基本介紹
Apache Spark是專為大規模資料處理而設計的快速通用的計算引擎 ,現在形成一個高速發展應用廣泛的生態系統,特點
Spark 主要有三個特點 : 首先,高級 API 剝離了對集群本身的關注,Spark 應用開發者可以專注于應用所要做的計算本身, 其次,Spark 很快,支持互動式計算和復雜演算法, 最后,Spark 是一個通用引擎,可用它來完成各種各樣的運算,包括 SQL 查詢、文本處理、機器學習等,而在 Spark 出現之前,我們一般需要學習各種各樣的引擎來分別處理這些需求,性能特點
- 更快的速度
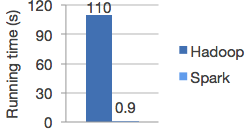
計算時間比較
- 易用性
- 通用性
- 支持多種資源管理器
spark的體系架構
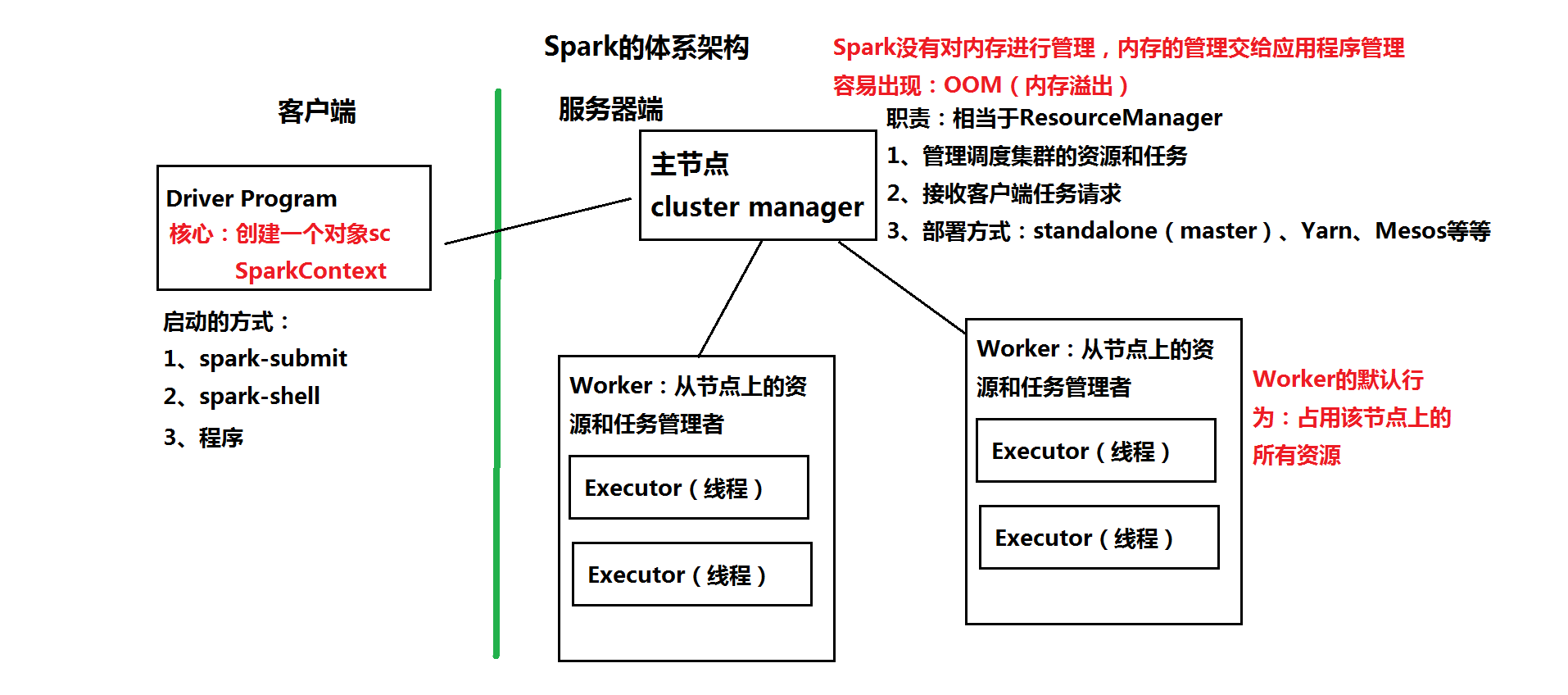
spark的安裝部署:
安裝部署
準備作業:安裝Linux、JDK等等
解壓:tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz -C ~/training/
由于Spark的腳本命令和Hadoop有沖突,只設定一個即可(不能同時設定)組態檔:/root/training/spark-2.1.0-bin-hadoop2.7/conf/spark-env.sh
=============偽分布: hadoop153============
修改組態檔:spark-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
export SPARK_MASTER_HOST=hadoop153
export SPARK_MASTER_PORT=7077
slaves
hadoop153
啟動:sbin/start-all.sh
Spark Web Console(內置Tomcat:8080) http://ip:8080
==============================================
執行Spark Demo程式(hadoop153:偽分布上)
1、執行Spark任務的工具
(1)spark-submit: 相當于 hadoop jar 命令 ---> 提交MapReduce任務(jar檔案 )
提交Spark的任務(jar檔案 )
Spark提供Example例子:/root/training/spark-2.1.0-bin-hadoop2.7/examples/spark-examples_2.11-2.1.0.jar
執行如下命令:
示例:蒙特卡羅求PI(3.1415926******)
>bin/spark-submit --master spark://Hadoop153:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 200

得到結果:

=============全分布:三臺================
Master節點: bigdata112
Worker從節點:bigdata113 bigdata114
修改組態檔:spark-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
export SPARK_MASTER_HOST=bigdata112
export SPARK_MASTER_PORT=7077
slaves
bigdata113
bigdata114
復制到從節點上
scp -r spark-2.1.0-bin-hadoop2.7/ root@bigdata113:/root/training
scp -r spark-2.1.0-bin-hadoop2.7/ root@bigdata114:/root/training
在主節點上啟動: sbin/start-all.sh
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/16356.html
標籤:大數據
上一篇:hive之大資料倉庫
下一篇:oracle11g卸載出錯