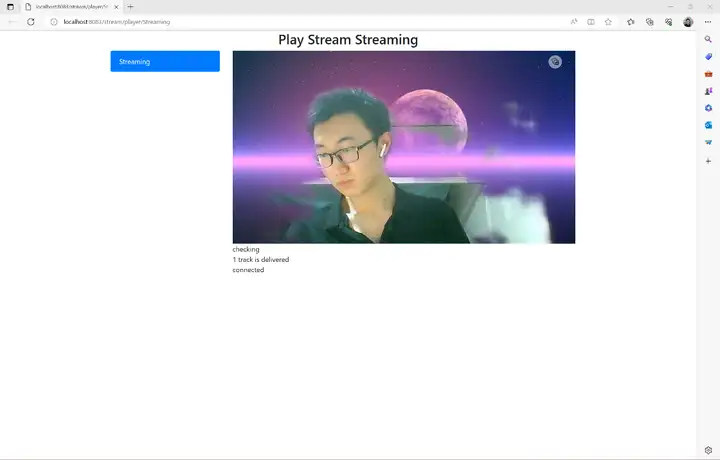
至此我們就完成了攝像頭虛擬背景AI應用的開發以及在Windows和RK3568開發板上的部署,本案例所需資源(代碼、模型、測驗資料等)均可從網盤鏈接下載,感興趣的小伙伴趕快下載玩一玩吧!
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/555588.html
標籤:其他
上一篇:黃金票據權限維持
下一篇:返回列表