作者|LAKSHAY ARORA
編譯|VK
來源|Analytics Vidhya
概述
-
流資料是機器學習領域的一個新興概念
-
學習如何使用機器學習模型(如logistic回歸)使用PySpark對流資料進行預測
-
我們將介紹流資料和Spark流的基礎知識,然后深入到實作部分
介紹
想象一下,每秒有超過8500條微博被發送,900多張照片被上傳到Instagram上,超過4200個Skype電話被打,超過78000個谷歌搜索發生,超過200萬封電子郵件被發送(根據互聯網實時統計),
我們正在以前所未有的速度和規模生成資料,在資料科學領域作業真是太好了!但是,隨著大量資料的出現,同樣面臨著復雜的挑戰,
主要是,我們如何收集這種規模的資料?我們如何確保我們的機器學習管道在資料生成和收集后繼續產生結果?這些都是業界面臨的重大挑戰,也是為什么流式資料的概念在各組織中越來越受到重視的原因,

增加處理流式資料的能力將大大提高你當前的資料科學能力,這是業界急需的技能,如果你能掌握它,它將幫助你獲得下一個資料科學的角色,
因此,在本文中,我們將了解什么是流資料,了解Spark流的基本原理,然后研究一個與行業相關的資料集,以使用Spark實作流資料,
目錄
-
什么是流資料?
-
Spark流基礎
-
離散流
-
快取
-
檢查點
-
-
流資料中的共享變數
-
累加器變數
-
廣播變數
-
-
利用PySpark對流資料進行情感分析
什么是流資料?
我們看到了上面的社交媒體資料——我們正在處理的資料令人難以置信,你能想象存盤所有這些資料需要什么嗎?這是一個復雜的程序!因此,在我們深入討論本文的Spark方面之前,讓我們花點時間了解流式資料到底是什么,
流資料沒有離散的開始或結束,這些資料是每秒從數千個資料源生成的,需要盡快進行處理和分析,相當多的流資料需要實時處理,比如Google搜索結果,
我們知道,一些結論在事件發生后更具價值,它們往往會隨著時間而失去價值,舉個體育賽事的例子——我們希望看到即時分析、即時統計得出的結論,以便在那一刻真正享受比賽,對吧?
Spark流基礎
Spark流是Spark API的擴展,它支持對實時資料流進行可伸縮和容錯的流處理,
在跳到實作部分之前,讓我們先了解Spark流的不同組件,
離散流
離散流或資料流代表一個連續的資料流,這里,資料流要么直接從任何源接收,要么在我們對原始資料做了一些處理之后接收,
構建流應用程式的第一步是定義我們從資料源收集資料的批處理時間,如果批處理時間為2秒,則資料將每2秒收集一次并存盤在RDD中,而這些RDD的連續序列鏈是一個不可變的離散流,Spark可以將其作為一個分布式資料集使用,
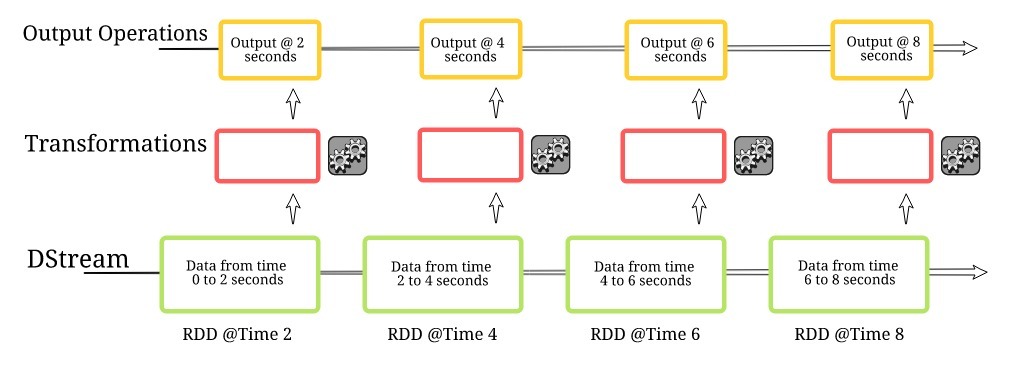
想想一個典型的資料科學專案,在資料預處理階段,我們需要對變數進行轉換,包括將分類變數轉換為數值變數、洗掉例外值等,Spark維護我們在任何資料上定義的所有轉換的歷史,因此,無論何時發生任何錯誤,它都可以追溯轉換的路徑并重新生成計算結果,
我們希望Spark應用程式運行24小時 x 7,并且無論何時出現任何故障,我們都希望它盡快恢復,但是,Spark在處理大規模資料時,出現任何錯誤時需要重新計算所有轉換,你可以想象,這非常昂貴,
快取
以下是應對這一挑戰的一種方法,我們可以臨時存盤計算(快取)的結果,以維護在資料上定義的轉換的結果,這樣,當出現任何錯誤時,我們不必一次又一次地重新計算這些轉換,
資料流允許我們將流資料保存在記憶體中,當我們要計算同一資料上的多個操作時,這很有幫助,
檢查點(Checkpointing)
當我們正確使用快取時,它非常有用,但它需要大量記憶體,并不是每個人都有數百臺擁有128GB記憶體的機器來快取所有東西,
這就引入了檢查點的概念,
檢查點是保存轉換資料幀結果的另一種技術,它將運行中的應用程式的狀態不時地保存在任何可靠的存盤器(如HDFS)上,但是,它比快取速度慢,靈活性低,
當我們有流資料時,我們可以使用檢查點,轉換結果取決于以前的轉換結果,需要保留才能使用它,我們還檢查元資料資訊,比如用于創建流資料的配置和一組DStream(離散流)操作的結果等等,
流資料中的共享變數
有時我們需要為Spark應用程式定義map、reduce或filter等函式,這些函式必須在多個集群上執行,此函式中使用的變數將復制到每個計算機(集群),
在這里,每個集群有一個不同的執行器,我們需要一些東西,可以給我們這些變數之間的關系,
例如,假設我們的Spark應用程式運行在100個不同的集群上,捕獲來自不同國家的人發布的Instagram圖片,我們需要一個在他們的帖子中提到的特定標簽的計數,
現在,每個集群的執行器將計算該集群上存在的資料的結果,但是我們需要一些東西來幫助這些集群進行通信,這樣我們就可以得到聚合的結果,在Spark中,我們有一些共享變數可以幫助我們克服這個問題,
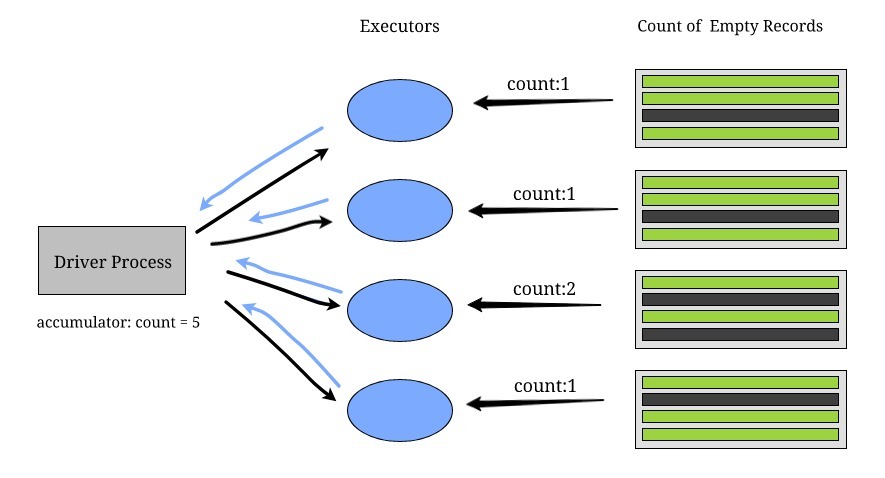
累加器變數
用例,比如錯誤發生的次數、空白日志的次數、我們從某個特定國家收到請求的次數,所有這些都可以使用累加器來解決,
每個集群上的執行器將資料發送回驅動程式行程,以更新累加器變數的值,累加器僅適用于關聯和交換的操作,例如,sum和maximum有效,而mean無效,
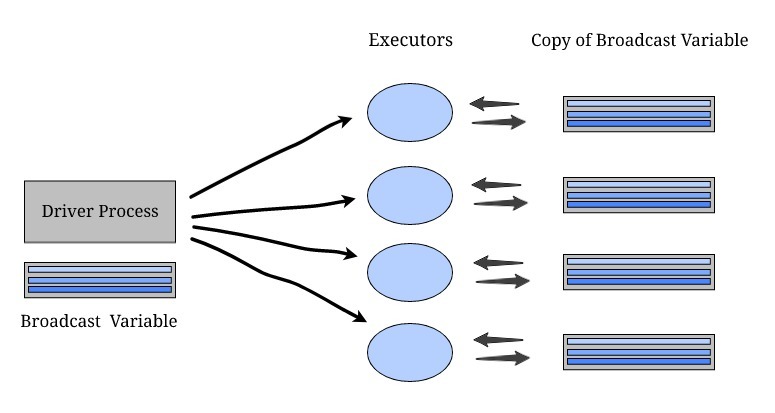
廣播變數
當我們處理位置資料時,比如城市名稱和郵政編碼的映射,這些都是固定變數,現在,如果任何集群上的特定轉換每次都需要此類資料,我們不需要向驅動程式發送請求,因為這太昂貴了,
相反,我們可以在每個集群上存盤此資料的副本,這些型別的變數稱為廣播變數,
廣播變數允許程式員在每臺機器上快取一個只讀變數,通常,Spark會使用有效的廣播演算法自動分配廣播變數,但如果我們有多個階段需要相同資料的任務,我們也可以定義它們,
利用PySpark對流資料進行情感分析
是時候啟動你最喜歡的IDE了!讓我們在本節中進行寫代碼,并以實際的方式理解流資料,
在本節中,我們將使用真實的資料集,我們的目標是在推特上發現仇恨言論,為了簡單起見,如果推特帶有種族主義或性別歧視情緒,我們說它包含仇恨言論,
因此,任務是將種族主義或性別歧視的推文與其他推文進行分類,我們將使用Tweets和label的訓練樣本,其中label'1'表示Tweet是種族主義/性別歧視,label'0'表示其他,

為什么這個專案與流處理相關?因為社交媒體平臺以評論和狀態更新的形式接收海量流媒體資料,這個專案將幫助我們限制公開發布的內容,
你可以在這里更詳細地查看問題陳述-練習問題:Twitter情感分析(https://datahack.analyticsvidhya.com/contest/practice-problem-twitter-sentiment-analysis/?utm_source=blog&utm_medium=streaming-data-pyspark-machine-learning-model),我們開始吧!
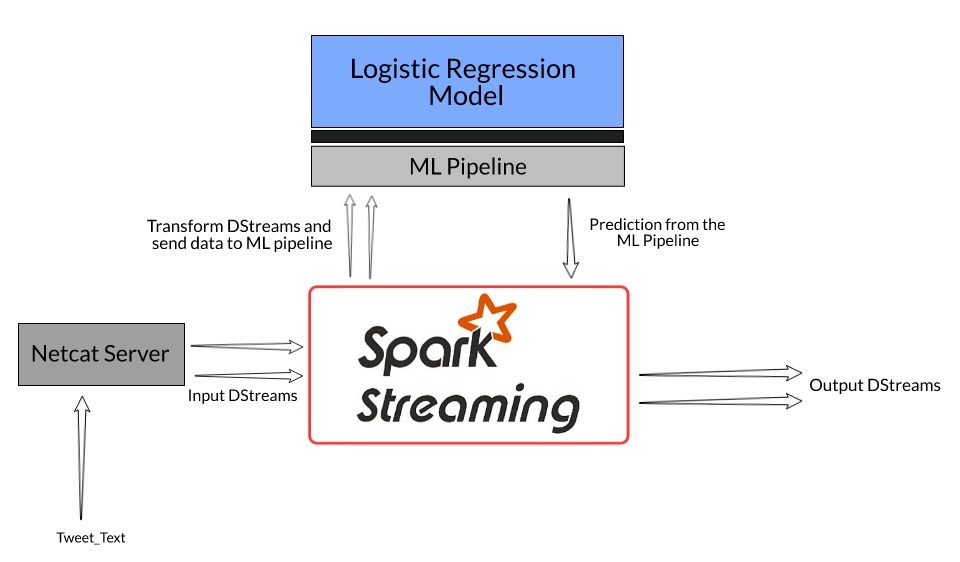
設定專案作業流
-
模型構建:我們將建立一個邏輯回歸模型管道來分類tweet是否包含仇恨言論,在這里,我們的重點不是建立一個非常精確的分類模型,而是查看如何使用任何模型并回傳流資料的結果
-
初始化Spark流背景關系:一旦構建了模型,我們就需要定義從中獲取流資料的主機名和埠號
-
流資料:接下來,我們將從定義的埠添加netcat服務器的tweets,Spark API將在指定的持續時間后接收資料
-
預測并回傳結果:一旦我們收到tweet文本,我們將資料傳遞到我們創建的機器學習管道中,并從模型回傳預測的情緒
下面是我們作業流程的一個簡潔說明:
建立Logistic回歸模型的資料訓練
我們在映射到標簽的CSV檔案中有關于Tweets的資料,我們將使用logistic回歸模型來預測tweet是否包含仇恨言論,如果是,那么我們的模型將預測標簽為1(否則為0),
你可以在這里下載資料集和代碼(https://github.com/lakshay-arora/PySpark/tree/master/spark_streaming),
首先,我們需要定義CSV檔案的模式,否則,Spark將把每列的資料型別視為字串,我們讀取資料并檢查:
# 匯入所需庫
from pyspark import SparkContext
from pyspark.sql.session import SparkSession
from pyspark.streaming import StreamingContext
import pyspark.sql.types as tp
from pyspark.ml import Pipeline
from pyspark.ml.feature import StringIndexer, OneHotEncoderEstimator, VectorAssembler
from pyspark.ml.feature import StopWordsRemover, Word2Vec, RegexTokenizer
from pyspark.ml.classification import LogisticRegression
from pyspark.sql import Row
# 初始化spark session
sc = SparkContext(appName="PySparkShell")
spark = SparkSession(sc)
# 定義方案
my_schema = tp.StructType([
tp.StructField(name= 'id', dataType= tp.IntegerType(), nullable= True),
tp.StructField(name= 'label', dataType= tp.IntegerType(), nullable= True),
tp.StructField(name= 'tweet', dataType= tp.StringType(), nullable= True)
])
# 讀取資料集
my_data = https://www.cnblogs.com/panchuangai/p/spark.read.csv('twitter_sentiments.csv',
schema=my_schema,
header=True)
# 查看資料
my_data.show(5)
# 輸出方案
my_data.printSchema()


定義機器學習管道
現在我們已經在Spark資料幀中有了資料,我們需要定義轉換資料的不同階段,然后使用它從我們的模型中獲取預測的標簽,
在第一階段中,我們將使用RegexTokenizer 將Tweet文本轉換為單詞串列,然后,我們將從單詞串列中洗掉停用詞并創建單詞向量,在最后階段,我們將使用這些詞向量建立一個邏輯回歸模型,并得到預測情緒,
請記住,我們的重點不是建立一個非常精確的分類模型,而是看看如何在預測模型中獲得流資料的結果,
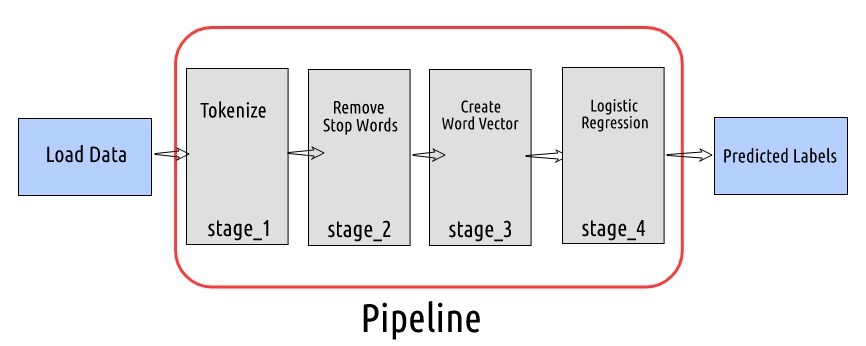
# 定義階段1:標記tweet文本
stage_1 = RegexTokenizer(inputCol= 'tweet' , outputCol= 'tokens', pattern= '\\W')
# 定義階段2:洗掉停用字
stage_2 = StopWordsRemover(inputCol= 'tokens', outputCol= 'filtered_words')
# 定義階段3:創建大小為100的詞向量
stage_3 = Word2Vec(inputCol= 'filtered_words', outputCol= 'vector', vectorSize= 100)
# 定義階段4:邏輯回歸模型
model = LogisticRegression(featuresCol= 'vector', labelCol= 'label')
設定我們的機器學習管道
讓我們在Pipeline物件中添加stages變數,然后按順序執行這些轉換,將管道與訓練資料集匹配,現在,每當我們有新的Tweet時,我們只需要將其傳遞到管道物件并轉換資料以獲得預測:
# 設定管道
pipeline = Pipeline(stages= [stage_1, stage_2, stage_3, model])
#擬合模型
pipelineFit = pipeline.fit(my_data)
流資料和回傳的結果
假設我們每秒收到數百條評論,我們希望通過阻止發布包含仇恨言論的評論的用戶來保持平臺的干凈,所以,每當我們收到新的文本,我們就會把它傳遞到管道中,得到預測的情緒,
我們將定義一個函式 get_prediction,它將洗掉空白陳述句并創建一個資料框,其中每行包含一條推特,
因此,初始化Spark流背景關系并定義3秒的批處理持續時間,這意味著我們將對每3秒收到的資料進行預測:
#定義一個函式來計算情感
def get_prediction(tweet_text):
try:
# 過濾得到長度大于0的tweets
tweet_text = tweet_text.filter(lambda x: len(x) > 0)
# 創建一個列名為“tweet”的資料框,每行將包含一條tweet
rowRdd = tweet_text.map(lambda w: Row(tweet=w))
# 創建spark資料框
wordsDataFrame = spark.createDataFrame(rowRdd)
# 利用管道對資料進行轉換,得到預測的情緒
pipelineFit.transform(wordsDataFrame).select('tweet','prediction').show()
except :
print('No data')
# 初始化流背景關系
ssc = StreamingContext(sc, batchDuration= 3)
# 創建一個將連接到hostname:port的資料流,如localhost:9991
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
# 用一個關鍵字“tweet_APP”分割tweet文本,這樣我們就可以從一條tweet中識別出一組單詞
words = lines.flatMap(lambda line : line.split('TWEET_APP'))
# 獲取收到的推文的預期情緒
words.foreachRDD(get_prediction)
#開始計算
ssc.start()
# 等待結束
ssc.awaitTermination()
在一個終端上運行程式并使用Netcat(一個實用工具,可用于將資料發送到定義的主機名和埠號),可以使用以下命令啟動TCP連接:
nc -lk port_number
最后,在第二個終端中鍵入文本,你將在另一個終端中實時獲得預測:
視頻演示地址:https://cdn.analyticsvidhya.com/wp-content/uploads/2019/12/final_twitter_sentiment.mp4?_=1
結尾
流資料在未來幾年會增加的越來越多,所以你應該開始熟悉這個話題,記住,資料科學不僅僅是建立模型,還有一個完整的管道需要處理,
本文介紹了Spark流的基本原理以及如何在真實資料集上實作它,我鼓勵你使用另一個資料集或收集實時資料并實作我們剛剛介紹的內容(你也可以嘗試其他模型),
原文鏈接:https://www.analyticsvidhya.com/blog/2019/12/streaming-data-pyspark-machine-learning-model/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/70520.html
標籤:其他
上一篇:使用PCA可視化資料
下一篇:詞袋模型和TF-IDF