作者|DR. VAIBHAV KUMAR
編譯|VK
來源|Analytics In Diamag
人工神經網路有許多流行的變體,可用于有監督和無監督學習問題,自編碼器也是神經網路的一個變種,主要用于無監督學習問題,
當它們在體系結構中有多個隱藏層時,它們被稱為深度自編碼器,這些模型可以應用于包括影像重建在內的各種應用,
在影像重建中,他們學習輸入影像模式的表示,并重建與原始輸入影像模式匹配的新影像,影像重建有許多重要的應用,特別是在醫學領域,需要從現有的不完整或有噪聲的影像中提取解碼后的無噪聲影像,
在本文中,我們將演示在PyTorch中實作用于重建影像的深度自編碼器,該深度學習模型將以MNIST手寫數字為訓練物件,在學習輸入影像的表示后重建數字影像,

自編碼器
自編碼器是人工神經網路的變體,通常用于以無監督的方式學習有效的資料編碼,
他們通常在一個表示學習方案中學習,在那里他們學習一組資料的編碼,網路通過學習輸入資料的表示,以非常相似的方式重建輸入資料,自編碼器的基本結構如下所示,
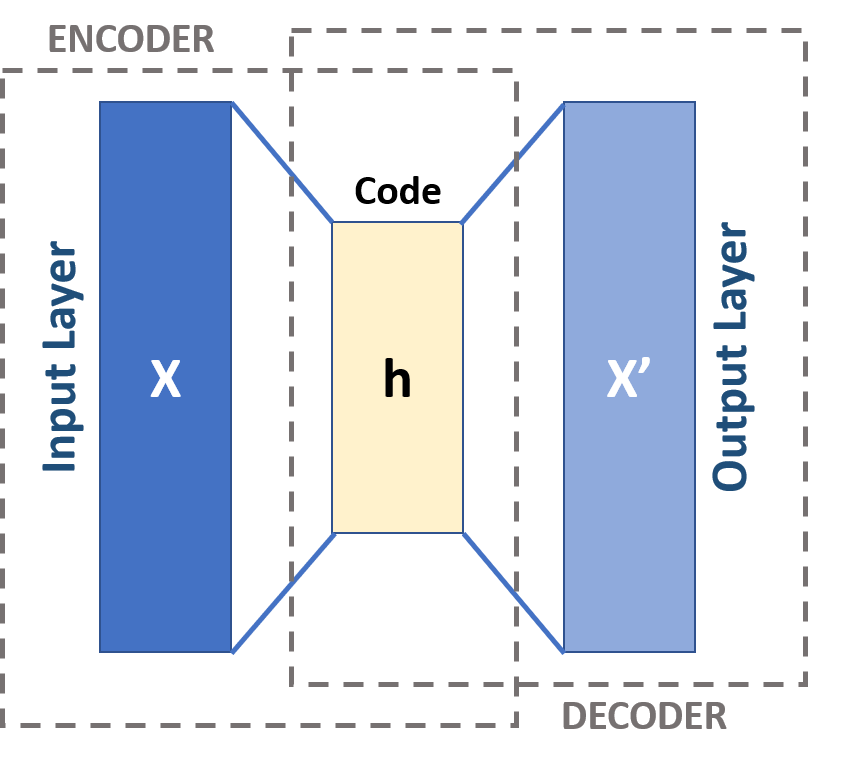
該體系結構通常包括輸入層、輸出層和連接輸入和輸出層的一個或多個隱藏層,輸出層與輸入層具有相同數量的節點,因為它要重新構造輸入,
在它的一般形式中,只有一個隱藏層,但在深度自動編碼器的情況下,有多個隱藏層,這種深度的增加減少了表示某些函式的計算成本,也減少了學習某些函式所需的訓練資料量,其應用領域包括例外檢測、影像處理、資訊檢索、藥物發現等,
在PyTorch中實作深度自編碼器
首先,我們將匯入所有必需的庫,
import os
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms as transforms
import torch.optim as optim
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torchvision import datasets
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from PIL import Image
現在,我們將定義超引數的值,
Epochs = 100
Lr_Rate = 1e-3
Batch_Size = 128
以下函式將用于PyTorch模型所需的影像轉換,
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
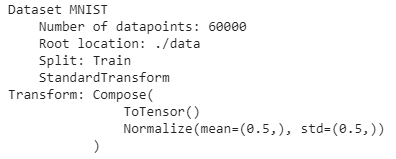
使用下面的代碼片段,我們將下載MNIST手寫數字資料集,并為進一步處理做好準備,
train_set = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_set = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_set, Batch_Size=Batch_Size, shuffle=True)
test_loader = DataLoader(test_set, Batch_Size=Batch_Size, shuffle=True)
讓我們看看關于訓練資料及其類的一些資訊,
print(train_set)
print(train_set.classes)

在下一步中,我們將定義用于定義模型的Autoencoder類,
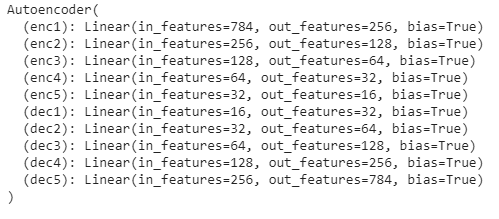
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
#編碼器
self.enc1 = nn.Linear(in_features=784, out_features=256) # Input image (28*28 = 784)
self.enc2 = nn.Linear(in_features=256, out_features=128)
self.enc3 = nn.Linear(in_features=128, out_features=64)
self.enc4 = nn.Linear(in_features=64, out_features=32)
self.enc5 = nn.Linear(in_features=32, out_features=16)
#解碼器
self.dec1 = nn.Linear(in_features=16, out_features=32)
self.dec2 = nn.Linear(in_features=32, out_features=64)
self.dec3 = nn.Linear(in_features=64, out_features=128)
self.dec4 = nn.Linear(in_features=128, out_features=256)
self.dec5 = nn.Linear(in_features=256, out_features=784) # Output image (28*28 = 784)
def forward(self, x):
x = F.relu(self.enc1(x))
x = F.relu(self.enc2(x))
x = F.relu(self.enc3(x))
x = F.relu(self.enc4(x))
x = F.relu(self.enc5(x))
x = F.relu(self.dec1(x))
x = F.relu(self.dec2(x))
x = F.relu(self.dec3(x))
x = F.relu(self.dec4(x))
x = F.relu(self.dec5(x))
return x
現在,我們將創建Autoencoder模型作為上面定義的Autoencoder類的一個物件,
model = Autoencoder()
print(model)
現在,我們將定義損失函式和優化方法,
criterion = nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=Lr_Rate)
以下函式將啟用CUDA環境,
def get_device():
if torch.cuda.is_available():
device = 'cuda:0'
else:
device = 'cpu'
return device
下面的函式將創建一個目錄來保存結果,
def make_dir():
image_dir = 'MNIST_Out_Images'
if not os.path.exists(image_dir):
os.makedirs(image_dir)
使用下面的函式,我們將保存模型生成的重建影像,
def save_decod_img(img, epoch):
img = img.view(img.size(0), 1, 28, 28)
save_image(img, './MNIST_Out_Images/Autoencoder_image{}.png'.format(epoch))
將呼叫下面的函式來訓練模型,
def training(model, train_loader, Epochs):
train_loss = []
for epoch in range(Epochs):
running_loss = 0.0
for data in train_loader:
img, _ = data
img = img.to(device)
img = img.view(img.size(0), -1)
optimizer.zero_grad()
outputs = model(img)
loss = criterion(outputs, img)
loss.backward()
optimizer.step()
running_loss += loss.item()
loss = running_loss / len(train_loader)
train_loss.append(loss)
print('Epoch {} of {}, Train Loss: {:.3f}'.format(
epoch+1, Epochs, loss))
if epoch % 5 == 0:
save_decod_img(outputs.cpu().data, epoch)
return train_loss
以下函式將對訓練后的模型進行影像重建測驗,
def test_image_reconstruct(model, test_loader):
for batch in test_loader:
img, _ = batch
img = img.to(device)
img = img.view(img.size(0), -1)
outputs = model(img)
outputs = outputs.view(outputs.size(0), 1, 28, 28).cpu().data
save_image(outputs, 'MNIST_reconstruction.png')
break
在訓練之前,模型將被推送到CUDA環境中,并使用上面定義的函式創建目錄來保存結果影像,
device = get_device()
model.to(device)
make_dir()
現在,將對模型進行訓練,
train_loss = training(model, train_loader, Epochs)


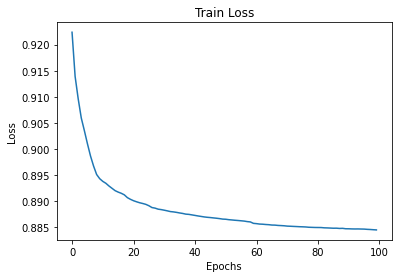
訓練成功后,我們將在訓練中可視化損失,
plt.figure()
plt.plot(train_loss)
plt.title('Train Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.savefig('deep_ae_mnist_loss.png')
我們將可視化訓練期間保存的一些影像,
Image.open('/content/MNIST_Out_Images/Autoencoder_image0.png')

Image.open('/content/MNIST_Out_Images/Autoencoder_image50.png')

Image.open('/content/MNIST_Out_Images/Autoencoder_image95.png')

在最后一步,我們將測驗我們的自編碼器模型來重建影像,
test_image_reconstruct(model, testloader)
Image.open('/content/MNIST_reconstruction.png')
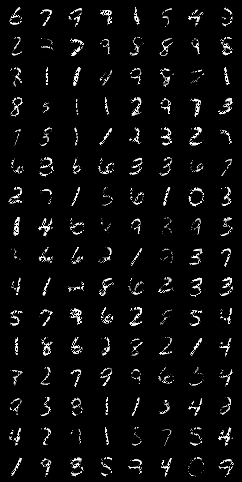
所以,我們可以看到,自訓練程序開始時,自編碼器模型就開始重建影像,第一個epoch以后,重建的質量不是很好,直到50 epoch后才得到改進,
經過完整的訓練,我們可以看到,在95 epoch以后生成的影像和測驗中,它可以構造出與原始輸入影像非常匹配的影像,
我們根據loss值,可以知道epoch可以設定100或200,
經過長時間的訓練,有望獲得更清晰的重建影像,然而,通過這個演示,我們可以理解如何在PyTorch中實作用于影像重建的深度自編碼器,
參考文獻:
- Sovit Ranjan Rath, “Implementing Deep Autoencoder in PyTorch”
- Abien Fred Agarap, “Implementing an Autoencoder in PyTorch”
- Reyhane Askari, “Auto Encoders”
原文鏈接:https://analyticsindiamag.com/hands-on-guide-to-implement-deep-autoencoder-in-pytorch-for-image-reconstruction/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/85206.html
標籤:其他