1.底層存盤結構
- 陣列需要一塊連續的記憶體空間來存盤, 對記憶體的要求比較高,如果我們申請一個 100MB 大小的陣列,當記憶體中沒有連續的、足夠大的存盤空間時,即便記憶體的剩余總可用空間大于 100MB,仍然會申請失敗,
- 而鏈表恰恰相反,它并不需要一塊連續的記憶體空間,它通過“指標”將一組零散的記憶體塊串聯起來使用,所以如果我們申請的是 100MB 大小的鏈表,根本不會有問題,
2.鏈表分類
2.1 單鏈表
將所有的結點串起來,每個鏈表的結點除了存盤資料之外,還需要記錄鏈上的下一個結點的地址,如圖所示,我們把這個記錄下個結點地址的指標叫作后繼指標 next,

-
頭結點 & 尾結點
-
我們習慣性地把第一個結點叫作頭結點,把最后一個結點叫作尾結點
-
頭結點用來記錄鏈表的基地址,有了它,我們就可以遍歷得到整條鏈表
-
尾結點特殊的地方是:指標不是指向下一個結點,而是指向一個空地址 NULL,表示這是鏈表上最后一個結點
-
-
哨兵節點:為了操作的便利,有時會將頭結點設定為一個存盤資料為null的節點
2.2 回圈鏈表
回圈鏈表是一種特殊的單鏈表,實際上,回圈鏈表也很簡單,它跟單鏈表唯一的區別就在尾結點,
- 單鏈表的尾結點指標指向空地址,表示這就是最后的結點了,
- 回圈鏈表的尾結點指標是指向鏈表的頭結點,它像一個環一樣首尾相連,所以叫作“回圈”鏈表
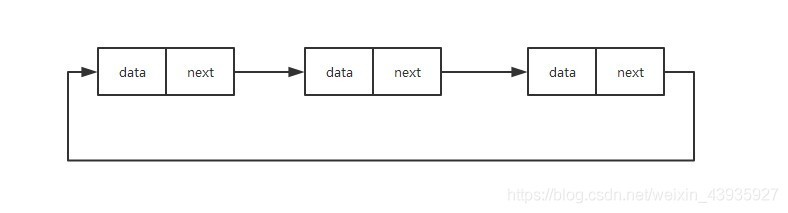
2.3 雙向鏈表
雙向鏈表需要額外的兩個空間來存盤后繼結點和前驅結點的地址,所以,如果存盤同樣多的資料,雙向鏈表要比單鏈表占用更多的記憶體空間,雖然兩個指標比較浪費存盤空間,但可以支持雙向遍歷,這樣也帶來了雙向鏈表操作的靈活性,
從結構上來看,雙向鏈表可以支持 O(1) 時間復雜度的情況下找到前驅結點,正是這樣的特點,也使雙向鏈表在某些情況下的插入、洗掉等操作都要比單鏈表簡單、高效,

2.4 雙向回圈鏈表
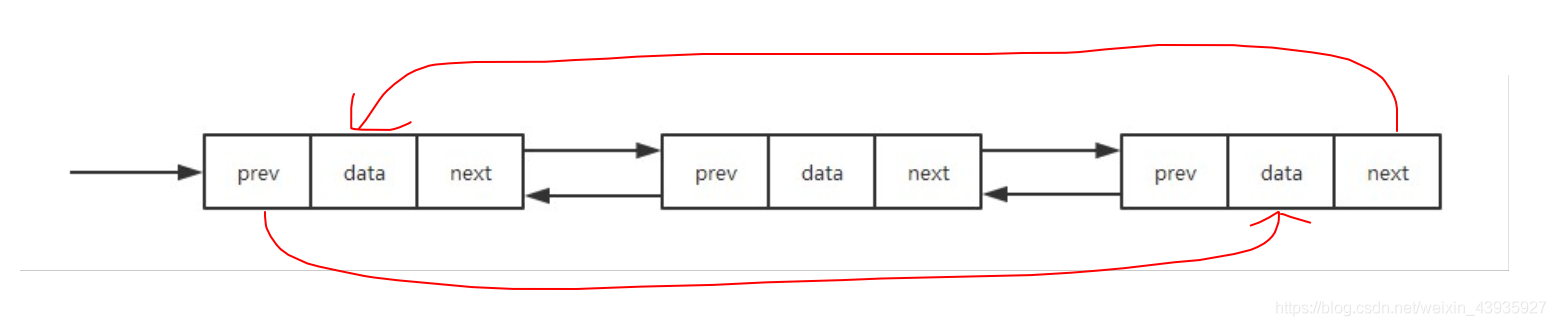
3.操作時間復雜度分析
3.1 插入 & 洗掉(理論)
- 在進行陣列的插入、洗掉操作時,為了保持記憶體資料連續性,需要做大量的資料搬移,所以時間復雜度是O(n)
- 在鏈表中插入或者洗掉一個資料,我們并不需要為了 保持記憶體的連續性而搬移結點,因為鏈表的存盤空間本身就不是連續的,所以,在鏈表中插入和洗掉一個資料是非常快速的,我們只需要考慮相鄰結點的指標改變,所以對應的時間復雜度是 O(1)
3.2 插入 & 洗掉(實際)
插入和洗掉實際上有以下兩種情況:
- 洗掉“某個給定值”的結點 == 插入節點到給定值后
- 不管是單鏈表還是雙向鏈表,為了查找到值等于給定值的結點,都需要從頭結點開始一個一個依次遍歷對比,直到找到值等于給定值的結點,然后再通過我前面講的指標操作將其洗掉,
- 盡管單純的洗掉操作時間復雜度是 O(1),但遍歷查找的時間是主要的耗時點,對應的時間復雜度為 O(n),根據時間復雜度分析中的加法法則,洗掉值等于給定值的結點對應的鏈表操作的總時間復雜度為 O(n)
- 洗掉給定指標指向的結點,即要洗掉node已經給定 == 插入給定node后
- 單鏈表:我們已經找到了要洗掉的結點,但是洗掉某個結點 q 需要知道其前驅結點,而單鏈表并不支持直接獲取前驅結點,所以,為了找到前驅結點,我們還是要從頭結點開始遍歷鏈表,直到 p->next=q,說明 p 是 q 的前驅結點,所以,單鏈表洗掉操作需要 O(n) 的時間復雜度
- 雙向鏈表:因為雙向鏈表中的結點已經保存了前驅結點的指標,不需要像單鏈表那樣遍歷,所以,雙向鏈表只需要在 O(1) 的時間復雜度內就搞定了
3.3 隨機訪問
- 鏈表要想隨機訪問第 k 個元素,就沒有陣列那么高效了(根據首地址和下標,通過尋址公式就能直接計算出對應的記憶體地址)
- 鏈表中的資料并非連續存盤的,需要根據指標一個結點一個結點地依次遍歷,直到找到相應的結點,
- 單鏈表:從頭到尾進行遍歷
- 雙向鏈表:我們可以記錄上次查找的位置 p,每次查詢時,根據要查找的值與 p 的大小關系,決定是往前還是往后查找,所以平均只需要查找一半的資料
4.鏈表 VS 陣列
4.1 操作時間復雜度
| 陣列 | 鏈表 | |
|---|---|---|
| 插入洗掉 | O(n) | O(1) |
| 隨機訪問 | O(1) | O(n) |
4.2 cpu快取預讀
- 陣列簡單易用,在實作上使用的是連續的記憶體空間,可以借助 CPU 的快取機制,預讀陣列中的資料,所以訪問效率更高
- 鏈表在記憶體中并不是連續存盤,所以對 CPU 快取不友好,沒辦法有效預讀
4.3 動態擴容(重點)
- 陣列的缺點是大小固定,一經宣告就要占用整塊連續記憶體空間,
- 如果宣告的陣列過大,系統可能沒有足夠的連續記憶體空間分配給它,導致“記憶體不足(out of memory)”
- 如果宣告的陣列過小,則可能出現不夠用的情況,這時只能再申請一個更大的記憶體空間,把原陣列拷貝進去,非常費時
- 雖然ArrayList底層實作了動態擴容,但假設ArrayList 存盤了了 1GB 大小的資料,這個時候已經沒有空閑空間了,當我們再插入資料的時候,ArrayList 會申請一個 1.5GB 大小的存盤空 間,并且把原來那 1GB 的資料拷貝到新申請的空間上
- 鏈表本身沒有大小的限制,天然地支持動態擴容,我覺得這也是它與陣列最大的區別
4.4 記憶體利用率
- 一般情況下鏈表可以動態擴容所以比一般陣列記憶體利用率高,但若陣列在已知要存盤元素多少的情況下初始化,記憶體很少會被浪費,陣列更優
- 鏈表不適用于記憶體要求嚴苛的場景
- 鏈表中的每個結 點都需要消耗額外的存盤空間去存盤一份指向下一個結點的指標,所以記憶體消耗會翻倍,但是對于比較大的Node,這點存指標的記憶體可以忽略
- 對鏈表進行頻繁的插入、洗掉操作,還會導致頻繁的記憶體申請和釋放,容易造成記憶體碎片,如果是 Java 語言,就有可能會導致頻繁的 GC(Garbage Collection,垃圾回收)
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/116559.html
標籤:其他
上一篇:虛擬幣的影響