作者|ARAVIND PAI
編譯|VK
來源|Analytics Vidhya
概述
-
理解預訓練詞嵌入的重要性
-
了解兩種流行的預訓練詞嵌入型別:Word2Vec和GloVe
-
預訓練詞嵌入與從頭學習嵌入的性能比較
介紹
我們如何讓機器理解文本資料?我們知道機器非常擅長處理和處理數字資料,但如果我們向它們提供原始文本資料,它們是不能理解的,
這個想法是創建一個詞匯的表示,捕捉它們的含義、語意關系和它們所使用的不同型別的背景關系,這就是詞嵌入的想法,將文本用數字表示,
預訓練詞嵌入是當今自然語言處理(NLP)領域中的一個重要組成部分,
但是,問題仍然存在——預訓練的單詞嵌入是否為我們的NLP模型提供了額外的優勢?這是一個重要的問題,你應該知道答案,
因此在本文中,我將闡明預訓練詞嵌入的重要性,對于一個情感分析問題,我們還將比較預訓練詞嵌入和從頭學習嵌入的性能,
目錄
-
什么是預訓練詞嵌入?
-
為什么我們需要預訓練的詞嵌入?
-
預訓練詞嵌入的不同模型?
-
谷歌的Word2vec
-
斯坦福的GloVe
-
-
案例研究:從頭開始學習嵌入與預訓練詞嵌入
什么是預訓練詞嵌入?
讓我們直接回答一個大問題——預訓練詞嵌入到底是什么?
預訓練詞嵌入是在一個任務中學習到的詞嵌入,它可以用于解決另一個任務,
這些嵌入在大型資料集上進行訓練,保存,然后用于解決其他任務,這就是為什么預訓練詞嵌入是遷移學習的一種形式,
遷移學習,顧名思義,就是把一項任務的學習成果轉移到另一項任務上,學習既可以是權重,也可以是嵌入,在我們這里,學習的是嵌入,因此,這個概念被稱為預訓練詞嵌入,在權重的情況下,這個概念被稱為預訓練模型,
但是,為什么我們首先需要預訓練詞嵌入呢?為什么我們不能從零開始學習我們自己的嵌入呢?我將在下一節回答這些問題,
為什么我們需要預訓練詞嵌入?
預訓練詞嵌入在大資料集上訓練時捕獲單詞的語意和句法意義,它們能夠提高自然語言處理(NLP)模型的性能,這些單詞嵌入在競賽資料中很有用,當然,在現實世界的問題中也很有用,
但是為什么我們不學習我們自己的嵌入呢?好吧,從零開始學習單詞嵌入是一個具有挑戰性的問題,主要有兩個原因:
-
訓練資料稀疏
-
大量可訓練引數
訓練資料稀疏
不這樣做的主要原因之一是訓練資料稀少,大多數現實世界的問題都包含一個包含大量稀有單詞的資料集,從這些資料集中學習到的嵌入無法得到單詞的正確表示,
為了實作這一點,資料集必須包含豐富的詞匯表,
大量可訓練引數
其次,從零開始學習嵌入時,可訓練引數的數量增加,這會導致訓練程序變慢,從零開始學習嵌入也可能會使你對單詞的表示方式處于不清楚的狀態,
因此,解決上述問題的方法是預訓練詞嵌入,讓我們在下一節討論不同的預訓練詞嵌入,
預訓練詞嵌入的不同模型
我將把嵌入大致分為兩類:單詞級嵌入和字符級嵌入,ELMo和Flair嵌入是字符級嵌入的示例,在本文中,我們將介紹兩種流行的單詞級預訓練詞嵌入:
-
谷歌的Word2vec
-
斯坦福的GloVe
讓我們了解一下Word2Vec和GloVe的作業原理,
谷歌的Word2vec
Word2Vec是Google開發的最流行的預訓練詞嵌入工具之一,Word2Vec是在Google新聞資料集(約1000億字)上訓練的,它有幾個用例,如推薦引擎、單詞相似度和不同的文本分類問題,
Word2Vec的架構非常簡單,它是一個只有一個隱藏層的前饋神經網路,因此,它有時被稱為淺層神經網路結構,
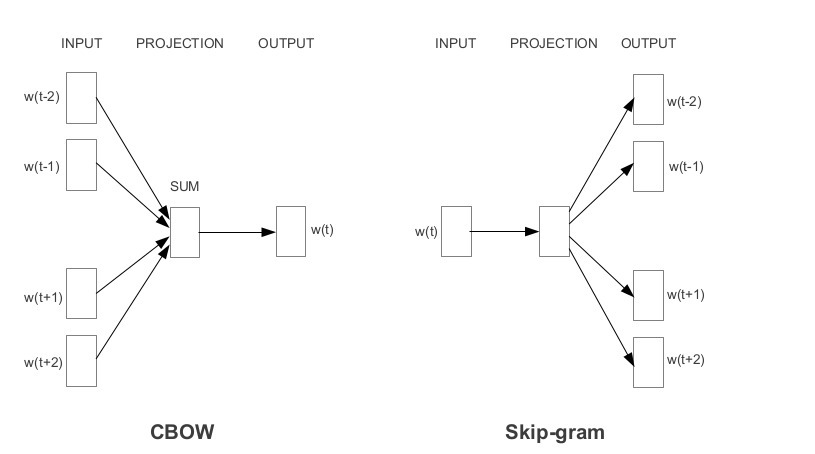
根據嵌入的學習方式,Word2Vec分為兩種方法:
-
連續詞袋模型(CBOW)
-
Skip-gram 模型
連續詞袋(CBOW)模型在給定相鄰詞的情況下學習焦點詞,而Skip-gram模型在給定詞的情況下學習相鄰詞,
連續詞袋模型模型和Skip-gram 模型是相互顛倒的,
例如,想想這句話:““I have failed at times but I never stopped trying”,假設我們想學習“failed”這個詞的嵌入,所以,這里的焦點詞是“failed”,
第一步是定義背景關系視窗,背景關系視窗是指出現在焦點詞左右的單詞數,出現在背景關系視窗中的單詞稱為相鄰單詞(或背景關系),讓我們將背景關系視窗固定為2
-
連續詞袋模型:Input=[I,have,at,times],Output=failed
-
Skip-gram 模型跳:Input = failed, Output = [I, have, at, times ]
如你所見,CBOW接受多個單詞作為輸入,并生成一個單詞作為輸出,而Skip gram接受一個單詞作為輸入,并生成多個單詞作為輸出,
因此,讓我們根據輸入和輸出定義體系結構,但請記住,每個單詞作為一個one-hot向量輸入到模型中:
斯坦福的GloVe
GloVe嵌入的基本思想是從全域統計中匯出單詞之間的關系,
但是,統計數字怎么能代表意義呢?讓我解釋一下,
最簡單的方法之一是看共現矩陣,共現矩陣告訴我們一對特定的詞在一起出現的頻率,共現矩陣中的每個值都是一對詞同時出現的計數,
例如,考慮一個語料庫:“play cricket, I love cricket and I love football”,語料庫的共現矩陣如下所示:
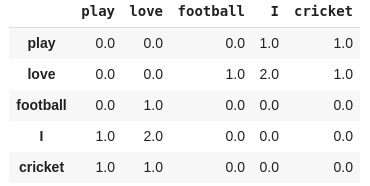
現在,我們可以很容易地計算出一對詞的概率,為了簡單起見,讓我們把重點放在“cricket”這個詞上:
p(cricket/play)=1
p(cricket/love)=0.5
接下來,我們計算概率比:
p(cricket/play) / p(cricket/love) = 2
當比率大于1時,我們可以推斷板球最相關的詞是“play”,而不是“love”,同樣,如果比率接近1,那么這兩個詞都與板球有關,
我們可以用簡單的統計方法得出這些詞之間的關系,這就是GLoVE預訓練詞嵌入的想法,
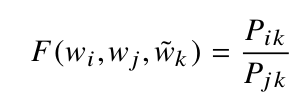
案例研究:從頭開始學習嵌入與預訓練詞嵌入
讓我們通過一個案例來比較從頭開始學習我們自己的嵌入和預訓練詞嵌入的性能,我們還將了解使用預訓練詞嵌入是否會提高NLP模型的性能?
所以,讓我們選擇一個文本分類問題-電影評論的情感分析,從這里下載電影評論資料集(https://www.kaggle.com/columbine/imdb-dataset-sentiment-analysis-in-csv-format),
將資料集加載到Jupyter:
#匯入庫
import pandas as pd
import numpy as np
#讀取csv檔案
train = pd.read_csv('Train.csv')
valid = pd.read_csv('Valid.csv')
#訓練測驗集分離
x_tr, y_tr = train['text'].values, train['label'].values
x_val, y_val = valid['text'].values, valid['label'].values
準備資料:
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer()
#準備詞匯表
tokenizer.fit_on_texts(list(x_tr))
#將文本轉換為整數序列
x_tr_seq = tokenizer.texts_to_sequences(x_tr)
x_val_seq = tokenizer.texts_to_sequences(x_val)
#填充以準備相同長度的序列
x_tr_seq = pad_sequences(x_tr_seq, maxlen=100)
x_val_seq = pad_sequences(x_val_seq, maxlen=100)
讓我們看一下訓練資料中的單詞個數:
size_of_vocabulary=len(tokenizer.word_index) + 1 #+1用于填充
print(size_of_vocabulary)
Output: 112204
我們將構建兩個相同架構的不同NLP模型,第一個模型從零開始學習嵌入,第二個模型使用預訓練詞嵌入,
定義架構從零開始學習嵌入:
#深度學習庫
from keras.models import *
from keras.layers import *
from keras.callbacks import *
model=Sequential()
#嵌入層
model.add(Embedding(size_of_vocabulary,300,input_length=100,trainable=True))
#lstm層
model.add(LSTM(128,return_sequences=True,dropout=0.2))
#Global Max池化
model.add(GlobalMaxPooling1D())
#Dense層
model.add(Dense(64,activation='relu'))
model.add(Dense(1,activation='sigmoid'))
#添加損失函式、度量、優化器
model.compile(optimizer='adam', loss='binary_crossentropy',metrics=["acc"])
#添加回呼
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1,patience=3)
mc=ModelCheckpoint('best_model.h5', monitor='val_acc', mode='max', save_best_only=True,verbose=1)
#輸出模型
print(model.summary())
輸出:

模型中可訓練引數總數為33889169,其中,嵌入層貢獻了33661200個引數,引數太多了!
訓練模型:
history = model.fit(np.array(x_tr_seq),np.array(y_tr),batch_size=128,epochs=10,validation_data=https://www.cnblogs.com/panchuangai/p/(np.array(x_val_seq),np.array(y_val)),verbose=1,callbacks=[es,mc])
評估模型的性能:
#加載最佳模型
from keras.models import load_model
model = load_model('best_model.h5')
#評估
_,val_acc = model.evaluate(x_val_seq,y_val, batch_size=128)
print(val_acc)
輸出:0.865
現在,是時候用GLoVE預訓練的詞嵌入來構建第二版了,讓我們把GLoVE嵌入到我們的環境中:
# 將整個嵌入加載到記憶體中
embeddings_index = dict()
f = open('../input/glove6b/glove.6B.300d.txt')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Loaded %s word vectors.' % len(embeddings_index))
輸出:Loaded 400,000 word vectors.
通過為詞匯表分配預訓練的詞嵌入,創建嵌入矩陣:
# 為檔案中的單詞創建權重矩陣
embedding_matrix = np.zeros((size_of_vocabulary, 300))
for word, i in tokenizer.word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
定義架構-預訓練嵌入:
model=Sequential()
#嵌入層
model.add(Embedding(size_of_vocabulary,300,weights=[embedding_matrix],input_length=100,trainable=False))
#lstm層
model.add(LSTM(128,return_sequences=True,dropout=0.2))
#Global Max池化
model.add(GlobalMaxPooling1D())
#Dense層
model.add(Dense(64,activation='relu'))
model.add(Dense(1,activation='sigmoid'))
#添加損失函式、度量、優化器
model.compile(optimizer='adam', loss='binary_crossentropy',metrics=["acc"])
#添加回呼
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1,patience=3)
mc=ModelCheckpoint('best_model.h5', monitor='val_acc', mode='max', save_best_only=True,verbose=1)
#輸出模型
print(model.summary())
輸出:

如你所見,可訓練引數的數量僅為227969,與嵌入層相比,這是一個巨大的下降,
訓練模型:
history = model.fit(np.array(x_tr_seq),np.array(y_tr),batch_size=128,epochs=10,validation_data=https://www.cnblogs.com/panchuangai/p/(np.array(x_val_seq),np.array(y_val)),verbose=1,callbacks=[es,mc])
評估模型的性能:
#加載最佳模型
from keras.models import load_model
model = load_model('best_model.h5')
#評估
_,val_acc = model.evaluate(x_val_seq,y_val, batch_size=128)
print(val_acc)
輸出:88.49
與從頭學習嵌入相比,使用預訓練詞嵌入的性能有所提高,
結尾
預訓練詞嵌入是有力的文本表示方式,因為它們往往捕捉單詞的語意和句法意義,
在本文中,我們了解了預訓練詞嵌入的重要,并討論了兩種流行的預訓練詞嵌入:Word2Vec和gloVe,
原文鏈接:https://www.analyticsvidhya.com/blog/2020/03/pretrained-word-embeddings-nlp/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/61006.html
標籤:其他