PyTorch是什么?
這是一個基于Python的科學計算包,其旨在服務兩類場合:
- 替代numpy發揮GPU潛能
- 一個提供了高度靈活性和效率的深度學習實驗性平臺
第一個概念:張量tensors
pytorch下的張量類似于numpy下的陣列,并且張量也可用于在GPU上對程式進行加速
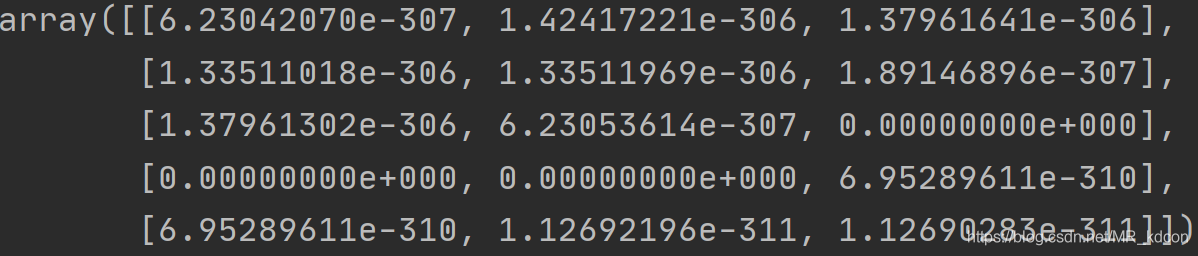
創建(5,3)的資料:
陣列:numpy.empty([5, 3])
張量:torch.empty(5, 3)
運行結果:
陣列
張量
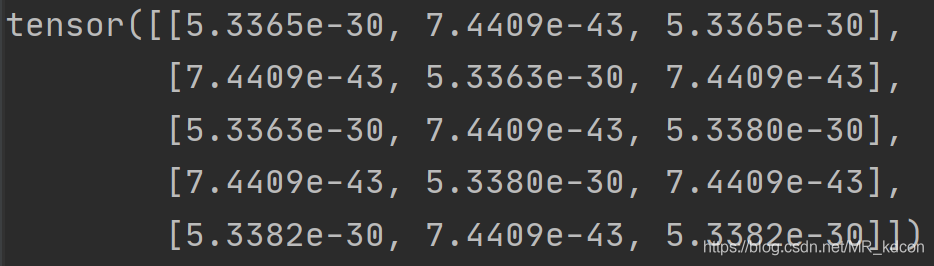
note:numpy下創建多維陣列,引數要是一個串列;torch下只需直接輸入數字;同理初始化張量的方式還有ones、zeros,
創建亂數
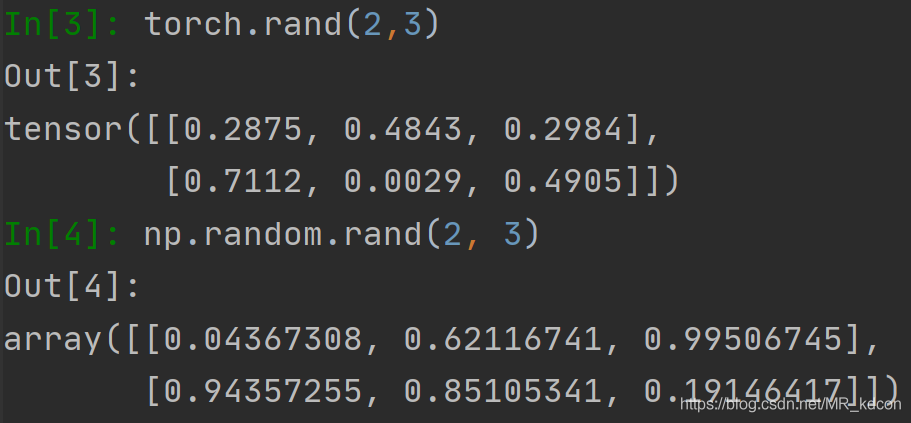
顯然,pytorch創建亂數更方便
創建指定內容的張量

張量和陣列的繼承
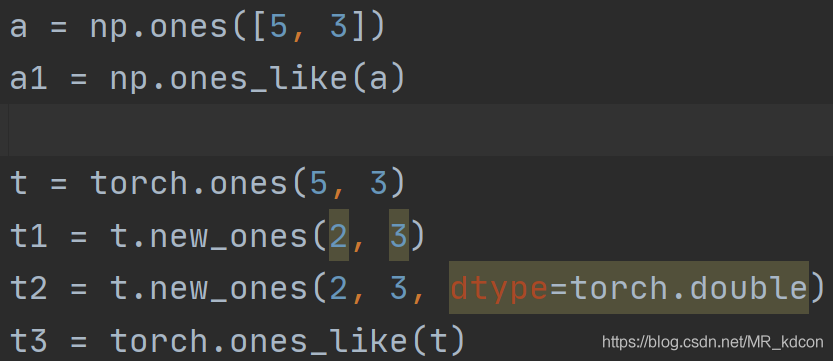
note:陣列沒有new_ones這種方法
張量和陣列創建正態分布的資料
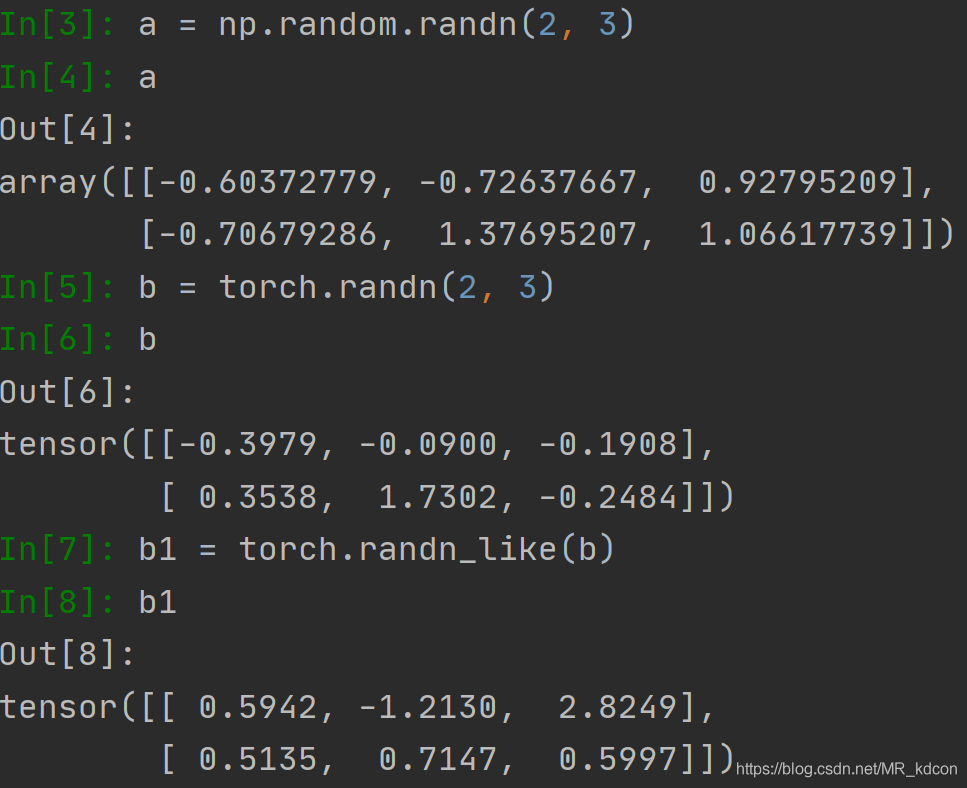
note:陣列沒有randn_like這種繼承方式
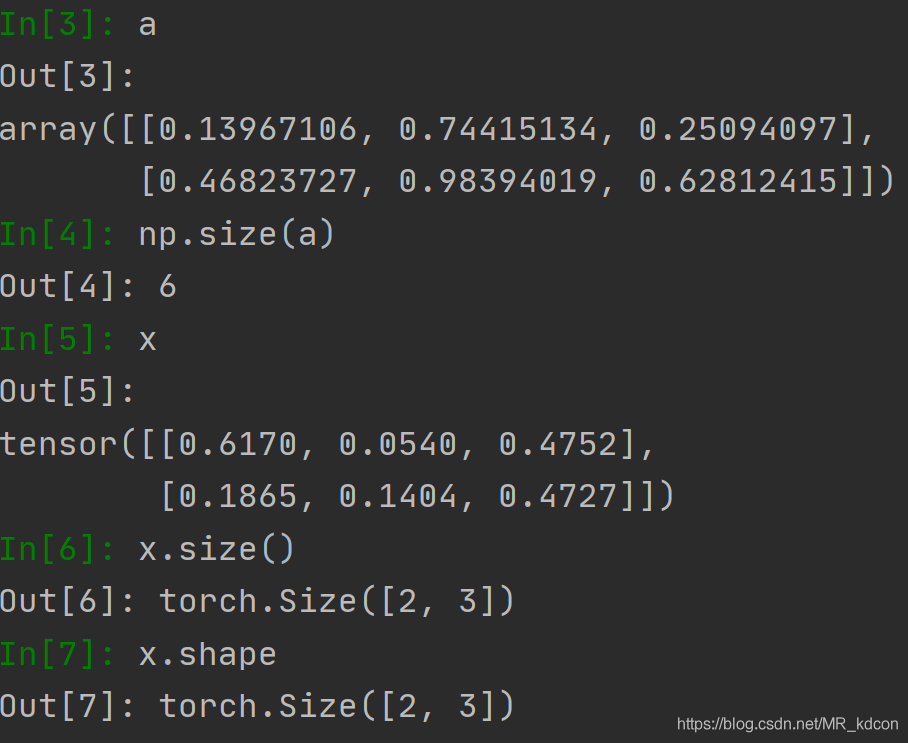
size的用法,
陣列和張量的用法是不一樣的,陣列回傳元素個數,張量回傳其規模,類似于shape
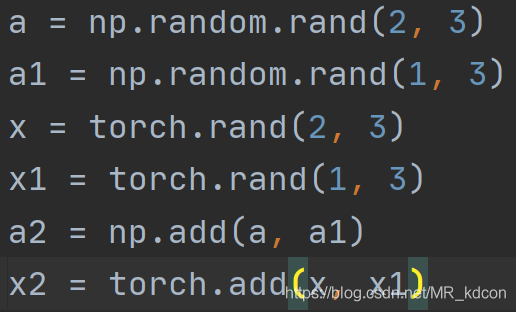
add用法(總算來了一個陣列和張量都一樣的用法)
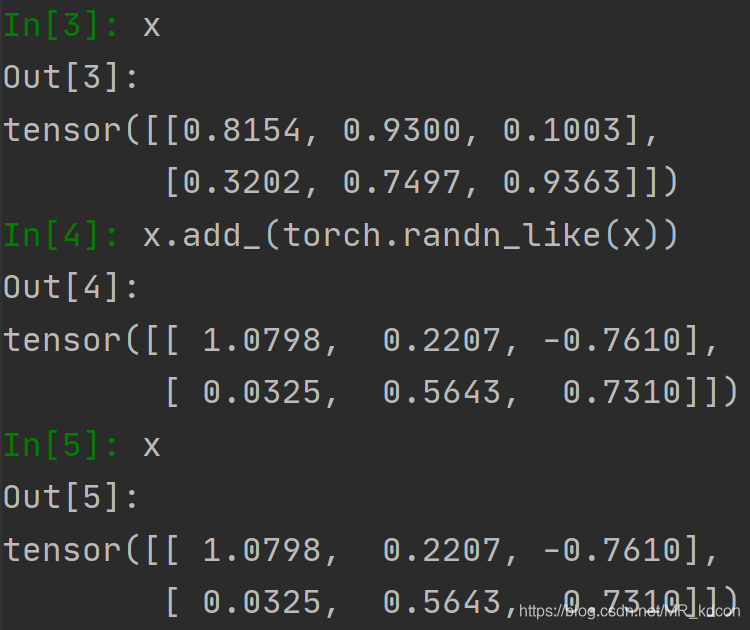
note:注意一下,使用add函式會生成一個新的tensor變數, add_ 函式會直接再當前tensor變數上進行操作,于函式名末尾帶有"_" 的函式都是會對Tensor變數本身進行操作的,add_是針對類的方法,而不能當函式呼叫
更改陣列或張量的規模reshape、view

note:對于張量,reshape和view都可以用,但陣列沒有view這個用法
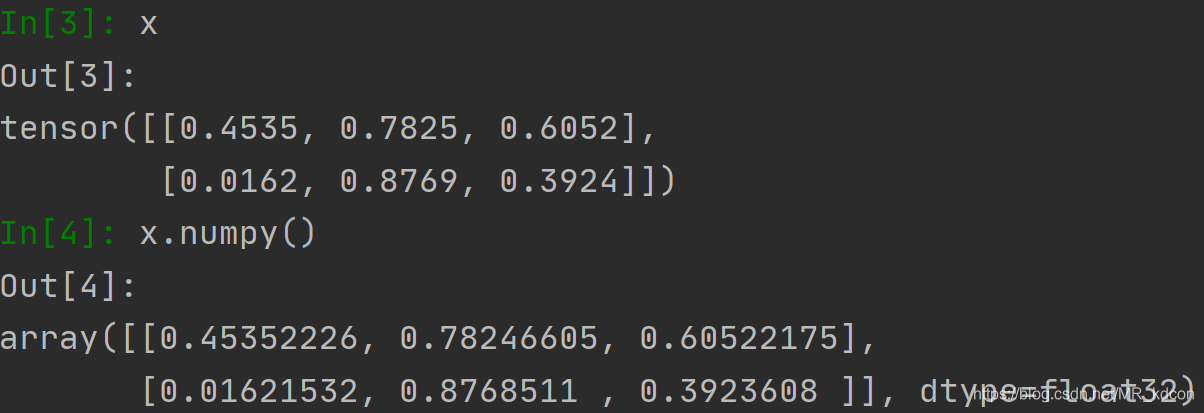
張量轉化為陣列
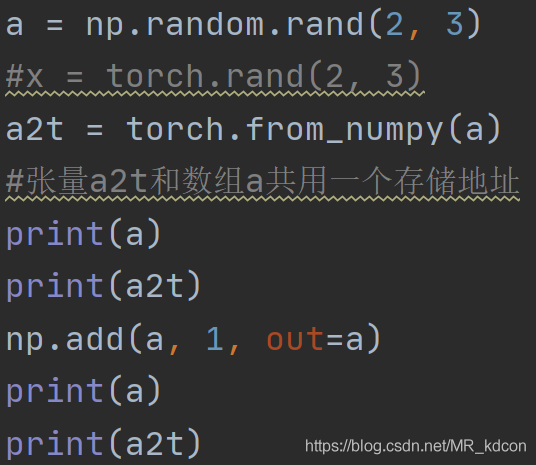
必須要強調一下,陣列和張量相互轉化時候,兩者共用一個存盤地址,因此兩者的相互轉化會非常快
張量轉為陣列
陣列轉為張量 呼叫函式from_numpy
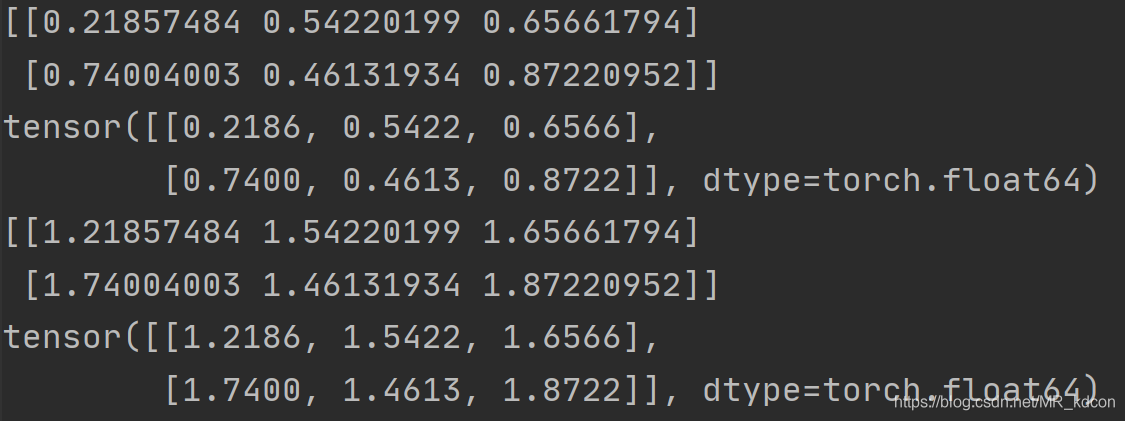
從最后4行結果也可以看出,從陣列轉化而來的張量和陣列共用一個地址
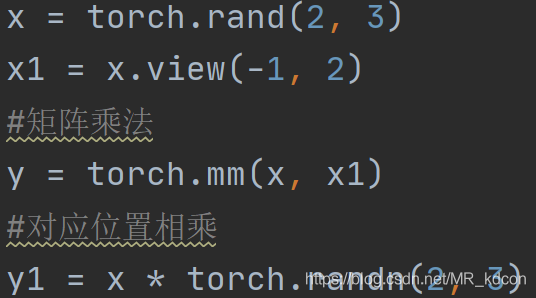
張量乘法
矩陣乘法、對應位置相乘
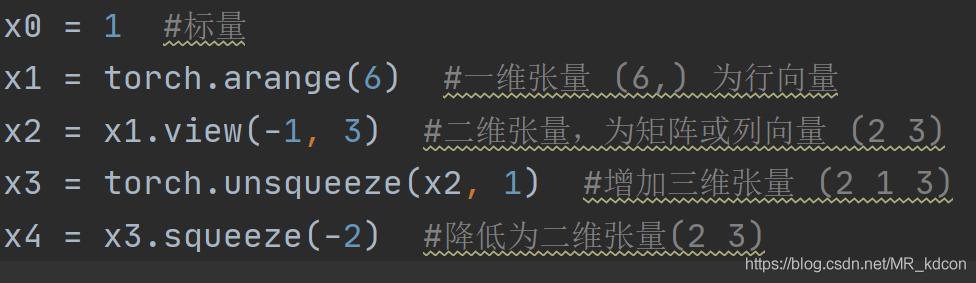
張量的增維和減維(擠維) unsqueeze、squeeze
torch.squeeze(input, dim=None, out=None)
1、當不給定dim時,將輸入張量形狀中的1 去除并回傳
2、當給定dim時,那么擠壓操作只在給定維度上,當這個給定的dim為1的時候,才有效,否則,函式是無效的
3、回傳張量與輸入張量共享記憶體,所以改變其中一個的內容會改變另一個,
4、dim為負數時候,-1表示最后一個,以此類推,如資料的維度(2,3,1),squeeze(input,-1)降低第二維成(2,3)
torch.unsqueeze(input, dim, out=None)
1、給定的dim是最終生成的dim,不如dim=2,是最終生成的張量中,第二維的大小為1
2、回傳張量與輸入張量共享記憶體,所以改變其中一個的內容會改變另一個,
3、dim為負數時候,-1表示最后一個,以此類推,如資料的維度(2,3),unsqueeze(input,-1)降低第二維成(2,3,1)
堆疊函式stack:用于擴展張量的維數
呼叫格式 d=torch.stack( (a,b,c) ,dim) 其中a、b、c為相同維數的張量,dim為指定的張量堆積方向,如abc分別為二維張量,dim=0,表明形成三維張量后第0維為堆積方向,
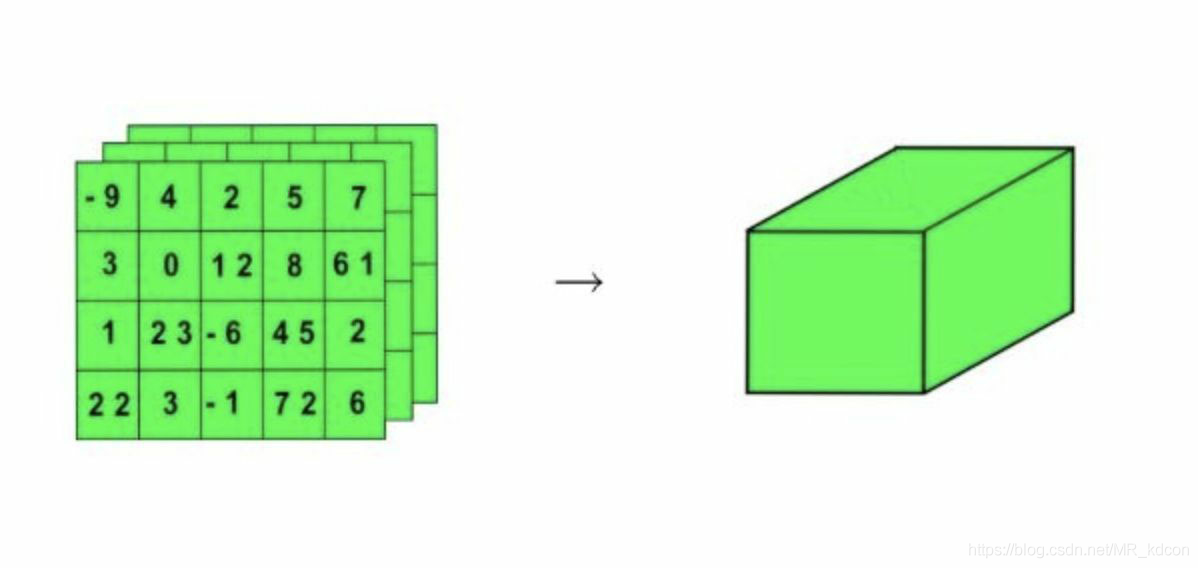
先來看一下三維的資料大致的形狀,三維是幾個2維資料按一定方向堆疊起來的,但不管怎么堆疊,可以始終看成一個長方體
以此類推
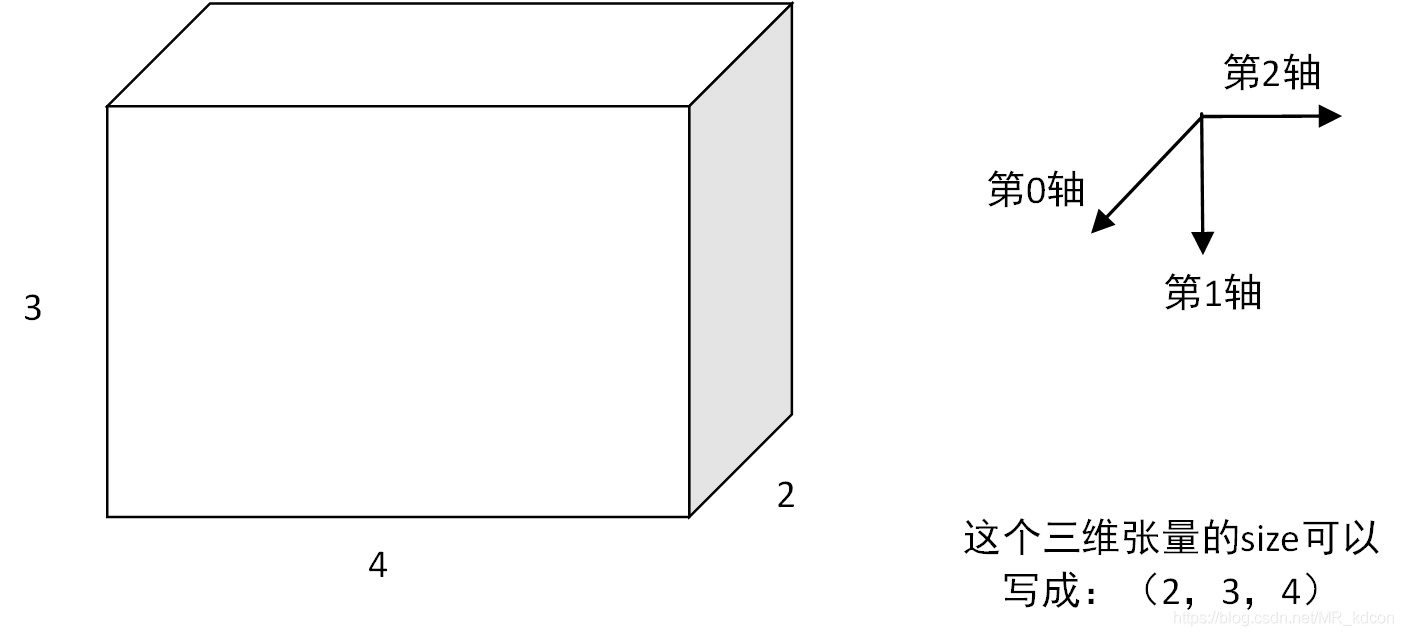
以具體例子來看
abc分別為(2,4)的二維張量
當dim=0,表明3張平面向著第0軸的方向堆疊,故容易得出最后的規模為(3,2,4)
然后用資料驗證下:
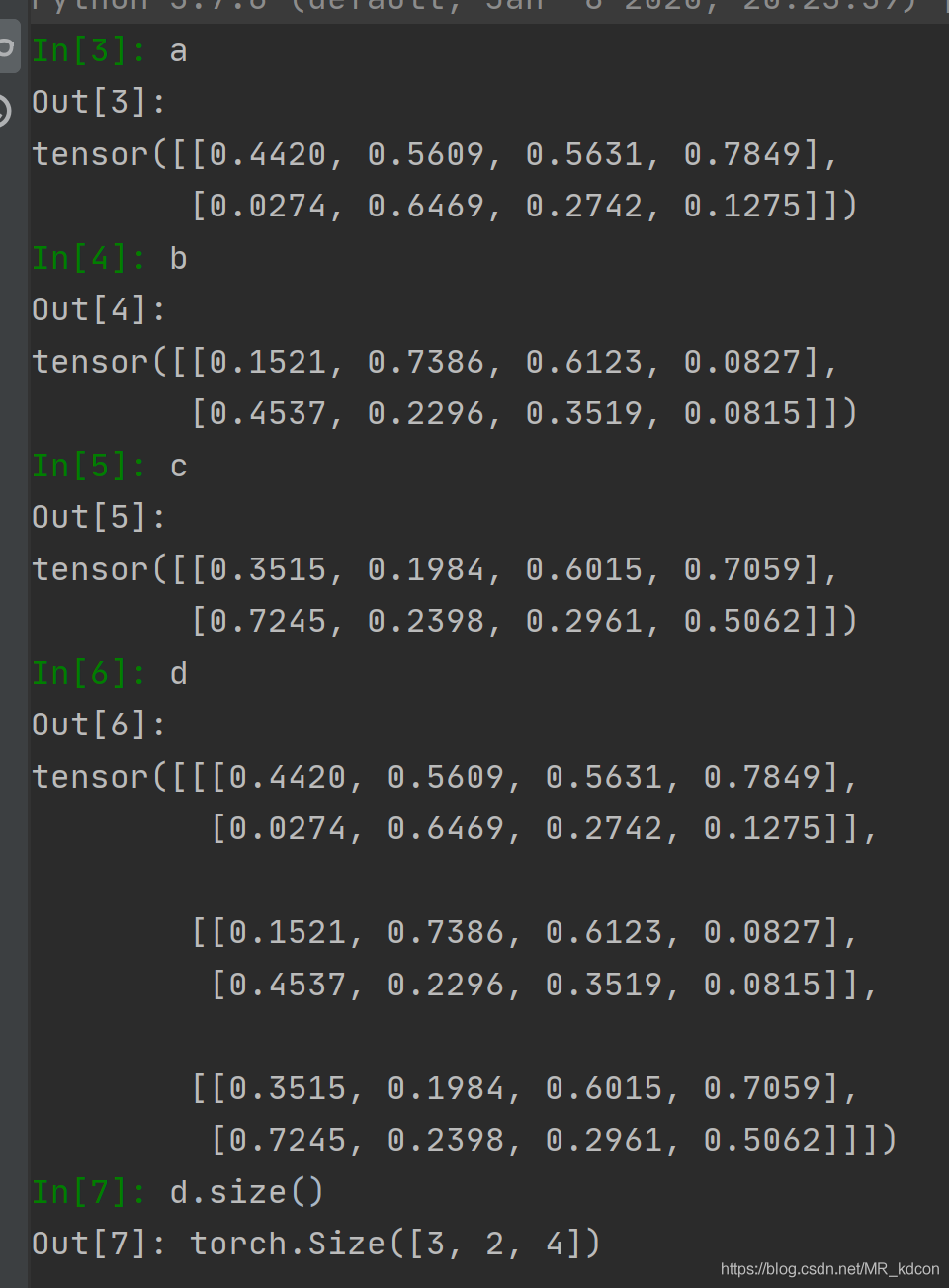
繼續,當dim=1時,表明3張平面按第1維的方向堆疊,易得出最后的規模(2,3,4)
驗證:
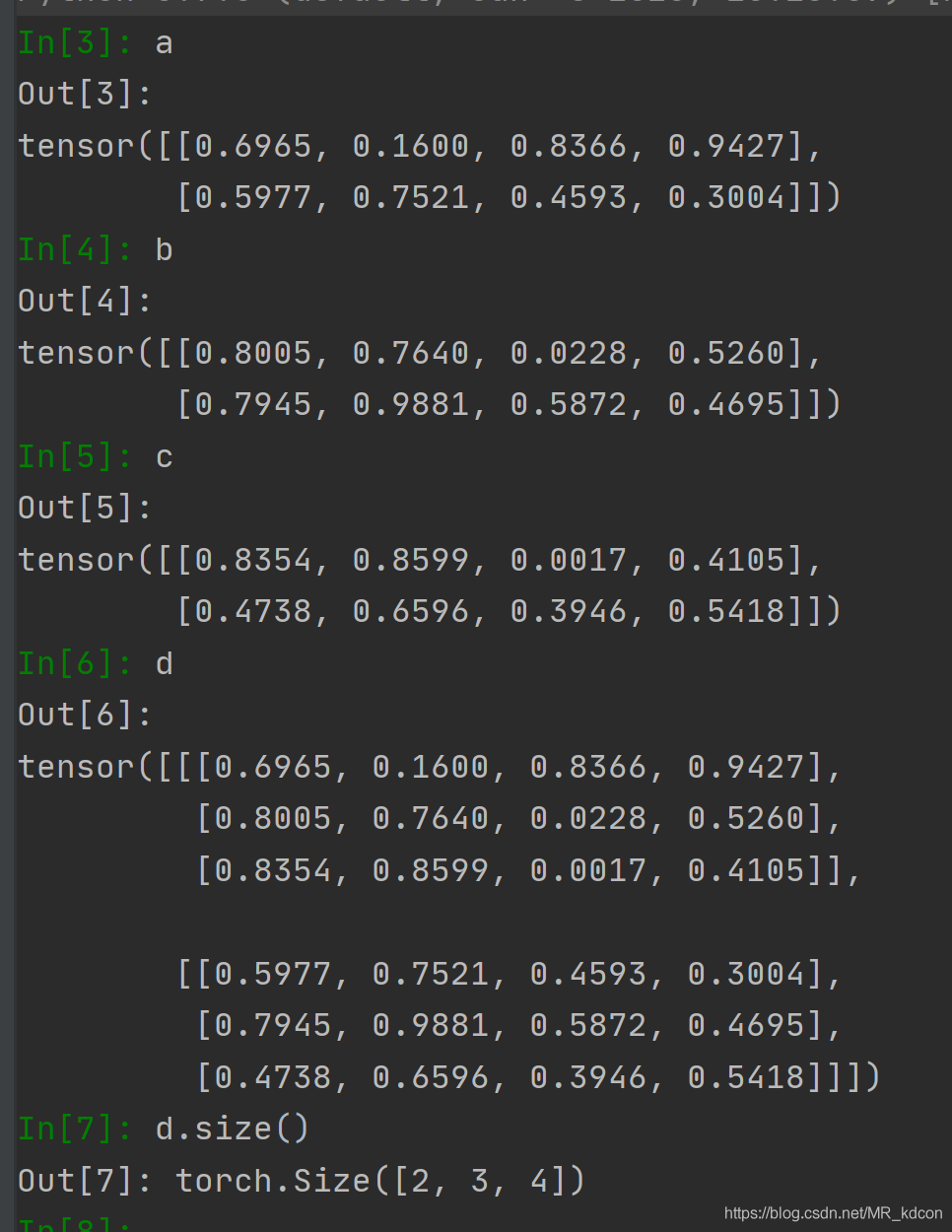
繼續,當dim=2,表明3個平面按第2軸的方向堆疊,容易的出最后的張量規模(2,4,3)
驗證:
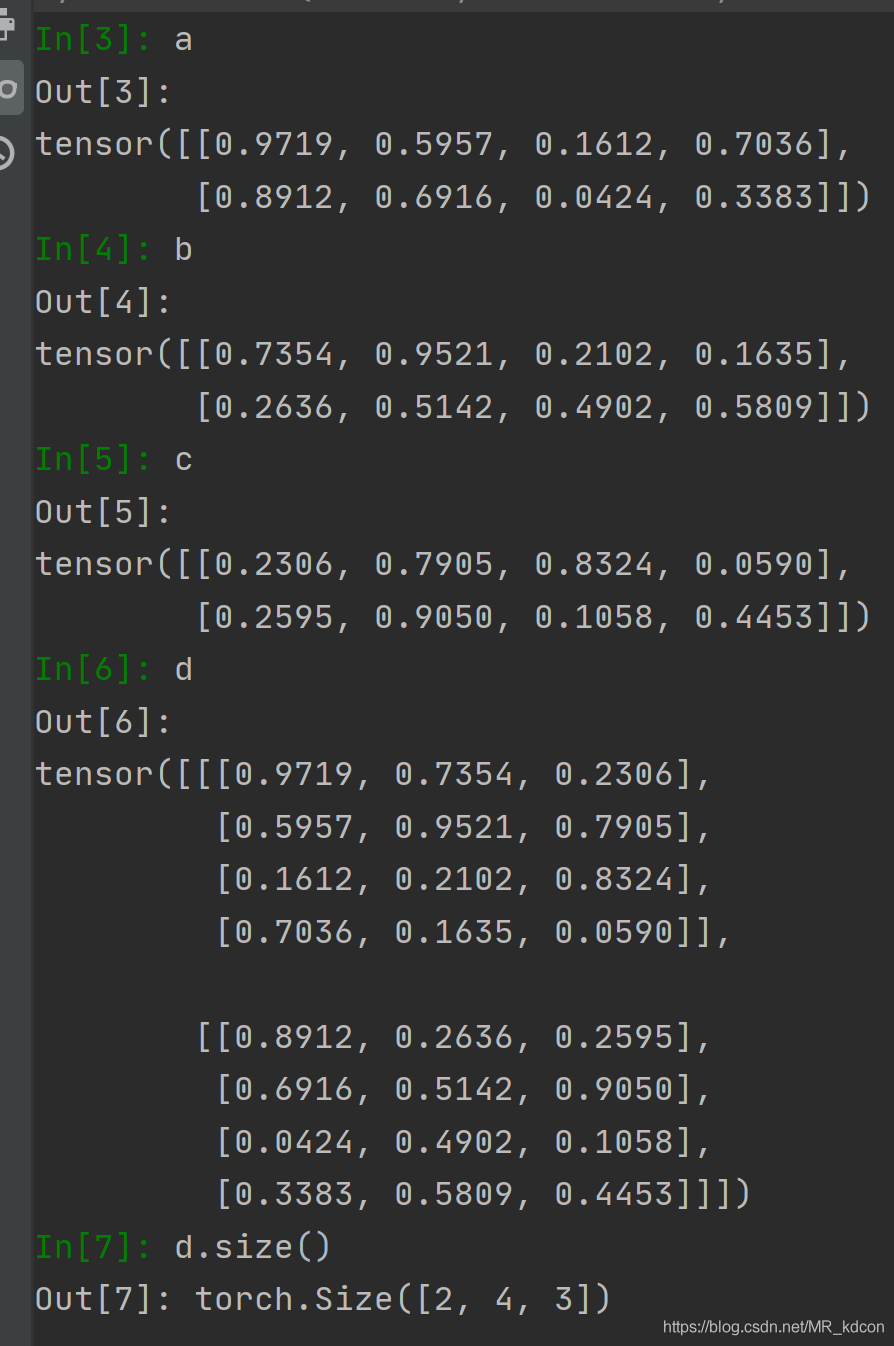
需要注意的是,d=torch.stack( (a,b,c) ,dim) ,表示堆疊的時候,按abc的順序依次向著堆疊方向放平面,順序不要錯了,
CUDA張量,將張量移送到GPU上進行運算
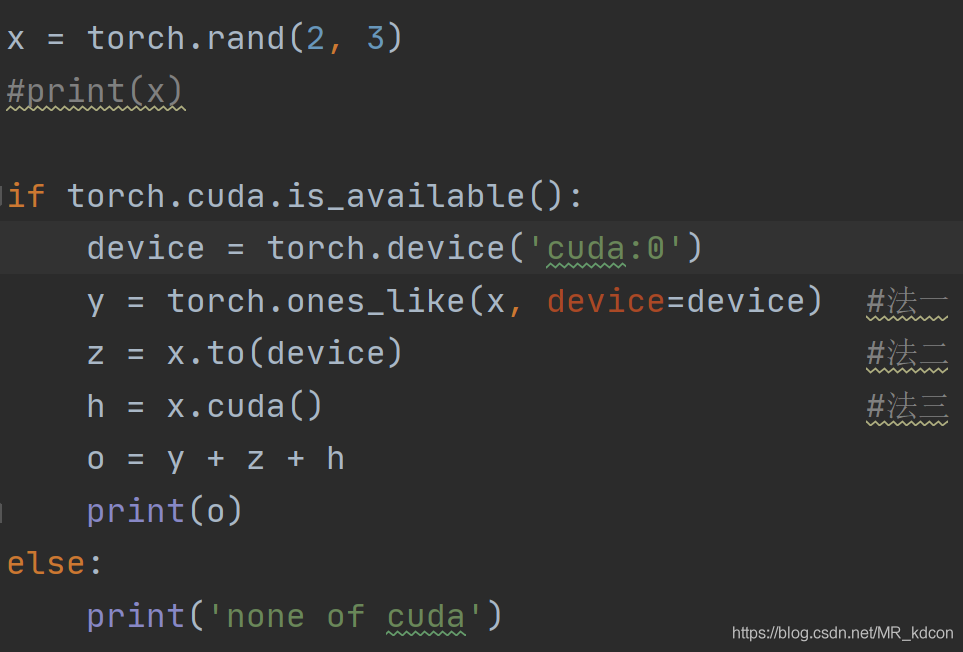
腳本的運行時間將比cpu下快很多
張量的復制
運用 clone、detach函式
clone():完全復制、開辟新記憶體,仍留在計算圖中,即參與梯度運算
detach():完全復制,和原變數為同一記憶體,但離開計算圖
clone().detach():完全復制,開辟新記憶體,離開計算圖
張量的求平均
運用mean函式,通過設定引數,該函式具有降維的作用,具體來看
呼叫格式:torch.mean(x, dim, keepdim)
x為求取平均的tensor物件,需要為float型,dim為指定維的反向求平均,keepdim為保持輸出維度,True時為指定的dim維度+1,False為默認值,即不保持輸入維度,即dim維度消失,實作了降維,
接下來看3個例子就可以明白這個函式具體怎么作業了:
第一個例子
x = torch.rand(4, 2, 3) #三維張量
x1 = torch.mean(x, dim=0, keepdim=True) #因為keepdim=True,所以x1維度保持3維
x2 = torch.mean(x1, dim=1, keepdim=True) #因為keepdim=True,所以x2維度保持3維
x3 = torch.mean(x2, dim=2, keepdim=True) #因為keepdim=True,所以x3維度保持3維
輸出
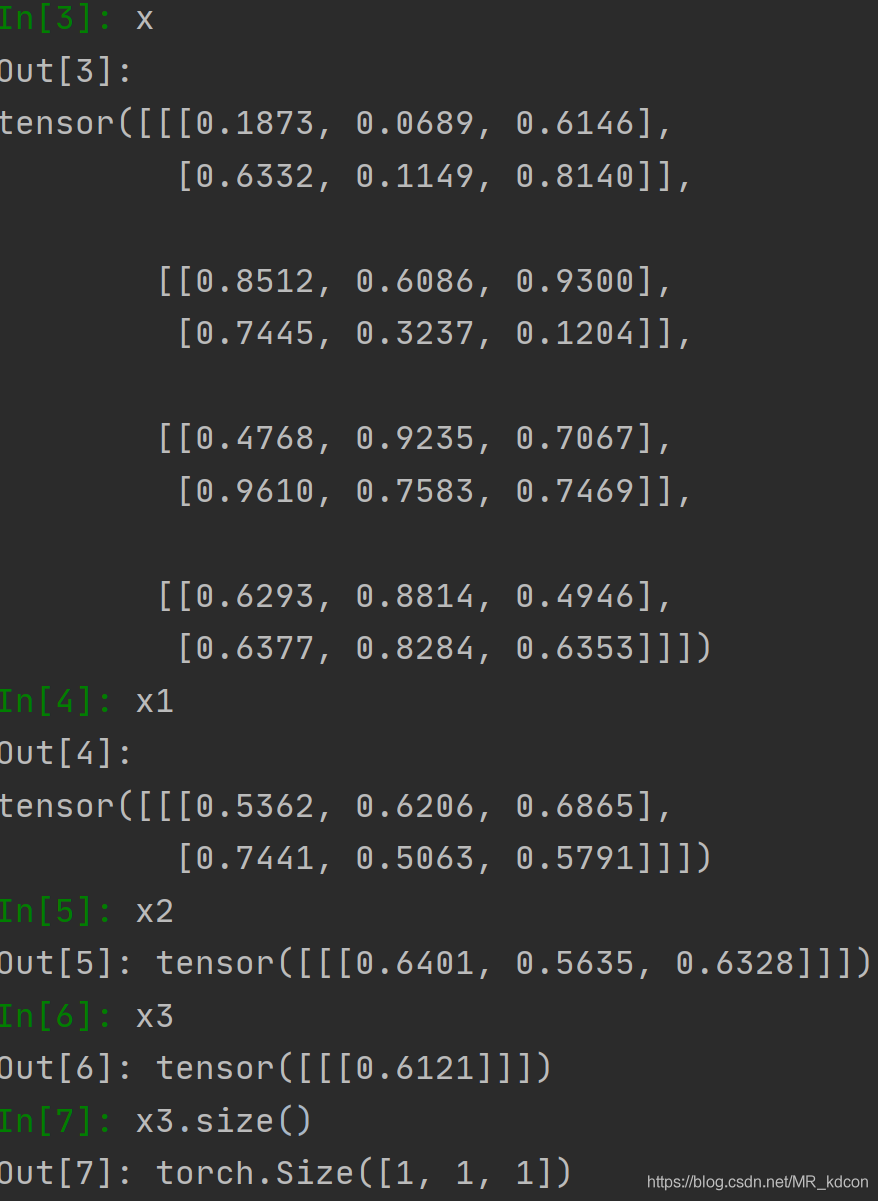
第二個例子
x = torch.rand(4, 2, 3)
x1 = torch.mean(x, dim=0) #keepdim=False,則x1為2維張量
x2 = torch.mean(x1, dim=0, keepdim=True)
x3 = torch.mean(x2, dim=1, keepdim=True)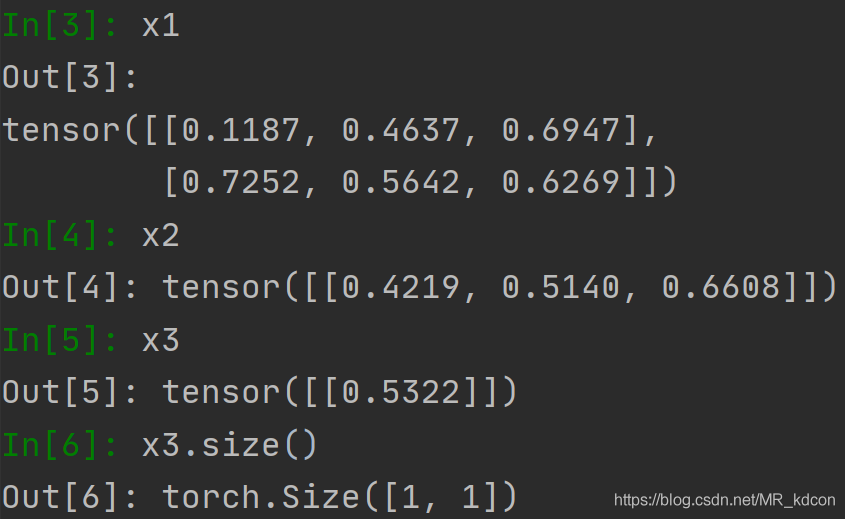
第三個例子
x4 = torch.mean(x),無任何引數,直接降成標量
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/152876.html
標籤:其他
上一篇:【Tensorflow slim API】影像分類訓練時在tensorboard中可視化每層卷積的輸出結果(便于觀察每層輸出!步驟清晰有用!)