hive是基于Hadoop的一個資料倉庫工具,用來進行資料提取、轉換、加載,這是一種可以存盤、查詢和分析存盤在Hadoop中的大規模資料的機制,hive資料倉庫工具能將結構化的資料檔案映射為一張資料庫表,并提供SQL查詢功能,能將SQL陳述句轉換成Map reduce任務運行,通過自己的SQL查詢分析需要的內容,這套SQL簡稱Hive SQL,
hive不適合用于聯機(online)事務處理,也不提供實時查詢功能,它最適合應用在基于大量不可變資料的批處理作業,
hive的特點包括:可伸縮(在Hadoop的集群上動態添加設備)、可擴展、容錯、輸入格式的松散耦合,
hive 構建在基于靜態批處理的Hadoop 之上,Hadoop 通常都有較高的延遲并且在作業提交和調度的時候需要大量的開銷,因此,hive 并不能夠在大規模資料集上實作低延遲快速的查詢,例如,hive 在幾百MB 的資料集上執行查詢一般有分鐘級的時間延遲,
hive是一種底層封裝Hadoop的資料倉庫處理工具,使用類SQL的hiveQL語言實作查詢,所有hive的資料都存盤在Hadoop兼容的檔案系統中,hive在加載資料程序中不會對資料進行任何的修改,只是將資料移動到HDFS中hive設定的目錄下,因此,hive不支持對資料的改寫和添加,所有的資料都是在加載的時候確定的,
hive的設計特點如下:
1.支持創建索引,優化資料查詢
2.不同的存盤型別,例如,出文本檔案、Hbase中的檔案,
3.將元資料保存在關系型資料庫中,大大減少了在查詢程序中執行語意檢查的時間,
4.可以直接使用存盤在Hadoop檔案系統中的資料,
5.內置大量用戶函式UDF來操作時間、字符和其他的資料挖掘工具,支持用戶擴展UDF函式來完成內置函式無法實作的操作,
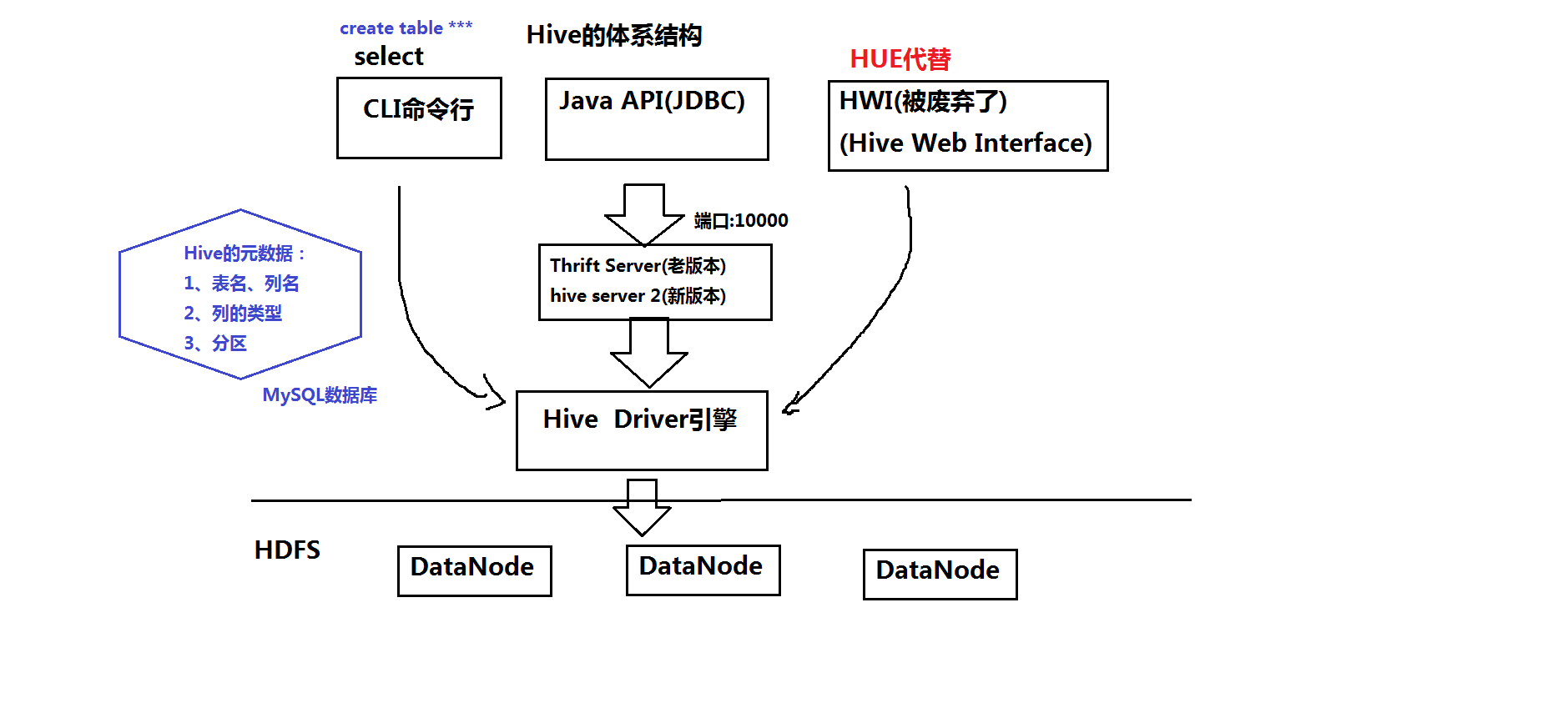
hive體系架構:
用戶介面:
用戶介面主要有三個:CLI,Client 和 WUI,其中最常用的是 Cli,Cli 啟動的時候,會同時啟動一個 hive 副本,
Client 是 hive 的客戶端,用戶連接至 hive Server,在啟動 Client 模式的時候,需要指出 hive Server 所在節點,
并且在該節點啟動 hive Server, WUI 是通過瀏覽器訪問 hive,
元資料存盤:
hive將元資料存盤在資料庫中,如MySQL、debty,hive中的元資料包括表的名字,表的列和磁區及其屬性,
表的屬性(是否為外部表等),表的資料所在目錄等,
解釋器、編譯器、優化器、執行器:
解釋器、編譯器、優化器完成 HQL 查詢陳述句從詞法分析、語法分析、編譯、優化以及查詢計劃的生成,
生成的查詢計劃存盤在 HDFS 中,并在隨后由 MapReduce 呼叫執行,
6.類SQL的查詢方式,將SQL查詢轉換為MapReduce的job在Hadoop集群上執行,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/16355.html
標籤:大數據
上一篇:hadoop全分布安裝和搭建
下一篇:apache spark