作者|Félix Revert
編譯|VK
來源|Towards Data Science
介紹
我翻閱了CatBoost的檔案之后,我被這個強大的框架震驚了,CatBoost不僅在你提供給它的任何資料集上構建了一個最精確的模型,其中只需要最少的資料準備,它還提供了迄今為止最好的開源解釋工具,以及快速生成模型的方法,
CatBoost引發了機器學習革命,學習使用它會提高你的技能,但更有趣的是,CatBoost對資料科學家(比如我自己)的現狀構成了威脅,因為我認為在給定資料集的情況下,建立一個高精度的模型是很乏味的,但是CatBoost正在改變這種狀況,它使得每個人都可以使用高度精確的模型,

以極快的速度建立高精度模型
安裝
你試過在筆記本電腦上安裝XGBoost嗎?那你肯定知道有多麻煩,但是在另一端安裝運行CatBoost卻是小菜一碟,
pip install catboost
這樣就安裝好了,
資料準備
與目前大多數可用的機器學習模型不同,CatBoost只需要最少的資料準備,它能處理:
-
數值變數的缺失值
-
沒有編碼的分類變數
注意:對于分類變數,必須事先處理缺失值,替換為新類別“missing”或最其他常用的類別,
-
對于GPU用戶,它也能處理文本變數,
不幸的是,我無法測驗這個功能,因為我正在一臺沒有GPU的筆記本電腦上作業,
構建模型
與XGBoost一樣,你擁有熟悉的sklearn語法和一些特定于CatBoost的附加功能,
from catboost import CatBoostClassifier # 或者 CatBoostRegressor
model_cb = CatBoostClassifier()
model_cb.fit(X_train, y_train)
或者,如果你想要一個關于模型如何學習以及是否開始過擬合的可視化界面,請使用plot=True并在eval_set引數中插入測驗集:
from catboost import CatBoostClassifier # 或者 CatBoostRegressor
model_cb = CatBoostClassifier()
model_cb.fit(X_train, y_train, plot=True, eval_set=(X_test, y_test))

注意,你可以同時顯示多個度量,甚至更人性化的度量,如準確度或精確度,此處列出了支持的指標:https://catboost.ai/docs/concepts/loss-functions-classification.html,
請參見下面的示例:

你甚至可以使用交叉驗證,在不同的分割上觀察模型準確度的平均和標準偏差:

微調
CatBoost與XGBoost非常相似,要對模型進行適當的微調,首先將early_stopping_rounds進行設定(如10或50),然后開始調整模型的引數,
訓練速度
無GPU
從他們的基準測驗中,你可以看到CatBoost比XGBoost更快,并且與LightGBM相對類似,眾所周知,LightGBM的訓練速度很快,
有GPU
不過,說到GPU,真正的魔力就來了,
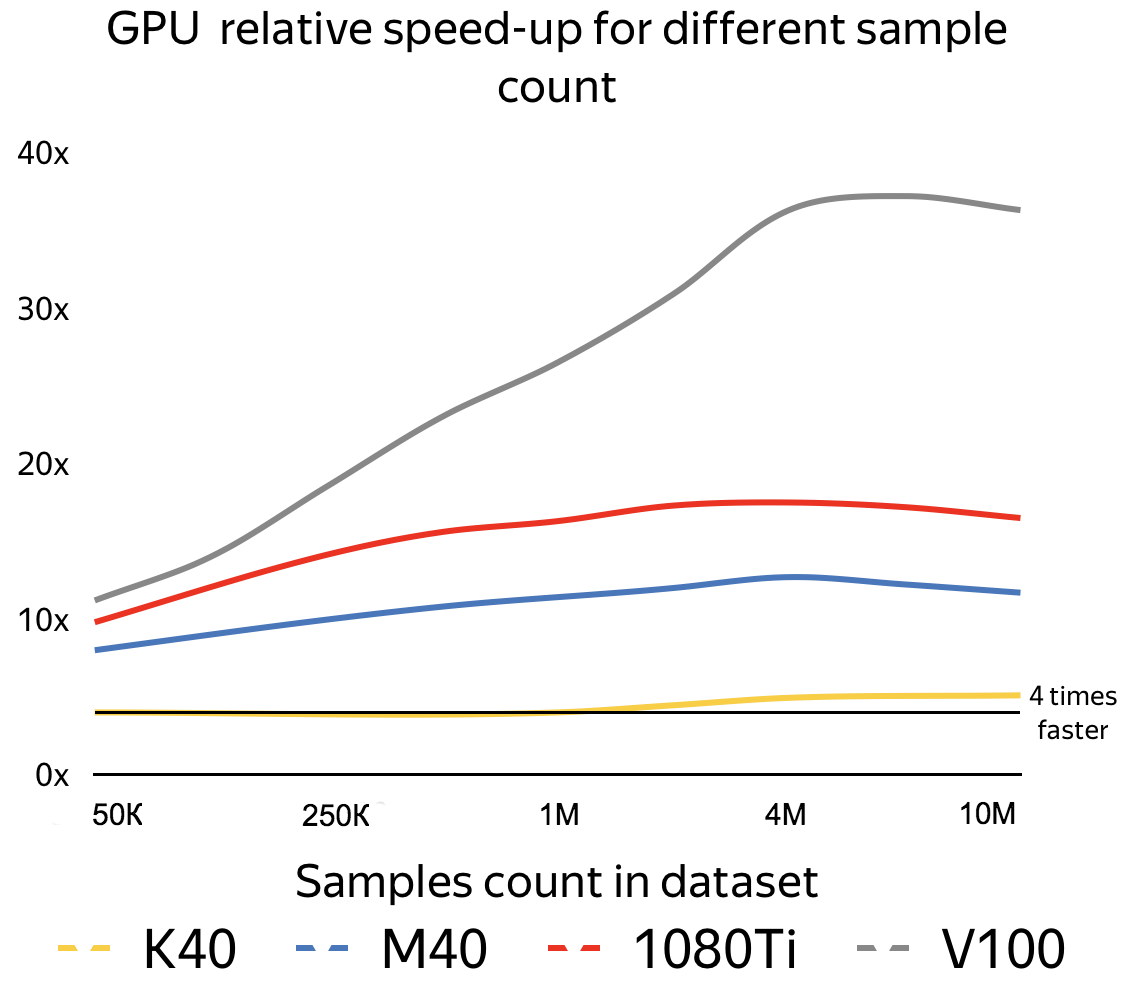
即使使用相對較老的GPU,如K40(2013年發布),訓練時間也將被至少快4倍,而其他更新的CPU最多能快40倍,
模型的解釋
CatBoost的作者們明白的一件事是,這不僅僅是一個玩精確度的游戲,為什么在XGBoost和LightGBM可用時要使用CatBoost呢,所以,在可解釋性方面,CatBoost提供了開箱即用的函式,
特征重要性
CatBoost提供了3種不同的方法:PredictionValuesChange、LossFunctionChange和InternalFeatureImportance,這里有詳細的檔案:https://catboost.ai/docs/concepts/fstr.html
區域可理解性
對于區域可理解性,CatBoost附帶SHAP,SHAP通常被認為是唯一可靠的方法,
shap_values = model.get_feature_importance(Pool(X, y), type='ShapValues')
官方也提供了教程:https://github.com/catboost/tutorials/blob/master/model_analysis/shap_values_tutorial.ipynb,你可以使用進行區域可理解性操作以及獲取特征重要性,
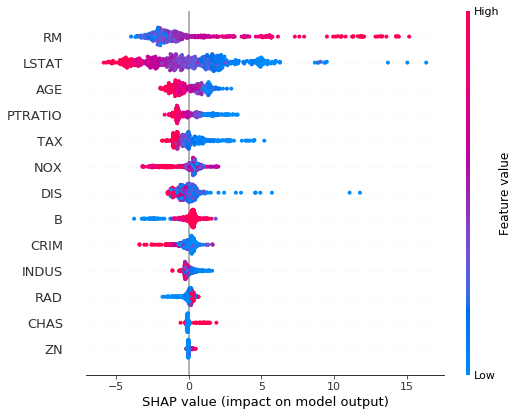
邊際效應
到目前為止,這是我最喜歡的東西,隨著高精度的商品化(特別是隨著AutoML的興起),當今從更深層次上了解這些高精度模型變得越來越重要,
根據經驗,以下圖表已成為模型分析的標準,CatBoos在它的包中直接提供它,
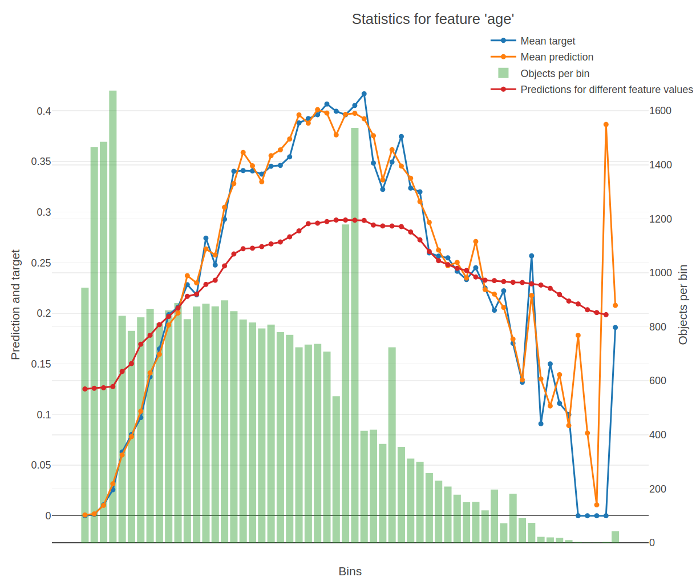
在這個圖示上你觀察到
-
綠色的是資料分布
-
藍色的是每個箱子的平均目標值
-
橙色的是每個箱子的平均預測值
-
紅色的是部分依賴圖( Partial Dependence)
在生產中使用CatBoost模型
在生產中實作你的模型變得非常容易,下面是如何匯出CatBoost模型,
使用.save_model()方法可以獲得以下幫助檔案:
Python和C++的匯出
model_cb.save_model(‘model_CatBoost.py’, format=’python’, pool=X_train)
執行后在你的repo中會有一個生成好的.py檔案,如下所示:
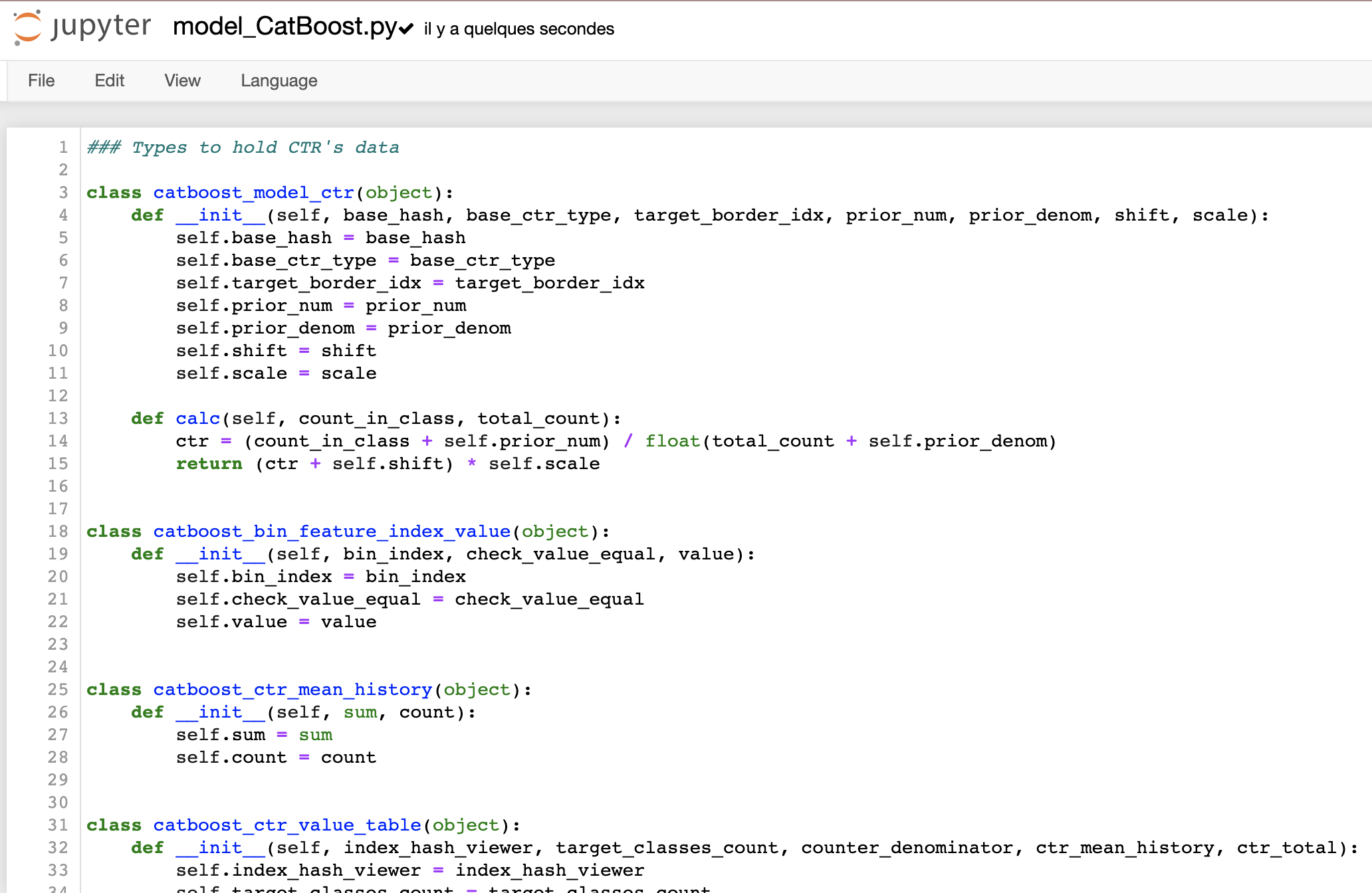
這時候模型已經準備好生產了!而且你不需要在機器上設定一個特定的環境來獲得新的分數,只需要Python 3就可以了!
二進制檔案輸出
二進制顯然是獲得新資料的最快選擇,代碼中改成輸出.cbm檔案,
載入時使用以下代碼重新加載模型:
from catboost import CatBoost
model = CatBoost()
model.load_model('filename', format='cbm')
其他有用的提示
Verbose = 50
大多數模型中通常都有詳細的輸入,以便查看你程序的進展情況,CatBoost也有,但比其他的稍好一點,例如,使用verbose=50將每50次迭代顯示一次訓練錯誤,而不是每次迭代顯示一次,因為如果有許多次迭代,這可能會很煩人,

使用verbose=10訓練同一模型,檢查起來好多了,

注意,剩余時間也會顯示出來,
模型比較
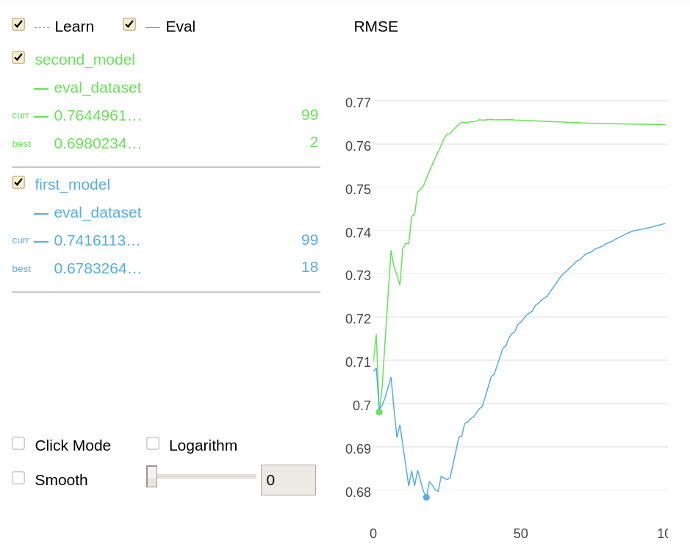
微調模型需要時間,通常,你可能有幾個好的引數串列,為了將其提升結果你甚至可以使用不同的引數集學習模型來比較,以便幫助你對要選擇的引數的最終串列做出決定,
訓練時保存模型
你有一個大資料集,你害怕訓練太久?你可以隨時保存模型,這樣你程序中的任何中斷都不必意味著對模型進行重新擬合!以下是相關檔案:https://catboost.ai/docs/features/snapshots.html#snapshots
學習資料
Catboost的檔案非常有用,即使你認為你對很多模型了如指掌,他們的檔案也可以幫助你,
原文鏈接:https://towardsdatascience.com/why-you-should-learn-catboost-now-390fb3895f76
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/70514.html
標籤:其他
上一篇:1041. Robot Bounded In Circle (M)
下一篇:使用PCA可視化資料