作者|Quentin Bacuet
編譯|VK
來源|Medium

隨著資訊過載的增加,我們不可能通過觀看海量的內容來獲取我們想要的專案,推薦系統可以來拯救我們,推薦系統是一種模型,通過向用戶展示他們可能感興趣的內容,幫助他們探索音樂和新聞等新內容,
在Snipfeed,我們每天處理成千上萬的內容,用戶群的要求很高:Gen Z.通過利用最先進的深度學習推薦系統,我們幫助用戶瀏覽他們最喜歡的視頻、新聞、和博客,
麥肯錫估計,
“已經有35%的消費者在亞馬遜上購買的東西和75%在Netflix上觀看的東西來自基于這種演算法的產品推薦,”
隨著推薦系統的日益普及,出現了這樣的問題:哪些新的模型和演算法可以將推薦提升到一個新的水平?與矩陣分解等更經典的方法相比,它們的性能如何?
為了回答這些問題,我決定比較九種方法,并專注于兩個指標:NDCG和個性化指數,使用MovieLens資料集進行實驗,我使用TensorFlow和Keras來實作這些模型,并使用Google Colab的GPU對它們進行訓練,
資料集:MovieLens 20M
初始資料集
為了進行分析,我們將使用著名的資料集MovieLens 20M,
這個資料集包含了來自電影推薦服務MovieLens的2000多萬個評分,下面是dataframe的示例:
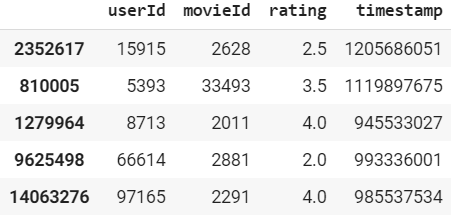
該資料集列出了138000個用戶和27000多部電影,經過清洗和過濾(我們只接受正面評價),我們有:
-
13.6萬用戶
-
2萬部電影
-
1000萬次互動
-
99.64%稀疏度
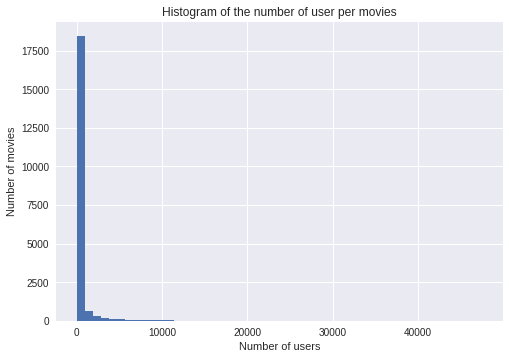
我們還可以從下面的直方圖中看到,大多數電影的收視率都在5000以下…
而且大多數用戶評價不超過500部電影,
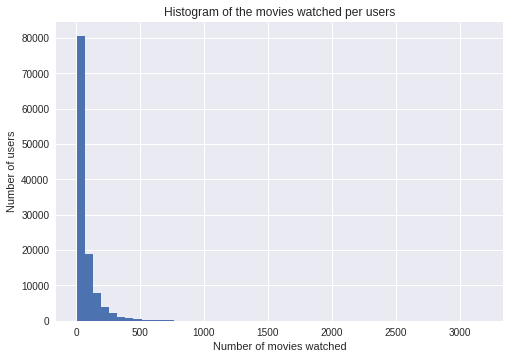
這與大多數推薦系統問題是一致的:很少有用戶對很多電影進行評分,很少有電影有很多評分,
訓練資料集
我們可以根據這些資料建立一個點擊矩陣,點擊矩陣的格式如下所示,如果用戶u與項i互動,則行u和列i上的單元格包含1,否則包含0,
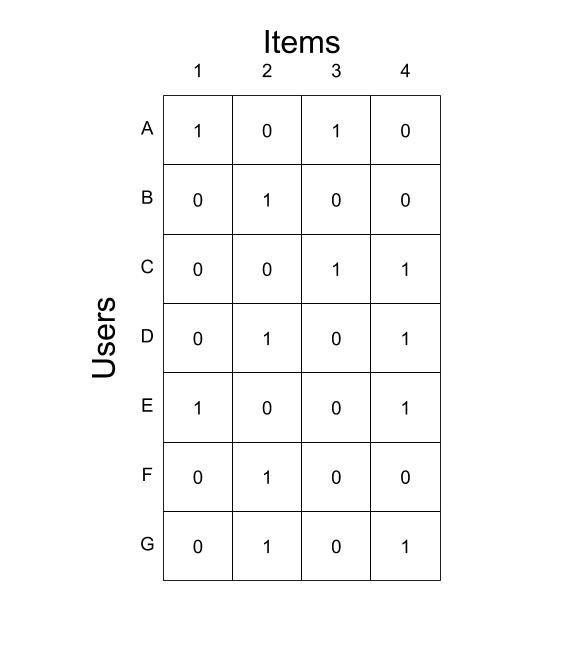
我們還將點擊向量x?定義為點擊矩陣的第u行向量,
訓練驗證測驗資料集
為了評估模型的質量,我們將資料集分成3個子集,一個子集用于訓練,一個子集用于驗證,一個子集用于測驗,我們將使用第一個子集訓練模型,第二個子集在訓練期間選擇最佳模型,最后一個子集獲得度量,
指標:NDCG和Personalization
NDCG
如前所述,我們將使用兩個指標來評估我們的模型,第一個將是NDCG,它衡量質量和我們的推薦專案的順序,我們首先需要定義DCG,DCG越高越好,DCG@p定義為:
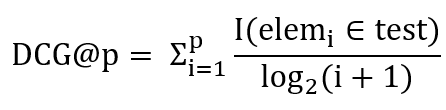
I是指示函式,elem_i代表推薦串列的第i個元素,為了說明這個抽象公式,這里有一個簡短的例子:
需要建議:{A,B,C}
建議1:[C、A、D]-DCG@3=1.63
建議2:[D、B、A]-DCG@3=1.13
注意,這些建議是有順序的,因此,我們有:DCG? > DCG?,因為預測1中的前兩個專案是我們的目標專案,而這些專案位于預測2的串列末尾,
NDCG是DCG的近親,將分數投影在0到1之間,以便它們在模型之間轉換,
Personalization(個性化指數)
Personalization=計算每對推薦之間的距離,然后計算平均值,為了比較不同的個性化指數,我們將其標準化(就像我們對NDCG所做的那樣,我們將分數投影在0到1之間),為了說明這個指標,讓我們看看下面的示例:
建議1:
用戶1:[A,B,C]/用戶2:[D,E,F] 個性化=1
建議2:
用戶1:[A,B,C]/用戶2:[A,B,C] 個性化=0
協同與基于內容的過濾
推薦系統可以分為兩類:協同過濾和基于內容的過濾,
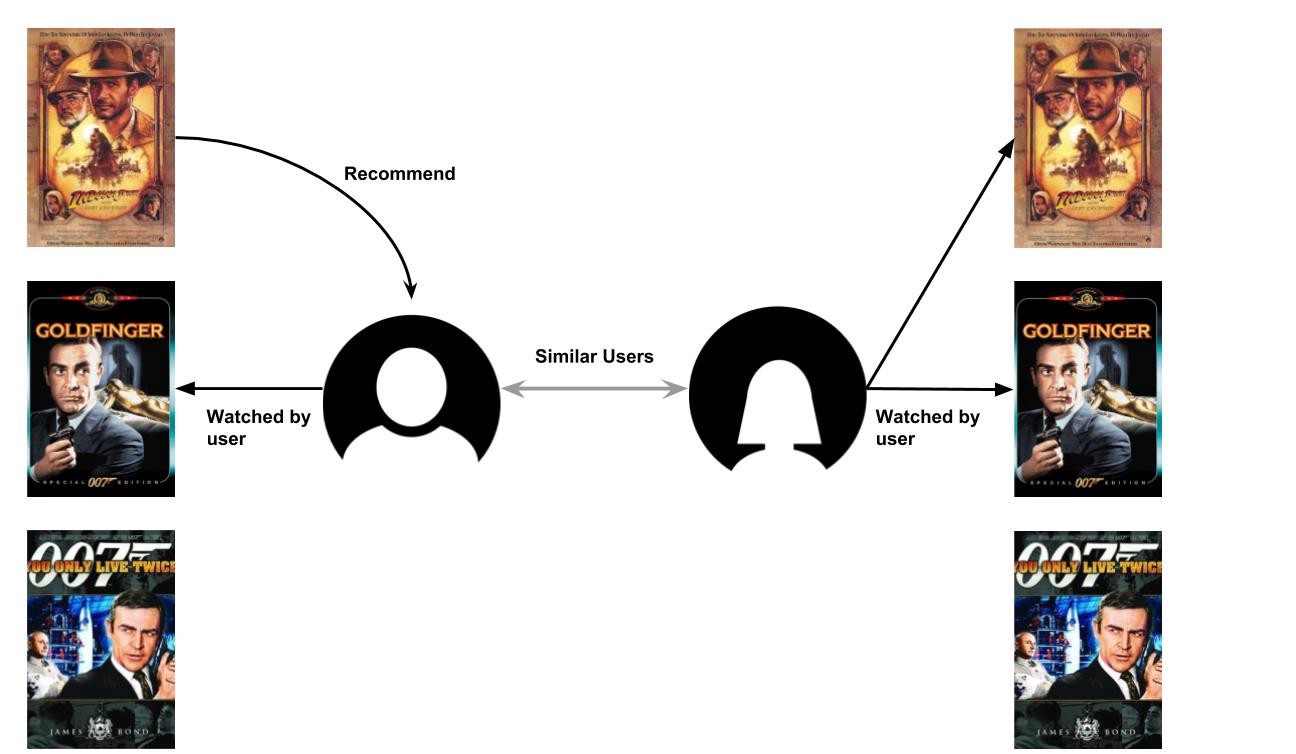
協同過濾
協同過濾是基于用戶相似度的RS子族,它通過分析與用戶u關系密切的其他用戶的口味來預測用戶u的興趣,它基于關系密切的用戶喜歡的東西是類似的,
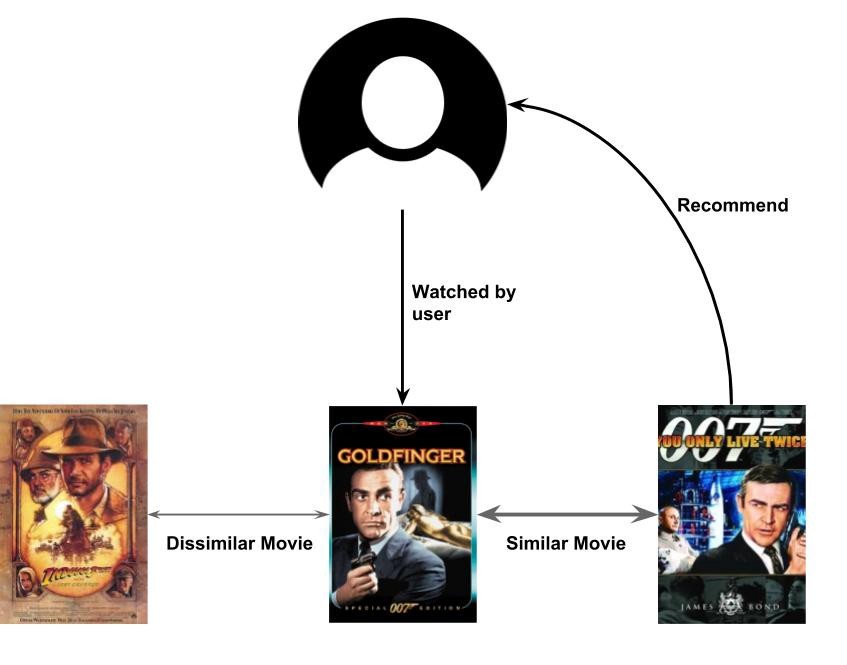
基于內容的過濾
基于內容的過濾是基于用戶偏好和內容相似性的另一類RS,這意味著它基于這樣一種想法:如果你喜歡item i,那么你更可能喜歡類似于i的項,而不是不同于它的項,
基于內容
定義
如上所述,基于內容的方法使用專案描述來查找與用戶看到的最接近的專案,我盡可能詳盡地實作了這個方法,但是一個幾乎沒有特征的資料集是這個方法的一個限制,MovieLens資料集只提供電影的型別,
但是,我們開發了一個簡單的方法,如下面的偽代碼所述:
reco = zero-vector of size number of items
for i in items of user u:
for j in the k closest items to i:
reco[j] = max(reco[j],1 - dist(i,j))
output recommendation reco
對于dist(i,j),使用型別向量之間的余弦距離,
結果
- NDCG@100: 0.011
- Personalization: 0.958
NDCG非常低,這是因為每個樣本的特征數量非常有限,
優點
無冷啟動:推薦系統(RS)中經常出現的問題之一是冷啟動,當添加新專案或用戶時,會出現此問題,由于沒有可供推斷的先前活動,推薦系統給的推薦就會有點生硬,在我們的場景中,一個專案的互動次數并不影響它最終被推薦的可能性,這意味著當涉及到新專案時,我們不存在冷啟動問題,
實作簡單:如上圖所示,使用幾行偽代碼,演算法相當簡單,
缺點
查詢時間是O(#items×#features),#代表個數,我們必須小心資料的大小,在不進行預處理的情況下,每次要求系統向用戶推薦新內容時,它都必須找到與用戶互動的每個專案最接近的k個專案,因為有專案可以比較,而每一個距離都需要計算特征來衡量,所以整個程序都需要O(#items × #features),通過預處理,我們可以終止這個查詢時間,但是我們需要在每個項中存盤k個最近的項,這意味著在記憶體中存盤k × #items 個專案,
僅當專案具有足夠的特征時才有效:如結果所示,如果專案沒有足夠的特征,則此操作不起作用,例如如果有電影情節的描述,我們會有更好的結果,
基于記憶
定義
基于記憶的推薦是一種計算用戶和專案之間相似度的簡單方法,與基于模型的方法不同,基于記憶的推薦沒有要優化的引數,這是一個非常簡單的演算法,可以概括為以下幾行偽代碼:
輸入用戶u:
使用dist函式查找與u最接近的k個用戶
在一個新向量v_u中聚集k個最近接近用戶的向量
輸出建議v_u
在我們的例子中,我們用以下方法實作了演算法:
- 對于距離函式,我們使用了漢明距離:
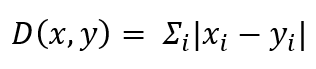
- 我們使用的聚合函式為:
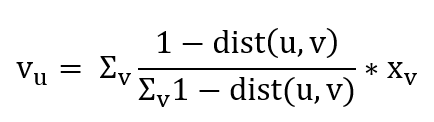
結果
-
NDCG@100: 0.173
-
Personalization: 0.715
優點
-
實作簡單:如上所示,使用少量偽代碼,演算法相當簡單,易于實作,
-
可解釋性:這是一些演算法的一個重要特性,這允許向用戶解釋為什么向他們推薦特定內容,這可以是:“我們推薦你看電影A是因為你看了電影B”,
缺點
-
復雜度:這種方法的主要問題是它會使獲得可縮放的物件變得更加困難,我們在這方面最好的朋友是本地敏感哈希(LSH)和最近鄰搜索演算法,
-
查詢時間是O(#users×#items):沒有預處理的查詢時間對每個用戶來說都很高,因為你需要以O(#items)的成本計算用戶距離,以獲得到所有其他用戶的距離,然后我們需要找到k個最接近的用戶,即O(#items),通過預處理,我們可以結束這個查詢時間,但是我們需要存盤離每個用戶最近的k個用戶,這意味著k × #users個用戶在記憶體中,
非負矩陣分解
定義
非負矩陣分解(Non-negative matrix factorization,NMF)是Netflix競賽期間出現的一種著名的推薦系統演算法,
NMF的思想是將點擊矩陣分解為兩個低維矩形矩陣,一個用于用戶,一個用于專案,嵌入到可計算維度的向量中(我們稱之為潛在空間),將這兩個矩陣相乘,得到一個新的矩陣,其值接近它們存在的原始點擊矩陣,所有的空白都用(希望)好的預測填補,
結果
- NDCG@100: 0.315
- Personalization: 0.800
優點
-
實作簡單:一些庫,如Surprise或sklearn可以實作矩陣分解!
-
潛在的可解釋性:使用一些聚類和對它們的一些分析(找到共同的演員、流派等);從技術上來說,獲得可解釋的結果是可能的,
-
查詢時間快:為了得到用戶的推薦,我們只需要乘以一個向量和一個矩陣,
缺點
- 線性模型:矩陣分解的一個主要限制是它是一個線性模型,因此它不能捕獲資料中更復雜的關系,盡管它是線性的,但我們看到它在NDCG方面給出了很好的結果,
神經矩陣分解
定義
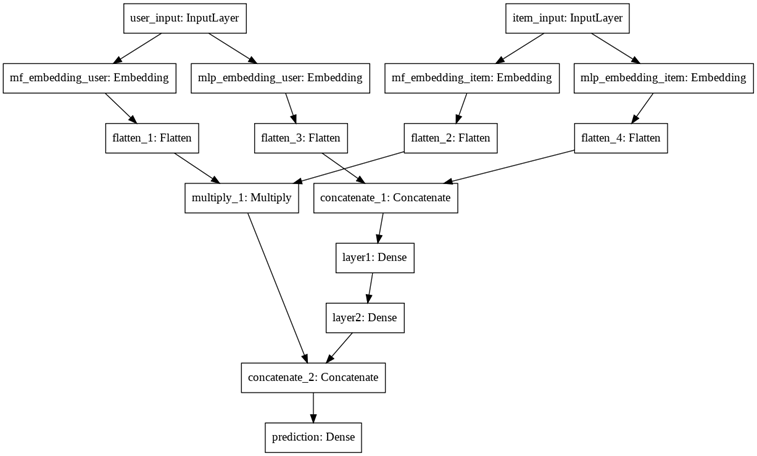
神經矩陣因式分解(NeuMF)是一種嘗試推廣上述經典NMF的新方法,它是在本文中開發的,該模型采用兩個整數(兩個索引)作為表示項i和用戶u的輸入,并輸出一個介于0和1之間的數字,輸出表示用戶u對專案i感興趣的概率,
該神經網路的結構可以分為兩部分:矩陣分解部分和全連接部分,然后連接起來傳遞到Sigmoid層,
結果
- NDCG@100: 0.173
- Personalization: 0.017
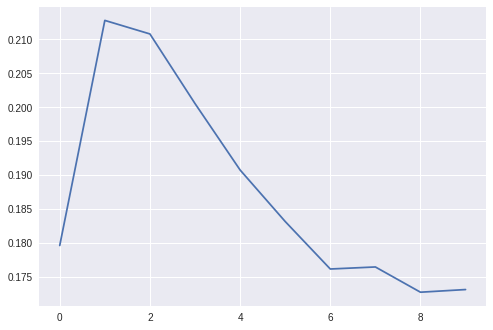
下面,盡管我試圖用許多不同的引數來正則化,但過擬合是不可避免的,
優點
- 神經網路(非線性模型):NeuMF的主要優點之一是它是一個非線性模型,因此它可以捕獲資料中更復雜的模式,然而,我們可以看到我們的NDCG比常規NMF要低,
缺點
-
對大資料集的過擬合:在最初的論文中,NeuMF改進了NMF模型,但它適用于較小的資料集,我們可以推斷,對于較大的資料集,這種方法往往會過擬合,
-
查詢時間是O(#items):此方法的問題之一是,對于給定的用戶,我們需要決議所有專案,當專案數量增加時,這可能會成為一個可伸縮性問題,
受限玻爾茲曼機
定義
受限玻爾茲曼機(RBM)是一種生成隨機神經網路,具有非常簡單的結構(一個輸入層和一個隱藏層),可以用來學習輸入上的概率分布,在我們的例子中是點擊向量,
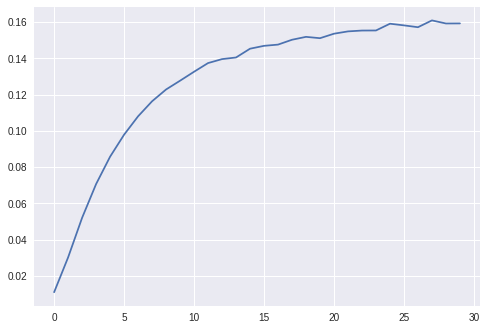
結果
- NDCG@100: 0.155
- Personalization: 0.959
下圖是驗證集上隨著epochs增加的NDCG@100
優點
- 神經網路(非線性模型):由于RBM是一個神經網路,它是一個非線性模型,所以它可以捕捉資料中更復雜的模式,
- 潛在的可解釋性:RBM從隱藏層表示的資料中學習復雜的特性,通過做一些分析(例如演員),有可能在技術上可以解釋結果,
缺點
- 長期訓練:這個模型的訓練圍繞著一種叫做吉布斯抽樣的方法,這種方法意味著大量的采樣,這是計算密集型的,
深度協同
定義
深度協同是一個直截了當的協同模型,旨在為用戶預測最有用的專案,輸入是用戶的點擊向量,原始輸出是我們的建議,為了訓練這個模型,我使用了用戶點擊向量的70%作為輸入,剩下的作為輸出,
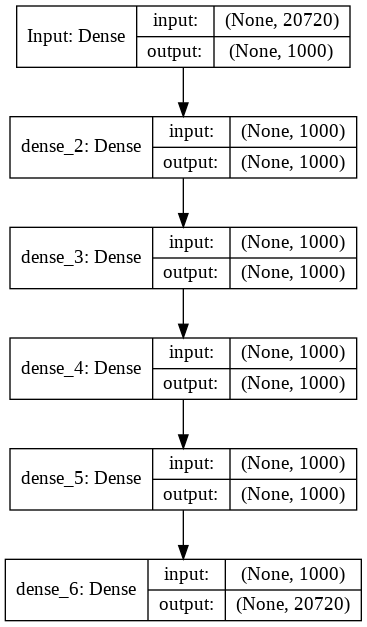
架構很簡單,有一個相同大小的輸入和輸出(#items),以及多個相同大小的隱藏層(1000個神經元),
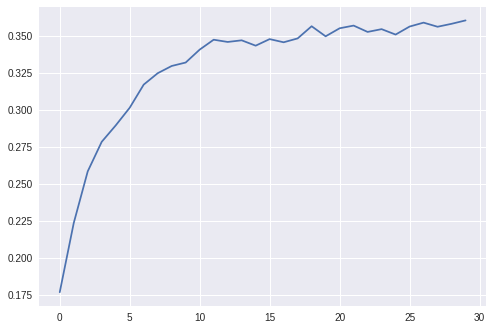
結果
- NDCG@100: 0.353
- Personalization: 0.087
下面,和往常一樣(驗證集上隨著epochs增加的NDCG@100):
優點
- 神經網路(非線性模型):深度協同是一個非線性模型,因此它可以捕獲資料中更復雜的模式,
- 查詢時間快:該模型的主要優點是,在一次正向傳遞中,我們可以獲得對給定用戶的推薦,從而縮短查詢時間,我們可以看到,模型的引數數量隨著專案數量的增加而增加,但即使如此,它仍然比NeuMF快,
缺點
- 沒有可解釋性:這種深度神經網路使得無法解釋結果,
自編碼
定義
自動編碼器(AE)最初用于學習資料的表示(編碼),它們被分解為兩部分:
編碼器,它減少了資料的維度大小;
解碼器,它將編碼轉換回其原始形式,由于存在降維,神經網路需要學習輸入(潛在空間)的低維表示,以便能夠重構輸入,
在RS環境中,它們可以用來預測新的推薦,為了做到這一點,輸入和輸出都是點擊向量(通常AE的輸入和輸出是相同的),我們將在輸入層之后使用dropout,這意味著模型將不得不重構點擊向量,因為輸入中的某個元素將會丟失,因此要學會預測給定的點擊向量的推薦值,
結果
- NDCG@100: 0.382
- Personalization: 0.154
下面慣例(驗證集上隨著epochs增加的NDCG@100),盡管我們試圖用很多不同的引數來調整,但它很快就過擬合了,
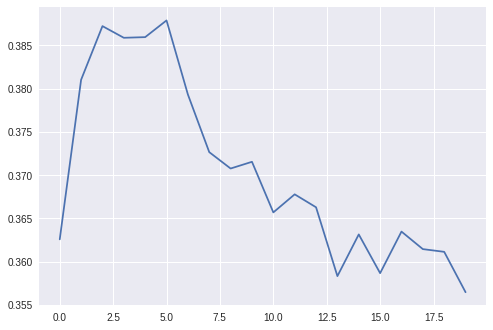
優點
- 神經網路(非線性模型):該模型是一個非線性模型,這意味著它可以捕獲資料中更復雜的模式,
- 查詢時間快:一次向前傳遞就足以獲得給定用戶的推薦,這意味著查詢時間很快,
缺點
無可解釋性:這種深度神經網路使得無法解釋結果,
變分自編碼器
定義
變分自編碼器(VAE)是AE的擴展,它將有一個采樣層,而不是簡單的全連接層,這一層將使用從編碼器的最后一層的均值和方差得到一個高斯樣本,并使用它作為輸入的解碼器,跟AE一樣,我們在第一層使用dropout,
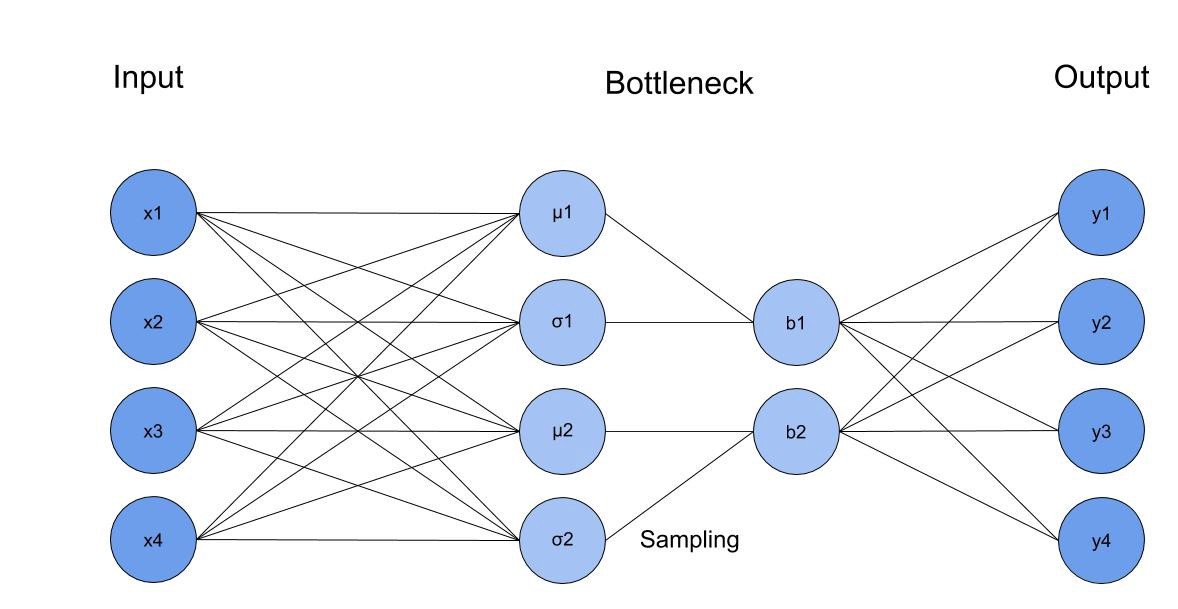
結果
- NDCG@100: 0.403
- Personalization: 0.117
下面,和往常一樣(驗證集上隨著epochs增加的NDCG@100):
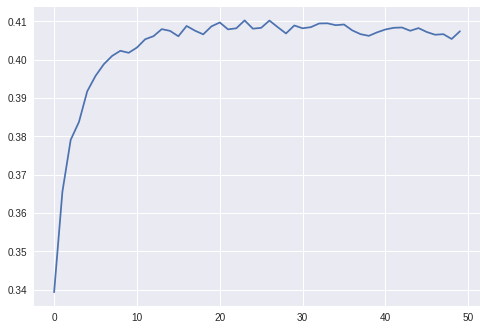
優點
- 神經網路(非線性模型):VAE是一個非線性模型,因此它可以捕獲資料中更復雜的模式,
- 查詢時間快:一次向前傳遞就足以獲得給定用戶的推薦,因此查詢時間很快,
缺點
-
更復雜的實作:采樣層使得用反向傳播計算梯度下降變得困難,重新引數化技巧使得利用方程z=ε×σ+μ,ε~N(0,1)來解決這個問題成為可能,我們現在可以安全地計算梯度了,
-
不可解釋:這種深度神經網路使得解釋結果不可行,
混合
定義
混合模型提供了兩個世界中最好的(基于記憶和基于模型的方法),因此在RS中非常流行,
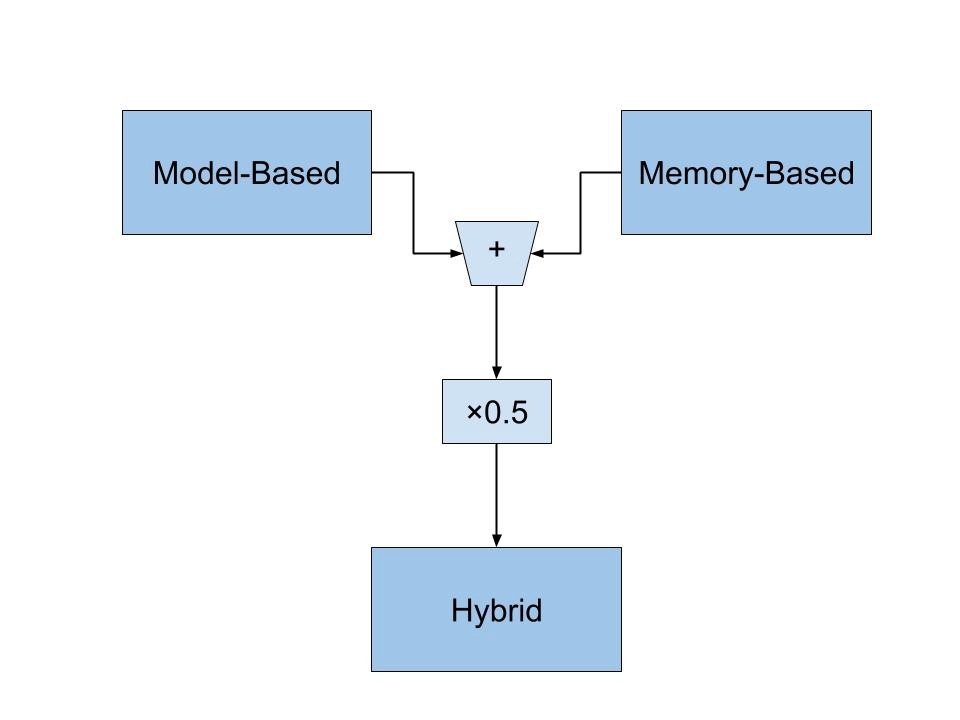
為了實作混合方法,我選擇使用VAE,然后將其結果與基于記憶的結果進行平均,
結果
- NDCG@100: 0.334
- Personalization: 0.561
優點
-
它的一部分是NN:作為VAE方法的一部分,它可以捕獲資料中更復雜的模式,
-
可解釋性:作為基于記憶的方法的一部分,我們得到了一個有趣的屬性,我們可以向用戶解釋為什么我們推薦他們一個特定的專案,
缺點
- 查詢時間是O(#users × #items):計算時間的瓶頸是基于記憶的部分,如上所示,它的查詢時間是O(#users×#items),無需預處理,
比較
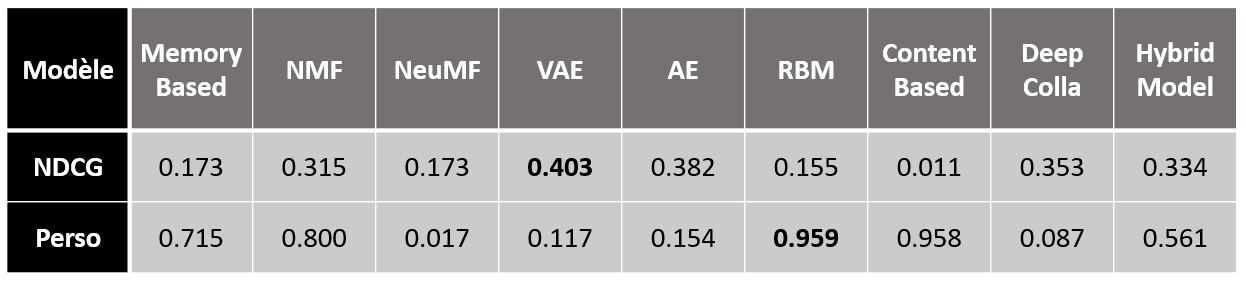
我們現在可以比較我們所有的模型,NDCG@100最好的模型看是VAE,對于個性化索引,它是RBM,
結論
在NDCG度量上,VAE、AE或深度協同等新方法的性能優于NMF等經典方法,非線性概率模型(如變分自編碼)使我們能夠超越線性因子模型的有限建模能力,
參考
- Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, Tat-Seng Chua, Neural Collaborative Filtering, 2017
- Dawen Liang, Rahul G. Krishnan, Matthew D. Hoffman, Tony Jebara,Variational autoencoders for collaborative filtering, 2018.
原文鏈接:https://medium.com/snipfeed/how-variational-autoencoders-make-classical-recommender-systems-obsolete-4df8bae51546
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/61002.html
標籤:其他
上一篇:機器學習模型的度量選擇二
下一篇:預訓練詞嵌入