第二章 步入資料之門
什么是資料
承載了資訊的東西
什么是資訊
資訊是用來消除隨機不定性的東西
演算法
在同一個算 法中,不同的引數和閾值設定同樣會帶來大相徑庭的結果,甚至影響資料解讀的科學性
第三章 排列組合與古典概型
1.古典概型
如果一個隨機試驗所包含的單位事件(就是剛才說的3次朝上分別為“正正正”、“正正反”……這其中每一種情況都是單位事件)是有限的,且每個單位事件發生的可能性均相等,則這個隨機試驗叫做拉普拉斯試驗,這種條件下的概率模型就叫古典概型,古典概型也叫傳統概率,該定義是由法國著名數學家拉普拉斯(Laplace)提出的, 第4章 統計與分布 4.1.1 加和值以使用加和值來對一群事物進行描述是一種非常自然的描述方式,比如:超市結賬,使用加和值來對整體進行描述 4.1.2 平均值“一年級一班有40名學生,3門課程平均分為80分”,“一年級二班有60名學生,3門課程平均分為75分”,“一年級三班有50名學生,3門課程平均分為80分”,從這組資料來看,基本可以得到一個印象,就是一年級一班的成績“普遍”比一年級二班“好”,至少是從“宏觀體現”上看比二班好,它和一年級三班“一樣好”,但是一年級一班和一年級三班這兩個班的每個人的成績都是一樣的嗎?至少人數是不一樣的,那么也許還需要進一步地描述這平均下來的80分和每個學生具體的課程分數之間的差異性有多大,這就涉及另一個描述的需求——標準差, 4.1.3 標準差我們先上公式,標準差公式如下: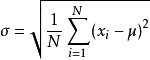 下面解釋一下這個公式的含義,我們以一年級一班所有40個學生為例,那么3門考試的情況下全班就有120個分數參與統計,也就是n=120,把每個學生每門課的成績減去全班的3個學科總的平均分80分,這樣得到120個差值,再把這些差值分別平方(主要是為了去掉負數,因為在分數差距里面,不管是比這個平均值多,還是比這個平均值少,都被視為偏差),將這些平方的結果再加和,之后除以參與統計的學科數量120,最后開平方,這個數字只可能是一個大于等于零的數字,用漢字描述起來很啰嗦,但是一旦變成一個標準差的指標以后,由于是約定俗成的,所以只需要“標準差”這3個字就能表示了,這個數字表示的是什么含義?從這個數字得到的程序其實不難看出來,如果所有的人的所有課程成績都是和平均分一樣,那么算出來的標準差就是0,因為每一個 ( xi - u )^2 肯定都是0^2;反之,如果所有的人的課程成績與平均分的差距都很大,好的很好,差的很差,那么結果就是這個值會很大,如果一個班級成績標準差比另一個班級成績的標準差小,說明學生之間的考試成績水平差不多,標準差大則說明學生之間的考試成績水平相差比較大, 4.2 加權均值如以重量1:4的原漿和水的比例來勾兌白酒,勾兌完的白酒成本怎么計算?1kg白酒成本=(1kg白酒原漿成本×1+1kg水成本×4)÷(1+4)而絕對不會是(1kg白酒原漿成本+1kg水成本)÷2 4.3.1 眾數我們可以感性地理解眾數就是在樣本物件中出現最多的那個數字 4.3.2 中位數中位數,顧名思義,就是位于中間位置的數字用中位數來描述樣本的分布,在一定程度上可以消除個別極端值對整個樣本平均值的影響, 4.4 歐氏距離這個距離需要用兩個點在各自維度上的坐標相減,平方后相加然后再開平方
下面解釋一下這個公式的含義,我們以一年級一班所有40個學生為例,那么3門考試的情況下全班就有120個分數參與統計,也就是n=120,把每個學生每門課的成績減去全班的3個學科總的平均分80分,這樣得到120個差值,再把這些差值分別平方(主要是為了去掉負數,因為在分數差距里面,不管是比這個平均值多,還是比這個平均值少,都被視為偏差),將這些平方的結果再加和,之后除以參與統計的學科數量120,最后開平方,這個數字只可能是一個大于等于零的數字,用漢字描述起來很啰嗦,但是一旦變成一個標準差的指標以后,由于是約定俗成的,所以只需要“標準差”這3個字就能表示了,這個數字表示的是什么含義?從這個數字得到的程序其實不難看出來,如果所有的人的所有課程成績都是和平均分一樣,那么算出來的標準差就是0,因為每一個 ( xi - u )^2 肯定都是0^2;反之,如果所有的人的課程成績與平均分的差距都很大,好的很好,差的很差,那么結果就是這個值會很大,如果一個班級成績標準差比另一個班級成績的標準差小,說明學生之間的考試成績水平差不多,標準差大則說明學生之間的考試成績水平相差比較大, 4.2 加權均值如以重量1:4的原漿和水的比例來勾兌白酒,勾兌完的白酒成本怎么計算?1kg白酒成本=(1kg白酒原漿成本×1+1kg水成本×4)÷(1+4)而絕對不會是(1kg白酒原漿成本+1kg水成本)÷2 4.3.1 眾數我們可以感性地理解眾數就是在樣本物件中出現最多的那個數字 4.3.2 中位數中位數,顧名思義,就是位于中間位置的數字用中位數來描述樣本的分布,在一定程度上可以消除個別極端值對整個樣本平均值的影響, 4.4 歐氏距離這個距離需要用兩個點在各自維度上的坐標相減,平方后相加然后再開平方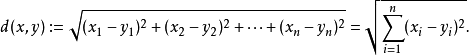 4.5 曼哈頓距離d(i,j)=|X1-X2|+|Y1-Y2|.在國際象棋棋盤上,有這種橫平豎直的格子,描述格子和格子之間的距離可以直接用曼哈頓距離
4.5 曼哈頓距離d(i,j)=|X1-X2|+|Y1-Y2|.在國際象棋棋盤上,有這種橫平豎直的格子,描述格子和格子之間的距離可以直接用曼哈頓距離第8章 回歸8.1 線性回歸 回歸的英文是Regression,單詞原型的regress大概的意思是“回退,退化,倒退”,其實Regression——回歸分析的意思借用了“倒退,倒推”的含義,簡單說就是“由果索因”的過程,是一種歸納的思想——當看到大量的事實所呈現的樣態,推斷出原因是如何的;當看到大量的數字對(pair)是某種樣態,推斷出它們之間蘊含的關系是如何的 線性回歸是利用數理統計學中的回歸分析來確定兩種或兩種以上變數間相互依賴的定量關系的一種統計分析方法,其表達形式如下:y = ax + b + ee為誤差服從均值為0的正態分布 8.2擬合這種把平面上一系列的點用一條光滑的曲線連接起來的程序就叫做擬合 8.4 過擬合過擬合簡稱“過擬”,是在擬合程序中出現的一種“做過頭”的情況 過度擬合的危害有以下幾點,(1)描述復雜,所有的過度擬合的模型都有一個共同點,那就是模型的描述非常復雜——引數繁多,計算邏輯多, (2)失去泛化能力,所謂泛化能力就是通過學習(或機器學習)得到的模型對未知數據的預測能力,即應用于其他非訓練樣本的向量時的分類能力,對于待分類樣本向量分類正確度高,表示泛化能力比較好;反之,如果對于待分類樣本向量分類正確度低,則表示泛化能力較差, 8.5 欠擬合欠擬顧名思義,就是由于操作不當——也可以說建模不當產生的誤差e分布太散或者太大的情況,這種情況下,通常體現出來的都是在線性回歸中的因素考慮不足的情況,常見的原因有以下兩種,(1)引數過少 對于訓練樣本向量的維度提取太少會導致模型描述的不準確,例如,要根據銀行儲戶的資訊來判斷其信譽好或不好,通常需要綜合考慮用戶的年齡、流水總和、賬戶余額、借貸頻次、借貸額度、歸還準時程度等資訊特征,這些因素考慮得越充分,通常對于用戶的信譽好或不好,給予的信用額度多少為宜就會有比較可靠的預測程度,而如果引數太少,如只有賬戶余額一項,那么就不得不用賬戶余額一個引數和信譽好壞去建立一個模型映射關系,這個模型是很不科學的,通過一個余額的數字就能斷言一個人信譽幾何太過武斷,(2)擬合不當,擬合不當的原因比較復雜,通常是擬合方法不正確造成的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/73701.html
標籤:其他
上一篇:Pytorch入門教程