目錄
- 寫在前面
- Cross-Entropy Loss (softmax loss)
- Contrastive Loss - CVPR2006
- Triplet Loss - CVPR2015
- Center Loss - ECCV2016
- L-Softmax Loss - ICML2016
- A-Softmax Loss - CVPR2017
- AM-Softmax Loss-CVPR2018
- ArcFace Loss - CVPR2019
- 歐氏距離or角度距離與歸一化
- 參考
博客:博客園 | CSDN | blog
寫在前面
Closed-set 和 Open-set 人臉識別的對比如下,

兩張人臉影像,分別提取特征,通過計算特征向量間的距離(相似度)來判斷它們是否來自同一個人,選擇與問題背景相契合的度量方式很重要,人臉識別中一般有兩種,歐氏距離和余弦距離(角度距離),
訓練階段和測驗階段采用的度量方式要一致,如果想在測驗階段使用歐氏距離,自然在訓練階段就要基于歐氏距離來構造損失進行優化,
實際上,不同度量方式間存在著一定的內在聯系,
- 歐氏距離與向量的模和角度都有關,模固定,角度越大歐氏距離也越大,角度固定,模同比增大歐式距離也增大,模分別增大情況會比較復雜;
- 余弦距離和角度距離有單調關系(負相關),但兩者分布的“密度”不同,觀察余弦函式曲線可知,在角度從0向\(\pi\)勻速(線性)前進時,余弦值在0和\(\pi\)附近緩慢變化,在\(\frac{\pi}{2}\)附近近似線性變化
- 當向量模長歸一化后,歐氏距離和余弦距離有單調關系,所以,在預測階段,歸一化后的特征選取哪種度量進行判別均可
可對不同損失函式按度量方式進行劃分,
- 歐氏距離:Contrastive Loss,Triplet Loss,Center Loss……
- 余弦距離(角度距離):Large-Margin Softmax Loss,Angular-Softmax Loss,Large Margin Cosine Loss,Additive Angular Margin Loss……
先從最基本的Softmax Loss開始,
Cross-Entropy Loss (softmax loss)
交叉熵損失,也稱為softmax損失,是深度學習中應用最廣泛的損失函式之一,
\[\mathcal{L}_{\mathrm{s}}=-\frac{1}{N_b} \sum_{i=1}^{N_b} \log \frac{e^{W_{y_{i}}^{T} x_{i}+b_{y_{i}}}}{\sum_{j=1}^{n} e^{W_{j}^{T} x_{i}+b_{j}}} \]
其中,
- \(n\)個類別,\(N_b\)為batch size
- \(x_{i} \in \mathbb{R}^{d}\),第\(i\)個樣本的特征,特征有\(d\)維,屬于\(y_i\)類
- \(W \in \mathbb{R}^{d \times n}\)為權重矩陣,\(W_j\)表示\(W\)的第\(j\)列,\(b_{j} \in \mathbb{R}^{n}\)為bias
特征\(x\)經全連接層的權重矩陣\(W\)得到與類別數相同的\(n\)個\((-\infty, +\infty)\)實數,相對越大的實數代表越像某一個類別,Softmax的作用是將\((-\infty, +\infty)\)的\(n\)個實數通過指數映射到\((0, +\infty)\),然后歸一化,使和為1,以獲得某種概率解釋,
指數操作會將映射前的小差異指數放大,Softmax Loss希望label對應的項越大越好,但因為指數操作的存在,只需要映射前差異足夠大即可,并不需要使出“全力”,
在人臉識別中,可通過對人臉分類來驅動模型學習人臉的特征表示,但該損失追求的是類別的可分性,并沒有顯式最優化類間和類內距離,這啟發了其他損失函式的出現,
Contrastive Loss - CVPR2006
Contrastive Loss由LeCun在《Dimensionality Reduction by Learning an Invariant Mapping》CVPR2006中提出,起初是希望降維后的樣本保持原有距離關系,相似的仍相似,不相似的仍不相似,如下所示,
\[\begin{array}{c} L\left(W, Y, \vec{X}_{1}, \vec{X}_{2}\right)= (1-Y) \frac{1}{2}\left(D_{W}\right)^{2}+(Y) \frac{1}{2}\left\{\max \left(0, m-D_{W}\right)\right\}^{2} \end{array} \]
其中,\(\vec{X}_{1}\)和\(\vec{X}_{2}\)為樣本對,\(Y=\{0, 1\}\)指示樣本對是否相似,\(Y=0\)相似,\(Y=1\)不相似,\(D_W\)為樣本對特征間的歐氏距離,\(W\)為待學習引數,相當于歐氏距離損失+Hinge損失
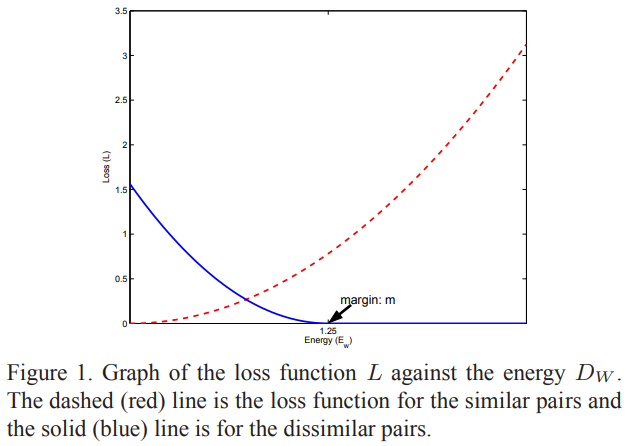
類內希望距離越小越好,類間希望越大越好(大于margin),這恰與人臉識別特征學習的目的相一致,Contrastive Loss在DeepID2中得以使用,作為Verification Loss,與Softmax Loss形式的Identification Loss構成聯合損失,如下所示,
\[\operatorname{Ident}\left(f, t, \theta_{i d}\right)=-\sum_{i=1}^{n}-p_{i} \log \hat{p}_{i}=-\log \hat{p}_{t} \\ \operatorname{Verif}\left(f_{i}, f_{j}, y_{i j}, \theta_{v e}\right)=\left\{\begin{array}{ll} \frac{1}{2}\left\|f_{i}-f_{j}\right\|_{2}^{2} & \text { if } y_{i j}=1 \\ \frac{1}{2} \max \left(0, m-\left\|f_{i}-f_{j}\right\|_{2}\right)^{2} & \text { if } y_{i j}=-1 \end{array}\right. \]
這種Softmax Loss + 其他損失 構成的聯合損失比較常見,通過引入Softmax Loss可以讓訓練更穩定,更容易收斂,
Triplet Loss - CVPR2015
Contrastive Loss的輸入是一對樣本,
Triplet Loss的輸入是3個樣本,1對正樣本(同一個人),1對負樣本(不同人),希望拉近正樣本間的距離,拉開負樣本間的距離,Triplet Loss出自《FaceNet: A Unified Embedding for Face Recognition and Clustering》,
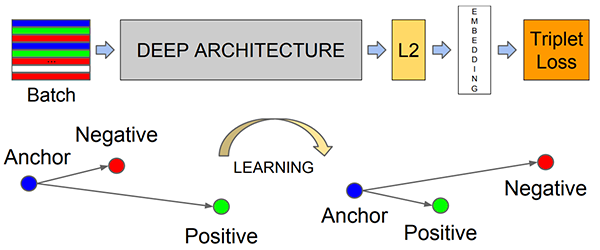
損失函式如下,
\[\mathcal{L}_t = \sum_{i}^{N}\left[\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{p}\right)\right\|_{2}^{2}-\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{n}\right)\right\|_{2}^{2}+\alpha\right]_{+} \]
該損失希望在拉近正樣本、拉開負樣本的同時,有一個margin,
\[\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{p}\right)\right\|_{2}^{2}+\alpha<\left\|f\left(x_{i}^{a}\right)-f\left(x_{i}^{n}\right)\right\|_{2}^{2} \]
Softmax Loss最后的全連接層引數量與人數成正比,在大規模資料集上,對顯存提出了挑戰,
Contrastive Loss和Triplet Loss的輸入為pair和triplet,方便在大資料集上訓練,但pair和triplet挑選有難度,訓練不穩定難收斂,可與Softmax Loss搭配使用,或構成聯合損失,或一前一后,用Softmax Loss先“熱身”,
Center Loss - ECCV2016
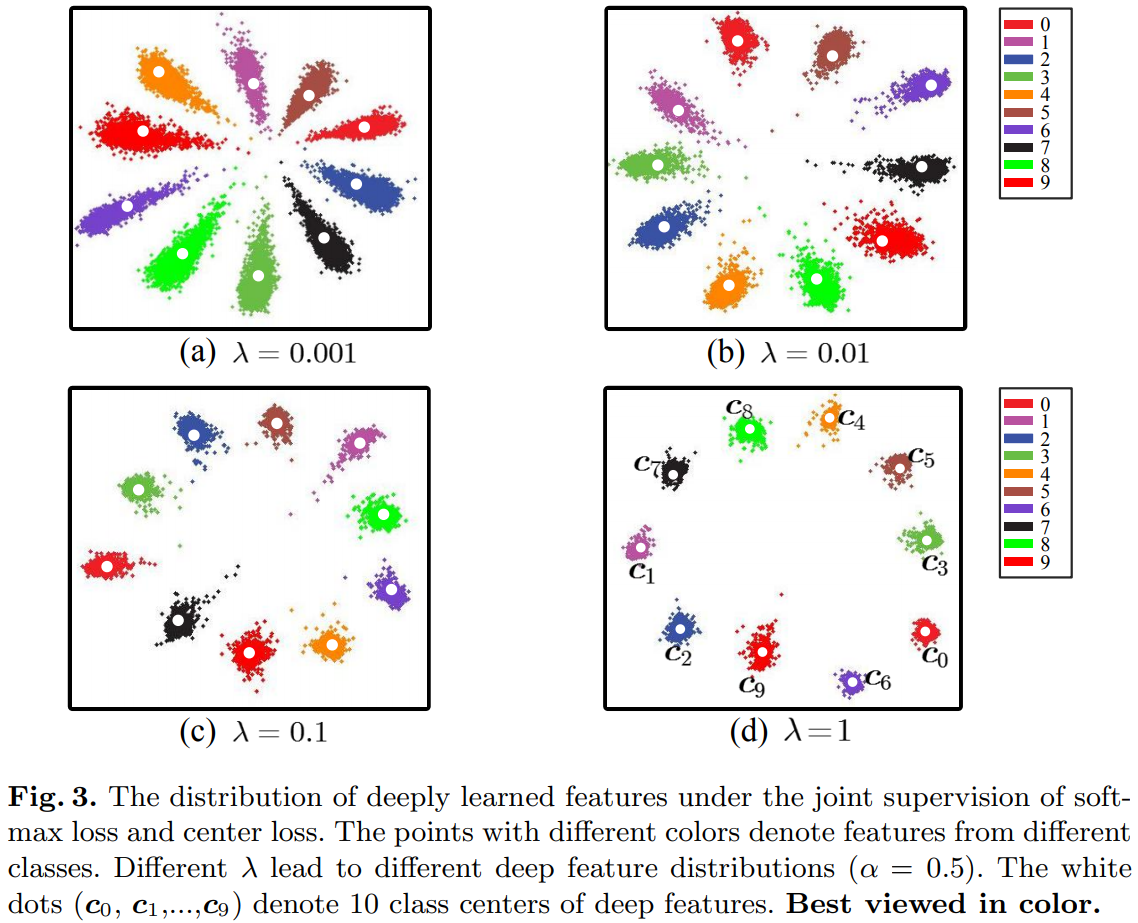
因為人臉表情和角度的變化,同一個人的類內距離甚至可能大于不同人的類間距離,Center Loss的出發點在于,不僅希望類間可分,還希望類內緊湊,前者通過Softmax loss實作,后者通過Center Loss實作,如下所示,為每個類別分配一個可學習的類中心,計算每個樣本到各自類中心的距離,距離之和越小表示類內越緊湊,
\[\mathcal{L}_{c e}=\frac{1}{2} \sum_{i=1}^{N}\left\|x_{i}-c_{y_{i}}\right\|_{2}^{2} \]
聯合損失如下,通過超引數\(\lambda\)來平衡兩個損失,并給兩個損失分配不同的學習率,
\[\begin{aligned} L_{c} &=L_{s}+\lambda L_{c e} \\ &=-\sum_{i=1}^{N_{b}} \log \frac{e^{W_{y_{i}}^{T} x_{i}+b_{y_{i}}}}{\sum_{j=1}^{n} e^{W_{j}^{T} x_{i}+b_{j}}}+\frac{\lambda}{2} \sum_{i=1}^{N_b}\left\|x_{i}-c_{y_{i}}\right\|_{2}^{2} \end{aligned} \]

希望達成的效果如下,
以上損失在歐氏距離上優化,下面介紹在余弦距離上優化的損失函式,
L-Softmax Loss - ICML2016
L-Softmax 即 large-margin softmax,出自《Large-Margin Softmax Loss for Convolutional Neural Networks》,
若忽略bias,FC+softmax+cross entropy可寫成如下形式,
\[L_{i}=-\log \left(\frac{e^{\left\|\boldsymbol{W}_{y_{i}}\right\|\left\|\boldsymbol{x}_{i}\right\| \cos \left(\theta_{y_{i}}\right)}}{\sum_{j} e^{\left\|\boldsymbol{W}_{j}\right\|\left\|\boldsymbol{x}_{i}\right\| \cos \left(\theta_{j}\right)}}\right) \]
可將\(\boldsymbol{W}_{j}\)視為第\(j\)類的類中心向量,對\(x_i\),希望\(\left\|\boldsymbol{W}_{y_{i}}\right\|\left\|\boldsymbol{x}_{i}\right\| \cos \left(\theta_{y_{i}}\right)\)相比\(\left\|\boldsymbol{W}_{j}\right\|\left\|\boldsymbol{x}_{i}\right\| \cos \left(\theta_{j}\right), j \neq y_i\)越大越好,有兩個影響因素,
- \(\boldsymbol{W}\)每一列的模
- \(\boldsymbol{x}_i\)與\(\boldsymbol{W}_j\)的夾角
L-Softmax主要關注在第2個因素 夾角上,相比Softmax,希望\(\boldsymbol{x}_i\)與\(\boldsymbol{W}_{y_i}\)靠得更近,于是對\(\cos \left(\theta_{y_{i}}\right)\)施加了更強的約束,對角度\(\theta_{y_i}\)乘上個因子\(m\),如果想獲得與Softmax相同的內積值,需要\(\theta_{y_i}\)更小,
\[L_{i}=-\log \left(\frac{e^{\left\|\boldsymbol{W}_{y_{i}}\right\|\left\|\boldsymbol{x}_{i}\right\| \psi\left(\theta_{y_{i}}\right)}}{e^{\left\|\boldsymbol{W}_{y_{i}}\right\|\left\|\boldsymbol{x}_{i}\right\| \psi\left(\theta_{y_{i}}\right)}+\sum_{j \neq y_{i}} e^{\left\|\boldsymbol{W}_{j}\right\|\left\|\boldsymbol{x}_{i}\right\| \cos \left(\theta_{j}\right)}}\right) \]
為此,需要構造\(\psi(\theta)\),需滿足如下條件
- \(\psi(\theta) < cos(\theta)\)
- 單調遞減
文中構造的\(\psi(\theta)\)如下,通過\(m\)調整margin大小
\[\psi(\theta)=(-1)^{k} \cos (m \theta)-2 k, \quad \theta \in\left[\frac{k \pi}{m}, \frac{(k+1) \pi}{m}\right], k \in [0, m-1] \]
當\(m=2\)時,如下所示,

二分類情況下,結合解釋如下,
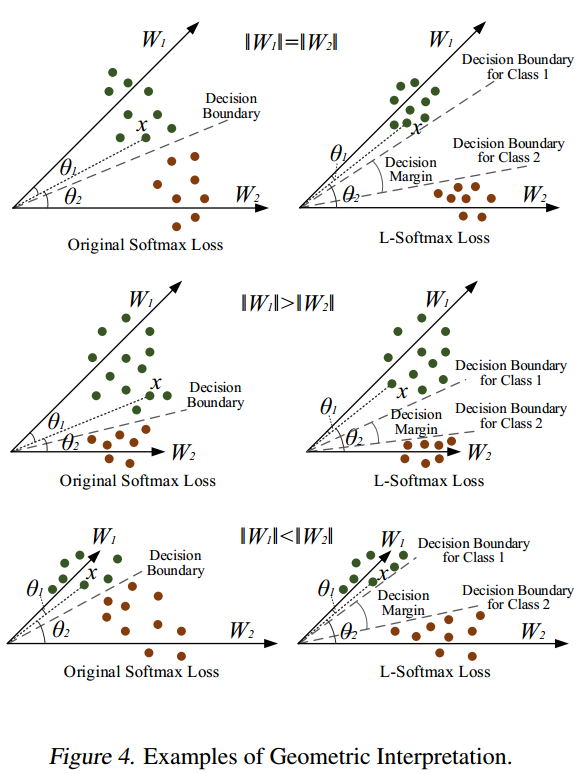
為了梯度計算和反向傳播,將\(\cos(\theta)\)替換為僅包含\(W\)和\(w_i\)的運算式\(\frac{\boldsymbol{W}_{j}^{T} \boldsymbol{x}_{i}}{\left\|\boldsymbol{W}_{j}\right\|\left\|\boldsymbol{x}_{i}\right\|}\),通過倍角公式計算\(\cos(m \theta)\),
\[\begin{aligned} \cos \left(m \theta_{y_{i}}\right) &=C_{m}^{0} \cos ^{m}\left(\theta_{y_{i}}\right)-C_{m}^{2} \cos ^{m-2}\left(\theta_{y_{i}}\right)\left(1-\cos ^{2}\left(\theta_{y_{i}}\right)\right) \\ &+C_{m}^{4} \cos ^{m-4}\left(\theta_{y_{i}}\right)\left(1-\cos ^{2}\left(\theta_{y_{i}}\right)\right)^{2}+\cdots \\ &(-1)^{n} C_{m}^{2 n} \cos ^{m-2 n}\left(\theta_{y_{i}}\right)\left(1-\cos ^{2}\left(\theta_{y_{i}}\right)\right)^{n}+\cdots \end{aligned} \]
同時,為了便于訓練,定義超引數\(\lambda\),將\(\left\|\boldsymbol{W}_{y_{i}}\right\|\left\|\boldsymbol{x}_{i}\right\| \psi\left(\theta_{y_{i}}\right)\)替換為\(f_{y_i}\),
\[f_{y_{i}}=\frac{\lambda\left\|\boldsymbol{W}_{y_{i}}\right\|\left\|\boldsymbol{x}_{i}\right\| \cos \left(\theta_{y_{i}}\right)+\left\|\boldsymbol{W}_{y_{i}}\right\|\left\|\boldsymbol{x}_{i}\right\| \psi\left(\theta_{y_{i}}\right)}{1+\lambda} \]
訓練時,從較大的\(\lambda\)開始,然后逐漸減小,近似于用Softmax“熱身”,
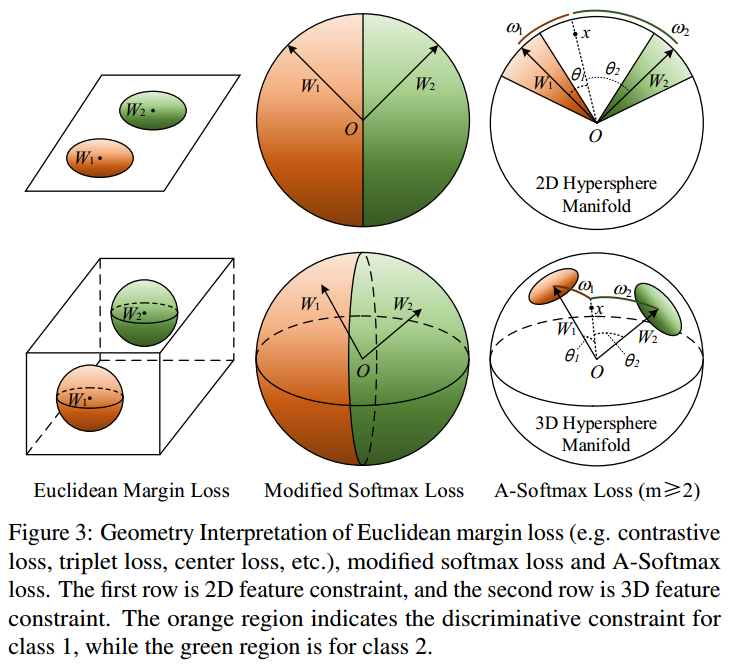
A-Softmax Loss - CVPR2017
A-Softmax即Angular-Softmax,出自《SphereFace: Deep Hypersphere Embedding for Face Recognition》,
L-Softmax中,在對\(x_i\)歸類時,會同時考慮類中心向量的模和夾角,
A-Softmax的最大差異在于對每個類中心向量進行歸一化,即令\(||W_j|| = 1\),同時令bias為0,在分類時只考慮\(x_i\)和\(W_j\)的夾角,并引入和L-Softmax相同的margin,如下所示,
\[\mathcal{L}_{\mathrm{AS}}=-\frac{1}{N} \sum_{i=1}^{N} \log \left(\frac{e^{\left\|\boldsymbol{x}_{i}\right\| \psi\left(\theta_{y_{i}, i}\right)}}{e^{\left\|\boldsymbol{x}_{i}\right\| \psi\left(\theta_{y_{i}, i}\right)}+\sum_{j \neq y_{i}} e^{\left\|\boldsymbol{x}_{i}\right\| \cos \left(\theta_{j, i}\right)}}\right) \\ \psi(\theta_{y_i, i})=(-1)^{k} \cos (m \theta_{y_i, i})-2 k, \quad \theta_{y_i, i} \in\left[\frac{k \pi}{m}, \frac{(k+1) \pi}{m}\right], k \in [0, m-1] \]
當\(m=1\)時,即不引入margin時,稱之為 modified softmax loss,
Softmax Loss、Modified Softmax Loss和A-Softmax Loss,三者的決策面如下,
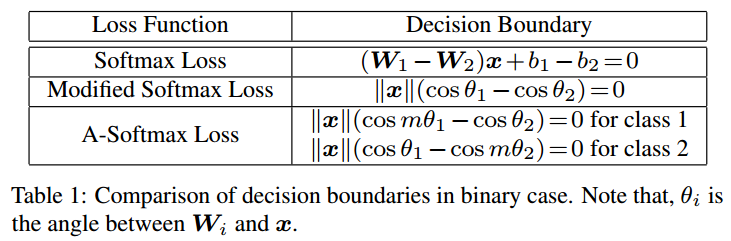
可視化如下,
AM-Softmax Loss-CVPR2018
AM-Softmax即Additive Margin Softmax,出自論文《Additive Margin Softmax for Face Verification》,同CosFace 《CosFace: Large Margin Cosine Loss for Deep Face Recognition》,CosFace中損失名為LMCL(Large Margin Cosine Loss),
與A-Softmax相比,有2點變化,
- 對\(x_i\)也做歸一化,同時保留對\(W\)每一列的歸一化以及bias為0
- 將\(\cos(m \theta)\)變成\(s \cdot (\cos \theta - m)\)
\[\mathcal{L}_{\mathrm{AM}}=-\frac{1}{N} \sum_{i=1}^{N} \log \frac{e^{s \cdot\left(\cos \theta_{y_{i}}-m\right)}}{e^{s \cdot\left(\cos \theta_{y_{i}}-m\right)}+\sum_{j=1, j \neq y_{i}}^{c} e^{s \cdot \cos \theta_{j}}} \]
相比Softmax,希望獲得更大的類間距離和更小類內距離,如果采用的是余弦距離,意味著,要想獲得與Softmax相同的\(y_i\)對應的分量,需要更小的夾角\(\theta\),為此需要構建\(\psi(\theta)\),如前所述,需要
- \(\psi(\theta) < cos(\theta)\)
- 單調遞減
前面構建的\(\psi(\theta)\),始于\(\cos(m \theta)\),\(m\)與\(\theta\)是乘的關系,這里令\(\varphi(\theta)= s(\cos (\theta)-m)\),
-
\(\cos(\theta) - m\):\(m\)變乘法為加法,\(\cos(m\theta)\)將margin作用在角度上,\(\cos(\theta) - m\)直接作用在余弦距離上,前者的問題在于對類中心向量夾角較小的情況懲罰較小,夾角小則margin會相對更小,同時計算復雜,后者可以看成是Hard Margin Softmax,希望在保證類間“硬”間距的情況下學習特征映射,

-
\(s\):將\(x_i\)也歸一化后,相當于將特征嵌入到單位超球上,表征空間有限,特征和權重歸一化后\(\mid \boldsymbol{W}_{j}\|\| \boldsymbol{x}_{i} \| \cos \left(\theta_{ij}\right)=cos(\theta_{ij})\)的值域為\([-1, 1]\),即\(x_i\)到每個類中心向量的余弦距離,最大為1,最小為-1,Softmax 指數歸一化前,各類的分量差異過小,所以要乘個因子\(s\),將特征映射到半徑為\(s\)的超球上,放大表征空間,拉開各分量的差距,

ArcFace Loss - CVPR2019
ArcFace Loss 即 Additive Angular Margin Loss,出自《ArcFace: Additive Angular Margin Loss for Deep Face Recognition》,
AM-Softmax Loss將margin作用在余弦距離上,與之不同的是,ArcFace將margin作用在角度上,其損失函式如下,
\[\mathcal{L}_{\mathrm{AF}}=-\frac{1}{N} \sum_{i=1}^{N} \log \frac{e^{s \cdot\left(\cos \left(\theta_{y_{i}}+m\right)\right)}}{e^{s \cdot\left(\cos \left(\theta_{y_{i}}+m\right)\right)}+\sum_{j=1, j \neq y_{i}}^{n} e^{s \cdot \cos \theta_{j}}} \]
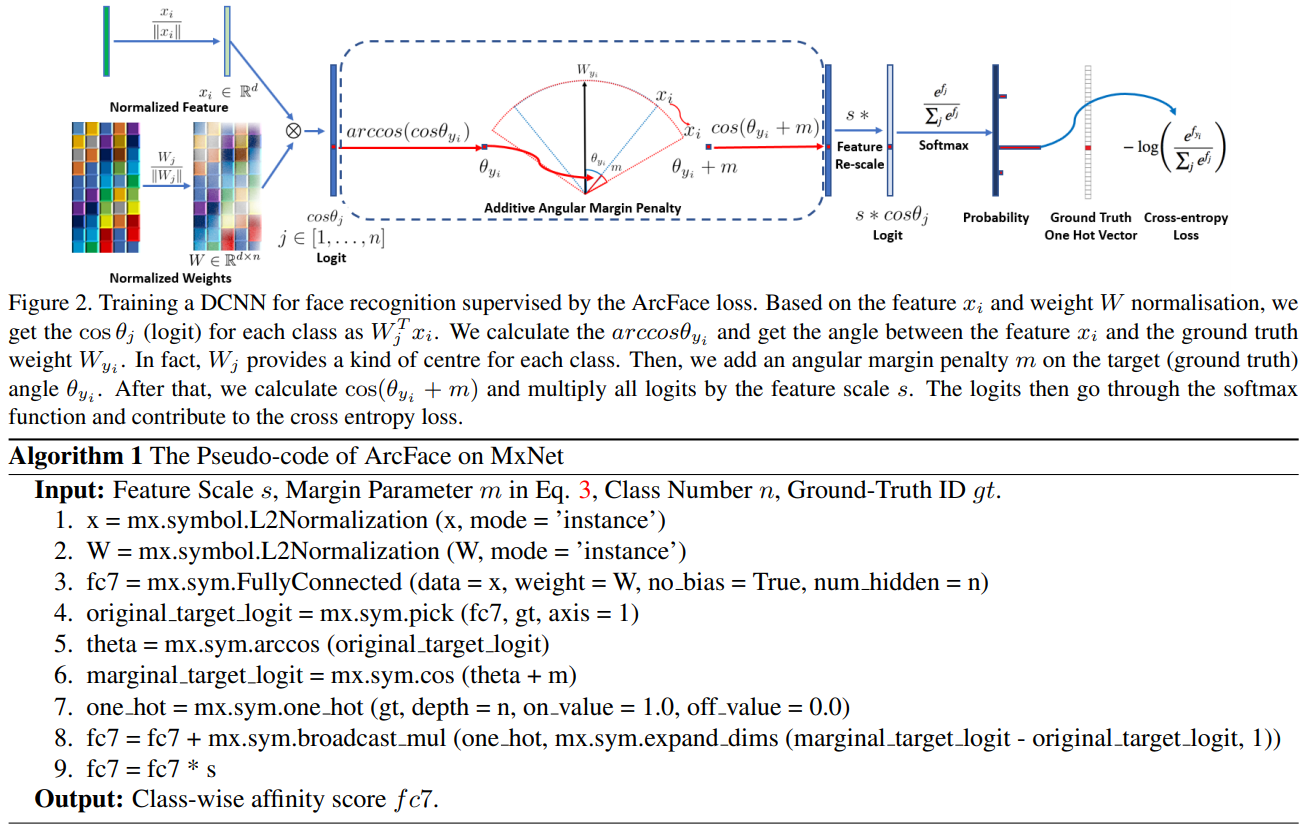
把margin是加在余弦距離(CosFace)還是加在角度(ArcFace)上,在《Additive Margin Softmax for Face Verification》中有這樣一段分析,

ArcFace中并沒有求取arccos,所以計算并不復雜,而是把margin加在了角度上,但優化的仍是余弦距離,
還有一點需要注意的是,無論margin是加在余弦距離上還是加在角度上,單純看示意圖,很容易看出減少了類內距離,那類間距離增加呢?
文中,給出了類內距離和類間距離的數學描述,如下:
\[L_{Intra}=\frac{1}{\pi N} \sum_{i=1}^{N} \theta_{y_{i}} \\ L_{Inter}=-\frac{1}{\pi N(n-1)} \sum_{i=1}^{N} \sum_{j=1, j \neq y_{i}}^{n} \arccos \left(W_{y_{i}}^{T} W_{j}\right) \]
\(W\)是待學習的引數,特征\(x_i\)也是通過前面層的權重學習得到,在訓練程序中\(x_i\)和\(W\)都會發生變化,都會被梯度驅使著向Loss減小的方向移動,margin的引入有意壓低了類標簽對應分量的值,去盡量“壓榨”模型的潛力,在softmax中原本可以收斂的位置還需要繼續下降,下降可以通過提高類標簽對應分量的值,也可以通過降低其他分量的值,所以,\(x_i\)在向\(W_{y_i}\)靠近的同時,\(W_j, j\neq y_i\)也可能在向遠離\(x_i\)的方向移動,最終達成的效果就可能是\(x_i\)盡可能地靠近\(W_{y_i}\),而\(W_j, j\neq y_i\)遠離了\(W_{y_i}\),
歐氏距離or角度距離與歸一化
這里,再討論下為什么對\(W\)和\(x\)的模進行歸一化,主觀思考偏多,未經驗證,
在文章為什么要做特征歸一化/標準化?中,我們提到,
歸一化/標準化的目的是為了獲得某種“無關性”——偏置無關、尺度無關、長度無關……當歸一化/標準化方法背后的物理意義和幾何含義與當前問題的需要相契合時,其對解決該問題就有正向作用,反之,就會起反作用,
特征\(x\)與\(W\)每個類中心向量內積的結果,取決于\(x\)的模、\(W_j\)的模以及它們的夾角,模的大小和夾角的大小都將影響內積結果的大小,
-
對\(W_j\)歸一化:如果訓練集存在較嚴重的類別不均衡,網路將傾向于把輸入影像劃分到圖片數量多的類別,這種傾向將反映在類中心向量的模上,即圖片數量多的類別其類中心向量的模將偏大,這一點論文One-shot Face Recognition by Promoting Underrepresented Classes中有實驗驗證,所以,對\(W_j\)的模歸一化相當于強迫網路同等看待每一個類別,相當于把同等看待每一個人的先驗做進網路,來緩解類別不均衡問題,
-
對\(x\)歸一化:對某一個具體的\(x_i\),其與每個類中心的內積 為 \(x_i \cdot W_j = |x_i||W_j|\cos \theta_{ij} = |x_i|\cos \theta_{ij}\),因為每個類別的內積結果都含\(x_i\)的模,\(x_i\)的模是否歸一化似乎并不影響內積結果間的大小關系,但會影響損失的大小,比如內積結果分別為\([4,1,1,1]\),模同時放大1倍,變成\([8,2,2,2]\),經過Softmax的指數歸一化后,后者的損失更小,在卷積神經網路之卷積計算、作用與思想中,我們知道模式蘊含在卷積核的權重當中,特征代表著與某種模式的相似程度,越相似回應越大,什么樣的輸入影像容易得到模小的特征,首先是數值尺度較小的輸入影像,這點可以通過對輸入影像做歸一化解決(如果輸入影像的歸一化不夠,對特征進行歸一化可能可以緩解這個問題),然后是那些模糊的、大角度的、有遮擋的人臉影像其特征的模會較小,這些圖在訓練集中相當于困難樣本,如果他們的數量不多,就可能會被簡單樣本淹沒掉,從這個角度看,對\(x\)進行歸一化,可能可以讓網路相對更關注到這些困難樣本,去找到更細節的特征,專注在角度上進行判別,進一步壓榨網路的潛能,有點Focal Loss思想的感覺,
網路會利用它可能利用上的一切手段來降低損失,有些手段可能并不是你所期望的,此時,通過調整資料、融入先驗、添加正則等方式抑制那些你不希望網路采取的手段,修正網路進化的方式,以此讓網路朝著你期望的方向成長,
以上,
參考
- A Performance Comparison of Loss Functions for Deep Face Recognition
- InsightFace: 2D and 3D Face Analysis Project
- 人臉識別的LOSS(上)
- 人臉識別的LOSS(下)
- 深度挖坑:從資料角度看人臉識別中Feature Normalization,Weight Normalization以及Triplet的作用
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/83551.html
標籤:其他
上一篇:5個步驟實作目標檢測