Dropout層在神經網路層當中是用來干嘛的呢?它是一種可以用于減少神經網路過擬合的結構,那么它具體是怎么實作的呢?
假設下圖是我們用來訓練的原始神經網路:
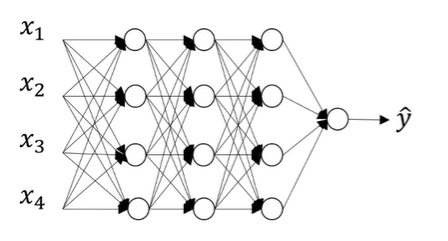
一共有四個輸入x_i,一個輸出y,Dropout則是在每一個batch的訓練當中隨機減掉一些神經元,而作為編程者,我們可以設定每一層dropout(將神經元去除的的多少)的概率,在設定之后,就可以得到第一個batch進行訓練的結果: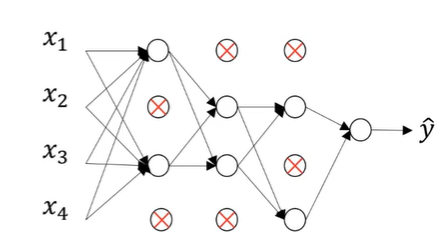
從上圖我們可以看到一些神經元之間斷開了連接,因此它們被dropout了!dropout顧名思義就是被拿掉的意思,正因為我們在神經網路當中拿掉了一些神經元,所以才叫做dropout層,
在進行第一個batch的訓練時,有以下步驟:
1.設定每一個神經網路層進行dropout的概率
2.根據相應的概率拿掉一部分的神經元,然后開始訓練,更新沒有被拿掉神經元以及權重的引數,將其保留
3.引數全部更新之后,又重新根據相應的概率拿掉一部分神經元,然后開始訓練,如果新用于訓練的神經元已經在第一次當中訓練過,那么我們繼續更新它的引數,而第二次被剪掉的神經元,同時第一次已經更新過引數的,我們保留它的權重,不做修改,直到第n次batch進行dropout時沒有將其洗掉,
備注:
這就是dropout層的思想了,為什么dropout能夠用于防止過擬合呢?因為約大的神經網路就越有可能產生過擬合,因此我們隨機洗掉一些神經元就可以防止其過擬合了,也就是讓我們擬合的結果沒那么準確,就如同機器學習里面的L1/L2正則化一樣的效果!
那么我們應該對什么樣的神經網路層進行dropout的操作呢?很顯然是神經元個數較多的層,因為神經元較多的層更容易讓整個神經網路進行預測的結果產生過擬合,假設有如下圖所示的一個dropou層:

由于隱藏層的第一層和第二層神經元個數較多,容易產生過擬合,因此我們將其加上dropout的結構,而后面神經元個數較少的地方就不用加了!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/83583.html
標籤:其他
上一篇:國內演算法比賽平臺匯總