一、概念
查找表(Search Table)是由同一型別的資料元素構成的集合,它是一種以查找為“核 心”,同時包括其他運算的非常靈活的資料結構,
查找就是從大量的資料元素中找出某個指定的資料元素,關鍵字分為主關鍵字和次關 鍵字兩種,前者可以唯一標識一個資料元素,即對于不同的資料元素其主關鍵字均不同; 后者則可以識別若干資料元素,
靜態查找表是以具有相同特性的資料元素集合為邏輯結構,包括下列三種基本運算 :建表 Create(ST)、查找 Search(ST, key)、 讀表中元素 Get(ST, pos)
動態查找表是以集合為邏輯結構,包括下列五種基本運算: 初始化 Initiate (ST)、查找 Search(ST,key)、讀表中元素 Get(ST, pos)、 插入 Insert(ST,key)、 洗掉 Delete(ST,key),、
二、靜態查找表
1、順序查找
從表中 最后一個 記錄開始 順序 進行查找,若當前記錄的關鍵字= 給定值,則 查找成功 ;否則,繼續查上一記錄…;若直至第一個記錄尚未找到需要的記錄,則 查找失敗
//使用一種 設計技巧 :設立 崗哨 int SearchSqtable(Sqtable T, KeyType key){ /* 在順序表R 中順序查找其關鍵字等于key 的元素, 若找到,則函式值為該元素在表中的位置,否則為0*/ T.elem[0].key=key; //設定崗哨 i=T.n;//設定比較位置初值 while ( T.elem[i].key!=key ){ i-- } return i ; }
查找成功:最少1次、最多 n+1次 、 平均查找長度=(n+1)/2
查找失敗:n+1次
例如:假設順序表的(b1,b2,b3)的概率是0.2,0.2,0.6,順序查找的平均長度?
ASL=0.2*(3-1+1)+0.2(3-2+1)+0.6(3-3+1)=1.6
時間復雜度:n
2、有序表上的查找—二分查找
二分查找基本思想: 每次將處于查找區間中間位置上的資料元素與給定值K 比較,若不等則縮小查找區間并在新的區間內重復上述程序,直到查找成功或查找區間長度為0 (查找不成功)為止
有序表:如果順序表中資料元素是按照鍵值大小的順序排列的,則稱為有序表,
演算法程序:
- 1、用給定值 key 與處在中間位置的資料元素 T.elem[mid]的鍵值 T.elem[mid] .key 進行 比較,可根據三種比較結果區分三種情況:
- 2、key=T.elem[mid].key,查找成功,T.elemEmid]即為待查元素;
- 3、key<t.elem[mid].key,說明若待查元素若在表中,則一定排在 t.elem[mid]="" 之前;
- 4、key>T.elem[mid].key,說明若待查元素若在表中,則一定排在 T.elem[mid]之后,
/*在有序表 T 中,用二分查找法查找鍵值等于 key 的元素,變數 low,hig 分別標記查找 區間的下界和上界*/ int SearchBin{SqTable T,KeyType key){ int low,high; low=l;high=T.n; //置查找區間初值 while (low<=high){ //區間長度不為 0 時繼續查找 mid= (low+high) /2; //對區間進行折半,〃/〃為整除 if (key==T.elem[mid].key){ return mid; } else if(key<T.elem[mid] .key){ high=mid-1; //在前半區間查找 } else { low=mid+1; //在后半區間查找 } } return 0; //查找不成功,則回傳 }

時間復雜度:log2n
3、索引順序表上的查找-分塊查找
索引順序表是結合了順序查找和二分查找的優點構造的一種帶索引的存盤結構
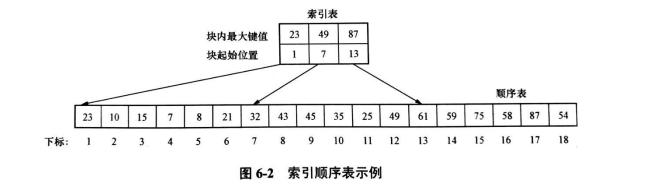
一個索引順序表由兩部分組成:一個索引表和一個順序表,其中的順序表在組織形式上 與普通的順序表完全相同,而索引表本身在組織形式上也是一個順序表,索引表通過索引將 順序表分割為若干塊,而順序表呈現出“按塊有序”的性質,
若靜態查找表用索引順序表表示,則查找操作可用分塊查找來實作,也稱為索引順序查 找,根據上面對索引順序表的描述,在索引順序表上的查找即分塊查找分兩步進行:先確定 待查資料元素所在的塊;然后在塊內順序查找,

二、動態查找表
1、二叉排序樹上的查找
二叉排序樹:一種實作動態查找的樹表——二叉排序樹,這種樹表的結構本身是在查找程序中動態 生成的,即對于給定 key,若表中存在與 key 相等的元素,則查找成功,不然,插入關鍵字 等于 key 的元素, 一棵二叉排序樹(Binary Sort Tree)(又稱二叉查找樹)或者是一棵空二叉樹,或者是具有下列性質的二叉樹:
- (1) 若它的左子樹不空,則左子樹上所有結點的鍵值均小于它的根結點鍵值;
- (2) 若它的右子樹不空,則右子樹上所有結點的鍵值均大于它的根結點鍵值;
- (3) 根的左、右子樹也分別為二叉排序樹,

中序遍歷一棵二叉排序樹所得的結點訪問序列是鍵值的遞增序列:1,2,3,4,5,6,7
在二叉排序樹上進行插入的原則是:必須要保證插入一個新結點后,仍為一棵二叉排序 樹,這個結點是查找不成功時查找路徑上訪問的最后一個結點的左孩子或右孩子,
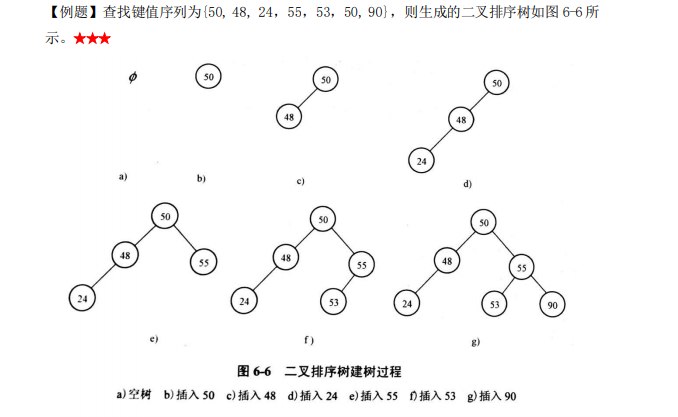
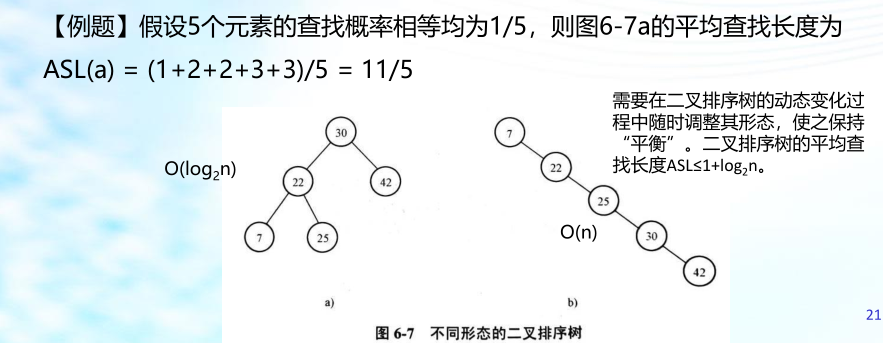
二叉排序樹的查找分析:二叉排序樹上的平均查找長度是介于O(n)和O(log 2 n)之間的,其查找效率與樹的形態(樹的生成程序)有關
二叉排序樹的平均查找長度:O(log 2 n) ;最壞情況下單支樹 平均查找長度:ASL=(n+1)/2;
二叉樹的查找長度不僅與節點的數量有關,還與二叉排序樹的生產程序有關
由n個鍵值構造的二叉排序樹,在等概率查找的假設下,查找成功的平均查找長度的最大值可能達到 (n+1)/2
2、散串列
散列函式:資料元素的鍵值和存盤位置 T 之間建立的對應關系 H 稱為散列函式,用鍵值通過散列函式獲取存盤位置的這種存盤方式構造的存盤結構稱為散串列,這一映射程序稱為散列或哈希造表,所得存盤位置稱散列地址或哈希地址,
散串列進行查找的基本出發點是:減少查找程序中的比較次數

散列地址—— 由散列函式決定資料元素的存盤位置,該位置稱為散列地址,
散串列—— 通過散列法建立的表稱為散串列
常用散列法
若對于鍵值集合中的任一個鍵值,經散列函式映射到地址集合中任何一個地址的概率是相等的,則稱此種散列函式是均勻的,
- 1、數字分析法
- 2、除留余數法:除留余數法是一種簡單有效且最常用的構造方法,其方法是選擇一個不大于散串列長n的正整數p,以鍵值除以p所得的余數作為散列地址,即H(key)=key mod p(p≤n)注意:通常選 p 為小于散串列長度 n 的素數,
- 3、平方取中法
- 4、基數轉換法
質數又稱為素數,是一個大于1的自然數,除了1和它自身外,不能被其他自然數整除的數叫做質數
散列法主要作業
- 選擇一個好的散列函式:函式計算簡便,運算速度快;隨機性好,地址盡可能均勻分布;沖突小
- 解決沖突
散串列的實作
通常用來解決沖突的方法有以下幾種:
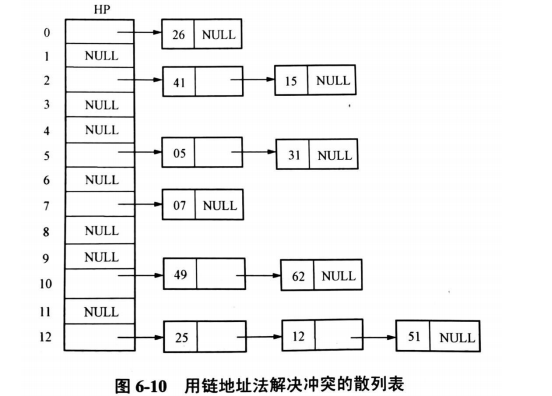
1、鏈地址法:避免沖突
思想:將散列地址相同記錄存盤在同一單鏈表中(稱同義詞表),同時按散列地址設立一個表頭指標向量,
例如,若選定的散列函式為H(key)=key mod 13,已存入鍵值為 26,41,25,05, 07,15,12, 49, 51, 31, 62 散串列,



轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/65498.html
標籤:其他
上一篇:PAT B# 1025 反轉鏈表
下一篇:資料結構導論之第五章圖