作者:Luyang Wang, Kai Huang, Jiao Wang, Shengsheng Huang, Jason Dai
基于深度學習的推薦模型已廣泛應用于各種電商平臺中,為用戶提供推薦,目前常用的方法通常會將用戶和商品embedding 向量連接起來輸入多層感知器(multilayer perceptron)以生成最終的預測,但是,這些方法無法捕獲實時用戶行為信號,并且沒有考慮到重要的情景特征(例如時間和位置等)的影響,以致最終的推薦不能準確地反映用戶的實時偏好,這個問題在快餐推薦的應用場景中更為重要,因為:
- 如果當用戶的購物車中已經添加了飲料時,用戶不太可能再購買其他飲料,
- 用戶的購買偏好會在給定的地點、時間和當前的天氣條件下發生很大變化,例如,人們幾乎從不在半夜給孩子們買食物,也不太可能在寒冷的雨天購買冰鎮飲料,
在此文章中,我們介紹了Transformer Cross Transformer(TxT)模型,該模型可以利用到實時用戶點餐行為以及情景特征來推斷用戶的當前偏好,該模型的主要優點是,我們應用了多個Transformer編碼器來提取用戶點單行為和復雜的情景特征,并通過點積的方法將Transformer輸出組合在一起以生成推薦,
此外,我們利用Analytics Zoo提供的RayOnSpark功能,使用Ray*, Apache Spark* 和Apache MXNet* 構建了一個完整的端到端的推薦系統,它將資料處理(使用Spark)和分布式訓練(使用MXNet和Ray)集成到一個統一的資料分析和AI流水線中,并直接運行在存盤資料的同一個大資料集群上,我們已經在Burger King成功部署了這套推薦系統,并且已經在生產環境中取得了卓越的成果,
TxT推薦模型
我們提出了Transformer Cross Transformer(TxT)模型,該模型使用Sequence Transformer對客戶訂單行為進行編碼,使用Context Transformer對情景特征(例如天氣,時間和位置等)進行編碼,然后使用點積的方式將它們組合(“cross”部分)以產生最終輸出,如圖1所示,我們利用MXNet API實作了我們的模型代碼,
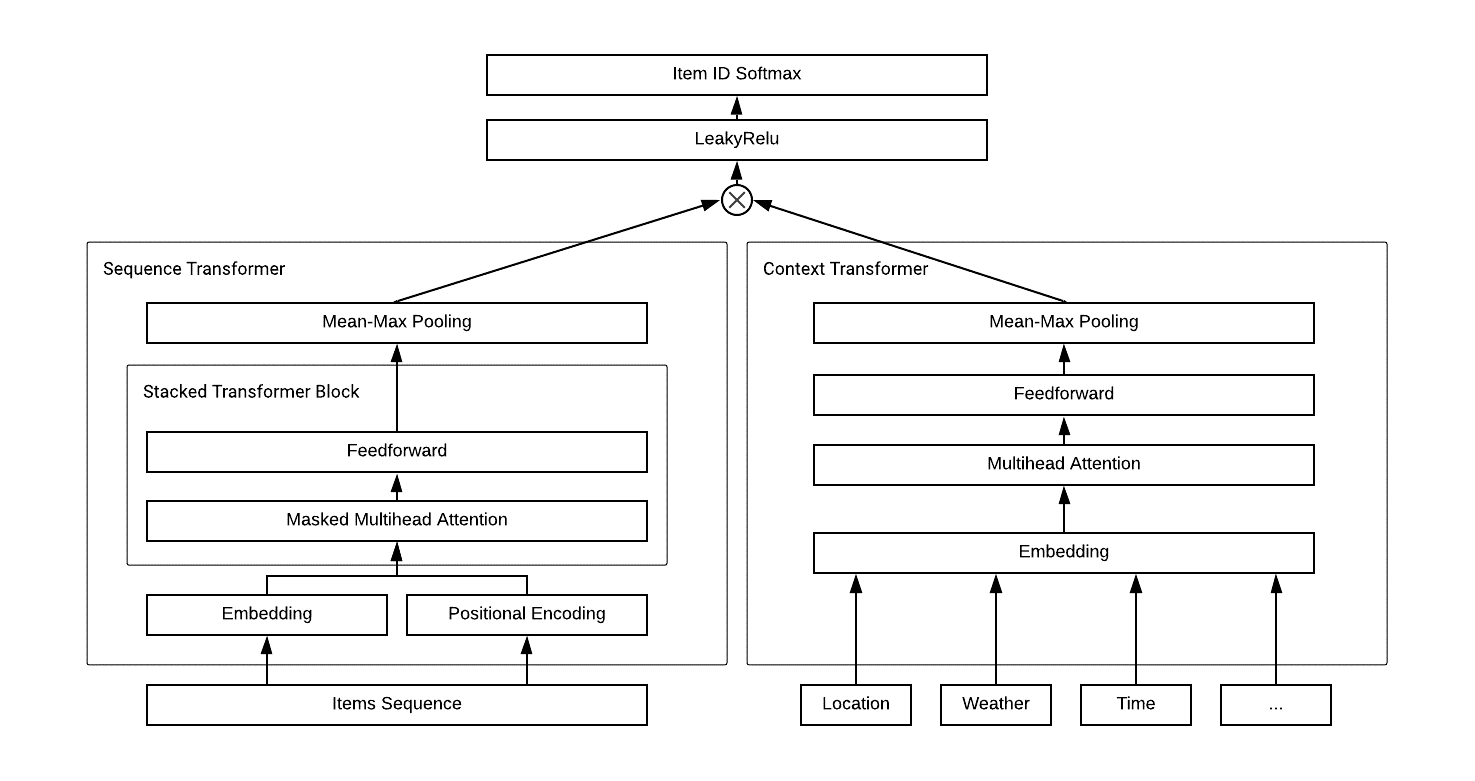
圖1: TxT模型結構
Sequence Transformer
我們基于Transformer架構創建了一個Sequence Transformer,用于學習客戶購物車中包含每件產品加入順序資訊的embedding 向量,如圖1的左下部分所示,為了確保商品位置資訊可以在其原始的購物行為中得到考慮,除了商品特征embedding之外,我們還對商品進行基于位置的embedding,兩個embedding的輸出加在一起,輸入到一個multi-head self-attention神經網路中,
為了從每個商品的隱藏向量中提取客戶整個購物車資訊的向量表示,我們將mean-pooling和max-pooling分別與最終Sequence Transformer的輸出連接起來,通過這種方式,pooling層的輸出既考慮到了在購物車中包含的所有產品,同時又專注提取了少數關鍵產品的顯著特征,
Sequence Transformer可以使用Analytics Zoo中的API直接構建,如下:
from zoo.models.recommendation import SequenceTransformer sequence_transformer = SequenceTransformer( num_items=num_items, item_embed=200, item_hidden_size=200, item_max_length=10, item_num_heads=4, item_num_layers=2, item_transformer_dropout=0.1, item_pooling_dropout=0.1, cross_size=100) item_outs = sequence_transformer(input_items, padding_mask)
Context Transformer
合并情景特征的一種常見方法是將它們與帶時間序列的輸入特征直接連接起來,但是簡單地將非時間序列的特征與時間序列的特征連接起來的意義不大,以前的一些解決方案使用相加來處理多個情景特征,然而簡單的相加只能綜合多個情景特征對輸出做出的貢獻,但大多數情況下,這些情景特征對用戶最終決策的貢獻并不相等,
因此,我們使用Context Transformer對情景特征進行編碼,如圖1右下方所示,使用Transformer的multi-head self-attention,我們不僅可以捕獲每一個情景特征的影響,還可以捕獲不同情景特征之間的內部關系和復雜的互動作用,
Context Transformer可以使用Analytics Zoo中的API直接構建,如下:
context_transformer = ContextTransformer( context_dims=context_dims, context_embed=100, context_hidden_size=200, context_num_heads=2, context_transformer_dropout=0.1, context_pooling_dropout=0.1, cross_size=100) context_outs = context_transformer(input_context_features)
Transformer Cross Transformer
為了聯合訓練Sequence Transformer和Context Transformer,我們在這兩個transformer輸出之間做點積進行聯合訓練,同時優化商品的embedding,情景特征的embedding及其互動的所有引數,最后我們使用LeakyRelu作為激活函式,使用softmax層來預測每個候選商品的概率,
TxT由Sequence Transformer和Context Transformer組成,可以使用Analytics Zoo中的API直接構建,如下:
from zoo.models.recommendation import TxT net = TxT(num_items, context_dims, item_embed=100, context_embed=100, item_hidden_size=256, item_max_length=8, item_num_heads=4, item_num_layers=2, item_transformer_dropout=0.0, item_pooling_dropout=0.1, context_hidden_size=256, context_max_length=4, context_num_heads=2, context_num_layers=1, context_transformer_dropout=0.0, context_pooling_dropout=0.0, activation="leakyRelu", cross_size=100) net.hybridize(static_alloc=True, static_shape=True) output = net(sequence, valid_length, context)
端到端的系統架構
通常情況下,構建一個完整的推薦系統會建立兩個單獨的集群,一個集群用于大資料處理,另一個集群用于深度學習(例如,使用GPU集群),但這不僅會帶來跨集群資料傳輸的巨大開銷,而且還需要在生產環境中去管理獨立的系統和作業流,為了應對這些挑戰,我們在Analytics Zoo的RayOnSpark之上構建了我們的推薦系統,將Spark資料處理和使用Ray的分布式MXNet訓練集成到一個統一的流水線中,直接運行在資料存盤的集群上,
圖2展示了我們系統的總體架構,Spark的程式中,在Driver節點上會創建一個SparkContext物件去負責啟動多個Spark Executor來運行Spark任務, RayOnSpark會在Spark Driver上另外創建一個RayContext物件,去自動把Ray行程和Spark Executor一起啟動,并在每個Spark Executor里創建一個RayManager來管理Ray行程(例如,在Ray程式退出時自動關閉行程),
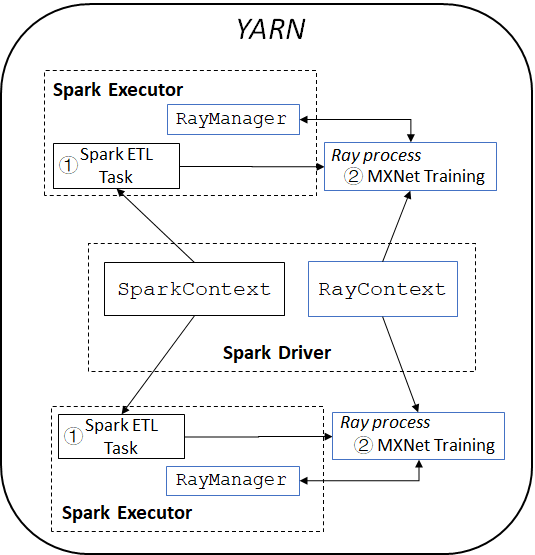
圖 2: 基于RayOnSpark的推薦系統流水線架構
在我們的推薦系統中,我們首先啟動Spark任務去讀取存盤在分布式檔案系統上的餐廳交易資料,然后使用Spark對這些資料進行資料清理,ETL和預處理, Spark任務完成后,我們將處理后在記憶體中的Spark RDD通過Plasma直接輸入給Ray進行分布式訓練,
參考RaySGD的設計,我們實作了MXNet Estimator,它提供了一個輕量級的wrapper,可以在Ray上自動地部署分布式MXNet訓練, MXNet worker和parameter server都是用Ray actor實作和運行的,它們之間通過MXNet提供的分布式key-value store來相互通信,每個MXNet worker從Plasma中拿取本地節點上的部分資料來訓練模型,通過這種方式,用戶就可以使用下面簡單的scikit-learn風格的API,通過Ray無縫地將MXNet的模型訓練代碼從單個節點擴展到生產集群:
from zoo.orca.learn.mxnet import Estimator mxnet_estimator = Estimator(train_config, model, loss, metrics, num_workers, num_servers) mxnet_estimator.fit(train_rdd, validation_rdd, epochs, batch_size)
這種統一的設計架構將基于Spark的資料處理和基于Ray的分布式MXNet訓練集成到一個端到端的、基于記憶體的流水線中,能夠在存盤大資料的同一集群上直接運行,因此,構建整個推薦系統的流水線我們只需要維護一個集群,避免了不同集群之間額外的資料傳輸,也不需要額外的集群維護成本,這樣充分地利用了現有的集群資源,并且顯著地提升了整個系統的端到端性能,
模型評估
我們使用了過去12個月中漢堡王客戶的交易記錄進行了離線的實驗,其中前11個月的歷史資料用于訓練,最后一個月的資料用于驗證,我們用這些資料對模型進行訓練,讓模型能夠預測客戶下一個最有可能購買的產品,從圖表1中,我們可以看到我們的TxT優于其他用于推薦的基準模型(包括Association Rule Learning和GRU4Rec),相比GRU4Rec,我們可以看到,TxT能利用各種情景特征大大提高了預測的準確性(Top1和Top3準確率分別提升了約5.65%和7.32%),
|
|
選用的模型 |
Top1準確率 |
Top3準確率 |
|
1 |
Association Rule Learning |
20.14% |
35.04% |
|
2 |
GRU4Rec |
30.65% |
45.72% |
|
3 |
Transformer Cross Transformer (TxT) |
35.03% |
53.04% |
圖表 1: 不同推薦模型的離線訓練結果
為了評估我們的模型在實際生產環境中的有效性,我們在Burger King的手機客戶端上同時對比了TxT模型和Google Recommendation AI*提供的推薦模型,我們從推薦轉化率和附加銷售額的提升這兩個方面評估了不同模型的在線效果,在生產環境做了4周的A/B測驗,我們隨機選擇了20%的用戶作為對照組,為他們提供之前在生產環境使用的基于規則(Rule Based)的推薦系統,如圖表2,與對照組相比,TxT將下單頁面上的推薦轉化率提高了264%,附加銷售額提高了137%,與運行Google Recommendation AI的測驗組相比,TxT進一步提高了100%的轉換收益和73%的附加銷售收益,
|
推薦系統 |
轉化率提升 |
附加銷售額提升 |
|
Rule Based Recommendation (Control) |
0% |
0% |
|
Google Recommendation AI |
+164% |
+64% |
|
Transformer Cross Transformer (TxT) |
+264% |
+137% |
圖表2: 不同推薦解決方案的在線結果
結論
這篇文章描述了我們如何在Burger King的生產環境中構建一個端到端的推薦系統,我們通過Transformer Cross Transformer(TxT)模型成功地捕獲了用戶訂單行為和復雜的情景特征為用戶做合適的推薦,并且使用RayOnSpark實作了統一的資料處理(使用Spark)和深度學習模型訓練(使用Ray)的流水線,TxT模型和RayOnSpark均已在Analytics Zoo專案中開源,
*其他名稱和品牌可能是其他所有者的財產
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/82497.html
標籤:其他
上一篇:spaCy教程學習