一、安裝MyCat
1.安裝準備環境
1.1 安裝JDK
??因為MyCat是java開發的,所以需要java虛擬機環境,在Linux節點中安裝JDK是必須的,

1.2 放開相關埠
??在主從節點上都放開對埠3306的訪問,或者直接關閉防火墻,
# 臨時關閉
service iptables stop
service iptables start
# 永久關閉
chkconfig iptables on
chkconfig iptables off
# 查看防火墻狀態
service iptables status
1.3 root賬號
??MyCat是我們的資料庫中間件,那么MyCat必然要能夠訪問對應的主從資料庫,所以在主從資料庫中我們需要分別創建訪問的賬號,
grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;
flush privileges;
2.安裝MyCat
2.1 下載安裝軟體
官網地址:http://www.mycat.io/
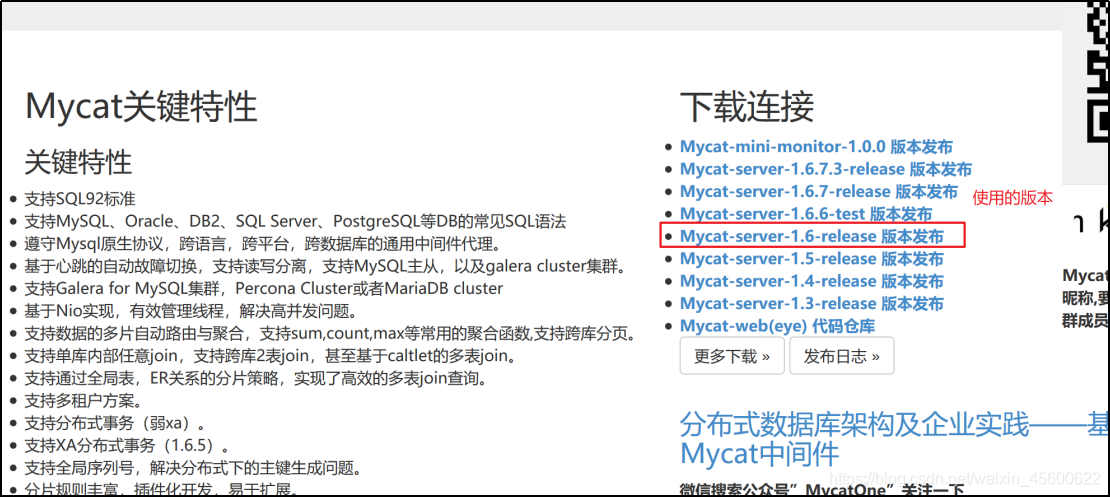
2.2 上傳解壓安裝
??將下載的檔案上傳到/usr/local目錄下,并解壓
2.3 目錄介紹
??解壓后的目錄結構如下:
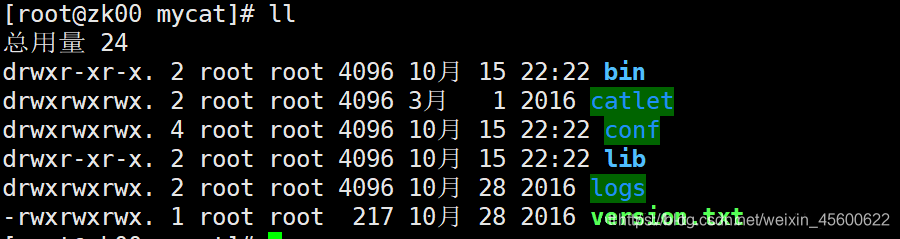
| 目錄 | 描述 |
|---|---|
| bin | 目錄里是啟動腳本 |
| conf | 目錄里是組態檔 |
| catlet | 為 MyCat 的一個擴展功能 |
| lib | 目錄里是 MyCat 和它的依賴 jar |
| logs | 目錄里是 console.log 用來保存控制臺日志,和 MyCat.log 用來保存 MyCat 的 log4j日志 |
二、相關組態檔介紹
??MyCat的架構其實很好理解,MyCat是代理,MyCat后面就是物理資料庫,和Web服務器的 Nginx類似,對于使用者來說,訪問的都是 MyCat,不會接觸到后端的資料庫,
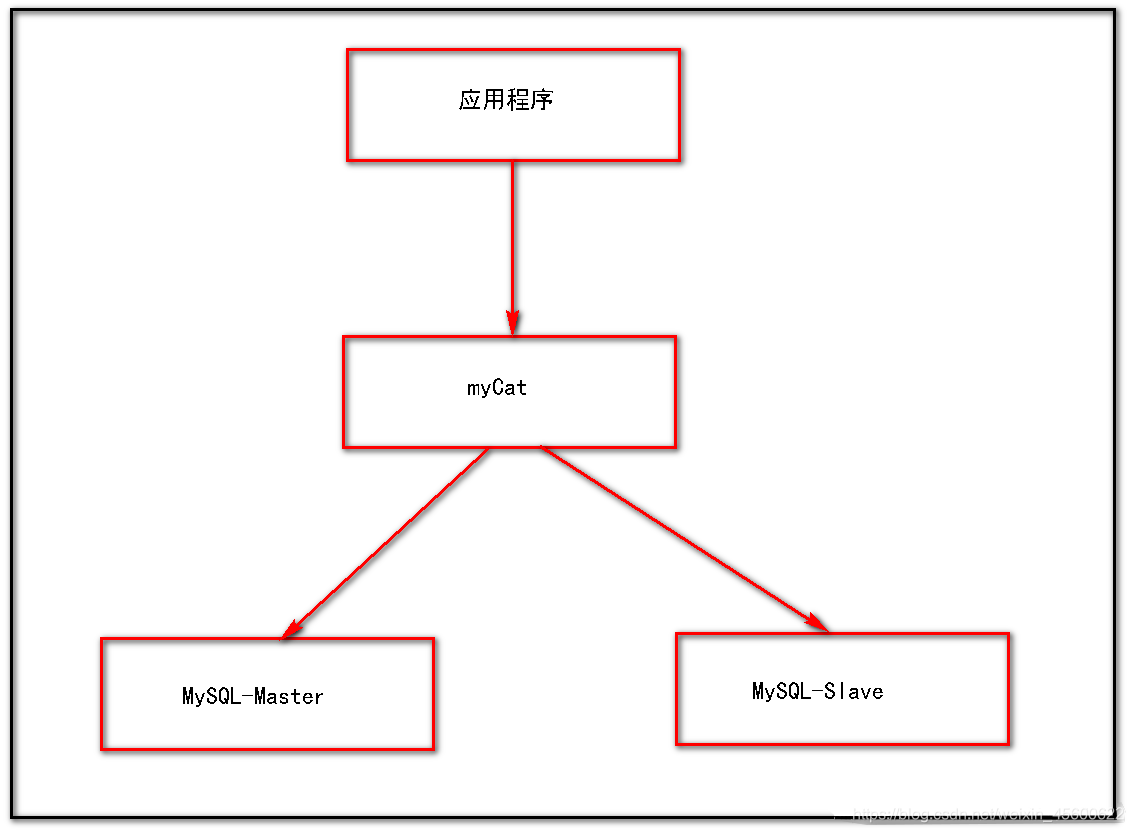
注意:MyCat的主要組態檔都在conf目錄下,我們給大家來介紹下介個核心的組態檔
| 組態檔 | 說明 |
|---|---|
| server.xml | MyCat 的組態檔,設定賬號、引數等 |
| schema.xml | MyCat 對應的物理資料庫和資料庫表的配置 |
| rule.xml | MyCat 分片(分庫分表)規則 |
2.1 server.xml
??server.xml是用來配置賬號,引數及相關操作權限的檔案,下面是給檔案的簡要內容,去掉了相關的注釋
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="useSqlStat">0</property>
<property name="useGlobleTableCheck">0</property>
<property name="sequnceHandlerType">2</property>
<property name="processorBufferPoolType">0</property>
<property name="handleDistributedTransactions">0</property>
<property name="useOffHeapForMerge">1</property>
<property name="memoryPageSize">1m</property>
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<property name="systemReserveMemorySize">384m</property>
<property name="useZKSwitch">true</property>
</system>
<!-- 全域SQL防火墻設定 -->
<!--
<firewall>
<whitehost>
<host host="127.0.0.1" user="mycat"/>
<host host="127.0.0.2" user="mycat"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
-->
<user name="root">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<!-- 表級 DML 權限設定 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
system標簽中設定的是系統級別的相關引數,參考源檔案中的注釋即可能看懂,初始默認即可
user標簽是我們要注意的地方,MyCat 中的用戶,用戶可以訪問的邏輯庫,可以訪問的邏輯表,服務的埠號等
說明:上面的默認的配置表示 創建的有兩個用戶root和user賬號
??root 賬號,密碼是123456,對應的邏輯庫是 TESTDB
??user 賬號,密碼是user,對應的邏輯庫是 TESTDB,權限是只讀
注釋掉的privileges 表示root用戶的操作權限
| 引數 | 說明 | 事例 |
|---|---|---|
| dml | insert,update,select,delete | 0000 |
dml 權限順序為:insert(新增),update(修改),select(查詢),delete(洗掉),0000–> 1111,0 為禁止權限,1 為開啟權限,
2.2 schema.xml
??schema.xml 是最主要的組態檔,首先看默認的組態檔
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="mod-long" />
<table name="employee" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-intfile" />
<table name="customer" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id" parentKey="id">
<childTable name="order_items" joinKey="order_id" parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id" parentKey="id" />
</table>
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
<readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" />
</writeHost>
<writeHost host="hostS1" url="localhost:3316" user="root"
password="123456" />
</dataHost>
</MyCat:schema>
2.2.1 主要節點介紹
??在組態檔中可以定義讀寫分離,邏輯庫,邏輯表,dataHost,dataNode 等資訊.
| 節點 | 描述 |
|---|---|
| schema | 配置邏輯庫,name 與 server.xml 中 schema 對應 |
| dataNode | 定義資料節點的標簽,也就是分庫相關配置 |
| dataHost | 物理資料庫,真正存盤資料的資料庫 |
2.2.2 節點及相關屬性介紹
2.2.2.1 schema
屬性name
邏輯庫名稱
屬性checkSQLschema
是否檢測 SQL 語法中的 schema 資訊. 如: MyCat邏輯庫名稱 A, dataNode 名稱 B
SQL : select * from A.table;
checkSQLschema 值是 true, MyCat發送到資料庫的 SQL 是 select * from table;
checkSQLschema 只是 false,MyCat發送的資料庫的 SQL 是 select * from A.table;
屬性sqlMaxLimit
MyCat 在執行 SQL 的時候,如果 SQL 陳述句中沒有 limit 子句.自動增加 limit 子句. 避免一次
性得到過多的資料,影響效率. limit子句的限制數量默認配置為100.如果 SQL中有具體的 limit
子句,當前屬性失效.
SQL : select * from table . MyCat決議后: select * from table limit 100
SQL : select * from table limit 10 . MyCat 不做任何操作修改.
標簽 table
定義邏輯表的標簽
屬性 name
邏輯表名
屬性 dataNode
資料節點名稱. 即物理資料庫中的 database 名稱.多個名稱使用逗號分隔.
屬性 rule
分片規則名稱.具體的規則名稱參考 rule.xml 組態檔.
2.2.2.2 dataNode
屬性 name
資料節點名稱, 是定義的邏輯名稱,對應具體的物理資料庫 database
屬性 dataHost
參考 dataHost 標簽的 name 值,代表使用的物理資料庫所在位置和配置資訊.
屬性 database
在 dataHost 物理機中,具體的物理資料庫 database 名稱.
2.2.2.3 dataHost
屬性 name
定義邏輯上的資料主機名稱
屬性 maxCon/minCon
最大連接數, max connections
最小連接數, min connections
屬性 dbType
資料庫型別 : mysql 資料庫
屬性 dbDriver
資料庫驅動型別, native,使用 MyCat提供的本地驅動.
dataHost 子標簽 writeHost
寫資料的資料庫定義標簽. 實作讀寫分離操作.
屬性 host
資料庫命名
屬性 url
資料庫訪問路徑
屬性 user
資料庫訪問用戶名
屬性 password
訪問用戶密碼
writeHost 子標簽 readHost
屬性 host
資料庫命名
屬性 url
資料庫訪問路徑
屬性 user
資料庫訪問用戶名
2.3 rule.xml
??用于定義分片規則的組態檔,mycat 默認的分片規則: 以 500 萬為單位,實作分片規則.邏輯庫 A 對應 dataNode - db1 和 db2. 1-500 萬保存在 db1 中, 500 萬零 1 到 1000 萬保存在 db2 中,1000 萬零 1 到 1500 萬保存在 db1 中.依次類推.
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
<function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默認是0 -->
<property name="count">2</property><!-- 要分片的資料庫節點數量,必須指定,否則沒法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一個實際的資料庫節點被映射為這么多虛擬節點,默認是160倍,也就是虛擬節點數是物理節點數的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 節點的權重,沒有指定權重的節點默認是1,以properties檔案的格式填寫,以從0開始到count-1的整數值也就是節點索引為key,以節點權重值為值,所有權重值必須是正整數,否則以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于測驗時觀察各物理節點與虛擬節點的分布情況,如果指定了這個屬性,會把虛擬節點的murmur hash值與物理節點的映射按行輸出到這個檔案,沒有默認值,如果不指定,就不會輸出任何東西 -->
</function>
<function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property><!-- 要分片的資料庫節點數量,必須指定,否則沒法分片 -->
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
</mycat:rule>
簡化版
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
</mycat:rule>
由上我們可以發現在rule.xml檔案中,核心的標簽就兩個tableRule 和function,我們分別來介紹下
2.3.1 tableRule
??是用來宣告table的分片規則的,相關屬性及標簽的含義如下
| 節點 | 描述 |
|---|---|
| name | 屬性指定唯一的名字,用于標識不同的分片規則,內嵌的 |
| rule | 標簽則指定對物理表中的哪一列進行拆分和使用什么分片演算法 |
| columns | 指定要拆分的列名字 |
| algorithm | 使用 function 標簽中的 name 屬性,連接表規則和具體分片演算法, table 標簽內使用,讓邏輯表使用這個規則進行分片 |
2.3.2 function
??指定分片規則的演算法的具體實作
| 節點 | 描述 |
|---|---|
| name | 指定演算法的名字 |
| class | 制定分片演算法具體的類名字 |
| property | 為具體演算法需要用到的一些屬性 |
ok~MyCat的安裝及相關配置介紹就介紹到此,下篇我們介紹通過MyCat來具體實作讀寫分離
關注微信公眾號【程式員的夢想】,專注于Java,SpringBoot,SpringCloud,微服務,Docker以及前后端分離等全堆疊技術,

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/115796.html
標籤:MySQL
上一篇:mysql 寫入中文亂碼