作為全球新冠疫情資料的實時統計的權威,約翰斯—霍普金斯大學的實時資料一直是大家實時關注的,也是各大媒體的主要資料來源,在今天早上的相當一段長的時間,霍普金斯大學的全球疫情分布大屏中顯示,全球確診人數已經突破200萬,
有圖有真相
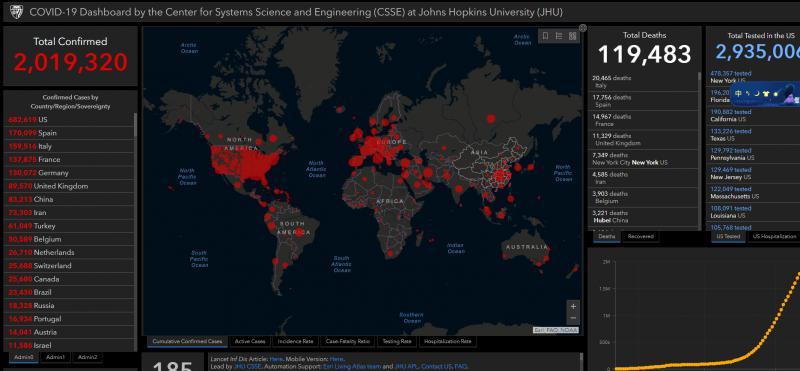
隨后相關媒體也進行了轉發,不過這個資料明顯波動太大,隨后該網站也修改了資料
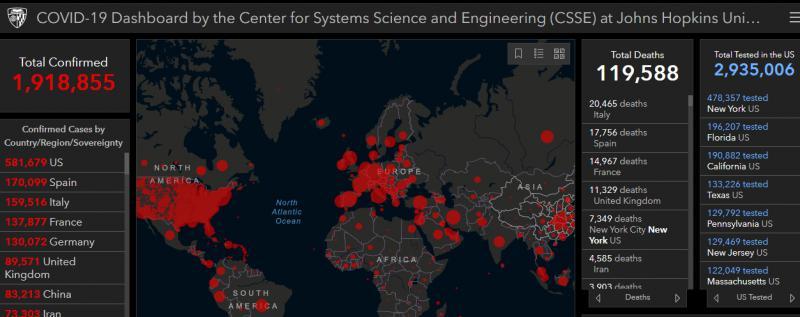
約翰斯·霍普金斯大學系統科學與工程中心就制作了“全球新冠病毒擴散地圖”,用于實時可視化和跟蹤報告的病例,于1月22日首次公開,
為了提高資料的實時性,資料的來源通過手動和自動獲取的方式,手動的方式出錯的概率還是很大的,如果我們可以通過實時流獲取資料的方式,就可以避免資料錯誤的問題,這其實是資料從一方到達另一方的資料是否準確的問題,也就是端到端的一致性,
這種訊息傳遞的定義叫做訊息傳遞語意:
我們要了解的是message delivery semantic 也就是訊息傳遞語意,
這是一個通用的概念,也就是訊息傳遞程序中訊息傳遞的保證性,
分為三種:
最多一次(at most once): 訊息可能丟失也可能被處理,但最多只會被處理一次,
可能丟失 不會重復
至少一次(at least once): 訊息不會丟失,但可能被處理多次,
可能重復 不會丟失
精確傳遞一次(exactly once): 訊息被處理且只會被處理一次,
不丟失 不重復 就一次
那么我們希望能做到精確傳遞一次(exactly once),雖然可能會付出一些性能的代價,
我們從幾個常見的流計算框架中,看一看都是如何解決端到端的一致性的問題,
1、Kafka
Kafka是最初由Linkedin公司開發,是一個分布式、支持磁區的(partition)、多副本的(replica),基于zookeeper協調的分布式訊息系統,它的最大的特性就是可以實時的處理大量資料以滿足各種需求場景:比如基于hadoop的批處理系統、低延遲的實時系統、storm/Spark流式處理引擎,web/nginx日志、訪問日志,訊息服務等等,用scala語言撰寫,Linkedin于2010年貢獻給了Apache基金會并成為頂級開源專案,
而kafka其實有兩次訊息傳遞,一次生產者發送訊息給kafka,一次消費者去kafka消費訊息,
兩次傳遞都會影響最終結果,
兩次都是精確一次,最終結果才是精確一次,
兩次中有一次會丟失訊息,或者有一次會重復,那么最終的結果就是可能丟失或者重復的,

一、Produce端訊息傳遞
這是producer端的代碼:
Properties properties = new Properties();
properties.put("bootstrap.servers", "kafka01:9092,kafka02:9092");
properties.put("acks", "all");
properties.put("retries", 0);
properties.put("batch.size", 16384);
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
for (int i = 1; i <= 600; i++) {
kafkaProducer.send(new ProducerRecord<String, String>("z_test_20190430", "testkafka0613"+i));
System.out.println("testkafka"+i);
}
kafkaProducer.close();
其中指定了一個引數acks 可以有三個值選擇:
0:producer完全不管broker的處理結果 回呼也就沒有用了 并不能保證訊息成功發送 但是這種吞吐量最高
all或者-1:leader broker會等訊息寫入 并且ISR都寫入后 才會回應,這種只要ISR有副本存活就肯定不會丟失,但吞吐量最低,
1:默認的值 leader broker自己寫入后就回應,不會等待ISR其他的副本寫入,只要leader broker存活就不會丟失,即保證了不丟失,也保證了吞吐量,
所以設定為0時,實作了at most once,而且從這邊看只要保證集群穩定的情況下,不設定為0,訊息不會丟失,
但是還有一種情況就是訊息成功寫入,而這個時候由于網路問題producer沒有收到寫入成功的回應,producer就會開啟重試的操作,直到網路恢復,訊息就發送了多次,這就是at least once了,
kafka producer 的引數acks 的默認值為1,所以默認的producer級別是at least once,并不能exactly once,

二、Consumer端訊息傳遞
consumer是靠offset保證訊息傳遞的,
consumer消費的代碼如下:
Properties props = new Properties();
props.put("bootstrap.servers", "kafka01:9092,kafka02:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset","earliest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
try{
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = https://www.cnblogs.com/tree1123/p/%s%n", record.offset(), record.key(), record.value());
}
}
}finally{
consumer.close();
}
其中有一個引數是 enable.auto.commit
若設定為true consumer在消費之前提交位移 就實作了at most once
若是消費后提交 就實作了 at least once 默認的配置就是這個,
kafka consumer的引數enable.auto.commit的默認值為true ,所以默認的consumer級別是at least once,也并不能exactly once,
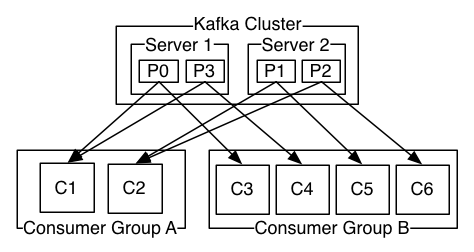
圖 consumer-groups
三、精確一次
通過了解producer端與consumer端的設定,我們發現kafka在兩端的默認配置都是at least once,肯能重復,通過配置的話呢也不能做到exactly once,好像kafka的訊息一定會丟失或者重復的,是不是沒有辦法做到exactly once了呢?
確實在kafka 0.11.0.0版本之前producer端確實是不可能的,但是在kafka 0.11.0.0版本之后,kafka正式推出了idempotent producer,
也就是冪等的producer還有對事務的支持,
冪等的producer
kafka 0.11.0.0版本引入了idempotent producer機制,在這個機制中同一訊息可能被producer發送多次,但是在broker端只會寫入一次,他為每一條訊息編號去重,而且對kafka開銷影響不大,
如何設定開啟呢? 需要設定producer端的新引數 enable.idempotent 為true,
而多磁區的情況,我們需要保證原子性的寫入多個磁區,即寫入到多個磁區的訊息要么全部成功,要么全部回滾,
這時候就需要使用事務,在producer端設定 transcational.id為一個指定字串,
這樣冪等producer只能保證單磁區上無重復訊息;事務可以保證多磁區寫入訊息的完整性,

圖 事務
這樣producer端實作了exactly once,那么consumer端呢?
consumer端由于可能無法消費事務中所有訊息,并且訊息可能被洗掉,所以事務并不能解決consumer端exactly once的問題,我們可能還是需要自己處理這方面的邏輯,比如自己管理offset的提交,不要自動提交,也是可以實作exactly once的,
還有一個選擇就是使用kafka自己的流處理引擎,也就是Kafka Streams,
設定processing.guarantee=exactly_once,就可以輕松實作exactly once了,
2、Flink
Apache Flink是由Apache軟體基金會開發的開源流處理框架,其核心是用Java和Scala撰寫的分布式流資料流引擎,Flink以資料并行和流水線方式執行任意流資料程式,Flink的流水線運行時系統可以執行批處理和流處理程式,此外,Flink的運行時本身也支持迭代演算法的執行,
我們從flink消費并寫入kafka的例子是如何通過兩部提交來保證exactly-once語意的
為了保證exactly-once,所有寫入kafka的操作必須是事物的,在兩次checkpiont之間要批量提交資料,這樣在任務失敗后就可以將沒有提交的資料回滾,
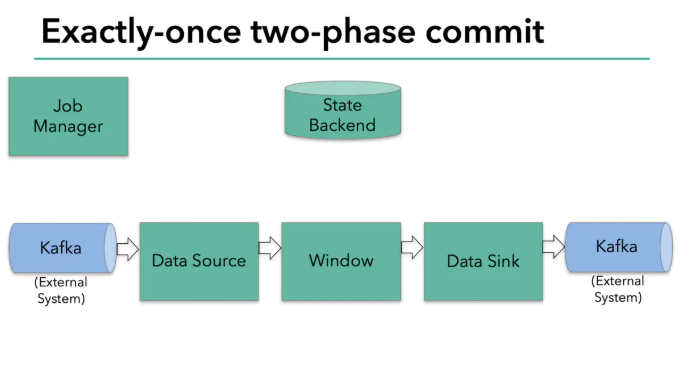
兩部提交協議的第一步是預提交,flink的jobmanager會在資料流中插入一個檢查點的標記(這個標記可以用來區別這次checkpoint的資料和下次checkpoint的資料),
這個標記會在整個dag中傳遞,每個dag中的算子遇到這個標記就會觸發這個算子狀態的快照,
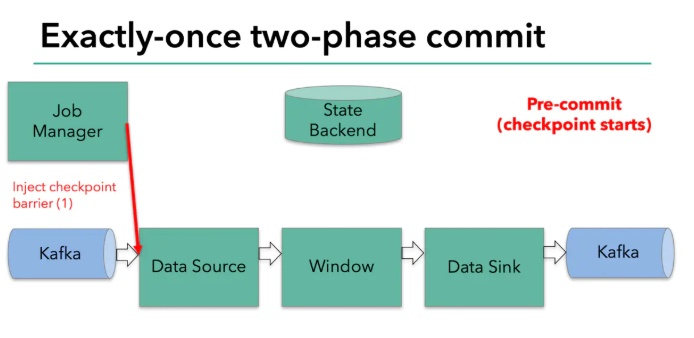
讀取kafka的算子,在遇到檢查點標記時會存盤kafka的offset,之后,會把這個檢查點標記傳到下一個算子,
接下來就到了flink的記憶體操作算子,這些內部算子就不用考慮兩部提交協議了,因為他們的狀態會隨著flink整體的狀態來更新或者回滾,
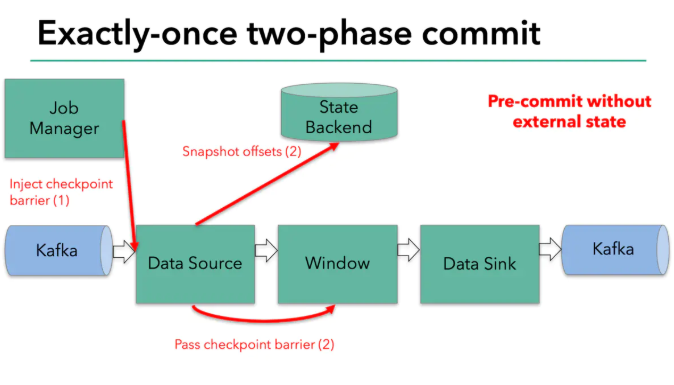
到了和外部系統打交道的時候,就需要兩步提交協議來保證資料不丟失不重復了,在預提交這個步驟下,所有向kafka提交的資料都是預提交,
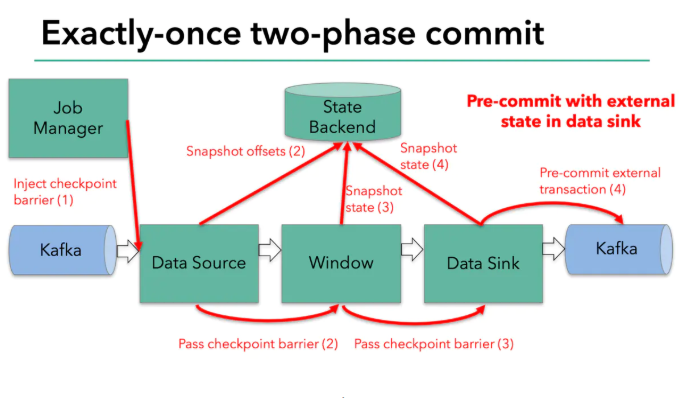
當所有算子的快照完成,也就是這次的checkpoint完成時,flink的jobmanager會向所有算子發通知說這次checkpoint完成,flink負責向kafka寫入資料的算子也會正式提交之前寫操作的資料,在任務運行中的任何階段失敗,都會從上一次的狀態恢復,所有沒有正式提交的資料也會回滾,
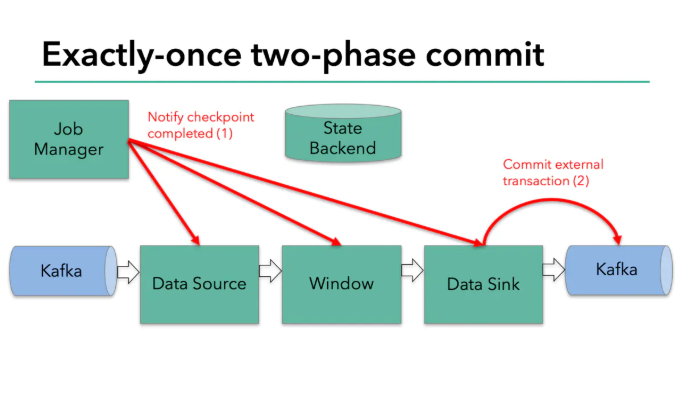
總結一下flink的兩步提交:
? 當所有算子都完成他們的快照時,進行正式提交操作
? 當任意子任務在預提交階段失敗時,其他任務立即停止,并回滾到上一次成功快照的狀態,
? 在預提交狀態成功后,外部系統需要完美支持正式提交之前的操作,如果有提交失敗發生,整個flink應用會進入失敗狀態并重啟,重啟后將會繼續從上次狀態來嘗試進行提交操作,
這樣flink就通過狀態和兩次提交協議來保證了端到端的exactly-once語意,
更多大資料,實時計算相關博文與科技資訊,歡迎搜索或者掃描下方關注 “實時流式計算”

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/16353.html
標籤:大數據
上一篇:PLSQL Developer的命令視窗下結果集怎么對齊?
下一篇:hadoop全分布安裝和搭建