神經網路學習筆記(2)
本文是神經網路學習筆記的第二部分,緊接著筆者的神經網路學習筆記(1),主要內容為對總結神經網路的常用配置方式,包括如下幾點:(1)資料預處理;(2)權重初始化;(3)正則化與Dropout;(4)損失函式,
1、資料預處理
對于神經網路而言,資料的預處理常見的方法主要包括0-1歸一化,主成分分析(PCA)及one-hot編碼標簽,
(1)0-1歸一化:將樣本所有維度的資料轉變為以0為均值,1為標準差的新資料,處理方式為,對訓練資料的每一個維度,分別計算其均值和標準差,然后將這一維度的資料分別減去均值然后除以標準差,至于為什么需要對資料進行這一處理,筆者也沒有找到很好的解答,歡迎各位大牛在本文下面留言探討;
注意:當我們在進行歸一化處理的時候,我們處理所用的數值(例如:均值和方差)只能夠從訓練集上面獲得,然后將從訓練集上計算得到的值直接應用到驗證集/測驗集上,而不是在驗證集/測驗集上面重新計算新值,或者直接從整體的資料集上面計算均值和方差然后再劃分資料集,我想這還是為了保證模型泛化能力檢測的公正性,避免驗證集/測驗集中的任何資料泄露到訓練程序中,
(2)主成分分析(PCA):對于神經網路而言,該方法主要用于對資料進行降維(也可用于資料的壓縮),網路上面已經有很多文章對PCA的基本程序進行解讀,但是筆者覺得這些文章還是存在很多不嚴謹的地方,因此向各位讀者推薦這一鏈接中對PCA的講解,概括來說,該文中將PCA歸結為求解一個矩陣,該矩陣能夠對原始資料進行降維,同時利用這一矩陣又能夠將降維后的資料最大化地還原回來,因此可將對這一矩陣的求解轉化為一個優化問題,最后應用基本的線性代數知識就能得到了PCA的基本運算程序,
(3)one-hot編碼:在進行多分類任務的時候,例如要將一個有十個維度的樣本分到5個類別中,我們所得到的樣本資料可能會是這樣的:特征:[x1,x2,x3,x4,x5,x6,x7,x8,x9,x10],標記:[y],y屬于{0,1,2,3,4},其中用0到4這5個數字來表示五種不同的類別,在應用神經網路完成這一分類任務的時候,我們往往會在輸出層設定5個節點,每一個節點都與一個類別相對應,因此在進行模型訓練的時候,為了保證標記與實際輸出的資料之間的對應,我們需要將訓練樣本的標記轉為one-hot編碼的格式,上例中假如有一個樣本被標記為“4”,那么轉為one-hot編碼就是[0,0,0,0,1],在keras庫中有一個函式“to_categorical”可以很方便地將標記轉為one-hot格式,
2、權重初始化
我們知道在進行優化的程序中,對引數的初始化會影響最后的初始化結果,同樣對神經網路引數的初始化也很重要,下面將介紹在神經網路應用的程序中常用的權重初始化方式和應該避免的錯誤方式,(下述內容主要摘自CS231n課程)
(1)小亂數
在初始化神經網路權重的時候,常見的做法是將神經元的權重初始化為非常小的亂數,這一程序被稱之為“打破對稱”,這樣操作的原因是,如果神經元的權重一開始都是隨機的并且不同的話,它們就會計算出不同的梯度,并且成為一個整體神經網路的多樣組成部分,這一操作應用numpy的實作方法為:W=0.01*np.random.randn(D, H),需要強調的一點是,并非越小的值就越好,因為如果權重值過小,那么在反向傳播的程序中,每一個引數就只能夠得到非常小的更新,
注意:不要將權重全部都設定為0,這會導致每一個神經元都計算出相同的輸出,以至于在反向傳播的程序中會對每一個引數計算出相同的權重值,結果就會導致同樣的權重更新,換句話說,如果權重都初始化為同樣的數的話,神經網路就沒有了“非對稱源”,
(2)偏置初始化
常見的偏置初始化方式是將偏置都設定為0,因為“打破對稱”已經由權重初始化完成了,對于以ReLU作為非線性函式的神經元而言,有些人喜歡將偏置初始化為一個很小的常數,例如:0.01,因為這樣能夠確保神經元從一開始就能夠有非0輸出,也就能夠從一開始就更新權重,然而還不清楚這種做法是否能夠提供穩定的表現提升,我們一般更常用的方式是將偏置都設定為0.
(3)Batch Normalization
這一種技術是2015年被Ioffe和Szegedy所提出來的,在論文中對該技術有很詳細的解讀,在此僅僅對該技術做一個基本的解讀,其基本程序為,在進行mini-Batch梯度下降訓練的程序中,一次訓練的程序就包含m個樣本的資料,某個神經元對應的原始的線性激活x通過減去mini-Batch內m個實體的線性激活的均值E(x)并除以m個實體的線性激活的方差Var(x)來進行轉換,表達如下式,很多的深度學習庫已經提供了Batch Normalization的實作,例如:keras的BatchNormalization層,在實踐中,Batch Normalization對于較差的初始化有著很強的魯棒性,并且這一技術有助于提升神經網路的訓練速度,
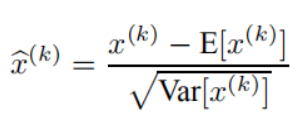
3、正則化與Dropout
下面將要介紹在神經網路中常用的可以有效避免過擬合問題的方法,即:正則化與Dropout
(1)正則化
L2正則化:該方法通過在最后的損失函式中添加一個懲罰項,即所有引數的平方,來避免過擬合,用公式表達就是在損失函式中添加一項1/2*λ*||W||2,其中λ是正則化系數,用來控制懲罰力度的大小,直覺上來說,這種正則化的方式傾向于懲罰過大或者過小的引數值,
L1正則化:該方法在損失函式中添加的懲罰項為,引數的絕對值,即1/2*λ*|W|,這一懲罰措施,導致模型會更偏愛接近于0的引數,
Max norm constraints(最大范數限制):直接對引數添加限制條件,如:||W||2<C,其中C為某個常數,典型的值為3或者4,
需要指出的是,我們很少對網路的偏置做正則化,雖然在實踐中正則化偏置很少會導致更差的結果,
(2)Dropout
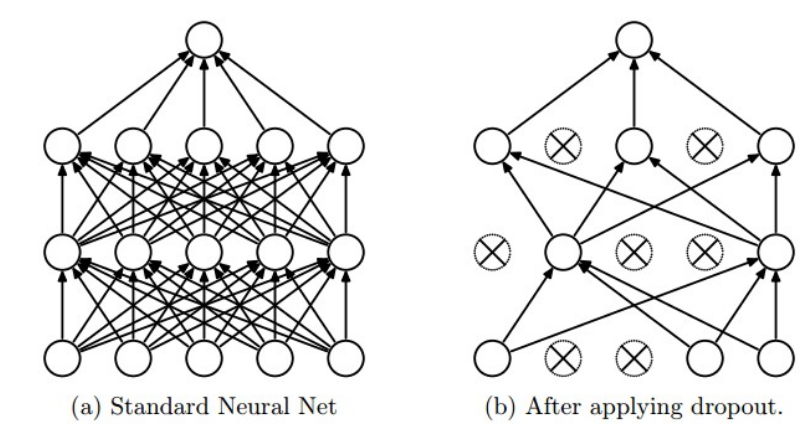
這是近些年來所提出來非常有效的避免過擬合問題的方法,源自于Srivastava et al的論文,簡單來說,該方法基本思路為在訓練的程序中以一定的概率p(一個超引數)來選擇保留神經元的輸出,或者直接將輸出設定為0,如下圖所示,Dropout可以被解釋為,在訓練程序中,對一個較大的全連接網路中的神經元抽取一個較小的網路進行訓練,在測驗階段則不使用dropout,這樣整體網路所得到的結果可解釋多個采樣網路的平均預測值,
4、損失函式
損失函式用來衡量模型預測值與標記值之間的誤差,一個資料集整體的損失就是所有樣本的誤差均值,根據所需要執行的任務的不同可以選擇不同的的損失函式,在此主要介紹:(1)二分類問題;(2)多分類問題;(3)回歸問題,這三類問題常用的損失函式,
(1)二分類
hinge loss(鉸鏈誤差):每一個樣本的標記為要不為-1,要不為1,其運算式為:L=max(0, 1-y*l),其中y為預測值,l為標記值,直觀上來看,如果預測值和標記值一致(同為-1或者1),那么函式就取小值0;而如果不一致,就會取較大值2,這樣就會導致誤差的增大,
binary cross-entropy loss(二分類交叉熵):用于以單個輸出節點來預測分類問題,最后的輸出范圍在[0,1]之間,對這種模型,在最后預測的時候,會根據某個閾值來劃分預測結果,例如:如果輸出值大于閾值為0.5,那么預測類別為0,否則為1,該損失函式的運算式為:L=-l*log(y),其中l為標記值,y為模型輸出值,簡單理解一下,如果預測結果和標記是相當的話,例如:預測值為0.8,標記為1,那么該損失函式的值就會非常小;而如果不相當的話,例如,在標記為1的時候預測值為0.1,那么該損失函式就會非常大,
(2)多分類問題
該問題指的是將樣本劃分到兩個以上的類別當中,典型的如Minist資料庫,cifar-10資料庫分類都屬于這種型別,對于這種問題,在神經網路的最后會使用softmax層將最終的結果壓縮到[0,1]范圍內,這一做法可以解釋為使得輸出節點的輸出值直接對應于樣本屬于某個類別的可能性大小,多分類問題的交叉熵運算式為:L=-l*log(y)-(1-l)*log(1-y),
(3)回歸問題
回歸問題的本質在于擬合資料,使得模型預測的實數值與標記值之間的差距最小,對于這一類問題,常用的損失函式就是模型輸出與標記之間的L2范數和L1范數,范數的概念可以參考這一篇文章,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/67688.html
標籤:其他