AI博士筆記系列推薦:周志華《機器學習》手推筆記正式開源!可列印版本附pdf下載鏈接
本文為聯盟學習筆記
參與:王博kings,Sophia
本文涉及論文已打包,公眾號【計算機視覺聯盟】后臺回復“9079”獲取下載鏈接!
前言
計算機視覺是將影像和視頻轉換成機器可理解的信號的主題,利用這些信號,程式員可以基于這種高級理解來進一步控制機器的行為,在許多計算機視覺任務中,影像分類是最基本的任務之一,它不僅可以用于許多實際產品中,例如Google Photo的標簽和AI內容審核,而且還為許多更高級的視覺任務(例如物體檢測和視頻理解)打開了一扇門,自從深度學習的突破以來,由于該領域的快速變化,初學者經常發現它太笨拙,無法學習,與典型的軟體工程學科不同,沒有很多關于使用DCNN進行影像分類的書籍,而了解該領域的最佳方法是閱讀學術論文,但是要讀什么論文?我從哪說起呢?在本文中,我將介紹10篇最佳論文供初學者閱讀,通過這些論文,我們可以看到該領域是如何發展的,以及研究人員如何根據以前的研究成果提出新的想法,但是,即使您已經在此領域作業了一段時間,對您進行大范圍整理仍然很有幫助,
1998年:LeNet
梯度學習在于檔案識別中的應用
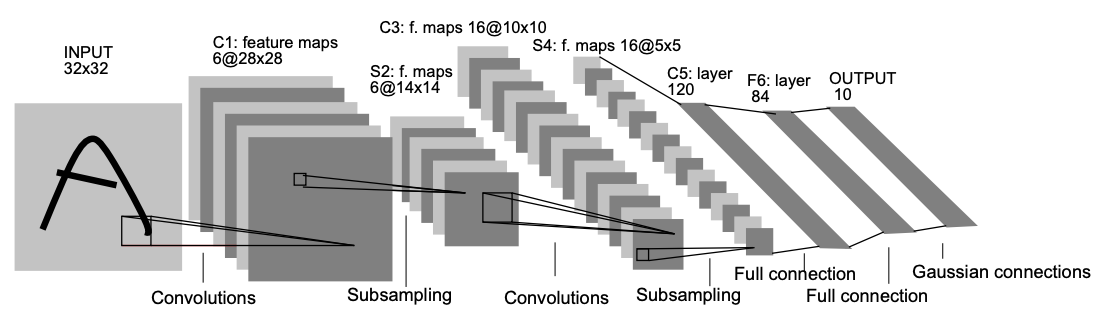
摘自“ 基于梯度的學習應用于檔案識別”
LeNet于1998年推出,為使用卷積神經網路進行未來影像分類研究奠定了基礎,許多經典的CNN技術(例如池化層,完全連接的層,填充和激活層)用于提取特征并進行分類,借助均方誤差損失功能和20個訓練周期,該網路在MNIST測驗集上可以達到99.05%的精度,即使經過20年,仍然有許多最先進的分類網路總體上遵循這種模式,
2012年:AlexNet
深度卷積神經網路的ImageNet分類
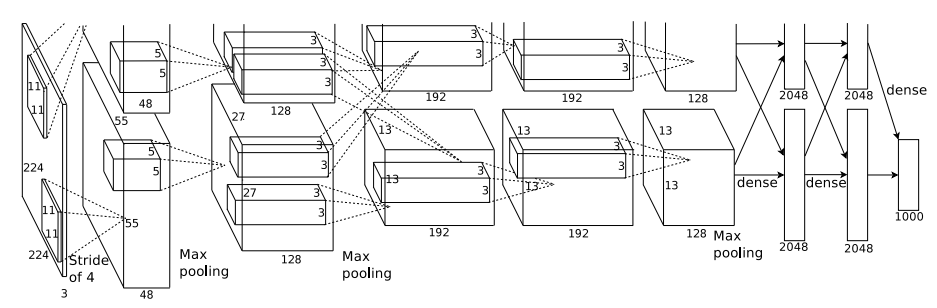
摘自“ 具有深度卷積神經網路的ImageNet分類”
盡管LeNet取得了不錯的成績并顯示了CNN的潛力,但由于計算能力和資料量有限,該領域的發展停滯了十年,看起來CNN只能解決一些簡單的任務,例如數字識別,但是對于更復雜的特征(如人臉和物體),帶有SVM分類器的HarrCascade或SIFT特征提取器是更可取的方法,
但是,在2012年ImageNet大規模視覺識別挑戰賽中,Alex Krizhevsky提出了基于CNN的解決方案來應對這一挑戰,并將ImageNet測驗裝置的top-5準確性從73.8%大幅提高到84.7%,他們的方法繼承了LeNet的多層CNN想法,但是大大增加了CNN的大小,從上圖可以看到,與LeNet的32x32相比,現在的輸入為224x224,與LeNet的6相比,許多卷積內核具有192個通道,盡管設計變化不大,但引數變化了數百次,但網路的捕獲和表示復雜特征的能力也提高了數百倍,為了進行大型模型訓練,Alex使用了兩個具有3GB RAM的GTX 580 GPU,這開創了GPU訓練的先河,同樣,使用ReLU非線性也有助于降低計算成本,
除了為網路帶來更多引數外,它還通過使用 Dropout層探討了大型網路帶來的過擬合問題 ,其區域回應歸一化方法此后并沒有獲得太大的普及,但是啟??發了其他重要的歸一化技術(例如BatchNorm)來解決梯度飽和問題,綜上所述,AlexNet定義了未來十年的實際分類網路框架: 卷積,ReLu非線性激活,MaxPooling和Dense層的組合,
2014年:VGG
超深度卷積網路用于大規模影像識別
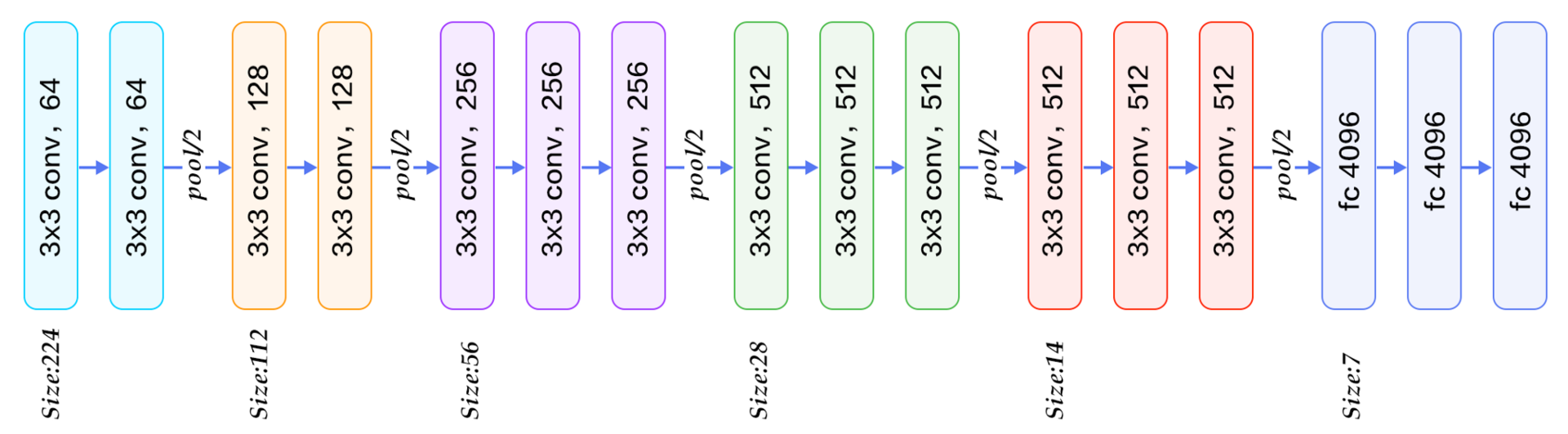
來自Quora“ https://www.quora.com/What-is-the-VGG-neural-network”
在使用CNN進行視覺識別方面取得了巨大成功,整個研究界都大吃一驚,所有人都開始研究為什么這種神經網路能夠如此出色地作業,例如,在2013年發表的“可視化和理解卷積網路”中,Matthew Zeiler討論了CNN如何獲取特征并可視化中間表示,突然之間,每個人都開始意識到CNN自2014年以來就是計算機視覺的未來,在所有直接關注者中,Visual Geometry Group的VGG網路是最吸引眼球的網路,在ImageNet測驗儀上,它的top-5準確度達到93.2%,top-1準確度達到了76.3%,
遵循AlexNet的設計,VGG網路有兩個主要更新: 1)VGG不僅使用了像AlexNet這樣的更廣泛的網路,而且使用了更深的網路,VGG-19具有19個卷積層,而AlexNet中只有5個,2)VGG還展示了一些小的3x3卷積濾波器可以代替AlexNet的單個7x7甚至11x11濾波器,在降低計算成本的同時實作更好的性能, 由于這種優雅的設計,VGG也成為了其他計算機視覺任務中許多開拓性網路的骨干網路,例如用于語意分割的FCN和用于物件檢測的Faster R-CNN,
隨著網路的深入,從多層反向傳播中梯度消失成為一個更大的問題,為了解決這個問題,VGG還討論了預訓練和權重初始化的重要性,這個問題限制了研究人員繼續添加更多的層,否則,網路將很難融合,但是兩年后,我們將為此找到更好的解決方案,
2014年:GoogLeNet
更深卷積
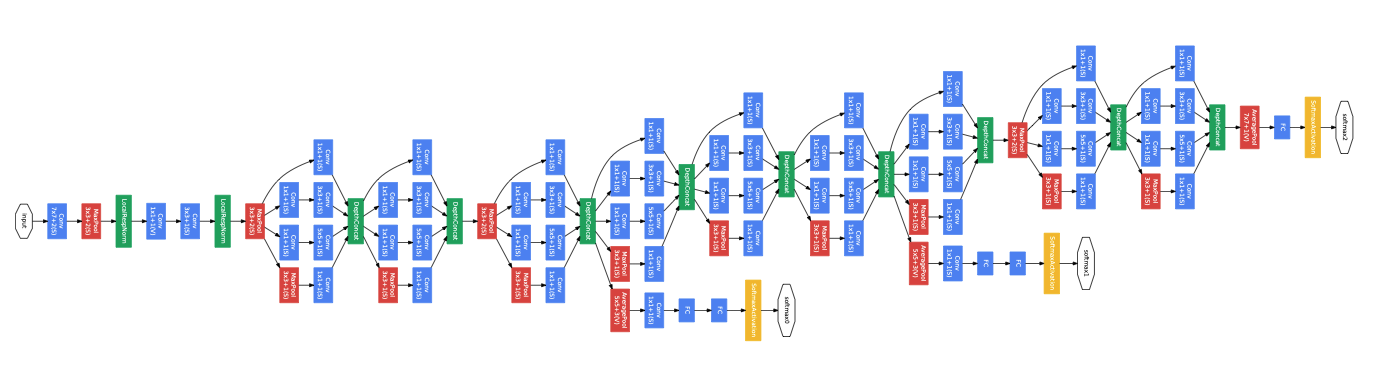
摘自“ Going Deeper with Convolutions”
VGG具有漂亮的外觀和易于理解的結構,但在ImageNet 2014競賽的所有決賽入圍者中表現都不佳,GoogLeNet(又名InceptionV1)獲得了最終獎,就像VGG一樣,GoogLeNet的主要貢獻之一就是 采用22層結構來突破網路深度的限制 ,這再次證明,進一步深入確實是提高準確性的正確方向,
與VGG不同,GoogLeNet試圖直接解決計算和梯度遞減問題,而不是提出具有更好的預訓練模式和權重初始化的解決方法,
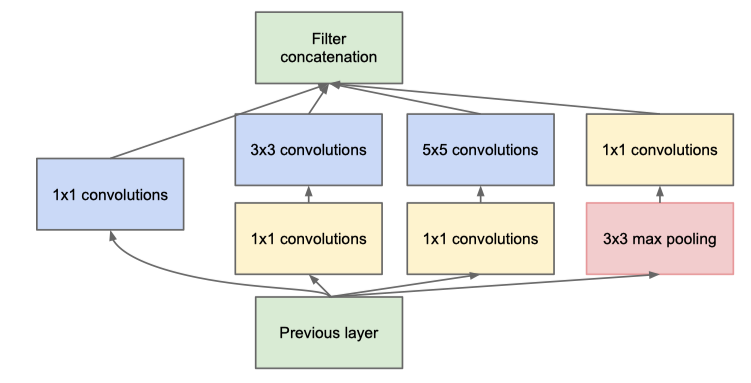
Bottleneck Inception Module From “ Going Deeper with Convolutions”
首先,它 使用稱為Inception的模塊探索了非對稱網路設計的思想 (請參見上圖),理想情況下,他們希望采用稀疏卷積或密集層來提高特征效率,但是現代硬體設計并非針對這種情況,因此,他們認為,網路拓撲級別的稀疏性還可以在利用現有硬體功能的同時,幫助融合功能,
其次,它通過借鑒論文“網路中的網路”來解決高計算成本的問題,基本上, 引入1x1卷積濾波器以在進行繁重的計算操作(如5x5卷積內核)之前減小特征的尺寸 ,以后將該結構稱為“ Bottleneck ”,并在許多后續網路中廣泛使用,類似于“網路中的網路”,它還使用平均池層代替最終的完全連接層,以進一步降低成本,
第三,為了幫助梯度流向更深的層次,GoogLeNet還對某些中間層輸出或輔助輸出使用了監督,由于其復雜性,該設計后來在影像分類網路中并不十分流行,但是在計算機視覺的其他領域(如Hourglass網路)的姿勢估計中越來越流行,
作為后續行動,這個Google團隊為此Inception系列寫了更多論文,“批處理規范化:通過減少內部協變數偏移來加速深度網路訓練”代表 InceptionV2 ,2015年的“重新思考計算機視覺的Inception架構”代表 InceptionV3 ,2015年的“ Inception-v4,Inception-ResNet和殘余連接對學習的影響”代表 InceptionV4 ,每篇論文都對原始的Inception網路進行了更多改進,并取得了更好的效果,
2015年:Batch Normalization
批處理規范化:通過減少內部協變數偏移來加速深度網路訓練
初始網路幫助研究人員在ImageNet資料集上達到了超人的準確性,但是,作為一種統計學習方法, CNN非常受特定訓練資料集的統計性質的限制 ,因此,為了獲得更高的準確性,我們通常需要預先計算整個資料集的平均值和標準偏差,并使用它們首先對我們的輸入進行歸一化,以確保網路中的大多數層輸入都緊密,從而轉化為更好的激活回應能力,這種近似方法非常麻煩,有時對于新的網路結構或新的資料集根本不起作用,因此深度學習模型仍然被認為很難訓練,為了解決這個問題,創建GoogLeNet的人Sergey Ioffe和Chritian Szegedy決定發明一種更聰明的東西,稱為“ 批量標準化 ”,

摘自“ 批量標準化:通過減少內部協變數偏移來加速深度網路訓練”
批量規范化的想法并不難:只要訓練足夠長的時間,我們就可以使用一系列小批量的統計資料來近似整個資料集的統計資料,而且,代替手動計算統計資訊,我們可以引入兩個更多可學習的引數 “縮放” 和 “移位” ,以使網路學習如何單獨對每一層進行規范化,
上圖顯示了計算批次歸一化值的程序,如我們所見,我們取整個小批量的平均值,并計算方差,接下來,我們可以使用此最小批量均值和方差對輸入進行歸一化,最后,通過比例尺和位移引數,網路將學會調整批標準化結果以最適合下一層,通常是ReLU,一個警告是我們在推理期間沒有小批量資訊,因此一種解決方法是在訓練期間計算移動平均值和方差,然后在推理路徑中使用這些移動平均值,這項小小的創新是如此具有影響力,所有后來的網路都立即開始使用它,
2015年:ResNet
深度殘差學習用于影像識別
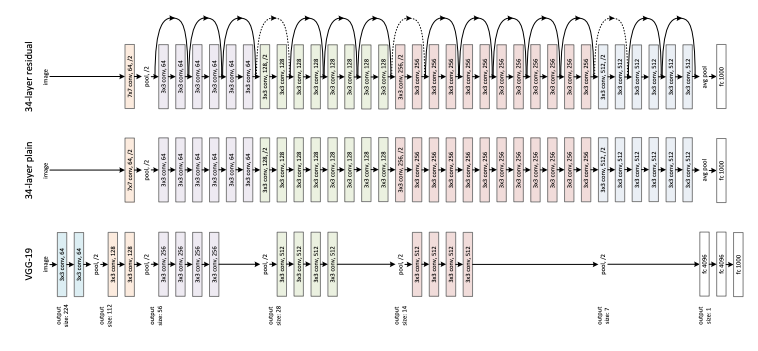
2015年可能是十年來計算機視覺最好的一年,我們已經看到很多偉大的想法不僅出現在影像分類中,而且還出現了各種各樣的計算機視覺任務,例如物件檢測,語意分割等, 2015年屬于一個名為ResNet或殘差網路的新網路,該網路由Microsoft Research Asia的一組中國研究人員提出,
摘自“ 用于影像識別的深度殘差學習”
正如我們之前在VGG網路中所討論的,要變得更深,最大的障礙是梯度消失問題,即,當通過更深的層向后傳播時,導數會越來越小,最終達到現代計算機體系結構無法真正代表的地步有意義地,GoogLeNet嘗試通過使用輔助監管和非對稱啟動模塊來對此進行攻擊,但只能在較小程度上緩解該問題,如果我們要使用50甚至100層,是否會有更好的方法讓漸變流過網路?ResNet的答案是使用殘差模塊,
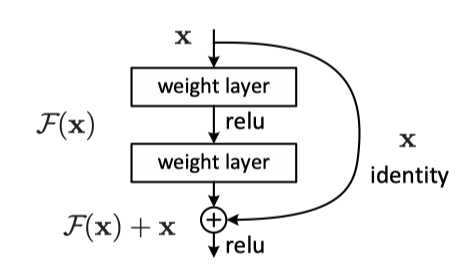
剩余的模塊從“ 深殘余學習影像識別”
ResNet在輸出中添加了身份標識快捷方式,因此每個殘差模塊至少都不能預測輸入是什么,而不會迷失方向,更為重要的是,殘差模塊不是希望每個圖層都直接適合所需的特征映射,而是嘗試了解輸出和輸入之間的差異,這使任務變得更加容易,因為所需的資訊增益較小,想象一下,您正在學習數學,對于每個新問題,都將得到一個類似問題的解決方案,因此您所要做的就是擴展此解決方案并使其起作用,這比為您遇到的每個問題想出一個全新的解決方案要容易得多,或者像牛頓所說,我們可以站在巨人的肩膀上,身份輸入就是剩余模塊的那個巨人,
除了身份映射,ResNet還從Inception網路借用了瓶頸和批處理規范化,最終,它成功構建了具有152個卷積層的網路,并在ImageNet上實作了80.72%的top-1準確性,剩余方法也成為后來的許多其他網路(例如Xception,Darknet等)的默認選項,此外,由于其簡單美觀的設計,如今它仍廣泛用于許多生產視覺識別系統中,
通過追蹤殘差網路的炒作,還有更多不變式出現,在“深層殘差網路中的身份映射”中,ResNet的原始作者試圖將激活放在殘差模塊之前,并獲得了更好的結果,此設計此后稱為ResNetV2,同樣,在2016年的論文《深度神經網路的聚合殘差變換》中,研究人員提出了ResNeXt,該模型為殘差模塊添加了并行分支,以匯總不同變換的輸出,
2016年:Xception
Xception:深度學習與深度可分卷積
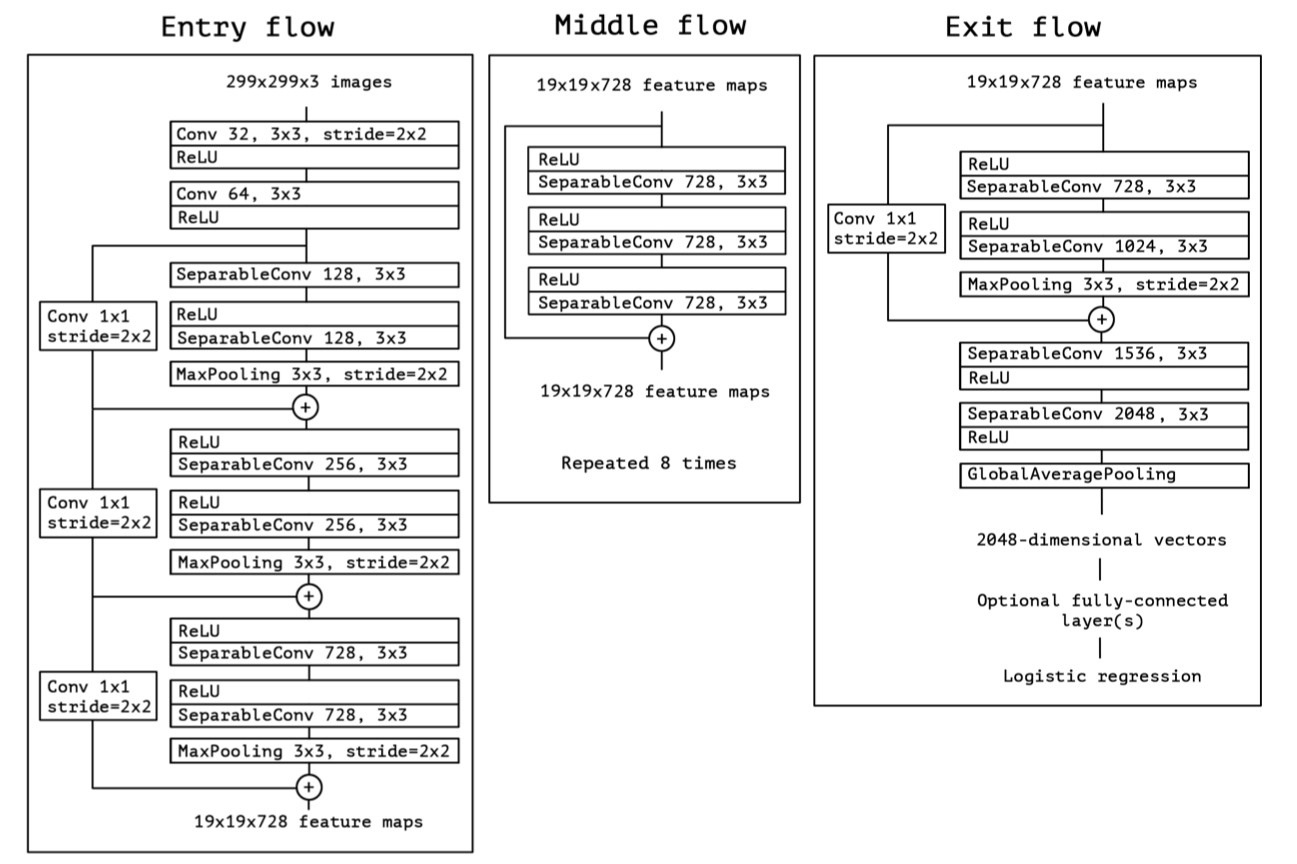
摘自“ Xception:深度學習與深度可分卷積”
隨著ResNet的發布,影像分類器中大多數低掛的水果看起來已經被搶走了,研究人員開始考慮CNN魔術的內部機制是什么,由于跨通道卷積通常會引入大量引數,因此Xception網路選擇調查此操作以了解其效果的全貌,
就像它的名字一樣,Xception源自Inception網路,在Inception模塊中,將不同轉換的多個分支聚合在一起以實作拓撲稀疏性,但是為什么這種稀疏起作用了?Xception的作者,也是Keras框架的作者,將此想法擴展到了一種極端情況,在這種情況下,一個3x3卷積檔案對應于最后一個串聯之前的一個輸出通道,在這種情況下,這些并行卷積內核實際上形成了一個稱為深度卷積的新操作,
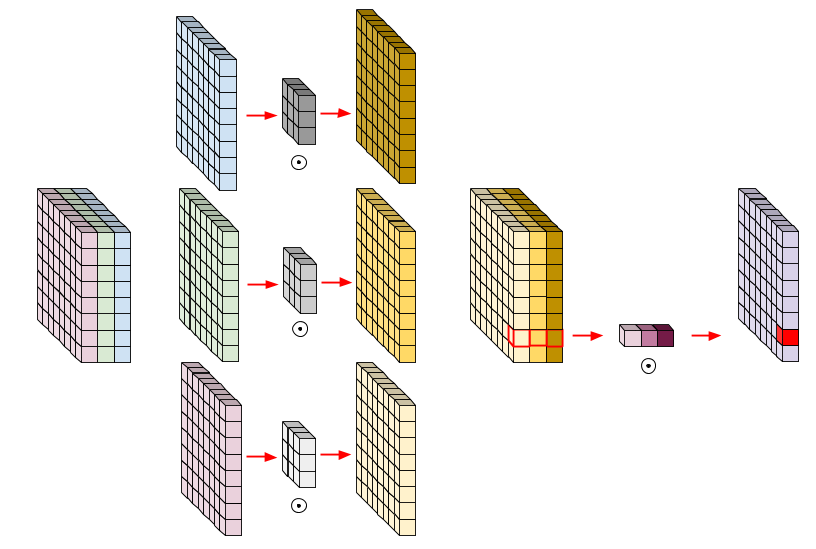
摘自“ 深度卷積和深度可分離卷積”
如上圖所示,與傳統卷積不同,傳統卷積包括所有通道以進行一次計算,深度卷積僅分別計算每個通道的卷積,然后將輸出串聯在一起,這減少了通道之間的特征交換,但也減少了很多連接,因此導致具有較少引數的層,但是,此操作將輸出與輸入相同數量的通道(如果將兩個或多個通道組合在一起,則輸出的通道數量將減少),因此,一旦合并了通道輸出,就需要另一個常規1x1濾波器或逐點卷積,以增加或減少通道數,就像常規卷積一樣,
這個想法最初不是來自Xception,在名為“大規模學習視覺表示”的論文中對此進行了描述,并且在InceptionV2中偶爾使用,Xception進一步邁出了一步,并用這種新型卷積代替了幾乎所有的卷積,實驗結果非常好,它超越了ResNet和InceptionV3,成為用于影像分類的新SOTA方法,這也證明了CNN中跨通道相關性和空間相關性的映射可以完全解耦,此外,由于與ResNet具有相同的優點,Xception也具有簡單美觀的設計,因此其思想還用于隨后的許多其他研究中,例如MobileNet,DeepLabV3等,
2017年:MobileNet
MobileNets:用于移動視覺應用的高效卷積神經網路
Xception在ImageNet上實作了79%的top-1準確性和94.5%的top-5準確性,但是與以前的SOTA InceptionV3相比分別僅提高了0.8%和0.4%,新影像分類網路的邊際收益越來越小,因此研究人員開始將注意力轉移到其他領域,在資源受限的環境中,MobileNet推動了影像分類的重大發展,
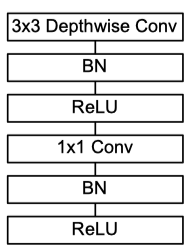
“ MobileNets:針對移動視覺應用的高效卷積神經網路”中的MobileNet模塊
與Xception相似,MobileNet使用與上面所示相同的深度可分離卷積模塊,并著重于高效和較少引數,
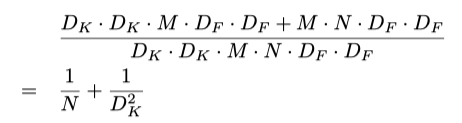
“ MobileNets:用于移動視覺應用的高效卷積神經網路”中的引數比率
上式中的分子是深度可分離卷積所需的引數總數,分母是相似的規則卷積的引數總數,這里D [K]是卷積核的大小,D [F]是特征圖的大小,M是輸入通道數,N是輸出通道數,由于我們將通道和空間特征的計算分開了,因此我們可以將乘法轉換為相加,其量級較小,從該比率可以看出,更好的是,輸出通道數越多,使用該新卷積節省的計算量就越多,
MobileNet的另一個貢獻是寬度和解析度乘數,MobileNet團隊希望找到一種規范的方法來縮小移動設備的模型大小,而最直觀的方法是減少輸入和輸出通道的數量以及輸入影像的解析度,為了控制此行為,比率alpha乘以通道,比率rho乘以輸入解析度(這也會影響要素圖的大小),因此,引數總數可以用以下公式表示:
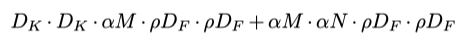
“ MobileNets:用于移動視覺應用的高效卷積神經網路”
盡管這種變化在創新方面看似天真,但它具有巨大的工程價值,因為這是研究人員首次得出結論,可以針對不同的資源約束調整網路的規范方法,此外,它還總結了改進神經網路的最終解決方案:更大和更高的解析度輸入會導致更高的精度,更薄和更低的解析度輸入會導致更差的精度,
在2018年和2019年晚些時候,MobiletNet團隊還發布了“ MobileNetV2:殘差和線性瓶頸”和“搜索MobileNetV3”,在MobileNetV2中,使用了倒置的殘留瓶頸結構,在MobileNetV3中,它開始使用神經體系結構搜索技術來搜索最佳體系結構組合,我們將在后面介紹,
2017年:NASNet
學習可擴展的體系結構以實作可擴展的影像識別
就像針對資源受限環境的影像分類一樣,神經體系結構搜索是在2017年左右出現的另一個領域,借助ResNet,Inception和Xception,似乎我們已經達到了人類可以理解和設計的最佳網路拓撲,但是如果有的話一個更好,更復雜的組合,遠遠超出了人類的想象力?2016年的一篇論文《帶有強化學習的神經體系結構搜索》提出了一種通過強化學習在預定搜索空間內搜索最佳組合的想法,眾所周知,強化學習是一種以目標明確,獎勵搜索代理商的最佳解決方案的方法,但是,受計算能力的限制,本文僅討論了在小型CIFAR資料集中的應用,

NASNet搜索空間,“ 學習可擴展的體系結構以實作可擴展的影像識別”
為了找到像ImageNet這樣的大型資料集的最佳結構,NASNet創建了針對ImageNet量身定制的搜索空間,它希望設計一個特殊的搜索空間,以便CIFAR上的搜索結果也可以在ImageNet上正常作業,首先,NASNet假設在良好的網路(如ResNet和Xception)中常用的手工模塊在搜索時仍然有用,因此,NASNet不再搜索隨機連接和操作,而是搜索這些模塊的組合,這些模塊已被證明在ImageNet上已經有用,其次,實際搜索仍在32x32解析度的CIFAR資料集上執行,因此NASNet僅搜索不受輸入大小影響的模塊,為了使第二點起作用,NASNet預定義了兩種型別的模塊模板:Reduction和Normal,
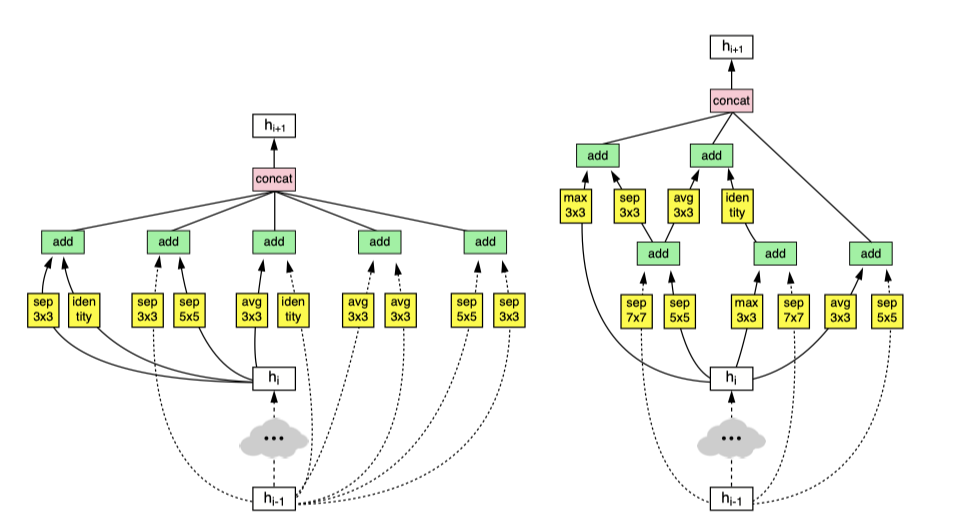
摘自“ 學習可擴展的體系結構以實作可伸縮的影像識別”
盡管NASNet具有比手動設計網路更好的度量標準,但是它也有一些缺點,尋找最佳結構的成本非常高,只有像Google和Facebook這樣的大公司才能負擔得起,而且,最終結構對人類來說并沒有太大意義,因此在生產環境中難以維護和改進,在2018年晚些時候,“ MnasNet:針對移動平臺的神經結構搜索”通過使用預定義的鏈塊結構限制搜索步驟,進一步擴展了NASNet的想法,此外,通過定義權重因子,mNASNet提供了一種更系統的方法來搜索給定特定資源限制的模型,而不僅僅是基于FLOP進行評估,
2019年:EfficientNet
EfficientNet:卷積神經網路模型縮放的反思
在2019年,對于CNN進行監督影像分類似乎不再有令人興奮的想法,網路結構的急劇變化通常只會帶來少許的精度提高,更糟的是,當同一網路應用于不同的資料集和任務時,以前聲稱的技巧似乎不起作用,這引發了人們的批評,即這些改進是否僅適合ImageNet資料集,另一方面,有一個技巧絕不會辜負我們的期望:使用更高解析度的輸入,為卷積層添加更多通道以及添加更多層,盡管力量非常殘酷,但似乎存在一種按需擴展網路的原則方法,MobileNetV1在2017年提出了這種建議,但后來重點轉移到了更好的網路設計上,
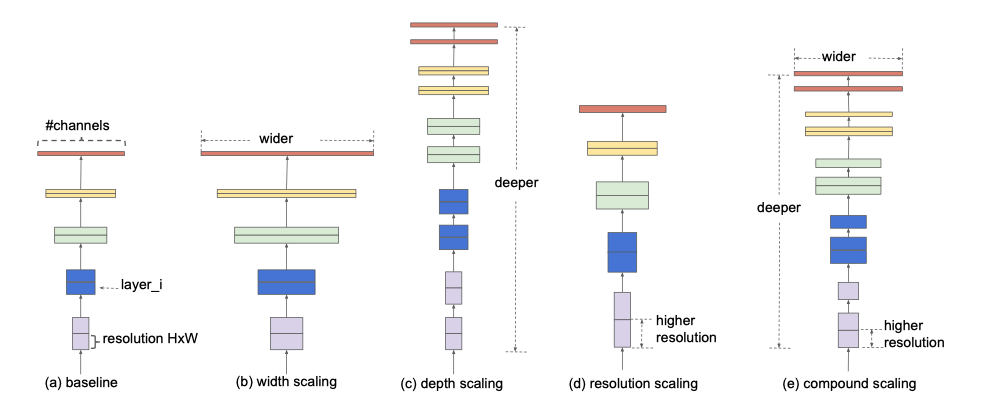
摘自“ EfficientNet:卷積神經網路的模型縮放思考”
繼NASNet和mNASNet之后,研究人員意識到,即使在計算機的幫助下,架構的改變也不會帶來太多好處,因此,他們開始回落到擴展網路規模,EfficientNet只是建立在此假設之上的,一方面,它使用了mNASNet的最佳構建基塊,以確保有良好的基礎,另一方面,它定義了三個引數alpha,beta和rho來分別控制網路的深度,寬度和解析度,這樣,即使沒有大型GPU池來搜索最佳結構,工程師仍可以依靠這些原則性引數根據他們的不同要求來調整網路,最后,EfficientNet提供了8種不同的變體,它們具有不同的寬度,深度和解析度,并且無論大小模型都具有良好的性能,換句話說,如果要獲得較高的精度,請使用600x600和66M引數的EfficientNet-B7,如果您想要低延遲和更小的模型,請使用224x224和5.3M引數EfficientNet-B0,問題解決了,
其他
如果您完成了10篇以上的論文的閱讀,您應該對CNN的影像分類歷史有了很好的了解,如果您想繼續學習這一領域,我還列出了一些其他有趣的論文供您閱讀,這些論文在各自領域都很有名,并啟發了世界上許多其他研究人員,
2014年:SPPNet
深度卷積網路中的空間金字塔池用于視覺識別
SPPNet從傳統的計算機視覺特征提取中借鑒了特征金字塔的思想,該金字塔形成了一個具有不同比例的要素詞袋,因此它可以適應不同的輸入大小并擺脫固定大小的全連接層,這個想法還進一步啟發了DeepLab的ASPP模塊以及用于物件檢測的FPN,
2016年:DenseNet
緊密連接的卷積網路
康奈爾大學的DenseNet進一步擴展了ResNet的想法,它不僅提供各層之間的跳過連接,而且還具有來自所有先前各層的跳過連接,
2017年:SENet
擠壓和激勵網路
Xception網路證明,跨渠道關聯與空間關聯關系不大,但是,作為上屆ImageNet競賽的冠軍,SENet設計了一個“擠壓和激發”區并講述了一個不同的故事,SE塊首先使用全域池將所有通道壓縮為較少的通道,然后應用完全連接的變換,然后使用另一個完全連接的層將其“激發”回原來的通道數量,因此,實質上,FC層幫助網路了解輸入要素圖上的注意力,
2017年:ShuffleNet
ShuffleNet:一種用于移動設備的極其高效的卷積神經網路
ShuffleNet構建在MobileNetV2的倒置瓶頸模塊之上,他認為深度可分離卷積中的點式卷積會犧牲準確性,以換取更少的計算量,為了彌補這一點,ShuffleNet增加了一個額外的通道改組操作,以確保逐點卷積不會始終應用于相同的“點”,在ShuffleNetV2中,此通道重排機制也進一步擴展到ResNet身份映射分支,因此身份功能的一部分也將用于重排,
2018:Bag of Tricks
使用卷積神經網路進行影像分類的技巧
“技巧包”重點介紹在影像分類區域中使用的常見技巧,當工程師需要提高基準性能時,它可以作為很好的參考,有趣的是,諸如混合增強和余弦學習速率之類的這些技巧有時可以比新的網路體系結構實作更好的改進,
結論
隨著EfficientNet的發布,ImageNet分類基準似乎即將結束,使用現有的深度學習方法,除非發生另一種模式轉變,否則我們永遠不會有一天可以在ImageNet上達到99.999%的準確性,因此,研究人員正在積極研究一些新穎的領域,例如用于大規模視覺識別的自我監督或半監督學習,同時,使用現有方法,對于工程師和企業家來說,找到這種不完美技術的實際應用已經成為一個問題,
Reference
- Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based Learning Applied to Document Recognition
- Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks
- Karen Simonyan, Andrew Zisserman, Very Deep Convolutional Networks for Large-Scale Image Recognition
- Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions
- Sergey Ioffe, Christian Szegedy, Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition
- Fran?ois Chollet, Xception: Deep Learning with Depthwise Separable Convolutions
- Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application
- Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le, Learning Transferable Architectures for Scalable Image Recognition
- Mingxing Tan, Quoc V. Le, EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger, Densely Connected Convolutional Networks
- Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu, Squeeze-and-Excitation Networks
- Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun, ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li, Bag of Tricks for Image Classification with Convolutional Neural Networks
- https://towardsdatascience.com/10-papers-you-should-read-to-understand-image-classification-in-the-deep-learning-era-4b9d792f45a7
編輯:Sophia | 王博(Kings)筆記
計算機視覺聯盟 報道 | 公眾號 CVLianMeng
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/83598.html
標籤:其他