spaCy教程學習
作者|PRATEEK JOSHI
編譯|VK
來源|Analytics Vidhya
介紹
spaCy是我的自然語言處理(NLP)任務的必備庫,我冒昧地說,大多數專家都是這樣!
如今,在眾多的NLP庫中,spaCy確實獨樹一幟,如果你在NLP上用過spaCy,你就會知道我在說什么,如果你對spaCy的強大功能還不熟悉,你會被這個庫的多功能性和靈活性所吸引,
spaCy的優點是它提供一系列優良的特性,庫也是易用的,以及庫總是保持最新,

spaCy入門
如果你對spaCy還不熟悉,你應該注意以下幾點:
-
spaCy的統計模型
-
spaCy的處理管道
讓我們詳細討論一下每一個問題,
spaCy的統計模型
這些模型是spaCy的核心,這些模型使spaCy能夠執行一些與NLP相關的任務,例如詞性標記、命名物體識別和依存關系決議,
下面我列出了spaCy中的不同統計模型及其規范:
-
en_core_web_sm:英語多任務CNN,在OntoNotes上訓練,大小為11 MB
-
en_core_web_md:英語多任務CNN,在OntoNotes上訓練,并且使用Common Crawl上訓練的GLoVe詞嵌入,大小為91 MB
-
en_core_web_lg:英語多任務CNN,在OntoNotes上訓練,并且使用Common Crawl上訓練的GLoVe詞嵌入,大小為789 MB
匯入這些模型非常容易,我們可以通過執行spacy.load(‘model_name’) 匯入模型,如下所示:
import spacy
nlp = spacy.load('en_core_web_sm')
spaCy的處理管道
使用spaCy時,文本字串的第一步是將其傳遞給NLP物件,這個物件本質上是由幾個文本預處理操作組成的管道,輸入文本字串必須通過這些操作,
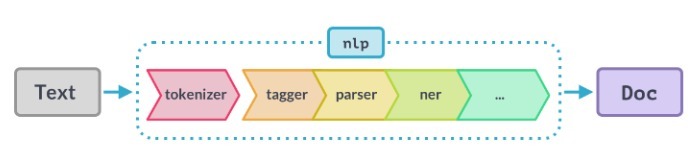
如上圖所示,NLP管道有多個組件,如標記生成器、標簽器、決議器、ner等,因此,在處理輸入文本字串之前,必須先通過所有這些組件,
讓我演示如何創建nlp物件:
import spacy
nlp = spacy.load('en_core_web_sm')
# 創建nlp物件
doc = nlp("He went to play basketball")
你可以使用以下代碼找出活動的管道組件:
nlp.pipe_names
輸出:['tagger','parser','ner']
如果您希望禁用管道組件并僅保持ner的運行,則可以使用下面的代碼禁用管道組件:
nlp.disable_pipes('tagger', 'parser')
讓我們再次檢查活動管道組件:
nlp.pipe_names
輸出:['ner']
當您只需要標記文本時,就可以禁用整個管道,標記化程序變得非常快,例如,可以使用以下代碼行禁用管道的多個組件:
nlp.disable_pipes('tagger', 'parser')
spaCy實戰
現在,讓我們練手,在本節中,你將學習使用spaCy執行各種NLP任務,我們將從流行的NLP任務開始,包括詞性標記、依存分析和命名物體識別,
1.詞性標注
在英語語法中,詞類告訴我們一個詞的功能是什么,以及如何在句子中使用,英語中常用的詞類有名詞、代詞、形容詞、動詞、副詞等,
詞性標注是自動將詞性標注分配給句子中所有單詞的任務,它有助于NLP中的各種下游任務,如特征工程、語言理解和資訊提取,
在spaCy中執行POS標記是一個簡單的程序:
import spacy
nlp = spacy.load('en_core_web_sm')
# 創建nlp物件
doc = nlp("He went to play basketball")
# 遍歷token
for token in doc:
# Print the token and its part-of-speech tag
print(token.text, "-->", token.pos_)
輸出:
He –> PRON
went –> VERB
to –> PART
play –> VERB
basketball –> NOUN
因此,該模型正確識別了句子中所有單詞的POS標記,如果你對這些標記中的任何一個都不確定,那么您可以簡單地使用spacy.explain()來確定:
spacy.explain("PART")
輸出: ‘particle’
2.使用spaCy進行依存分析
每個句子都有一個語法結構,通過依存句法分析,我們可以提取出這個結構,它也可以看作是一個有向圖,其中節點對應于句子中的單詞,節點之間的邊是單詞之間的對應依賴關系,
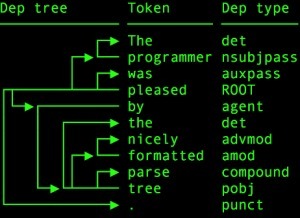
在spaCy中,執行依存分析同樣非常容易,我們將使用與詞性標注相同的句子:
# 依存分析
for token in doc:
print(token.text, "-->", token.dep_)
輸出:
He –> nsubj
went –> ROOT
to –> aux
play –> advcl
basketball –> dobj
依存標記ROOT表示句子中的主要動詞或動作,其他詞與句子的詞根有直接或間接的聯系,通過執行下面的代碼,你可以了解其他標記的含義:
spacy.explain("nsubj"), spacy.explain("ROOT"), spacy.explain("aux"), spacy.explain("advcl"), spacy.explain("dobj")
輸出:
(‘nominal subject’,
None,
‘auxiliary’,
‘adverbial clause modifier’,
‘direct object’)
3.基于spaCy的命名物體識別
首先讓我們了解什么是物體,物體是表示諸如個人、地點、組織等常見事物的資訊的詞或詞組,這些物體具有專有名稱,
例如,請考慮以下句子:

在這句話中,物體是“Donald Trump”、“Google”和“New York City”,
現在讓我們看看spaCy如何識別句子中的命名物體,
doc = nlp("Indians spent over $71 billion on clothes in 2018")
for ent in doc.ents:
print(ent.text, ent.label_)
輸出:
Indians NORP
over $71 billion MONEY
2018 DATE
spacy.explain("NORP")
輸出:‘Nationalities or religious or political groups’
4.基于規則的spaCy匹配
基于規則的匹配是spaCy的新功能,使用這個spaCy匹配器,您可以使用用戶定義的規則在文本中查找單詞和短語,
就像正則運算式,
正則運算式使用文本模式來查找單詞和短語,而spaCy匹配器不僅使用文本模式,還使用單詞的詞匯屬性,如POS標記、依賴標記、詞根等,
讓我們看看它是如何作業的:
import spacy
nlp = spacy.load('en_core_web_sm')
# 匯入 spaCy Matcher
from spacy.matcher import Matcher
#用spaCy詞匯表初始化Matcher
matcher = Matcher(nlp.vocab)
doc = nlp("Some people start their day with lemon water")
# 定義規則
pattern = [{'TEXT': 'lemon'}, {'TEXT': 'water'}]
# 添加規則
matcher.add('rule_1', None, pattern)
所以,在上面的代碼中:
-
首先,我們匯入spaCy matcher
-
之后,我們用默認的spaCy詞匯表初始化matcher物件
-
然后,我們像往常一樣在NLP物件中傳遞輸入
-
在下一步中,我們將為要從文本中提取的內容定義規則,
假設我們想從文本中提取“lemon water”這個短語,所以,我們的目標是water跟在lemon后面,最后,我們將定義的規則添加到matcher物件,
現在讓我們看看matcher發現了什么:
matches = matcher(doc)
matches
輸出: [(7604275899133490726, 6, 8)]
輸出有三個元素,第一個元素“7604275899133490726”是匹配ID,第二個和第三個元素是匹配標記的位置,
# 提取匹配文本
for match_id, start, end in matches:
# 獲得匹配的寬度
matched_span = doc[start:end]
print(matched_span.text)
輸出:lemon water
因此,模式是一個標記屬性串列,例如,“TEXT”是一個標記屬性,表示標記的確切文本,實際上,spaCy中還有許多其他有用的標記屬性,可以用來定義各種規則和模式,
我列出了以下標記屬性:
| 屬性 | 型別 | 描述 |
|---|---|---|
ORTH |
unicode | 精確匹配的文本 |
TEXT |
unicode | 精確匹配的文本 |
LOWER |
unicode | 文本小寫形式 |
LENGTH |
int | 文本的長度 |
IS_ALPHA, IS_ASCII, IS_DIGIT |
bool | 文本由字母字符、ASCII字符、數字組成, |
IS_LOWER, IS_UPPER, IS_TITLE |
bool | 文本是小寫、大寫、首字母大寫格式的, |
IS_PUNCT, IS_SPACE, IS_STOP |
bool | 文本是標點符號、空格、停用詞, |
LIKE_NUM, LIKE_URL, LIKE_EMAIL |
bool | 文本表示數字、URL和電子郵件, |
POS, TAG, DEP, LEMMA, SHAPE |
unicode | 文本是詞性標記、依存標簽、詞根、形狀, |
ENT_TYPE |
unicode | 物體標簽 |
讓我們看看spaCy matcher的另一個用例,考慮下面的兩句話:
- You can read this book
- I will book my ticket
現在我們感興趣的是找出一個句子中是否含有“book”這個詞,看起來挺直截了當的對吧?但這里有一個問題——只有當“book”這個詞在句子中用作名詞時,我們才能找到它,
在上面的第一句中,“book”被用作名詞,在第二句中,它被用作動詞,因此,spaCy匹配器應該只能從第一句話中提取,我們試試看:
doc1 = nlp("You read this book")
doc2 = nlp("I will book my ticket")
pattern = [{'TEXT': 'book', 'POS': 'NOUN'}]
# 用共享的vocab初始化matcher
matcher = Matcher(nlp.vocab)
matcher.add('rule_2', None, pattern)
matches = matcher(doc1)
matches
輸出: [(7604275899133490726, 3, 4)]
matcher在第一句話中找到了模式,
matches = matcher(doc2)
matches
輸出:[]
很好!盡管“book”出現在第二句話中,matcher卻忽略了它,因為它不是一個名詞,
結尾
這是一個很短的介紹,讓你嘗嘗spaCy能做什么,相信我,你會發現自己在NLP任務中經常使用spaCy,我鼓勵你使用這些代碼,從DataHack中獲取一個資料集,并使用spaCy嘗試使用它,
原文鏈接:https://www.analyticsvidhya.com/blog/2020/03/spacy-tutorial-learn-natural-language-processing/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/82493.html
標籤:其他