作者|Conor O'Sullivan
編譯|VK
來源|Towards Data Science
主成分分析(PCA)是一個很好的工具,可以用來降低特征空間的維數,PCA的顯著優點是它能產生不相關的特征,并能提高模型的性能,
它可以幫助你深入了解資料的分類能力,在本文中,我將帶你了解如何使用PCA,將提供Python代碼,完整的專案可以在GitHub鏈接:https://github.com/conorosully/medium-articles,

什么是PCA
我們先復習一下這個理論,如果你想確切了解PCA是如何作業的,我們不會詳細介紹,網上有大量學習資源,
PCA用于減少用于訓練模型的特征的數量,它通過從多個特征構造所謂的主成分(PC)來實作這一點,
PC的構造方式使得PC1方向在最大變化上盡可能地解釋了你的特征,然后PC2在最大變化上盡可能地解釋剩余特征,等等……PC1和PC2通常可以解釋總體特征變化中的很大一部分,
另一種思考方法是,前兩個PC可以很好地概括大部分特征,這很重要,因為正如我們將看到的,它允許我們在二維平面上可視化資料的分類能力,
資料集
讓我們來看看一個實際的例子,我們將使用PCA來探索乳腺癌資料集(http://archive.ics.uci.edu/ml/datasets/breast+cancer+wisconsin+(diagnostic)),我們使用下面的代碼匯入該資料集,
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
data = https://www.cnblogs.com/panchuangai/p/pd.DataFrame(cancer['data'],columns=cancer['feature_names'])
data['y'] = cancer['target']
目標變數是乳腺癌檢測的結果,惡性或良性,每次測驗,都要取多個癌細胞,然后從每個癌細胞中采取10種不同的措施,這些測量包括細胞半徑和細胞對稱性,最后,為了得到特征值,我們計算了每個度量值的平均值、標準誤差和最大值(不太好的),這樣我們總共得到30個特征值,
在圖中,我們仔細觀察了其中兩個特征——細胞的平均對稱性(Benign)和最差平滑度(worst smoothness),
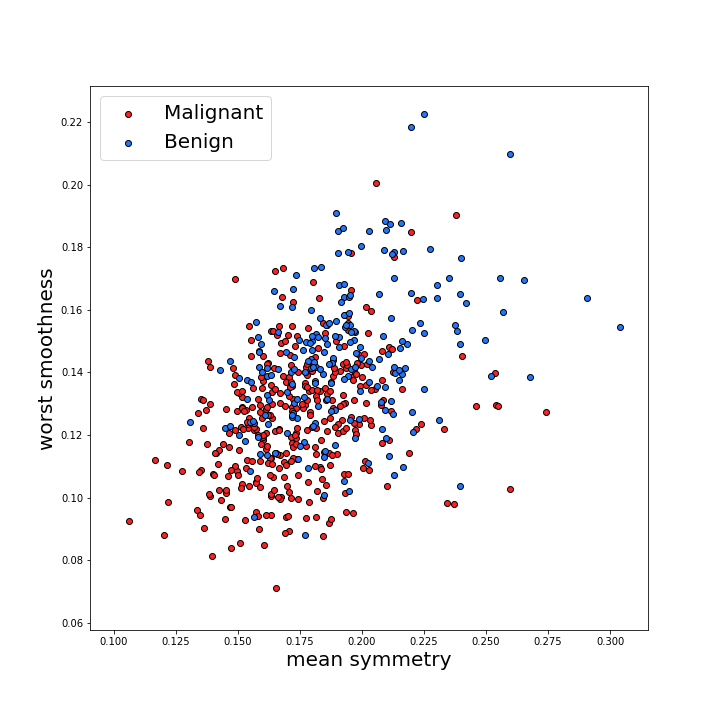
在圖中,我們看到這兩個特征可以幫助區分這兩個類,那就是良性腫瘤往往更為對稱和光滑,但是,仍然有很多重疊,所以僅僅使用這些特征的模型不會做得很好,
我們可以創建這樣的圖來了解每個特征的預測能力,但是有30個特征,這意味著有相當多的圖要分析,他們也沒有告訴我們如何作為一個整體來預測資料集,這我們可以引入PCA,
PCA-整個資料集
首先,我們對整個資料集進行主成分分析,我們使用下面的代碼,
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
#標準化
scaler = StandardScaler()
scaler.fit(data)
scaled = scaler.transform(data)
#PCA
pca = PCA().fit(scaled)
pc = pca.transform(scaled)
pc1 = pc[:,0]
pc2 = pc[:,1]
#畫出主成分
plt.figure(figsize=(10,10))
colour = ['#ff2121' if y == 1 else '#2176ff' for y in data['y']]
plt.scatter(pc1,pc2 ,c=colour,edgecolors='#000000')
plt.ylabel("Glucose",size=20)
plt.xlabel('Age',size=20)
plt.yticks(size=12)
plt.xticks(size=12)
plt.xlabel('PC1')
我們首先標準化特征,使它們的平均值為0,方差為1,這一點很重要,因為主成分分析通過最大化主成分分析所解釋的方差來作業,
一些特征由于其沒有經過標準化自然會有更高的方差,例如,以厘米為單位測量的距離將比以公里為單位測量的相同距離具有更高的方差,在不縮放特征的情況下,主成分分析將被那些高方差特征“吸引”,
縮放完成后,我們會擬合PCA模型,并將我們的特征轉換為PC,由于我們有30個特征,我們最多可以有30個PC,但是,對于可視化,我們只對前兩個感興趣,然后使用PC1和PC2創建如圖所示的散點圖,

在圖2中,我們可以看到兩個不同的簇,雖然仍然有一些重疊,但是簇比我們在之前的圖中要清晰得多,這告訴我們,作為一個整體,這個資料集在區分惡性腫瘤和良性腫瘤方面會做得很好,
我們還應該考慮到,我們只關注前兩個PC,因此并不是所有特征的變化都被捕獲,這意味著使用所有特征訓練的模型仍然可以正確預測例外值(即聚類中不清楚的點),
在這一點上,我們應該提到這種方法的一個警告,我們提到PC1和PC2可以解釋你的特征中很大一部分的差異,然而,這并不總是真的,在這種情況下,這些PC可以被認為是對你的特征的錯誤總結,這意味著,即使你的資料能夠很好地分離,你也可能無法獲得如上圖所示的清晰的簇,
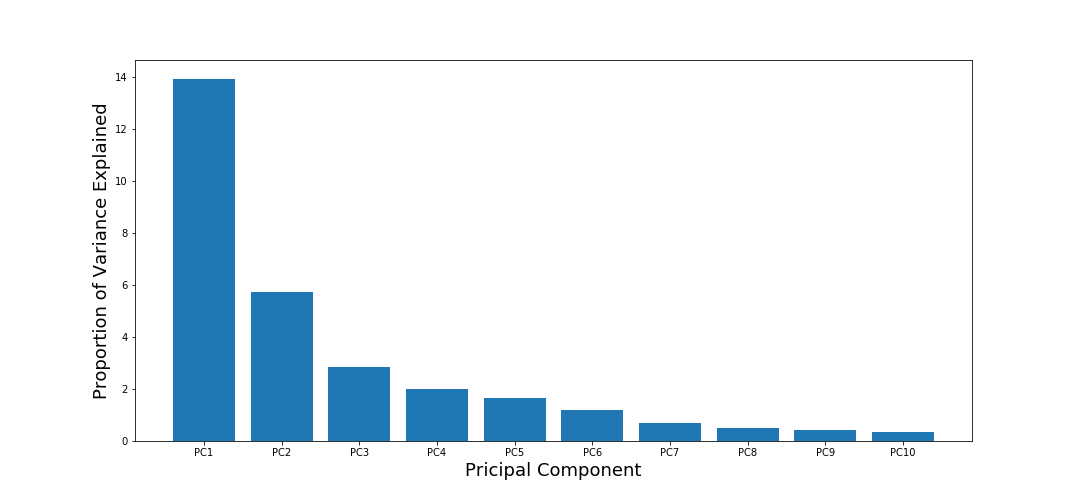
我們可以通過查看PCA-scree圖來確定,我們使用下面的代碼為這個分析創建scree圖,
var = pca.explained_variance_[0:10] #percentage of variance explained
labels = ['PC1','PC2','PC3','PC4','PC5','PC6','PC7','PC8','PC9','PC10']
plt.figure(figsize=(15,7))
plt.bar(labels,var,)
plt.xlabel('Pricipal Component')
plt.ylabel('Proportion of Variance Explained')
它本質上是一個柱狀圖,其中每個柱狀圖的高度是相關PC解釋的方差百分比,我們看到,總共只有大約20%的特征方差是由PC1和PC2解釋的,即使只解釋了20%,我們仍然得到兩個不同的集群,這強調了資料的預測能力,
PCA-特征組
到目前為止,我們已經使用主成分分析來了解整個特征集對資料的分類效果,我們也可以使用這個程序來比較不同的特征組,例如,假設我們想知道細胞的對稱性和光滑性是否比細胞的周長和凹陷性更好,
group_1 = ['mean symmetry', 'symmetry error','worst symmetry',
'mean smoothness','smoothness error','worst smoothness']
group_2 = ['mean perimeter','perimeter error','worst perimeter',
'mean concavity','concavity error','worst concavity']
我們首先創建兩組特征,第一組包含所有與對稱性和光滑性有關的特征,第二組包含所有與周長和凹陷性有關的特征,然后,除了使用這兩組特征外,我們以與之前相同的方式進行主成分分析,這個程序的結果如下圖所示,

我們可以看到,對于第一組,有一些分離,但仍然有很多重疊,相比之下,第2組有兩個不同的簇,因此,從這些圖中,我們可以預期第2組的特征(即細胞周長和凹陷)將是更好的預測腫瘤是惡性還是良性的指標,
最終,這將意味著使用組2中的特征的模型比使用組1中的特征的模型具有更高的精度,現在,讓我們來驗證這個假設,
我們使用下面的代碼來訓練一個使用兩組特征的logistic回歸模型,在每種情況下,我們使用70%的資料來訓練模型,剩下的30%用來測驗模型,
from sklearn.model_selection import train_test_split
import sklearn.metrics as metric
import statsmodels.api as sm
for i,g in enumerate(group):
x = data[g]
x = sm.add_constant(x)
y = data['y']
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.3,
random_state = 101)
model = sm.Logit(y_train,x_train).fit() #fit logistic regression model
predictions = np.around(model.predict(x_test))
accuracy = metric.accuracy_score(y_test,predictions)
print("Accuracy of Group {}: {}".format(i+1,accuracy))
第一組測驗集的準確率為74%,相比之下,第二組的準確率為97%,因此,組2的特征明顯是更好的預測因子,這正是我們從主成分分析結果中所看到的,
最后,我們將了解如何在開始建模之前使用PCA來加深對資料的理解,了解哪些特征是可預測的,將在特征選擇方面給你帶來優勢,此外,查看特征的總體分類能力將使你了解預期的分類精度,
如前所述,這種方法并不能完全證明,因此應與其他資料勘探圖和匯總統計一起使用,一般來說,在開始建模之前,最好從盡可能多的不同角度查看資料,
原文鏈接:https://towardsdatascience.com/visualising-the-classification-power-of-data-54f5273f640
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/70517.html
標籤:其他