文章作者:凌逆戰
文章地址:https://www.cnblogs.com/LXP-Never/p/11703440.html
回聲就是聲音信號經過一系列反射之后,又聽到了自己講話的聲音,這就是回聲,一些回聲是必要的,比如劇院里的音樂回聲以及延遲時間較短的房間回聲;而大多數回聲會造成負面影響,比如在有線或者無線通信時重復聽到自己講話的聲音(回想那些年我們開黑打游戲時,如果其中有個人開了外放,他的聲音就會回蕩來回蕩去),因此消除回聲的負面影響對通信系統是十分必要的,
針對回聲消除(Acoustic Echo Cancellation,AEC )問題,現如今最流行的演算法就是基于自適應濾波的回聲消除演算法,本文從回聲信號的兩種分類以及 AEC 的基本原理出發,介紹幾種經典的 AEC 演算法并對其性能進行闡釋,
回聲分類
在通信系統中,回聲主要分為兩類:電路回聲和聲學回聲
電路回聲
電路回聲通常產生于有線通話中,為了降低電話中心局與電話用戶之間電話線的價格,用戶間線的連接采用兩線制;而電話中心局之間連接采用四線制(上面兩條線路用于發送給用戶端信號,下面兩條線路用于接收用戶端信號),問題就出來了,造成電路回聲的根本原因是轉換混合器的二線-四線阻抗不能完全匹配(使用的不同型號的電線或者負載線圈沒有被使用的原因),導致混合器 接收線路 上的語音信號流失到了 發送線路 ,產生了回聲信號,使得另一端的用戶在接收信號的同時聽到了自己的聲音,
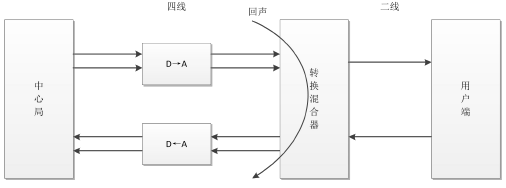
電路回聲產生原理
在現如今的數字通信網路中,轉換混合器與數模轉換器融為一體,但無論是模擬電子線路還是數字電子線路,二-四線的轉換都會造成阻抗不匹配問題,從而導致其產生電路回聲,影響現代通信質量,由于電路回聲的線性以及穩定性,用一個簡單的線性疊加器就可以實作電路回聲消除,首先將產生的回聲信號在數值上取反,線性地疊加在回聲信號上,將產生的回聲信號抵消,實作電路回聲的初步消除,然而由于技術缺陷,線性疊加器不能完整地將回聲信號抹去,因此需要添加一個非線性處理器,其實質是一個阻擋信號的開關,將殘余的回聲信號經過非線性處理之后,就可以實作電路回聲的消除,或者得到噪聲很小的靜音信號,由于電路回聲信號是線性且穩定的,所以比較容易將其消除,而本文主要研究的是如何消除非線性的聲學回聲,
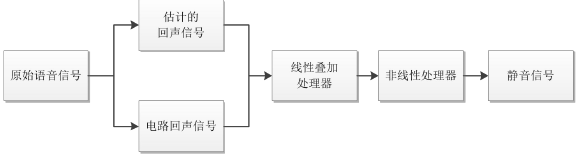
電路回聲消除的基本原理
聲學回聲
在麥克風與揚聲器互相作用影響的雙工通信系統中極易產生聲學回聲,如下圖所示
遠端講話者A-->麥克風A-->電話A-->電話B---->揚聲器B--->麥克風B-->電話B-->電話A-->揚聲器A--->麥克風A--->.........就這樣無限回圈,
詳細講解:遠端講話者A的話語被麥克風采集并傳入至通信設備,經過無線或有線傳輸之后達到近端的通信設備,并通過近端 B 的揚聲器播放,這個聲音又會被近端 B 的麥克風拾取至其通信設備形成聲學回聲,經傳輸又回傳了遠端 A 的通信設備,并通過遠端 A 的揚聲器播放出來,從而遠端講話者就聽到了自己的回聲,
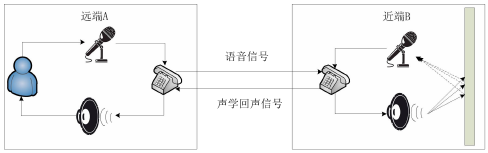
聲學回聲產生原理
| 近端(near-end) | 遠端(far-end) |
| 近端麥克風 | 遠端麥克風 |
| 近端揚聲器 | 遠端揚聲器 |
近端語音信號:說話人說話 被近端麥克風采集的信號
遠端語音信號:遠端的語音信號通過近端揚聲器播放,與房間的回聲路徑卷積后 被近端麥克風采集到的語音信號
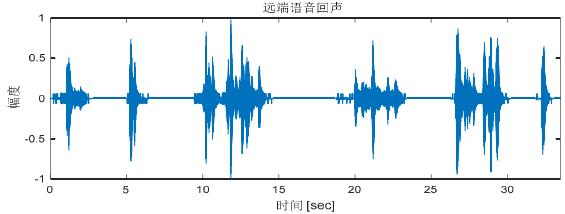
近端混合回聲信號:整個對話程序中,近端麥克風接收到的信號有近端說話人的語音信號和遠端說話人通過揚聲器播放的語音信號,這樣疊加的語音信號通過傳輸線路傳到遠端揚聲器播放導致遠端人聽到自己剛剛檢測出的語音信號,即所謂的回聲,
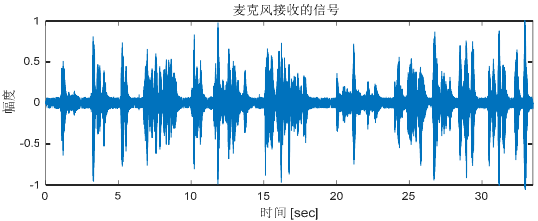
聲學回聲信號根據傳輸途徑的差別可以分別直接回聲信號和間接回聲信號,
直接回聲:近端揚聲器B將語音信號播放出來后,近端麥克風B直接將其采集后得到的回聲,
直接回聲不受環境的印象,與揚聲器到麥克風的距離及位置有很大的關系,因此直接回聲是一種線性信號,
間接回聲:近端揚聲器B將語音信號播放出來后,語音信號經過復雜多變的墻面反射后由近端麥克風B將其拾取,
間接回聲的大小與房間環境、物品擺放以及墻面吸引系數等等因素有關,因此間接回聲是一種非線性信號,
回聲消除技術主要用于在免提電話、電話會議系統等情形中,
AEC的基本原理
回聲消除常用方法
- 聲場環境材料處理
- 墻壁、天花板換成吸音材料,有效的較少聲音的反射,
- 可以較為直接的抑制間接噪聲,但是直接噪聲無法抑制;成本較高
- 回聲抑制器
- 通過一個電平對比單元 輪流打開和關閉揚聲器和麥克風
- 導致功放設備的輸出信號不連續,總體效果不好
- 自適應回聲抵消(用的最多)
- 首先通過自適應演算法來調整濾波器的迭代更新系數來估計出與實際回聲路徑逼近的期望信號,也就是模擬回聲,然后從麥克風采集的混合信號中減去這個模擬回聲,達到回聲抵消的功能
如今解決 AEC 問題最常用的方法,就是
使用不同的自適應濾波演算法調整濾波器的權值向量,估計一個近似的回聲路徑來逼近真實回聲路徑,從而得到估計的回聲信號,并在純凈語音和回聲的混合信號中除去此信號來實作回聲的消除,
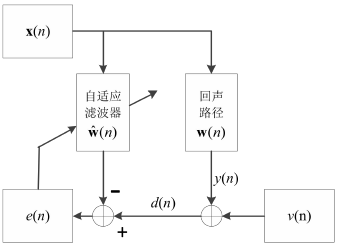
AEC的基本原理
$x(n)$為遠端輸入信號,經過未知的回聲路徑$w(n)$得到$y(n)=x(n)*w(n)$,再加上觀測噪聲$v(n)$,得到期望信號$d(n)= y(n) + v(n)$,x(n)通過自適應濾波器$\hat{w}(n)$得到估計的回聲信號,并與期望信號$d(n)$相減得到誤差信號$e(n)$,即$e(n)=d(n)-\hat{w}^T(n)x(n)$,誤差信號的值越小說明自適應濾波演算法所估計的回聲路徑就越接近實際的回聲路徑,
濾波器采用特定的自適應演算法不停地調整權值向量,使估計的回聲路徑$\hat{w}(n)$逐漸趨近于真實回聲路徑$w(n)$,顯然,在 AEC 問題中,自適應濾波器的選擇對回聲消除的性能好壞起著十分關鍵的作用,
自適應濾波器的基本原理
自適應濾波器是一個對輸入信號進行處理并不停學習,直到其達到期望值的器件,自適應濾波器在輸入信號非平穩條件下,也可以根據環境不斷調節濾波器權值向量,使演算法達到特定的收斂條件,從而實作自適應濾波程序,
自適應濾波器按輸入信號型別可分為模擬濾波器和離散濾波器,本文中使用的是離散濾波器中的數字濾波器(數字濾波器按結構可劃分為輸入不僅與過去和當前的輸入有關、還與過去的輸出有關的無限沖激回應濾波器(IIR),以及輸出與有限個過去和當前的輸入有關的有限沖激回應濾波器(FIR))為了使得自適應濾波器具有更強的穩定性,并且具有足夠的濾波器系數可以用來調整以達到特定的收斂準則,一般選取橫向的 FIR 濾波器進行來進行回聲的消除,(解釋:無限沖激回應型別的優勢在于零極點都包含于傳遞函式中,所以 IIR 能夠實作較低的階數構造較為理想化的尖銳帶通特性的傳遞函式,而劣勢也很明顯,即極點會造成量化誤差大,使系統魯棒性下降,并且對相位特性的控制變得困難;FIR(有限沖擊回應濾波器)的傳遞函式都是零點,所以魯棒性很穩定,相對而言更能實作線性特性)
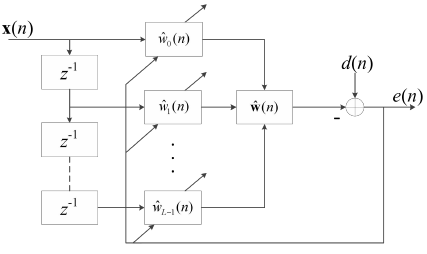
橫向FIR濾波器結構框圖
$x(n)$是遠端輸入信號,$\hat{w}_i(n)$是濾波器系數,其中$i=0,1,...,L-1$,$L$為濾波器的長度,$n$為采樣點數,$\hat{w}(n)$為濾波器的權值向量且$\hat{w}(n)=[\hat{w}_0(n),\hat{w}_1(n),...,\hat{w}_{L-1}(n)]^T$,根據誤差信號$e(n)=d(n)-\hat{w}^T(n)x(n)$的值以及不同演算法的收斂準則調整濾波器的權值向量,
然而自適應濾波演算法的選擇從根本上決定了回聲消除的效果是否良好,接下來將介紹幾種解決 AEC 問題的經典自適應濾波演算法,
回聲消除常用演算法
LSM演算法
通過上面AEC的基本原理我們知道了誤差信號$e(n)$等于期望信號減去濾波器輸出信號:
$$e(n)=d(n)-\hat{w}^T(n)x(n)$$
運用最小均方誤差準則,通過對其求導并令其等于0,求到使得誤差$|e(n)|^2$最小時的$w$($|e(n)|$在最小點不可導,所以使用的是$|e(n)|^2$),對于LMS演算法,其濾波器系數迭代公式為
$$w(n+1)=w(n)+\mu\frac{\partial e(n)^2}{\partial w}\\\qquad\qquad =w(n)+2\mu e(n)\frac{\partial (d(n)-w*x(n))}{\partial w}\\\qquad\qquad =w(n)+2\mu e(n)x(n)$$
式中,$\mu$為固定步長因子,$\mu$的大小很大程度上決定了演算法的收斂與穩態性能,$\mu$越大,演算法收斂越快,但穩態誤差也越大;$\mu$越小,演算法收斂越慢,但穩態誤差也越小,為保證演算法穩態收斂,應使$\mu$在以下范圍取值:
$$0 < \mu < \frac{2}{{\sum\limits_{i = 1}^N {x(i)_{}^2} }}$$
LMS演算法實作
LMS演算法的每次迭代都需要三個不同的步驟,順序如下
1、FIR濾波器輸出$y(n)$
$$y(n)=\sum_{i=0}^{N-1}w(n)x(n-i)=w^T(n)x(n)$$
2、估計誤差
$$e(n)=d(n)-y(n)$$
3、FIR向量的抽頭權值更新,以準備下一次迭代
$$w(n+1)=w(n)+2\mu e(n)x(n)$$


clear;clc; snr=20; % 信噪比 order=8; % 自適應濾波器的階數為8 % Hn是濾波器權重 Hn =[0.8783 -0.5806 0.6537 -0.3223 0.6577 -0.0582 0.2895 -0.2710 0.1278 ... % ...表示換行的意思 -0.1508 0.0238 -0.1814 0.2519 -0.0396 0.0423 -0.0152 0.1664 -0.0245 ... 0.1463 -0.0770 0.1304 -0.0148 0.0054 -0.0381 0.0374 -0.0329 0.0313 ... -0.0253 0.0552 -0.0369 0.0479 -0.0073 0.0305 -0.0138 0.0152 -0.0012 ... 0.0154 -0.0092 0.0177 -0.0161 0.0070 -0.0042 0.0051 -0.0131 0.0059 ... -0.0041 0.0077 -0.0034 0.0074 -0.0014 0.0025 -0.0056 0.0028 -0.0005 ... 0.0033 -0.0000 0.0022 -0.0032 0.0012 -0.0020 0.0017 -0.0022 0.0004 -0.0011 0 0]; Hn=Hn(1:order); mu=0.02; % mu表示步長 N=1000; % 設定1000個音頻采樣點 Loop=150; % 150次回圈 EE_LMS = zeros(N,1); % 誤差初始化 for nn=1:Loop % epoch=150 win_LMS = zeros(1,order); % 權重初始化w error_LMS=zeros(1,N)'; % 初始化誤差 % 均勻分布的語音資料輸入 r=sign(rand(N,1)-0.5); % shape=(1000,1)的(0,1)均勻分布-0.5,sign(n)>0=1;<0=-1 % 聲學環境語音輸出:輸入卷積Hn得到 輸出 output=conv(r,Hn); % r卷積Hn,output長度=length(u)+length(v)-1 output=awgn(output,snr,'measured'); % 加一點環境噪聲:將白高斯噪聲添加到信號中 for i=order:N % i=8:1000 input=r(i:-1:i-order+1); % 每次迭代取8個資料進行處理 e_LMS = output(i)-win_LMS*input; win_LMS = win_LMS+2*mu*e_LMS*input'; error_LMS(i)=error_LMS(i)+e_LMS^2; end % 把總誤差相加 EE_LMS = EE_LMS+error_LMS; end % 對總誤差求平均值 error_LMS = EE_LMS/Loop; figure; error1_LMS=10*log10(error_LMS(order:N)); plot(error1_LMS,'b.'); % 藍色 axis tight; % 使用緊湊的坐標軸 legend('LMS演算法'); % 圖例 title('LMS演算法誤差曲線'); % 圖示題 xlabel('樣本'); % x軸標簽 ylabel('誤差/dB'); % y軸標簽 grid on; % 網格線MATLAB演算法實作
我們將演算法用到音頻效果中,音頻獲取地址,代碼如下
clear;clc; snr=20; % 信噪比 order=8; % 自適應濾波器的階數為8 [d, fs_orl] = audioread('./audio/handel.wav'); % 期望輸出(73113,1) [x, fs_echo] = audioread('./audio/handel_echo.wav'); % 回聲輸入 mu=0.02; % mu表示步長 0.02, N=length(x); Loop=10; % 150次回圈 EE_LMS = zeros(N,1); y_LMS = zeros(N,1); for nn=1:Loop % epoch=150 win_LMS = zeros(order,1); % 自適應濾波器權重初始化w y = zeros(N,1); % 輸出 error_LMS=zeros(N,1); % 誤差初始化 for i=order:N % i=8:73113 input=x(i:-1:i-order+1); % 每次迭代取8個資料進行處理,(8,1)->(9,2) y(i)=win_LMS'*input; % (8,1)'*(8*1)=1 error_LMS(i) = d(i)-y(i); % (8,1)'*(8,1)=1 win_LMS = win_LMS+2*mu*error_LMS(i)*input; error_LMS(i)=error_LMS(i)^2; % 記錄每個采樣點的誤差 end % 把總誤差相加 EE_LMS = EE_LMS+error_LMS; y_LMS=y_LMS+y; end error_LMS = EE_LMS/Loop; % 對總誤差求平均值 y_LMS=y_LMS/Loop; % 對輸出求平均 audiowrite("audio/done.wav", y_LMS, fs_orl); sound(y_LMS) % 聽一聽回聲消除后的音效 figure; error1_LMS=10*log10(error_LMS(order:N)); plot(error1_LMS,'b.'); % 藍色 axis tight; % 使用緊湊的坐標軸 legend('LMS演算法'); % 圖例 title('LMS演算法誤差曲線'); % 圖示題 xlabel('樣本'); % x軸標簽 ylabel('誤差/dB'); % y軸標簽 grid on; % 網格線
LMS演算法在自適應濾波中流行的主要原因是其計算簡單,比其他常用的自適應演算法更易于實作,對于每次迭代,LMS演算法需要2N加法和2N+1乘法,但是總體而言,LMS 演算法復雜性低,它的收斂速度還是慢,而且是固定步長,這就需要在開始自適應濾波操作之前了解輸入信號的統計資訊,實際上,這是很難實作的,即使我們假設自適應回聲抵消系統的唯一輸入信號是語音,但仍有許多因素如信號輸入功率和振幅會影響其性能,為改善 LMS 這個不足之處,科研人員提出一系列改進演算法,NLMS 演算法就是其中一種,
NLMS演算法
歸一化最小均方(NLMS)演算法是LMS演算法的一個擴展,利用可變的步長因子代替固定的步長因子,就得到了NLMS演算法,它通過計算最大步長值繞過了這個問題,
$$步長=\frac{1}{x^T(n)x(n)}$$
這個步長與輸入向量$x(n)$的系數的瞬時值的總期望能量的倒數成正比,輸入樣本的期望能量之和也等于輸入向量與自身的點積,
NLMS演算法迭代方程為
$$w(n+1)=w(n)+\mu(n)e(n)x(n)=w(n)+\frac{1}{x^T(n)x(n)}e(n)x(n)$$
NLMS演算法實作
由于步長引數是根據當前的輸入值來選擇的,因此NLMS演算法在未知信號下具有更大的穩定性,該演算法具有良好的收斂速度和相對簡單的計算能力,是實時自適應回波抵消系統的理想演算法,
NLMS演算法的每次迭代都需要按照以下順序執行這些步驟,
1、計算了自適應濾波器的輸出
$$y(n)=\sum_{i=0}^{N-1}w(n)x(n-i)=w^T(n)x(n)$$
2、計算誤差信號:期望信號和濾波器輸出之間的差值
$$e(n)=d(n)-y(n)$$
3、計算輸入向量的步長值
$$\mu(n)=\frac{1}{x^T(n)x(n)}$$
4、更新濾波器抽頭權重,為下一次迭代做準備
$$w(n+1)=w(n)+\mu (n)e(n)x(n)$$
clear; clc; snr=20; % 信噪比 order=8; % 自適應濾波器的階數為8 % 房間聲學環境脈沖回應 Hn =[0.8783 -0.5806 0.6537 -0.3223 0.6577 -0.0582 0.2895 -0.2710 0.1278 ... % ...表示換行的意思 -0.1508 0.0238 -0.1814 0.2519 -0.0396 0.0423 -0.0152 0.1664 -0.0245 ... 0.1463 -0.0770 0.1304 -0.0148 0.0054 -0.0381 0.0374 -0.0329 0.0313 ... -0.0253 0.0552 -0.0369 0.0479 -0.0073 0.0305 -0.0138 0.0152 -0.0012 ... 0.0154 -0.0092 0.0177 -0.0161 0.0070 -0.0042 0.0051 -0.0131 0.0059 ... -0.0041 0.0077 -0.0034 0.0074 -0.0014 0.0025 -0.0056 0.0028 -0.0005 ... 0.0033 -0.0000 0.0022 -0.0032 0.0012 -0.0020 0.0017 -0.0022 0.0004 -0.0011 0 0]; Hn=Hn(1:order); mu=0.5; % mu表示步長 N=1000; % 1000個音頻采樣點 Loop=150; % 150次回圈 EE_NLMS=zeros(N,1); % 初始化總誤差 for nn=1:Loop % epoch=150 win_NLMS=zeros(1,order); % 權重初始化w error_NLMS=zeros(1,N)'; % 初始化誤差 % 均勻分布的輸入值 r=sign(rand(N,1)-0.5); % shape=(1000,1)的(0,1)均勻分布-0.5,sign(n)>0=1;<0=-1 % 聲學環境音頻輸出:輸入卷積Hn得到 輸出 output=conv(r,Hn); % r卷積Hn,output長度=length(u)+length(v)-1 output=awgn(output,snr,'measured'); % 將白高斯噪聲添加到信號中 % N=1000,每個采樣點 for i=order:N % i=8:1000 input=r(i:-1:i-order+1); % 每次迭代取8個資料進行處理 e_NLMS = output(i)-win_NLMS*input; win_NLMS=win_NLMS+e_NLMS*input'/(input'*input); % NLMS更新權重 error_NLMS(i)=error_NLMS(i)+e_NLMS^2; end EE_NLMS=EE_NLMS+error_NLMS; % 把總誤差相加 end % 對總誤差求平均值 error_NLMS=EE_NLMS/Loop; figure; error_NLMS=10*log10(error_NLMS(order:N)); plot(error_NLMS,'r'); % 紅色 axis tight; % 使用緊湊的坐標軸 legend('NLMS演算法'); % 圖例 title('NLMS演算法誤差曲線'); % 圖示題 xlabel('樣本'); % x軸標簽 ylabel('誤差/dB'); % y軸標簽 grid on; % 網格線MATLAB演算法實作
我們將演算法用到音頻效果中,音頻獲取地址,代碼如下,,
clear;clc; snr=20; % 信噪比 order=8; % 自適應濾波器的階數為8 [d, fs_orl] = audioread('./audio/handel.wav'); % 期望輸出(73113,1) [x, echo] = audioread('./audio/handel_echo.wav'); % 回聲輸入 fai=0.0001; mu=0.02; % mu表示步長 N=length(x); Loop=10; % 150次回圈 EE_NLMS = zeros(N,1); % 初始化總損失 y_NLMS = zeros(N,1); % 初始化AEC音頻輸出 for nn=1:Loop % epoch=150 win_NLMS = zeros(order,1); % 權重初始化w y = zeros(N,1); % 輸出 error_NLMS=zeros(N,1); % 初始化誤差 for i=order:N % i=8:73113 input=x(i:-1:i-order+1); % 每次迭代取8個資料進行處理,(8,1)->(9,2) y(i)=win_NLMS'*input; % (8,1)'*(8*1)=1 error_NLMS(i) = d(i)-y(i); % (8,1)'*(8,1)=1 k = mu/(fai + input'*input); win_NLMS = win_NLMS+2*k*error_NLMS(i)*input; error_NLMS(i)=error_NLMS(i)^2; % 記錄每個采樣點的誤差 end % 把總誤差相加 EE_NLMS = EE_NLMS+error_NLMS; y_NLMS=y_NLMS+y; end error_NLMS = EE_NLMS/Loop; % 對總誤差求平均值 y_NLMS=y_NLMS/Loop; % 對輸出求平均 audiowrite("audio/done.wav", y_NLMS, fs_orl); sound(y_NLMS) % 聽一聽回聲消除后的音效 figure; error1_NLMS=10*log10(error_NLMS(order:N)); plot(error1_NLMS,'b.'); % 藍色 axis tight; % 使用緊湊的坐標軸 legend('NLMS演算法'); % 圖例 title('NLMS演算法誤差曲線'); % 圖示題 xlabel('樣本'); % x軸標簽 ylabel('誤差/dB'); % y軸標簽 grid on; % 網格線
NLMS演算法的每次迭代需要3N+1個乘法,僅比標準LMS演算法多N個,考慮到所獲得的穩定性和回波衰減增益,這是一個可接受的增加,有的時候會對NLMS進行改進,設$\mu(n)=\frac{\eta}{\delta +x^T(n)x(n)}$,$0 <\eta < 2$,$\delta $為一個較小的整數,防止輸入資料矢量$x(n)$的內積過小使得$\mu(n)$過大而引起穩定性能下降,一般取0.0001,
NSAF演算法
MATLAB代碼實作
當需要同時進行語音通信(或全雙工傳輸)時,回聲消除對于音頻電話會議非常重要,在回聲消除中,測得的麥克風信號$d(n)$包含兩個信號:
-
近端語音信號$v(n)$
-
遠端回聲信號$\hat{d}(n)$
目的是從麥克風信號中去除遠端回聲信號,從而僅發送近端語音信號,本示例包含一些聲音片段,因此您可能現在要調整計算機的音量,
房間脈沖回應
首先,您需要對揚聲器所在的揚聲器到麥克風的信號路徑的聲學建模,使用長有限沖激回應濾波器來描述房間的特征,下面的代碼生成一個隨機的脈沖回應,該回應與會議室的顯示相同,假設系統采樣率為16000 Hz,
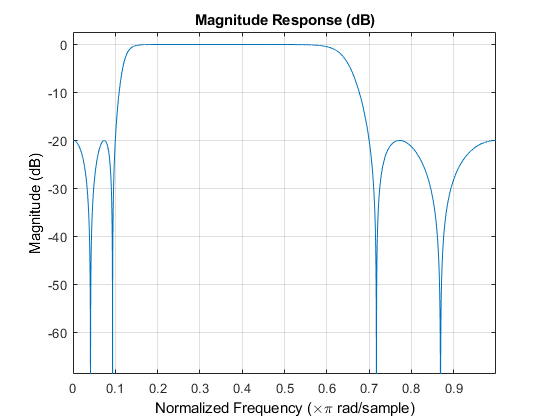
fs = 16000; M = fs / 2 + 1; frameSize = 2048; [B,A] = cheby2(4,20,[0.1 0.7]); impulseResponseGenerator = dsp.IIRFilter(' Numerator ',[zeros(1,6)B],... 'Denominator',A); FVT = fvtool(impulseResponseGenerator); %分析過濾器 FVT.Color = [1 1 1];
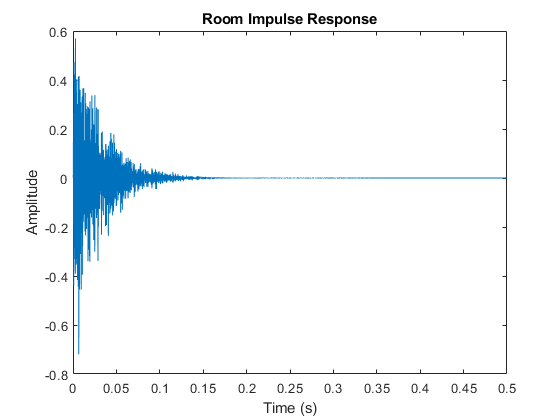
roomImpulseResponse = impulseResponseGenerator( ... (log(0.99*rand(1,M)+0.01).*sign(randn(1,M)).*exp(-0.002*(1:M)))'); roomImpulseResponse = roomImpulseResponse/norm(roomImpulseResponse)*4; room = dsp.FIRFilter('Numerator', roomImpulseResponse'); fig = figure; plot(0:1/fs:0.5, roomImpulseResponse); xlabel('Time (s)'); ylabel('Amplitude'); title('Room Impulse Response'); fig.Color = [1 1 1];
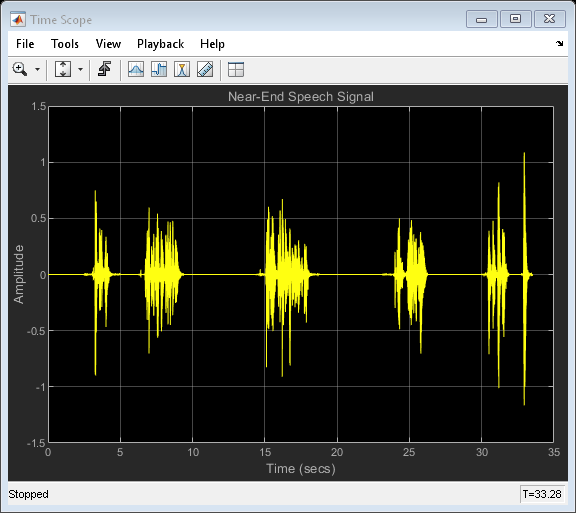
近端語音信號
電話會議系統的用戶通常位于系統麥克風附近,這是麥克風上男性講話的聲音,
load nearspeech player = audioDeviceWriter('SupportVariableSizeInput', true, ... 'BufferSize', 512, 'SampleRate', fs); nearSpeechSrc = dsp.SignalSource('Signal',v,'SamplesPerFrame',frameSize); nearSpeechScope = dsp.TimeScope('SampleRate', fs, ... 'TimeSpan', 35, 'TimeSpanOverrunAction', 'Scroll', ... 'YLimits', [-1.5 1.5], ... 'BufferLength', length(v), ... 'Title', 'Near-End Speech Signal', ... 'ShowGrid', true); % Stream processing loop while(~isDone(nearSpeechSrc)) % Extract the speech samples from the input signal nearSpeech = nearSpeechSrc(); % Send the speech samples to the output audio device player(nearSpeech); % Plot the signal nearSpeechScope(nearSpeech); end release(nearSpeechScope);
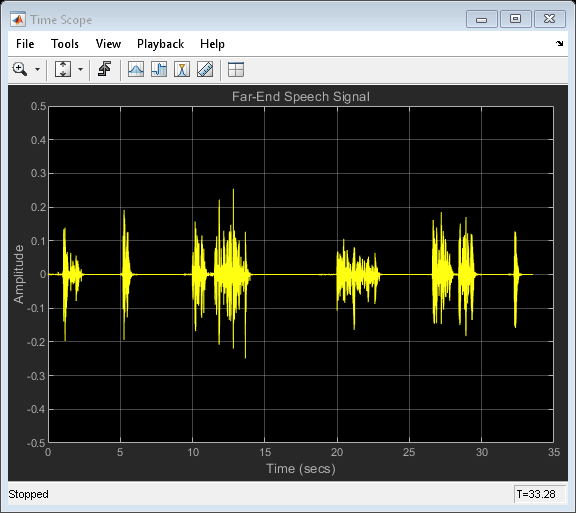
遠端語音信號
在電話會議系統中,語音從揚聲器中傳播出去,在房間里彈跳,然后被系統的麥克風拾取,聆聽在沒有近端語音的情況下在麥克風處拾起語音時的聲音,
load farspeech farSpeechSrc = dsp.SignalSource('Signal',x,'SamplesPerFrame',frameSize); farSpeechSink = dsp.SignalSink; farSpeechScope = dsp.TimeScope('SampleRate', fs, ... 'TimeSpan', 35, 'TimeSpanOverrunAction', 'Scroll', ... 'YLimits', [-0.5 0.5], ... 'BufferLength', length(x), ... 'Title', 'Far-End Speech Signal', ... 'ShowGrid', true); % Stream processing loop while(~isDone(farSpeechSrc)) % Extract the speech samples from the input signal farSpeech = farSpeechSrc(); % Add the room effect to the far-end speech signal farSpeechEcho = room(farSpeech); % Send the speech samples to the output audio device player(farSpeechEcho); % Plot the signal farSpeechScope(farSpeech); % Log the signal for further processing farSpeechSink(farSpeechEcho); end release(farSpeechScope);
麥克風信號
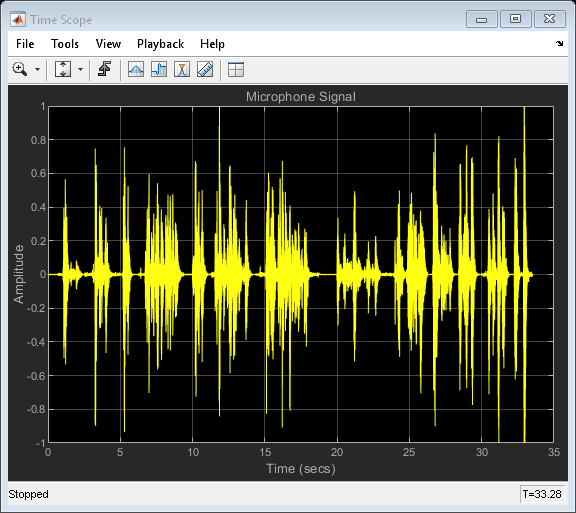
麥克風處的信號既包含近端語音,也包含在整個房間中回聲的遠端語音,回聲消除器的目的是消除遠端語音,從而僅將近端語音發送回遠端聽眾,
reset(nearSpeechSrc); farSpeechEchoSrc = dsp.SignalSource('Signal', farSpeechSink.Buffer, ... 'SamplesPerFrame', frameSize); micSink = dsp.SignalSink; micScope = dsp.TimeScope('SampleRate', fs,... 'TimeSpan', 35, 'TimeSpanOverrunAction', 'Scroll',... 'YLimits', [-1 1], ... 'BufferLength', length(x), ... 'Title', 'Microphone Signal', ... 'ShowGrid', true); % Stream processing loop while(~isDone(farSpeechEchoSrc)) % Microphone signal = echoed far-end + near-end + noise micSignal = farSpeechEchoSrc() + nearSpeechSrc() + ... 0.001*randn(frameSize,1); % Send the speech samples to the output audio device player(micSignal); % Plot the signal micScope(micSignal); % Log the signal micSink(micSignal); end release(micScope);
頻域自適應濾波器(FDAF)
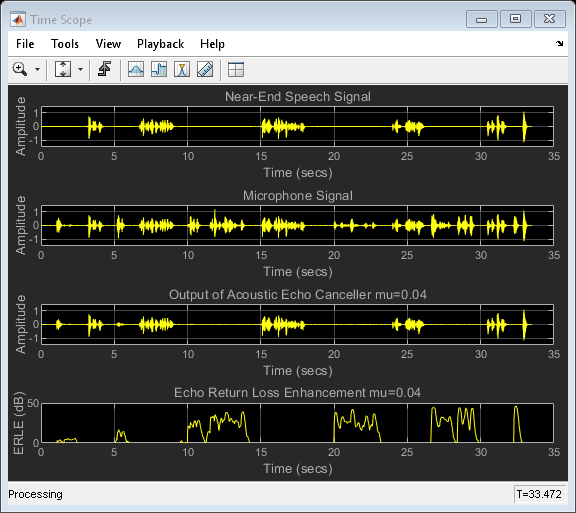
該示例中的演算法是頻域自適應濾波器(FDAF),當待識別系統的脈沖回應較長時,此演算法非常有用,FDAF使用快速卷積技術來計算輸出信號和過濾器更新,該計算可在MATLAB®中快速執行,通過頻點步長歸一化,它還具有快速收斂性能,為濾波器選擇一些初始引數,并查看遠端語音在誤差信號中的消除程度,
% Construct the Frequency-Domain Adaptive Filter echoCanceller = dsp.FrequencyDomainAdaptiveFilter('Length', 2048, ... 'StepSize', 0.025, ... 'InitialPower', 0.01, ... 'AveragingFactor', 0.98, ... 'Method', 'Unconstrained FDAF'); AECScope1 = dsp.TimeScope(4, fs, ... 'LayoutDimensions', [4,1], ... 'TimeSpan', 35, 'TimeSpanOverrunAction', 'Scroll', ... 'BufferLength', length(x)); AECScope1.ActiveDisplay = 1; AECScope1.ShowGrid = true; AECScope1.YLimits = [-1.5 1.5]; AECScope1.Title = 'Near-End Speech Signal'; AECScope1.ActiveDisplay = 2; AECScope1.ShowGrid = true; AECScope1.YLimits = [-1.5 1.5]; AECScope1.Title = 'Microphone Signal'; AECScope1.ActiveDisplay = 3; AECScope1.ShowGrid = true; AECScope1.YLimits = [-1.5 1.5]; AECScope1.Title = 'Output of Acoustic Echo Canceller mu=0.025'; AECScope1.ActiveDisplay = 4; AECScope1.ShowGrid = true; AECScope1.YLimits = [0 50]; AECScope1.YLabel = 'ERLE (dB)'; AECScope1.Title = 'Echo Return Loss Enhancement mu=0.025'; % Near-end speech signal release(nearSpeechSrc); nearSpeechSrc.SamplesPerFrame = frameSize; % Far-end speech signal release(farSpeechSrc); farSpeechSrc.SamplesPerFrame = frameSize; % Far-end speech signal echoed by the room release(farSpeechEchoSrc); farSpeechEchoSrc.SamplesPerFrame = frameSize;
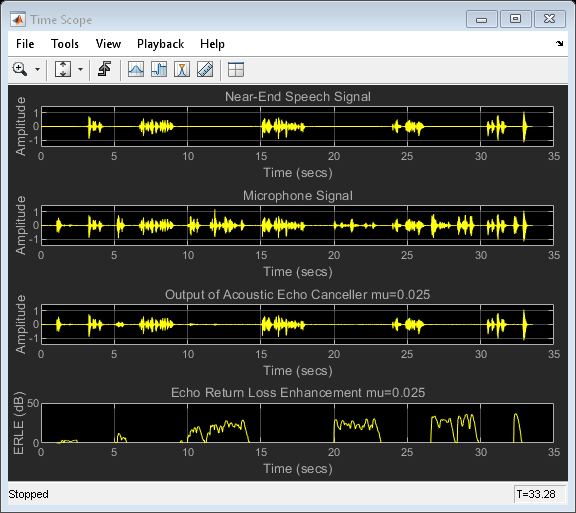
回波回波增強(ERLE)
由于您可以訪問近端和遠端語音信號,因此可以計算回聲回波損耗增強(ERLE),這是對回聲衰減量的平滑度量(以dB為單位),從圖中可以看出,在收斂周期結束時您獲得了大約35 dB的ERLE,
diffAverager = dsp.FIRFilter('Numerator', ones(1,1024)); farEchoAverager = clone(diffAverager); setfilter(FVT,diffAverager); micSrc = dsp.SignalSource('Signal', micSink.Buffer, ... 'SamplesPerFrame', frameSize); % Stream processing loop - adaptive filter step size = 0.025 while(~isDone(nearSpeechSrc)) nearSpeech = nearSpeechSrc(); farSpeech = farSpeechSrc(); farSpeechEcho = farSpeechEchoSrc(); micSignal = micSrc(); % Apply FDAF [y,e] = echoCanceller(farSpeech, micSignal); % Send the speech samples to the output audio device player(e); % Compute ERLE erle = diffAverager((e-nearSpeech).^2)./ farEchoAverager(farSpeechEcho.^2); erledB = -10*log10(erle); % Plot near-end, far-end, microphone, AEC output and ERLE AECScope1(nearSpeech, micSignal, e, erledB); end release(AECScope1);
不同步長值的影響
為了獲得更快的收斂速度,可以嘗試使用更大的步長值,但是,這種增加會產生另一種效果:當近端揚聲器講話時,自適應濾波器“調整不當”,聆聽您選擇的步長比以前大60%時會發生什么,
% Change the step size value in FDAF reset(echoCanceller); echoCanceller.StepSize = 0.04; AECScope2 = clone(AECScope1); AECScope2.ActiveDisplay = 3; AECScope2.Title = 'Output of Acoustic Echo Canceller mu=0.04'; AECScope2.ActiveDisplay = 4; AECScope2.Title = 'Echo Return Loss Enhancement mu=0.04'; reset(nearSpeechSrc); reset(farSpeechSrc); reset(farSpeechEchoSrc); reset(micSrc); reset(diffAverager); reset(farEchoAverager); % Stream processing loop - adaptive filter step size = 0.04 while(~isDone(nearSpeechSrc)) nearSpeech = nearSpeechSrc(); farSpeech = farSpeechSrc(); farSpeechEcho = farSpeechEchoSrc(); micSignal = micSrc(); % Apply FDAF [y,e] = echoCanceller(farSpeech, micSignal); % Send the speech samples to the output audio device player(e); % Compute ERLE erle = diffAverager((e-nearSpeech).^2)./ farEchoAverager(farSpeechEcho.^2); erledB = -10*log10(erle); % Plot near-end, far-end, microphone, AEC output and ERLE AECScope2(nearSpeech, micSignal, e, erledB); end release(nearSpeechSrc); release(farSpeechSrc); release(farSpeechEchoSrc); release(micSrc); release(diffAverager); release(farEchoAverager); release(echoCanceller); release(AECScope2);
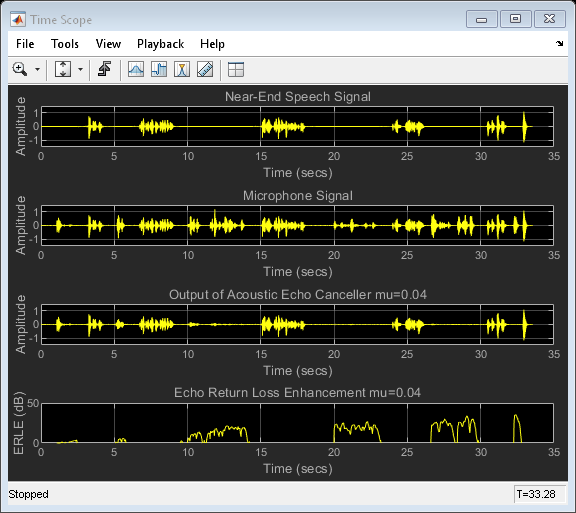
回聲回波損耗增強比較
步長較大時,由于近端語音引入的錯誤調整,導致ERLE性能不佳,為了解決此性能難題,聲學回聲消除器包括一種檢測方案,可告知何時存在近端語音并在這些時間段內降低步長值,沒有這種檢測方案,從ERLE圖可以看出,具有較大步長的系統的性能不如前者,
使用磁區減少延遲
對于長脈沖回應,傳統FDAF在數值上比時域自適應濾波更有效,但是由于輸入幀大小必須是指定濾波器長度的倍數,因此它具有高延遲,對于許多實際應用程式來說,這可能是不可接受的,通過使用磁區的FDAF可以減少延遲,該方法將過濾器脈沖回應分為較短的部分,將FDAF應用于每個部分,然后合并中間結果,在這種情況下,幀大小必須是磁區(塊)長度的倍數,從而大大減少了長脈沖回應的等待時間,
% Reduce the frame size from 2048 to 256 frameSize = 256; nearSpeechSrc.SamplesPerFrame = frameSize; farSpeechSrc.SamplesPerFrame = frameSize; farSpeechEchoSrc.SamplesPerFrame = frameSize; micSrc.SamplesPerFrame = frameSize; % Switch the echo canceller to Partitioned constrained FDAF echoCanceller.Method = 'Partitioned constrained FDAF'; % Set the block length to frameSize echoCanceller.BlockLength = frameSize; % Stream processing loop while(~isDone(nearSpeechSrc)) nearSpeech = nearSpeechSrc(); farSpeech = farSpeechSrc(); farSpeechEcho = farSpeechEchoSrc(); micSignal = micSrc(); % Apply FDAF [y,e] = echoCanceller(farSpeech, micSignal); % Send the speech samples to the output audio device player(e); % Compute ERLE erle = diffAverager((e-nearSpeech).^2)./ farEchoAverager(farSpeechEcho.^2); erledB = -10*log10(erle); % Plot near-end, far-end, microphone, AEC output and ERLE AECScope2(nearSpeech, micSignal, e, erledB); end
開源的音頻處理庫
Speex:開源語音編解碼器
基于碼激勵線性預測編碼的 Speex 平臺來進行回音消除,兩者都是將多媒體通信的模塊集成在瀏覽器中,徹底屏蔽掉其它方案存在的作業系統和底層硬體間的差異,能夠用于所有作業系統和瀏覽器,
專為語音設計的無專利音頻壓縮格式,Speex專案旨在通過提供免費替代昂貴的專有語音編解碼器的方法來降低語音應用程式的進入門檻,此外,Speex非常適合Internet應用程式,并提供了大多數其他編解碼器中沒有的有用功能,
Speex基于CELP ,旨在以2到44 kbps的位元率壓縮語音,Speex的一些功能包括:
- 同一位流中的窄帶(8 kHz),寬帶(16 kHz)和超寬帶(32 kHz)壓縮
- 強度立體聲編碼
- 丟包隱藏
- 可變位元率操作(VBR)
- 語音活動檢測(VAD)
- 不連續傳輸(DTX)
- 定點埠
- 回聲消除器
- 噪聲抑制
Speex編解碼器已被Opus淘汰,它會繼續可用,但是由于Opus在各個方面都比Speex更好,因此建議用戶切換Opus,
Opus互動音頻編解碼器
Opus是一款完全開放,免版稅,功能廣泛的音頻編解碼器,Opus在互聯網上的互動式語音和音樂傳輸方面無可匹敵,但也適用于存盤和流媒體應用程式,
Opus可以處理各種音頻應用程式,包括IP語音,視頻會議,游戲內聊天,甚至是遠程現場音樂表演,它可以從低位元率的窄帶語音擴展到高質量的立體聲音樂,支持的功能有:
- 位元率從6 kb / s到510 kb / s
- 采樣率從8 kHz(窄帶)到48 kHz(全帶)
- 幀大小從2.5毫秒到60毫秒
- 支持恒定位元率(CBR)和可變位元率(VBR)
- 音頻帶寬從窄帶到全帶
- 支持語音和音樂
- 支持單聲道和立體聲
- 最多支持255個通道(多流幀)
- 動態可調的位元率,音頻帶寬和幀大小
- 良好的丟失健壯性和資料包丟失隱藏(PLC)
- 浮點和定點實作
WebRTC(實時通信):谷歌公司在 2010 年收購了 Global IP Solutions 后逐步開源的音視頻解決方案 WebRTC,該方案中的 AEC 模塊是實作自適應濾波演算法的優秀平臺,它集成了聲學回聲消除所需要的所有結構,用戶可以通過簡單API為瀏覽器和移動應用程式提供實時通信(RTC)功能
推薦使用webrtc
回聲消除需要時候的技術:雙講檢測技術(語音活動檢測,區分希臘佛中是否存在雙端講話)、自適應濾波技術(主要性能指標:跟蹤性能、抗沖激性、魯棒性和計算復雜性)、后處理(消除自適應濾波器的輸出誤差)
參考
《基于自適應濾波器的聲學回聲消除研究——馮江浩》
MATLAB官網audio_Examples_Acoustic Echo Cancellation
Hand Book of Speech Enhancement and Recognition
語音自適應回聲消除演算法代碼講解
WebRTC AEC AGC ANC NS示例
目前大家都在用什么演算法:黃翔. 基于麥克風陣列的回聲抵消系統研究[D]. 湖北工業大學, 2018.京東和科大訊飛聯合開發的叮咚智能音箱的回聲消除技術體系包括四大核心模塊:超低信噪比回聲消除、多通道回聲消除、非線性回聲消除和麥克風陣列回聲消除,
思必馳、云知聲、Nuance 等也正不斷開發出能適應越來越復雜環境的回聲消除演算法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/67661.html
標籤:其他