介紹
在深度學習黑客競賽中表現出色的技巧(或者坦率地說,是任何資料科學黑客競賽) 通常歸結為特征工程, 當您獲得的資料不足以建立一個成功的深度學習模型時,你能發揮多少創造力?
我是根據自己參加多次深度學習黑客競賽的經驗而談的,在這次深度黑客競賽中,我們獲得了包含數百張影像的資料集——根本不足以贏得甚至完成排行榜的頂級排名,那我們怎么處理這個問題呢?
答案? 好吧,那要看資料科學家的技能了! 這就是我們的好奇心和創造力脫穎而出的地方, 這就是特征工程背后的理念——在現有特征的情況下,我們能多好地提出新特征,當我們處理影像資料時,同樣的想法也適用,
這就是影像增強的主要作用,這一概念不僅僅局限于黑客競賽——我們在工業和現實世界中深度學習模型專案中都使用了它!

影像增強功能幫助我擴充現有資料集,而無需費時費力, 而且我相信您會發現這項技術對您自己的專案非常有幫助,
因此,在本文中,我們將了解影像增強的概念,為何有用以及哪些不同的影像增強技術, 我們還將實作這些影像增強技術,以使用PyTorch構建影像分類模型,
目錄
- 為什么需要影像增強?
- 不同的影像增強技術
- 選擇正確的增強技術的基本準則
- 案例研究:使用影像增強解決影像分類問題
為什么需要影像增強?
深度學習模型通常需要大量的資料來進行訓練,通常,資料越多,模型的性能越好,但是獲取海量資料面臨著自身的挑戰,不是每個人都有大公司的雄厚財力,
缺少資料使得我們的[深度學習模型](https://courses.analyticsvidhya.com/courses/computer-vision-using-deep-learning-version2?utm_source=blog&utm_medium=image-augmentation-deep -learning-pytorch)可能無法從資料中學習模式或功能,因此在未見過的資料上可能無法提供良好的性能,
那么在那種情況下我們該怎么辦?我們可以使用影像增強技術,而無需花費幾天的時間手動收集資料,
影像增強是生成新影像以訓練我們的深度學習模型的程序,這些新影像是使用現有的訓練影像生成的,因此我們不必手動收集它們,

有多種影像增強技術,我們將在下一節討論一些常見的和使用最廣泛的技術,
不同的影像增強技術
影像旋轉
影像旋轉是最常用的增強技術之一,它可以幫助我們的模型對物件方向的變化變得健壯,即使我們旋轉影像,影像的資訊也保持不變,汽車就是一輛汽車,即使我們從不同的角度看它:

因此,我們可以使用此技術,通過從原始影像創建旋轉影像來增加資料量,讓我們看看如何旋轉影像:
# 匯入所有必需的庫
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import skimage.io as io
from skimage.transform import rotate, AffineTransform, warp
from skimage.util import random_noise
from skimage.filters import gaussian
import matplotlib.pyplot as plt
% matplotlib inline
我將使用此影像演示不同的影像增強技術,你也可以根據自己的要求嘗試其他圖片,
我們先匯入影像并將其可視化:
# reading the image using its path
image = io.imread('emergency_vs_non-emergency_dataset/images/0.jpg')
# shape of the image
print(image.shape)
# displaying the image
io.imshow(image)

這是原始影像,現在讓我們看看如何旋轉它,我將使用skimage 庫的旋轉功能來旋轉影像:
print('Rotated Image')
#rotating the image by 45 degrees
rotated = rotate(image, angle=45, mode = 'wrap')
#plot the rotated image
io.imshow(rotated)
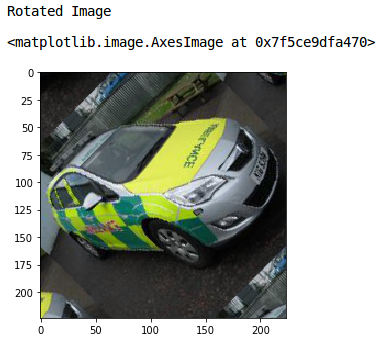
很好!將模式設定為“wrap”,用影像的剩余像素填充輸入邊界之外的點,
平移影像
可能會出現影像中的物件沒有完全居中對齊的情況, 在這些情況下,可以使用影像平移為影像添加平移不變性,
通過移動影像,我們可以更改物件在影像中的位置,從而使模型更具多樣性, 最終將生成更通用的模型,
影像平移是一種幾何變換,它將影像中每個物件的位置映射到最終輸出影像中的新位置,
在移位操作之后,輸入影像中的位置(x,y)處的物件被移位到新位置(X,Y):
- X = x + dx
- Y = y + dy
其中,dx和dy分別是沿不同維度的位移,讓我們看看如何將shift應用于影像:
# 應用平移操作
transform = AffineTransform(translation=(25,25))
wrapShift = warp(image,transform,mode='wrap')
plt.imshow(wrapShift)
plt.title('Wrap Shift')
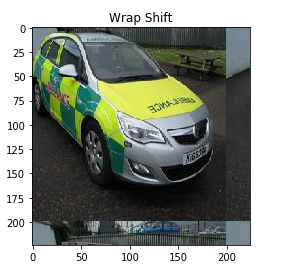
translation超引數定義影像應移動的像素數,這里,我把影像移了(25,25)個像素,您可以隨意設定此超引數的值,
我再次使用“wrap”模式,它用影像的剩余像素填充輸入邊界之外的點,在上面的輸出中,您可以看到影像的高度和寬度都移動了25像素,
翻轉影像
翻轉是旋轉的延伸, 它使我們可以在左右以及上下方向上翻轉影像, 讓我們看看如何實作翻轉:
#flip image left-to-right
flipLR = np.fliplr(image)
plt.imshow(flipLR)
plt.title('Left to Right Flipped')
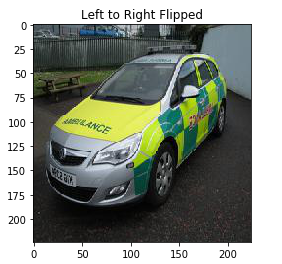
在這里,我使用了NumPy的fliplr 函式從左向右翻轉影像, 它翻轉每一行的像素值,并且輸出確認相同, 類似地,我們可以沿上下方向翻轉影像:
# 上下翻轉影像
flipUD = np.flipud(image)
plt.imshow(flipUD)
plt.title('Up Down Flipped')
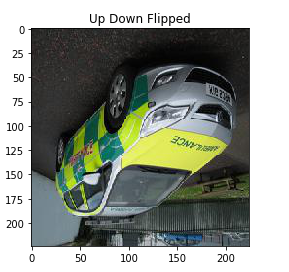
這就是我們可以翻轉影像并制作更通用的模型的方法,該模型將學習到原始影像以及翻轉后的影像, 向影像添加隨機噪聲也是影像增強技術, 讓我們通過一個例子來理解它,
給影像添加噪點
影像噪聲是一個重要的增強步驟,使我們的模型能夠學習如何分離影像中的信號和噪聲,這也使得模型對輸入的變化更加健壯,
我們將使用“skipage”庫的“random_noise”函式為原始影像添加一些隨機噪聲
我將噪聲的標準差取為0.155(您也可以更改此值),請記住,增加此值將為影像添加更多噪聲,反之亦然:
# 要添加到影像中的噪聲的標準差
sigma=0.155
# 向影像添加隨機噪聲
noisyRandom = random_noise(image,var=sigma**2)
plt.imshow(noisyRandom)
plt.title('Random Noise')
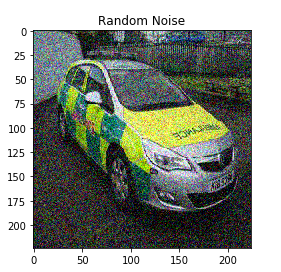
我們可以看到隨機噪聲已添加到原始影像中, 試一下不同的標準偏差的值,看看得到的不同結果,
模糊影像
所有攝影愛好者都會立即理解這個想法,
影像有不同的來源, 因此,每個來源的影像質量都將不同, 有些影像的質量可能很高,而另一些則可能很差勁,
在這種情況下,我們可以使影像模糊, 那將有什么幫助? 好吧,這有助于使我們的深度學習模型更強大,
讓我們看看我們如何做到這一點, 我們將使用高斯濾波器來模糊影像:
# 模糊影像
blurred = gaussian(image,sigma=1,multichannel=True)
plt.imshow(blurred)
plt.title('Blurred Image')
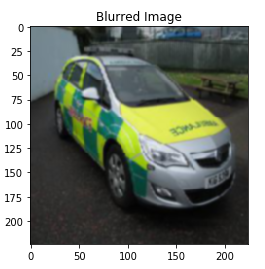
Sigma是高斯濾波器的標準差,我將其視為1,sigma值越高,模糊效果越強, 將* Multichannel *設定為true可確保分別過濾影像的每個通道,
同樣,您可以嘗試使用不同的sigma值來更改模糊度,
這些是一些影像增強技術,有助于使我們的深度學習模型健壯且可推廣,這也有助于增加訓練集的大小,
我們即將完成本教程的實作部分,在此之前,讓我們看看一些基本的準則,以決定正確的影像增強技術,
選擇正確的增強技術的基本準則
我認為在根據您試圖解決的問題來決定增強技術時,有一些準則是很重要的,以下是這些準則的簡要概述:
- 任何模型構建程序的第一步都是確保輸入的大小與模型所期望的大小相匹配,我們還必須確保所有影像的大小應該相似,為此,我們可以調整我們的影像到適當的大小,
- 假設您正在處理一個分類問題,并且樣本資料量相對較少,在這種情況下,可以使用不同的增強技術,如影像旋轉、影像噪聲、翻轉、移位等,請記住,所有這些操作都適用于對影像中物件位置無關緊要的分類問題,
- 如果您正在處理一個物件檢測任務,其中物件的位置是我們要檢測的,這些技術可能不合適,
- 影像像素值的標準化是保證模型更好更快收斂的一個很好的策略,如果模型有特定的要求,我們必須根據模型的要求對影像進行預處理,
現在,不用再等了,讓我們繼續到模型構建部分,我們將應用本文討論的增強技術生成影像,然后使用這些影像來訓練模型,
我們將研究緊急車輛與非緊急車輛的分類問題,如果你看過我以前的PyTorch文章,你應該熟悉問題的描述,
該專案的目標是將車輛影像分為緊急和非緊急兩類,你猜對了,這是一個影像分類問題,您可以從這里下載資料集,
加載資料集
我們開始吧!我們先把資料裝入notebook,然后,我們將應用影像增強技術,最后,建立一個卷積神經網路(CNN)模型,
讓我們匯入所需的庫:
# 匯入庫
from torchsummary import summary
import pandas as pd
import numpy as np
from skimage.io import imread, imsave
from tqdm import tqdm
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from skimage.transform import rotate
from skimage.util import random_noise
from skimage.filters import gaussian
from scipy import ndimage
現在,我們將讀取包含影像名稱及其相應標簽的CSV檔案:
# 加載資料集
data = https://www.cnblogs.com/panchuangai/p/pd.read_csv('emergency_vs_non-emergency_dataset/emergency_train.csv')
data.head()
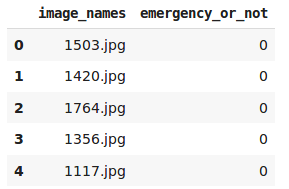
0表示該車為非緊急車輛,1表示該車為緊急車輛,現在讓我們從資料集中加載所有影像:
# 加載影像
train_img = []
for img_name in tqdm(data['image_names']):
image_path = 'emergency_vs_non-emergency_dataset/images/' + img_name
img = imread(image_path)
img = img/255
train_img.append(img)
train_x = np.array(train_img)
train_y = data['emergency_or_not'].values
train_x.shape, train_y.shape

資料集中共有1646幅影像,讓我們把這些資料分成訓練和驗證集,我們將使用驗證集來評估模型在未見過的資料上的性能:
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, test_size = 0.1, random_state = 13, stratify=train_y)
(train_x.shape, train_y.shape), (val_x.shape, val_y.shape)

我將“test_size”保持為0.1,因此10%的資料將隨機選擇作為驗證集,剩下的90%將用于訓練模型,訓練集有1481個影像,這對于訓練深度學習模型來說是相當少的,
因此,接下來,我們將增加這些訓練影像,以增加訓練集,并可能提高模型的性能,
增強影像
我們將使用前面討論過的影像增強技術:
final_train_data = https://www.cnblogs.com/panchuangai/p/[]
final_target_train = []
for i in tqdm(range(train_x.shape[0])):
final_train_data.append(train_x[i])
final_train_data.append(rotate(train_x[i], angle=45, mode ='wrap'))
final_train_data.append(np.fliplr(train_x[i]))
final_train_data.append(np.flipud(train_x[i]))
final_train_data.append(random_noise(train_x[i],var=0.2**2))
for j in range(5):
final_target_train.append(train_y[i])

我們為訓練集中的1481張影像中的每一張生成了4張增強影像,讓我們以陣列的形式轉換影像并驗證資料集的大小:
len(final_target_train), len(final_train_data)
final_train = np.array(final_train_data)
final_target_train = np.array(final_target_train)
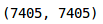
這證實了我們已經增強了影像并增加了訓練集的大小,讓我們將這些增強影像進行可視化:
fig,ax = plt.subplots(nrows=1,ncols=5,figsize=(20,20))
for i in range(5):
ax[i].imshow(final_train[i+30])
ax[i].axis('off')

這里的第一個影像是來自資料集的原始影像,其余四幅影像分別使用不同的影像增強技術(旋轉、從左向右翻轉、上下翻轉和添加隨機噪聲)生成的,
我們的資料集現在已經準備好了,是時候定義我們的深度學習模型的結構,然后在增強過的訓練集上對其進行訓練了,我們先從PyTorch中匯入所有函式:
# PyTorch 庫和模塊
import torch
from torch.autograd import Variable
from torch.nn import Linear, ReLU, CrossEntropyLoss, Sequential, Conv2d, MaxPool2d, Module, Softmax, BatchNorm2d, Dropout
from torch.optim import Adam, SGD
我們必須將訓練集和驗證集轉換為PyTorch格式:
# 將訓練影像轉換為torch格式
final_train = final_train.reshape(7405, 3, 224, 224)
final_train = torch.from_numpy(final_train)
final_train = final_train.float()
# 將target轉換為torch格式
final_target_train = final_target_train.astype(int)
final_target_train = torch.from_numpy(final_target_train)
同樣,我們將轉換驗證集:
# 將驗證影像轉換為torch格式
val_x = val_x.reshape(165, 3, 224, 224)
val_x = torch.from_numpy(val_x)
val_x = val_x.float()
# 將target轉換為torch格式
val_y = val_y.astype(int)
val_y = torch.from_numpy(val_y)
模型結構
接下來,我們將定義模型的結構,這有點復雜,因為模型結構包含4個卷積塊,然后是4個全連接層:
torch.manual_seed(0)
class Net(Module):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = Sequential(
# 定義2D convolution層
Conv2d(3, 32, kernel_size=3, stride=1, padding=1),
ReLU(inplace=True),
# 添加batch normalization層
BatchNorm2d(32),
MaxPool2d(kernel_size=2, stride=2),
# 添加 dropout
Dropout(p=0.25),
# 定義另一個2D convolution層
Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
ReLU(inplace=True),
# 添加batch normalization層
BatchNorm2d(64),
MaxPool2d(kernel_size=2, stride=2),
# 添加 dropout
Dropout(p=0.25),
# 定義另一個2D convolution層
Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
ReLU(inplace=True),
# 添加batch normalization層
BatchNorm2d(128),
MaxPool2d(kernel_size=2, stride=2),
# 添加 dropout
Dropout(p=0.25),
# 定義另一個2D convolution層
Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
ReLU(inplace=True),
# 添加batch normalization層
BatchNorm2d(128),
MaxPool2d(kernel_size=2, stride=2),
# 添加 dropout
Dropout(p=0.25),
)
self.linear_layers = Sequential(
Linear(128 * 14 * 14, 512),
ReLU(inplace=True),
Dropout(),
Linear(512, 256),
ReLU(inplace=True),
Dropout(),
Linear(256,10),
ReLU(inplace=True),
Dropout(),
Linear(10,2)
)
# 定義前向程序
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
return x
讓我們定義模型的其他超引數,包括優化器、學習率和損失函式:
# defining the model
model = Net()
# defining the optimizer
optimizer = Adam(model.parameters(), lr=0.000075)
# defining the loss function
criterion = CrossEntropyLoss()
# checking if GPU is available
if torch.cuda.is_available():
model = model.cuda()
criterion = criterion.cuda()
print(model)

訓練模型
為我們的深度學習模型訓練20個epoch:
torch.manual_seed(0)
# 模型的batch size
batch_size = 64
# 訓練模型的epoch數
n_epochs = 20
for epoch in range(1, n_epochs+1):
train_loss = 0.0
permutation = torch.randperm(final_train.size()[0])
training_loss = []
for i in tqdm(range(0,final_train.size()[0], batch_size)):
indices = permutation[i:i+batch_size]
batch_x, batch_y = final_train[indices], final_target_train[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
optimizer.zero_grad()
outputs = model(batch_x)
loss = criterion(outputs,batch_y)
training_loss.append(loss.item())
loss.backward()
optimizer.step()
training_loss = np.average(training_loss)
print('epoch: \t', epoch, '\t training loss: \t', training_loss)
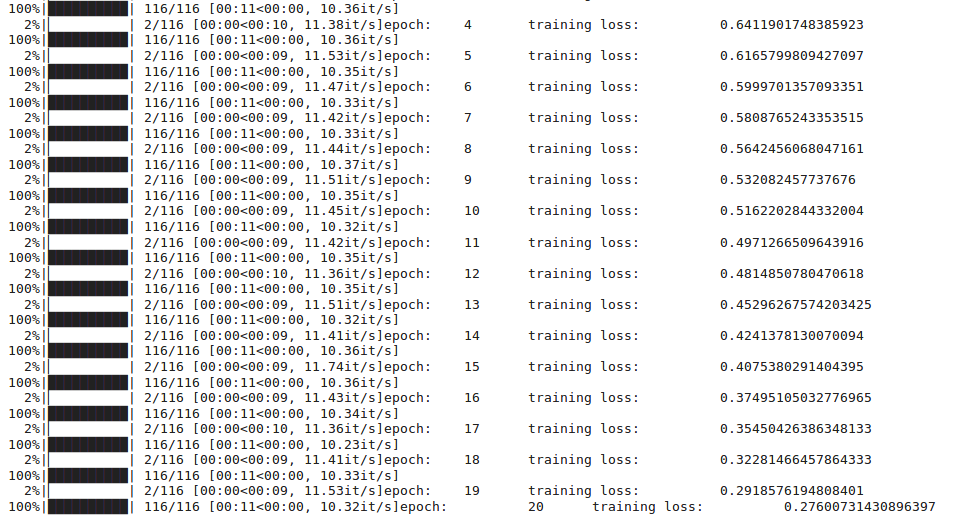
這是訓練階段的summary,你會注意到,隨著epoch的增加,訓練loss會減少,讓我們保存已訓練的模型的權重,以便將來在不重新訓練模型的情況下使用它們:
torch.save(model, 'model.pt')
如果您不想在您的終端訓練模型,您可以使用此鏈接下載已訓練了20個epoch的模型的權重,
接下來,讓我們加載這個模型:
the_model = torch.load('model.pt')
測驗我們模型的性能
最后,讓我們對訓練集和驗證集進行預測,并檢查各自的準確度:
torch.manual_seed(0)
# 預測訓練集
prediction = []
target = []
permutation = torch.randperm(final_train.size()[0])
for i in tqdm(range(0,final_train.size()[0], batch_size)):
indices = permutation[i:i+batch_size]
batch_x, batch_y = final_train[indices], final_target_train[indices]
if torch.cuda.is_available():
batch_x, batch_y = batch_x.cuda(), batch_y.cuda()
with torch.no_grad():
output = model(batch_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.numpy())
predictions = np.argmax(prob, axis=1)
prediction.append(predictions)
target.append(batch_y)
# 訓練準確度
accuracy = []
for i in range(len(prediction)):
accuracy.append(accuracy_score(target[i].cpu(),prediction[i]))
print('training accuracy: \t', np.average(accuracy))

訓練集的準確率超過91%!很有希望,但是,讓我們拭目以待吧,我們需要對驗證集進行相同的檢查:
# 預測驗證集
torch.manual_seed(0)
output = model(val_x.cuda())
softmax = torch.exp(output).cpu()
prob = list(softmax.detach().numpy())
predictions = np.argmax(prob, axis=1)
accuracy_score(val_y, predictions)
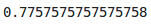
驗證準確性約為78%, 很好!
尾注
當我們開始獲得的訓練資料較少時,我們可以使用影像增強技術,
在本文中,我們介紹了大多數常用的影像增強技術, 我們學習了如何旋轉,移動和翻轉影像, 我們還學習了如何為影像添加隨機噪聲或使其模糊, 然后,我們討論了選擇正確的增強技術的基本準則,
您可以在任何影像分類問題上嘗試使用這些影像增強技術,然后比較使用增強和不使用增強的性能, 隨時在下面的評論部分中分享您的結果,
而且,如果您不熟悉深度學習,計算機視覺和影像資料,那么建議您完成以下課程:
- 使用深度學習2.0的計算機視覺
原文鏈接:https://www.analyticsvidhya.com/blog/2019/12/image-augmentation-deep-learning-pytorch/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/85199.html
標籤:其他