一. 導論
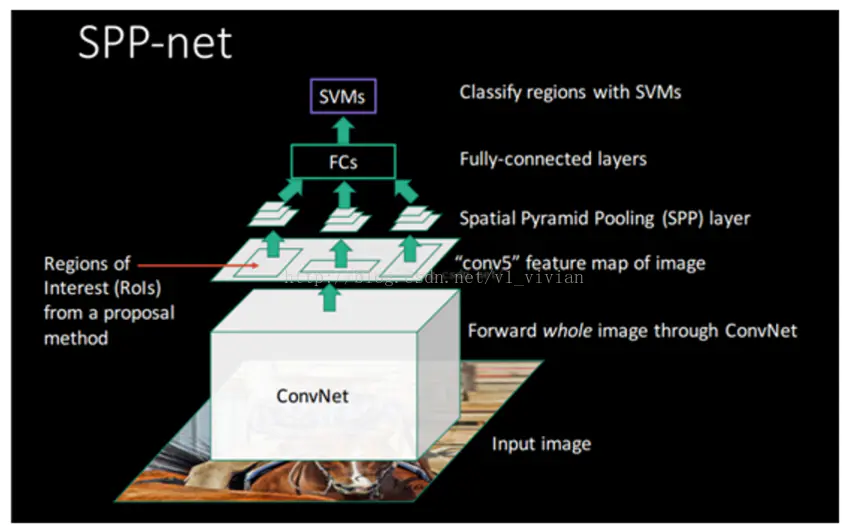
SPP-Net是何凱明在基于R-CNN的基礎上提出來的目標檢測模型,使用SPP-Net可以大幅度提升目標檢測的速度,檢測同樣一張圖片當中的所有目標,SPP-Net所花費的時間僅僅是RCNN的百分之一,而且檢測的準確率甚至會更高,那么SPP-Net是怎么設計的呢?我們要想理解SPP-Net,先來回顧一下RCNN當中的知識吧,下圖為SPP-Net的結構:
二. RCNN
rcnn進行目標檢測的框架如下:
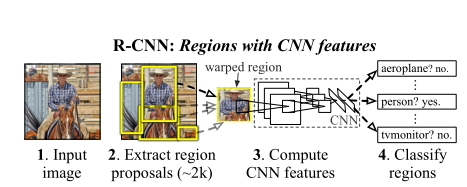
因此RCNN的步驟如下:
1.將影像輸入計算機當中
2.利用selective search演算法找到圖片當中屬于同一個物體的區域,并使用Bounding Box圈起來,這個演算法不屬于深度學習的演算法,而是一種傳統演算法,這個演算法不能夠在GPU上運行,只能在CPU上運行,因此相比于SPP-Net具有一定的局限性,它是根據影像當中的各個部位的顏色,輪廓,紋理等將影像當中的事物進行分類,一共篩選出1-2k個候選區域,用region proposal來表示,
3. 將得到的候選區域全部進行剪裁或者縮放將其變為統一的大小,這樣才可以使用影像分類神經網路(AlexNet/Google InceptionNet/VGG)對每一個候選區域進行影像識別,因此這一步我們需要進行1-2k次卷積運算,對于時間而言非常不劃算,
4.最后使用SVM分類器將候選區域當中的所有圖片通過全連接層進行分類,查看看是否為我們所需要檢測的目標,并且輸出其名稱,如:人,飛機,電視機等等,同時進行bounding box的回歸,這樣可以使得預測的bounding box的大小和位置更加準確,在論文當中bounding-box的回歸公式如下:

最后使用SVM分類器而沒有使用softmax分類器的原因是在RCNN當中使用SVM后分類結果的準確率會更高(根據實驗得知),論文當中的說明如下:

mAP的大小表示的是目標檢測的準確率,是目標檢測領域中一種重要的評價指標,整體而言R-CNN的實作還是頗為簡單的,也很容易被人們所想到,這個演算法在當時也是非常優越的,使用selective search的方法代替了之前做目標檢測所使用的滑動視窗法來生成候選區域,不然的話使用滑動視窗法針對每個影像進行卷積運算我們可能不僅僅要進行1-2K次運算,最后運算的次數很可能是10k-50k次,這在時間上來說太不劃算了,而且使用滑動視窗法還可能滑動的視窗沒有框到目標,因此會丟失掉準確率,SVM分類最后的輸出是每個影像bounding box的形狀大小,位置以及每一個bounding box內影像分類的結果以及概率,
那么我們的SPP-Net在這之上做了哪些改進呢?
三. SPP-Net
SPP-Net發現在RCNN當中使用selective search的方法生成候選區域實在是太耗費時間了,因為所有生成的候選區域都要進行一次卷積運算來進行影像分類,那么我們能不能夠直接只計算一次卷積而非1-2k次卷積呢?因此在SPP-Net當中我們省略掉了生成候選區域這一步,直接將影像做一次卷積運算,并且在卷積神經網路CNN之后增加了影像空間金字塔池化(SSP-Spatial Pyramid Pooling)的結構,這樣就可以根據影像的特征將影像當中的目標區域進行分類,SPP-Net和RCNN的區別如下圖所示: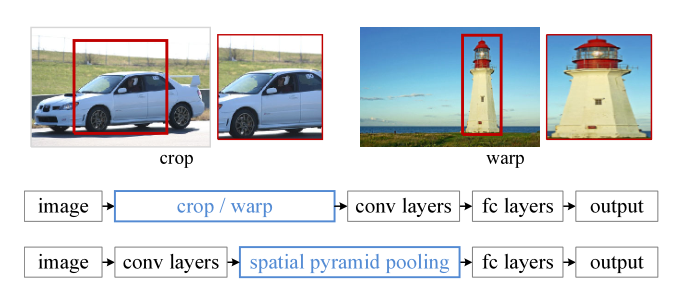
可以從上看出,影像輸入到網路中之后,RCNN將候選區域進行了剪裁和縮放,然后再把剪裁好的區域“喂”入到CNN當中,而spp-net則直接將整張圖片放入了卷積神經網路當中,然后使用spatial pytamid pooling(空間金字塔池化)提取卷積之后的特征,最后使用全連接神經網路連同最后的輸出和空間金字塔池化層,在整個spp-net當中最為重要的結構則是我們用紅色字體標注出的spatial pytamid pooling(空間金字塔池化層)了,那么整個結構是如何實作的呢?
四.空間金字塔池化結構
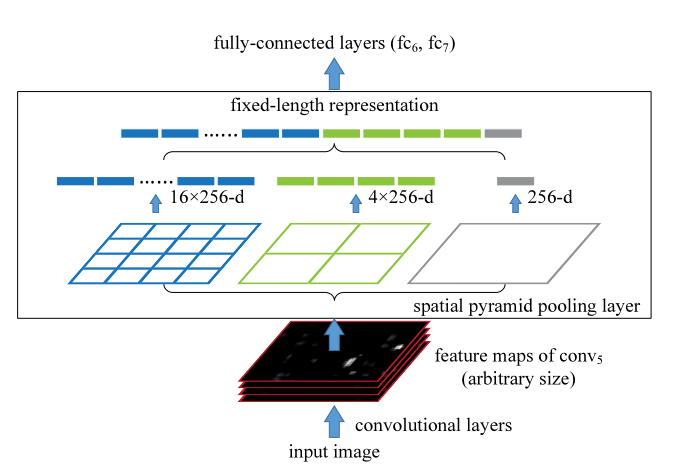
空間金字塔池化層的結構如上所示,Image經過一次卷積之后會得到256個特征圖,也就是上面圖中最下面的一連串黑色堆疊圖,這是整個卷積神經網路的第五層嗎,因此稱為conv5,然后我們使用SSP結構對這256個特征圖進行處理,將這256張特征圖分別進行1*1,2*2,4*4的最大池化,也就是分別選取這256個特征圖當中的最大值,然后最后的輸出也是256個每一層特征圖的最大值,比如我們做空間金字塔池化最右邊的那個1*1池化,計算機僅僅會選取這256個特征圖當中最大的值作為輸出的結果作為影像的語意特征,這也就是最大池化,2*2的最大池化同理,但我們會做完2*2的最大池化之后會得到4個數值,每一個數值都代表這影像某一區域的特征,因此最后我們會得到21(21=4*4+1*1+2*2)*256=5376個數值作為影像高度抽象的特征,之后將這5376個特征送入全連接神經網路(fc6和fc7,一共兩層全連接神經網路,這個完全看研究員自己的喜好來設定了,可以沒有,也可以多層),最后用SVM分類器輸出bounding box的x,y,w,h以及每一個bounding box的圖象分類的結果,小編在網上查看了很多教程都沒有把空間金字塔池化結構解釋清楚,也是自己想了很久認真研讀了論文好幾遍才明白,畢竟論文上這一點其實也沒講得多清楚,最后輸出的結果如下圖所示:

那么為什么我們可以作這樣的處理呢?我們來看看論文當中是怎么說的,下圖來自于spp-net的論文:

在圖的左邊,(a)代表了我們進行目標檢測的影像,(b)上面的那張圖是卷積神經網路的第175層輸出的結果,我們將其可視化了,下面的那張特征圖是卷積神經網路第55層的輸出結果,我們也將其可視化了,我們發現汽車的窗戶正好在第175層的conv layer發現了這個特征,并且高亮的了出來是白色,在影像上表示為這個區域的灰度是很大的(有0-255個數字,因此這個高亮的地方數值可能在200以上),這個時候第55層的特征圖發現了汽車的輪胎這一個特征,在特征圖當中也高亮了出來,這也是最后我們在金字塔池化層做最大池化的原因,因為最大池化就會將高亮的地方的特征提取出來,我們只提取影像當中具有物體的特征,從而忽略掉其他沒有無體的地方的特征,最后再全連接神經網路當中進行特征融合并歸類,就可以得到目標檢測的結果了!是不是很神奇呢?
終于寫完啦,如果覺得讀了小編的文章您有識訓的話,不要忘記了點擊下方的“推薦”哦!您的支持就是對小編創作最大的動力!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/83554.html
標籤:其他
上一篇:人臉識別損失函式疏理與分析