作者|Renu Khandelwal
編譯|VK
來源|Towards Data Science
什么是神經機器翻譯?
神經機器翻譯是一種將一種語言翻譯成另一種語言的技術,一個例子是把英語轉換成印地語,讓我們想想,如果你在一個印度村莊,那里的大多數人都不懂英語,你打算毫不費力地與村民溝通,在這種情況下,你可以使用神經機器翻譯,
神經機器翻譯的任務是使用深層神經網路從一個源語言(如英語)的一系列單詞轉換成一個序列的目標語言(如西班牙語),
神經機器翻譯的特點是什么?
- 能夠在多個時間步中持久存盤順序資料
NMT使用連續的資料,這些資料需要在幾個時間步中進行持久保存,人工神經網路(ANN)不會將資料保存在幾個時間步長上,回圈神經網路(RNN),如LSTM(長短時記憶)或GRU(門控遞回單元),能夠在多個時間步長中持久保存資料
- 處理可變長度的輸入和輸出向量的能力
ANN和CNN需要一個固定的輸入向量,在這個向量上應用一個函式來產生一個固定大小的輸出,NMT將一種語言翻譯成另一種語言,源語言和目標語言的單詞序列的長度是可變的,

RNN與LSTM或GRU一樣如何幫助進行順序資料處理?
RNN是一種神經網路,結構中具有回圈來保存資訊,它們對序列中的每個元素執行相同的任務,并且輸出元素依賴于以前的元素或狀態,這正是我們處理順序資料所需要的,
RNN可以有一個或多個輸入以及一個或多個輸出,這是處理順序資料(即變數輸入和變數輸出)的另一個要求
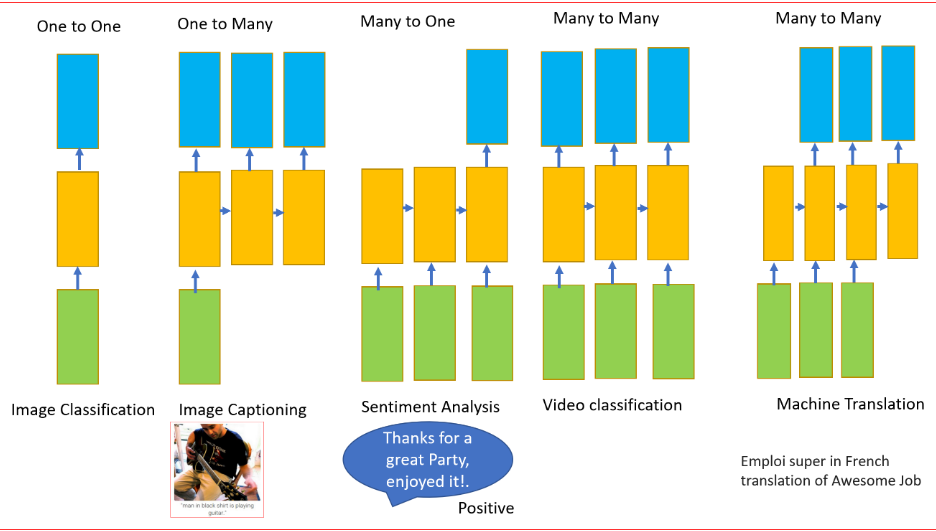
為什么我們不能用RNN進行神經機器翻譯?
在人工神經網路中,我們不需要在網路的不同層之間共享權重,因此,我們不需要對梯度求和,RNN的共享權重,我們需要在每個時間步中得出W的梯度,如下所示,
在時間步t=0計算h的梯度涉及W的許多因素,因為我們需要通過每個RNN單元反向傳播,即使我們不要權重矩陣,并且一次又一次地乘以相同的標量值,但是時間步如果特別大,比如說100個時間步,這將是一個挑戰,
如果最大奇異值大于1,則梯度將爆炸,稱為爆炸梯度,
如果最大奇異值小于1,則梯度將消失,稱為消失梯度,
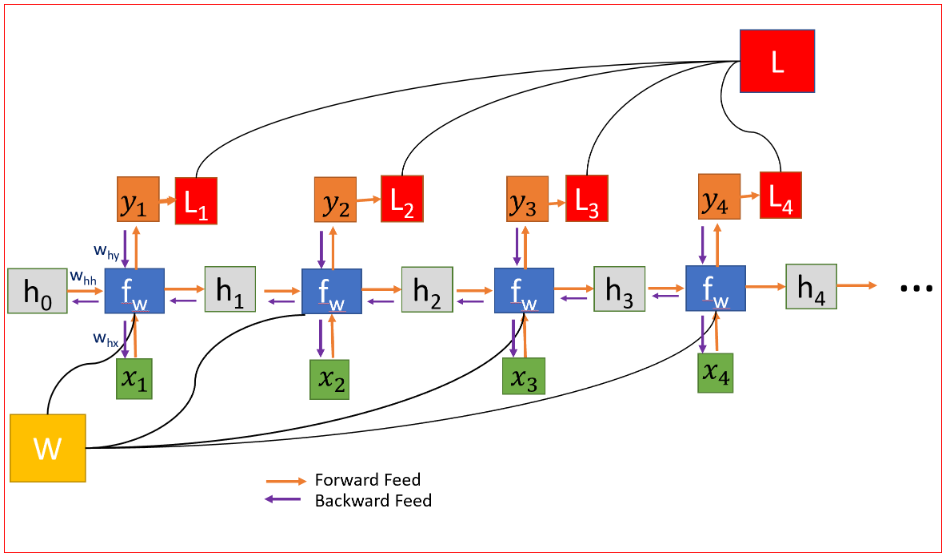
權重在所有層中共享,導致梯度爆炸或消失
對于梯度爆炸問題,我們可以使用梯度剪裁,其中我們可以預先設定一個閾值,如果梯度值大于閾值,我們可以剪裁它,
為了解決消失梯度問題,常用的方法是使用長短期記憶(LSTM)或門控回圈單元(GRU),
什么是LSTM和GRU?
LSTM是長短時記憶網路(Long Short Term Memory),GRU是門控回圈單元(Gated Recurrent Unit),他們能夠快速學習長期依賴性,LSTM可以學習跨越1000步的時間間隔,這是通過一種高效的基于梯度的演算法實作的,
LSTM和GRU在很長一段時間內記住資訊,他們通過決定要記住什么和忘記什么來做到這一點,
LSTM使用4個門,你可以將它們認為是否需要記住以前的狀態,單元狀態在LSTMs中起著關鍵作用,LSTM可以使用4個調節門來決定是否要從單元狀態添加或洗掉資訊,這些門的作用就像水龍頭,決定了應該通過多少資訊,

GRU是求解消失梯度問題的LSTM的一個簡單變種
它使用兩個門:重置門和更新門,這與LSTM中的三個步驟不同,GRU沒有內部記憶
重置門決定如何將新輸入與前一個時間步的記憶相結合,更新門決定了應該保留多少以前的記憶,
GRU的引數更少,因此它們的計算效率更高,并且比LSTM需要的資料更少
如何使用LSTM或GRU進行神經機器翻譯?
我們使用以LSTM或GRU為基本塊的編解碼器框架創建Seq2Seq模型
序列到序列(seq2seq)模型將源序列映射到目標序列,源序列是機器翻譯系統的輸入語言,目標序列是輸出語言,
Encoder(編碼器):從源語言中讀取單詞的輸入序列,并將該資訊編碼為實值向量,也稱為隱狀態向量或背景關系向量,該向量將輸入序列的“意義”編碼為單個向量,編碼器輸出被丟棄,只有隱狀態或內部狀態作為初始輸入傳遞給解碼器
Decoder(解碼器):將來自編碼器的背景關系向量作為輸入,并將字串標記的開始<start>作為初始輸入,以生成輸出序列,
編碼器逐字讀取輸入序列,類似地解碼器逐字生成輸出序列,
在訓練和推理階段,解碼器的作業方式不同,而在訓練和推理階段,編碼器的作業方式相同
解碼器的訓練階段
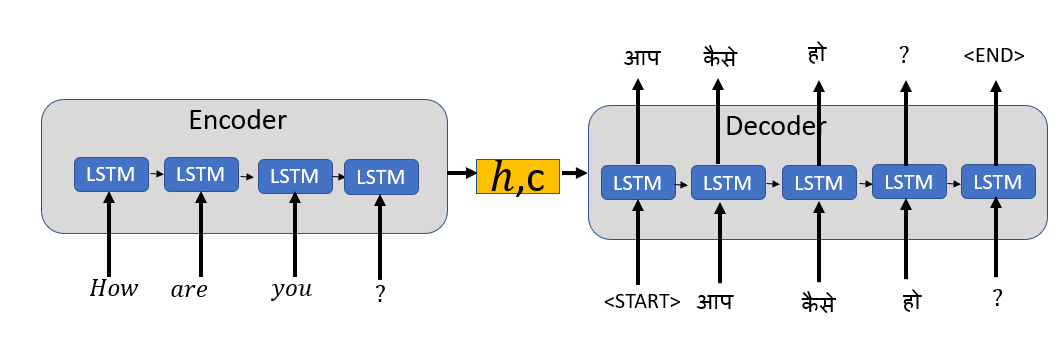
我們使用Teacher forcing(強制教學)來快速有效地訓練解碼器,
Teacher forcing就像教師在學生接受新概念的訓練時糾正學生一樣,由于教師在訓練程序中給予學生正確的輸入,學生將更快、更有效地學習新概念,
Teacher forcing演算法通過在訓練程序中提供前一時間戳的實際輸出而不是前一時間的預測輸出作為輸入來訓練解碼器,
我們添加一個標記<START>來表示目標序列的開始,并添加一個標記<END>作為目標序列的最后一個單詞,<END>標記稍后在推斷階段用作停止條件,以表示輸出序列的結束,
解碼器的推理階段
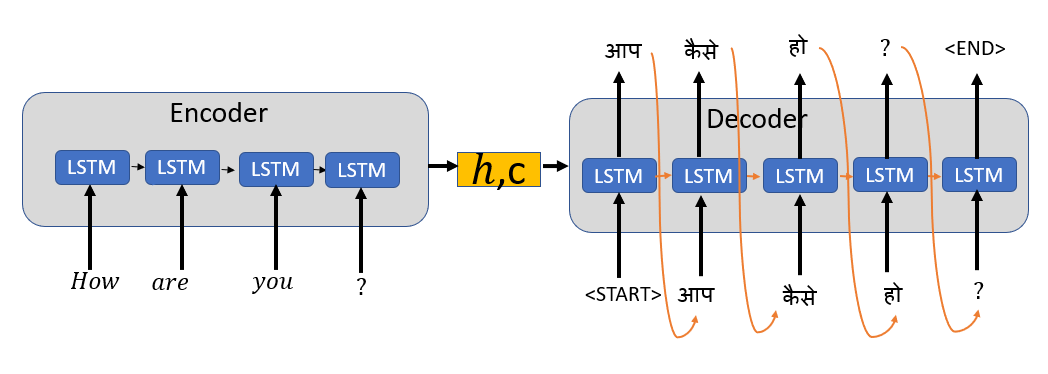
在推斷或預測階段,我們沒有實際的輸出序列或單詞,在推理階段,我們將上一個時間步的預測輸出作為輸入和隱藏狀態一起傳遞給解碼器,
解碼器預測階段的第一時間步將具有來自編碼器和<START>標記的最終狀態作為輸入,
對于隨后的時間步驟,解碼器的輸入將是前一解碼器的隱藏狀態以及前一解碼器的輸出,
當達到最大目標序列長度或<END>標記時,預測階段停止,
注:這只是Seq2Seq的直觀解釋,我們為輸入語言單詞和目標語言單詞創建單詞嵌入,嵌入提供了單詞及其相關含義的向量表示,
如何提高seq2seq模型的性能?
- 大型訓練資料集
- 超引數調節
- 注意力機制
什么是注意力機制?
編碼器將背景關系向量傳遞給解碼器,背景關系向量是總結整個輸入序列的單個向量,
注意力機制的基本思想是避免試圖為每個句子學習單一的向量表示,注意力機制根據注意權值來關注輸入序列的某些輸入向量,這允許解碼器網路“聚焦”于編碼器輸出的不同部分,它使用一組注意權重對解碼器自身輸出的每個時間步執行此操作,
原文鏈接:https://towardsdatascience.com/intuitive-explanation-of-neural-machine-translation-129789e3c59f
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/6855.html
標籤:其他
下一篇:3個高級Excel圖表技巧