Kylin on HBase 方案經過長時間的發展已經比較成熟,但也存在著局限性,因此,Kyligence 推出了 Kylin on Parquet 方案(了解詳情戳此處),通過標準資料集測驗,與仍采用 Kylin on HBase 方案的 Kylin 3.0 相比,Kylin on Parquet 的構建引擎性能有了很大的提升,對于復雜查詢也有更好的性能表現,
本篇文章主要通過使用標準 SSB 資料集和 TPC-H 資料集,來分別獲取 Kylin on Parquet 和 Kylin 3.0 構建引擎以及查詢引擎的性能資料,然后進行對比分析,讓用戶們能夠更清楚地了解到當前 Kylin on Parquet 相對于 Kylin 3.0(仍采用 Kylin on HBase )的優勢和不足,
- SSB(Star Schema Benchmark)是一套用于測驗資料庫產品在星型模式下性能表現的基準測驗規范,也是 OLAP 領域經常會用到的資料集,
- TPC(Transaction Processing Performance Council,即事務處理性能委員會)有多種基準測驗體系,在這里我們使用了 TPC-H 資料集,使用 TPC-H 的主要目的是測驗資料庫系統復雜查詢的回應時間,以此來評價特定查詢的決策支持能力,
Kyligence 公司研發了適用于 Kylin 的 SSB 和 TPC-H 資料集工具,并且包含了標準 SQL,原始碼倉庫地址如下:
- https://github.com/Kyligence/ssb-kylin
- https://github.com/Kyligence/kylin-tpch
01
測驗環境配置
Hadoop 集群:
- 4 個物理節點
- Yarn 佇列擁有 400G 記憶體和 128 個 CPU 核數
Kylin 3.0 使用的是 MapReduce 引擎,Kylin on Parquet 目前只支持內部定制版本的 Spark 引擎,定制版相對于社區版主要是做了性能方面的優化,其他方面與社區版 Spark 并沒有區別,
- Spark 原始碼倉庫https://github.com/Kyligence/spark/tree/2.4.1-kylin-r3
- Spark 二進制包下載https://download-resource.s3.cn-north-1.amazonaws.com.cn/osspark/spark-2.4.1-os-kylin-r3
02
構建性能對比
Over SSB
下面兩個圖分別表示構建時間和構建完成后占用存盤空間的對比,我們可以看到在 SSB 6000 萬和 9000 萬資料量下,新的構建引擎構建速度快了一倍,最終占用存盤空間也減少了接近一倍,
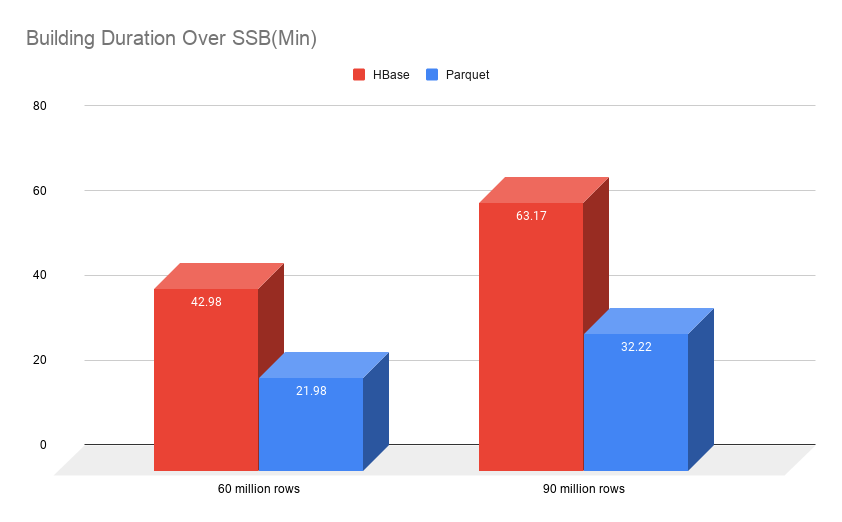
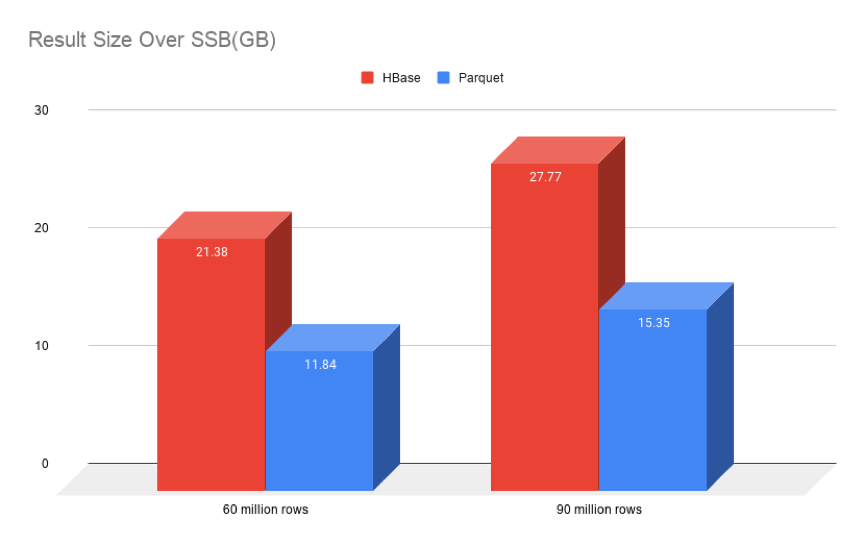
值得一提的是,Kylin on Parquet 最終構建的資料只包含 HDFS 上的資料,由于 Kylin on HBase cuboid 檔案構建完成之后 HDFS 上的檔案需要轉換為 HFile,而且為了 merge 準備,HDFS 上的資料默認是不會清除的,所以實際存盤還會多一倍空間;而使用 Parquet 后,只需要一份資料即可以用于查詢,也可以用于 segment 合并,所以總體對比,Kylin on Parquet 的占用空間大約只有 Kylin on HBase 存盤的 1/3 到 1/4 !
構建完成后前端頁面會顯示 Cube 的大小,如下圖所示:

△ Kylin on Parquet

△ Kylin 3.0
03
查詢性能對比
Kylin on Parquet 的查詢引擎會在第一次查詢的時候在 YARN 上創建一個常駐行程,專門用來處理查詢任務,所以第一次查詢會比較慢(初始化程序大約 20 秒),這里的測驗并沒有將第一次查詢時間統計在內,
最近一周,查詢引擎兼容性的問題也得到了進一步的修復,目前大部分 SQL 查詢包括 CountDistinct, TopN, Percentile 等目前都已經能夠支持,
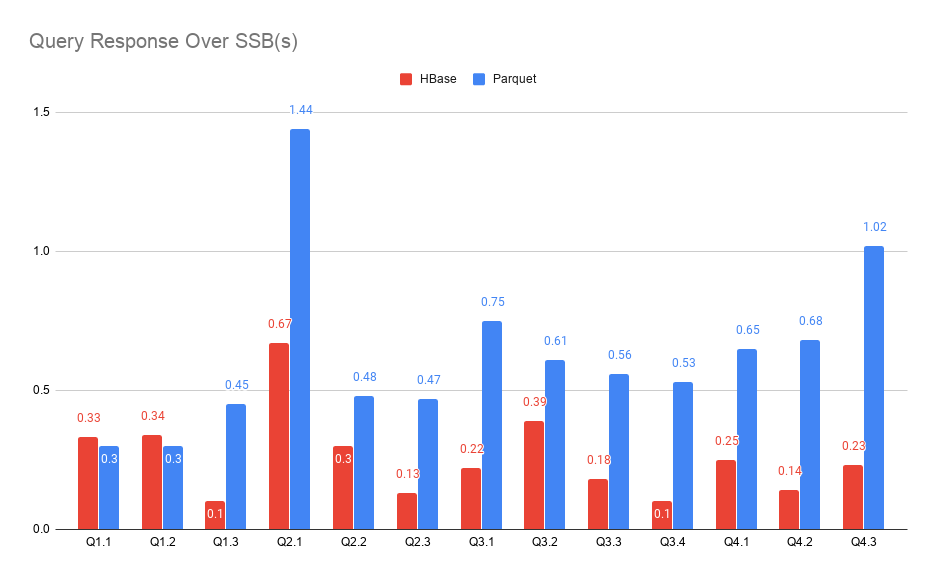
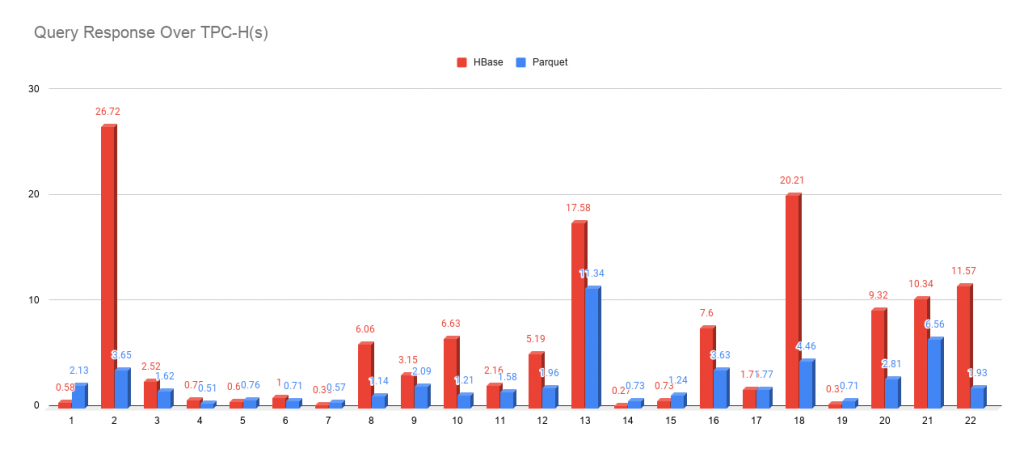
我們使用 SSB 資料集(9000萬行)和TPC-H(1200萬行)官方標準 SQL 進行查詢回應時間測驗,查詢回應時間越低,查詢引擎性能表現越好,兩個資料集的標準查詢 SQL 可以在文章開始提到的 SSB 和 TPC-H 資料集工具倉庫中找到,
Over SSB
從下圖中我們可以看到對于 SSB 資料集, Kylin on Parquet 查詢回應要比 Kylin 3.0 的要慢,但是大部分的查詢還是能夠在 1 秒內回傳,
Over TPC-H
因為 TPC-H 的主要目的是測驗資料庫系統復雜查詢的回應時間,所以 TPC-H 資料集的 SQL 更加復雜,要求更高,從下圖中可以看到 Kylin on Parquet 對查詢復雜的 SQL 處理時間更快,具有明顯優勢,
04
總結
通過 Kylin on Parquet 和 Kylin 3.0 查詢構建引擎的性能對比資料我們能夠看到,Kylin on Parquet 的構建引擎性能有了很大的提升,構建時間和存盤空間都減少了接近一倍,從 SSB 資料集查詢對比結果來看,查詢引擎對于簡單的查詢請求和 Kylin 3.0 有一定差距,但是大部分還是能夠做到秒級回應,而對于 TPC-H 資料集測驗使用的比較復雜的 SQL 來說,一般后計算會比較多,新的查詢引擎會有更好的性能表現,
目前, Kylin on Parquet 方案(了解詳情戳此處)還處在不斷完善的階段,歡迎大家來體驗,最后附上 GitHub 倉庫地址:https://github.com/Kyligence/kylin-on-parquet-v2.git,

大家有問題可以提 issue 和 pr,也歡迎大家加一下上圖的微信群,一起討論完善,
了解更多大資料資訊,點擊進入Kyligence官網
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/12631.html
標籤:大數據