全分布模式安裝
1、準備作業
(*)關閉防火墻
systemctl stop firewalld.service
systemctl disable firewalld.service
(*)安裝JDK
(*)配置主機名 vi /etc/hosts
192.168.153.11 bigdata11
192.168.153.12 bigdata12
192.168.153.13 bigdata13
(*)配置免密碼登錄:兩兩之間的免密碼登錄
(1) 每臺機器產生自己的公鑰和私鑰
ssh-keygen -t rsa
(2) 每臺機器把自己的公鑰給別人
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata11
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata12
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata13
(*)保證每臺機器的時間同步
如果時間不一樣,執行MapReduce程式的時候可能存在問題
2、在主節點上(bigdata11)安裝Hadoop
(1)解壓設定環境變數
tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
設定:bigdata11 bigdata12 bigdata13
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
(2) 修改組態檔
進入Hadoop的組態檔目錄:

修改hadoop-env.sh 檔案,添加Java的安裝目錄

=======hdfs-site.xml
<!--表示資料塊的冗余度,默認:3-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
=======core-site.xml
<!--配置NameNode地址,9000是RPC通信埠-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata11:9000</value>
</property>
<!--HDFS資料保存在Linux的哪個目錄,默認值是Linux的tmp目錄-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>
========mapred-site.xml 默認沒有 cp mapred-site.xml.template mapred-site.xml
<!--MR運行的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
=============yarn-site.xml
<!--Yarn的主節點RM的位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata11</value>
</property>
<!--MapReduce運行方式:shuffle洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
slaves
bigdata11
bigdata12
bigdata13
(3) 格式化NameNode: hdfs namenode -format
(4) 把主節點上配置好的hadoop復制到從節點
scp -r hadoop-2.7.3/ root@bigdata12:/root/training
scp -r hadoop-2.7.3/ root@bigdata13:/root/training
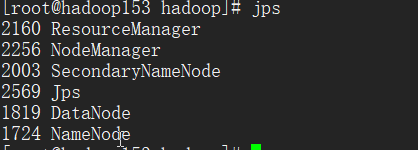
(5) 在主節點上啟動 start-all.sh
通過jps命令可以查看得到以下行程
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/16354.html
標籤:大數據
上一篇:超200萬?約翰斯·霍普金大學資料錯誤!——談談如何保證實時計算資料準確性
下一篇:hive之大資料倉庫