
在時間序列預測中,臟亂資料的存在會影響最終的預測結果,這是肯定的,尤其是在這個領域,因為時間依賴性在處理時間序列時起著至關重要的作用,
噪音或例外值必須按照特別的解決方案小心處理,在這種情況下,tsmoothie包可以幫助我們節省大量時間來準備用于分析的時間序列,Tsmoothie是一個用于時間序列平滑和離群值檢測的python庫,它可以以向量化的方式處理多個序列,它很有用,因為它可以提供我們需要的預處理步驟,如去噪或離群值去除,保留原始資料中的時間模式,
在這篇文章中,我們使用這些小工具來改進預測任務,更準確地說,我們試圖預測太陽能電池板的日發電量,最后,我們期望能從去噪程序中獲益,并產生比未進行預處理的情況更好的預測,
資料
Kaggle上有一個真實的資料集,這些資料存盤了安裝在私人住宅屋頂上的太陽能電池板每天的發電量,資料記錄自2011年,以時間序列的形式呈現3個不同的來源:
- 房子每天的煤氣消耗量,
- 房屋的日常耗電量,當值為負值時,表示太陽能超過當地的電力消耗,
- 功率表在直流到交流轉換器上的日值,這是當前累積的太陽能,我們不需要累積值,相反,我們需要絕對的日值,因此,我們做了一個簡單的區分,這是我們要預測的目標,
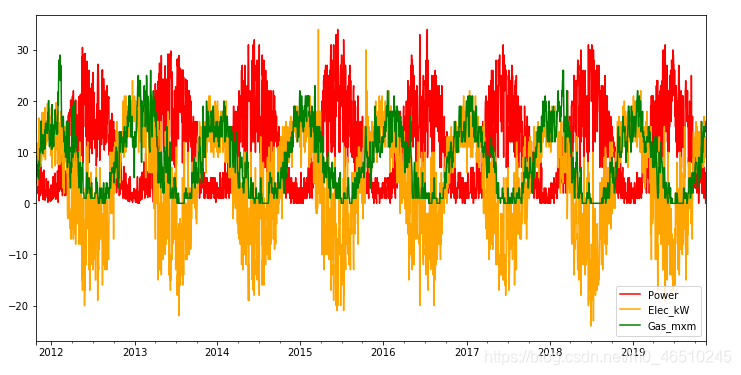
正如我們可以從原始系列的情節中注意到的,有很多噪音存在,這是正常的資料登記的傳感器,如果我們的資料源受到外部氣象條件的影響,或者傳感器質量不佳,位置不理想,情況會更糟,
幸運的是,我們有知識和工具來實作我們的預測任務的良好結果,
時間序列平滑
我們作業流程中的第一步是時間序列預處理,我們的戰略非常直觀和有效,我們取目標時間序列(發電量),并用一種奇妙的工具使其平滑:卡爾曼濾波器,這是每個資料科學家都必須知道的,
一般來說,在時間序列任務中,使用卡爾曼濾波的最大優點是可以使用狀態空間形式來表示未觀察到的組件模型,以狀態空間形式表示時間序列模型的范圍是可用性的一套通用演算法(包括卡爾曼濾波),用于計算高斯似然,可以在數值上最大化,得到模型引數的最大似然估計,著名的軟體使用這種表示來匹配像ARIMA這樣的模型并非偶然,在我們的特殊情況下,我們使用卡爾曼濾波器和狀態空間表示來構建一個未觀察組件模型,
到目前為止所解釋的一切聽起來可能很棘手,但我想向您保證……Tsmoothie可以輕松地構建未觀察到的組件模型,以非常簡單和有效的方式操作定制的Kalman平滑,在這個階段,我們可以釋放我們的想象力,從水平、趨勢、季節性、長季節性中發現哪些成分有助于創建我們正在觀察的時間序列,365天的水平和漫長的季節對我們來說很好,我們只需為每個組件假設添加一個“置信度”,就完成了,

卡爾曼平滑的可視化展示
結果平滑的時間序列保持相同的時間模式存在于原始資料,但具有一致和合理的降噪,
專業提示:如果我們的系列中包含nan,這不是一個問題,卡爾曼平滑會作業得非常好,它是一個非常強大的工具,以填補我們的資料空白……這是卡爾曼平滑的美麗,
時間序列預測
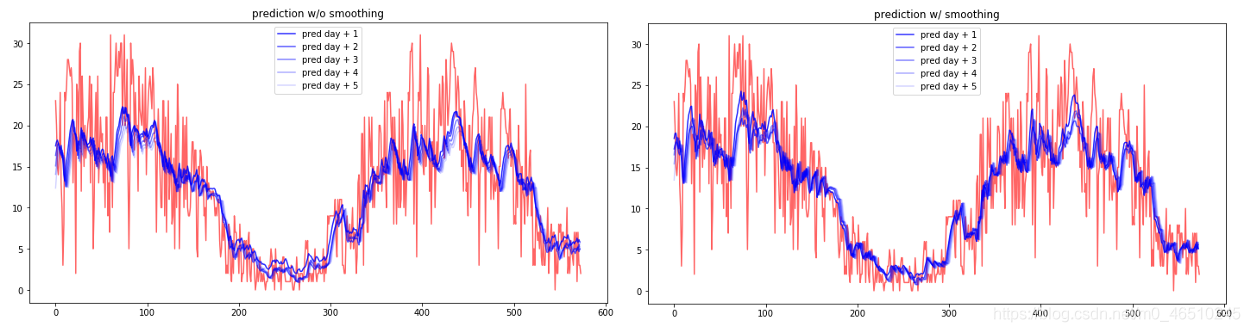
第二步是建立一個神經網路結構來預測未來幾天的發電量,首先對原始資料擬合模型,然后對平滑后的序列進行擬合,平滑資料僅作為目標變數使用,所有輸入序列保持原始格式,使用平滑標簽的目的是為了幫助模型更好地捕捉真實模式和去除噪聲,
我們選擇一個LSTM自動編碼器來預測接下來的5個日發電量值,訓練程式使用keras-hypetune進行,該框架以非常直觀的方式提供了神經網路結構的超引數優化,我們對一些引陣列合進行網格搜索,
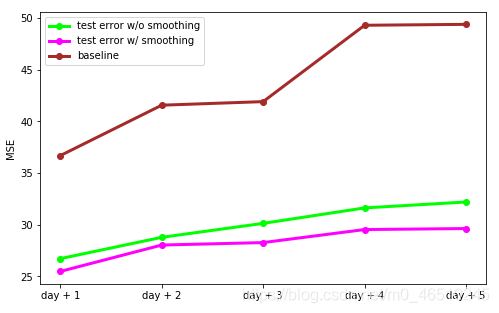
我們可以想象,預測誤差與時間范圍有關,對第二天的預測比對未來五天的預測更準確,重要的一點是,平滑程序提供了很大的好處,在預測精度的所有時間跨度,
總結
在這篇文章中,我們利用了預測場景中的時間序列平滑,應用卡爾曼濾波平滑使得原始資料和減少噪聲的存在,這種選擇在預測精度方面被證明是有利的,我還想指出卡爾曼濾波在這個應用程式中的威力,以及它在構建未觀察組件模型時是一個很好的工具的能力,
本文代碼:https://github.com/cerlymarco/MEDIUM_NoteBook
作者:Marco Cerliani
deephub翻譯組
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/76270.html
標籤:其他
上一篇:深度學習環境搭建