作者 王文安,騰訊CSIG資料庫專項的資料庫工程師,主要負責騰訊云資料庫 MySQL 的相關的作業,熱愛技術,歡迎留言進行交流,文章首發于騰訊云+社區的騰訊云資料庫專家服務專欄,
在日常作業中,發現 MySQL 的狀態不太對勁的時候,一般都會看看監控指標,很多時候會看到熟悉的一幕:CPU 使用率又爆了,本文將給大家介紹 MySQL 和 CPU 之間的關系,對此有一定的了解之后可以更準確的判斷出問題的原因,也能夠提前發現一些引發 CPU 問題的隱患,
怎么看懂CPU使用率
以 Linux 的 top 命令為例,效果如下:

在 %CPU 這一列就展示了 CPU 的使用情況,百分比指代的是總體上占用的時間百分比:
- %us:表示用戶行程的 CPU 使用時間(沒有通過 nice 調度)
- %sy:表示系統行程的 CPU 使用時間,主要是內核使用,
- %ni:表示用戶行程中,通過 CPU 調度(nice)過的使用時間,
- %id:空閑的 CPU 時間
- %wa:CPU 運行時在等待 IO 的時間
- %hi:CPU 處理硬中斷花費的時間
- %si:CPU 處理軟中斷花費的時間
- %st:被虛擬機偷走的 CPU 時間
通常情況下,我們討論的 CPU 使用率過高,指的是 %us 這個指標,監控里面的 CPU 使用率通常也是這個值(也有用其他的方法計算出來的,不過簡單起見,不考慮其他的情況 ),其他幾個指標過高也代表出 MySQL 的狀態例外,簡單起見,這里主要還是指 %us 過高的場景,
MySQL和執行緒
MySQL 是單行程多執行緒的結構,意味著獨占的 MySQL 服務器里面,只能用 top 命令看到一行資料,
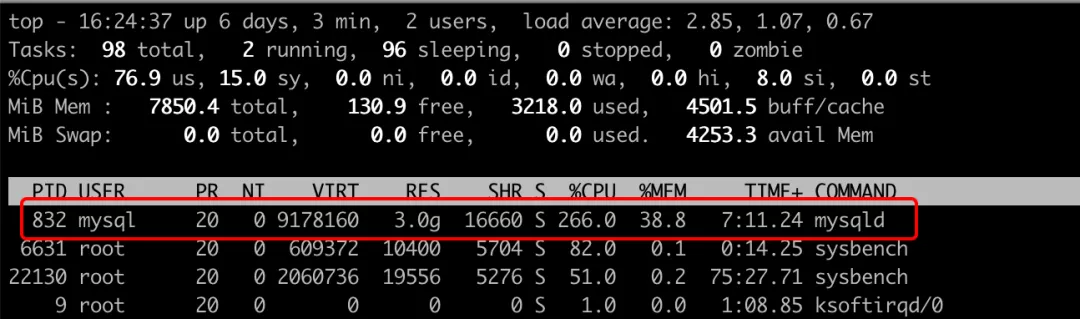
這里能看到的是 MySQL 的行程 ID,如果要看到執行緒的情況,需要用top -H
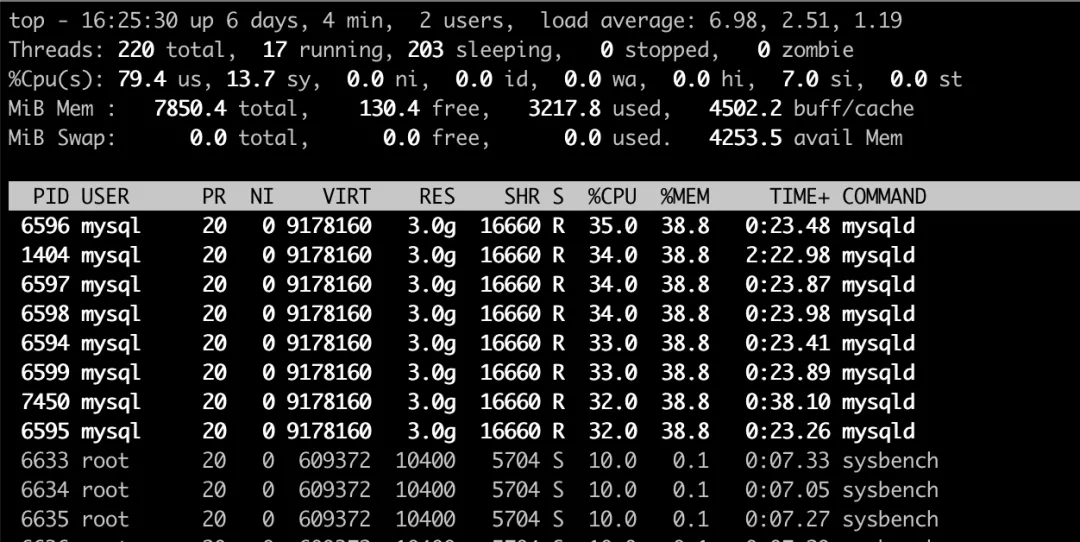
在這里能看到的是 MySQL 各個執行緒的 ID,可以看到 MySQL 在啟動之后,會創建非常多的內部執行緒來作業,
這些內部執行緒包括 MySQL 自己用來刷臟,讀寫資料等操作的系統執行緒,也包括處理用戶 SQL 的執行緒,姑且叫做用戶執行緒吧,用戶執行緒有一個特殊的地方:程式端發送到 MySQL 端的 SQL,只會由一個用戶執行緒來執行(one-thread-per-connection),所以 MySQL 在處理復雜查詢的時候,會出現“一核有難,多核圍觀”的尷尬現象,
參考 %us 的定義,對于 Linux 系統來說,MySQL 行程和它啟動的所有執行緒都不算內核行程,因此 MySQL 的系統執行緒和用戶執行緒在繁忙的時候,都會體現在 CPU 使用率的 %us 指標上,
什么時候CPU會100%
MySQL 干什么的時候,CPU 會 100%?從前文的分析來看,MySQL 主要是兩類執行緒占用 CPU:系統執行緒和用戶執行緒,因此 MySQL 獨占的服務器上,只需要留意一下這兩類執行緒的情況,就能 Cover 住絕大部分的問題場景,
系統執行緒
在實際的環境中,系統執行緒遇到問題的情況會比較少,一般來說,多個系統執行緒很少會同時跑滿,只要服務器的可用核心數大于等于 4 的話,一般也不會遇到 CPU 100%,當然有一些 bug 可能會有影響,比如這個:
MySQL BUG
雖然情況比較少,但是在面對問題的常規排查程序中,系統執行緒的問題也是需要關注的,
用戶執行緒
提到用戶執行緒繁忙,很多時候肯定會第一時間憑經驗想到慢查詢,確實 90% 以上的時候都是“慢查詢”引起的,不過作為方法論,還是要根據分析再去得出結論的~
參考 us% 的定義,是指用戶執行緒占用 CPU 的時間多少,這代表著用戶執行緒占用了大量的時間,
一方面是在進行長時間的計算,例如:order by,group by,臨時表,join 等,這一類問題可能是查詢效率不高,導致單個 SQL 陳述句長時間占用 CPU 時間,也有可能是單純的資料量比較多,導致計算量巨大,另一方面是單純的 QPS 壓力高,所以 CPU 的時間被用滿了,比如 4 核的服務器用來支撐 20k 到 30k 的點查詢,每個 SQL 占用的 CPU 時間并不多,但是因為整體的 QPS 很高,所以 CPU 的時間被占滿了,
問題的定位
分析完之后,就要開始實戰了,這里根據前文的分析給出一些經典的 CPU 100% 場景,并給出簡要的定位方法作為參考,
PS:系統執行緒的 bug 的場景 skip,以后有機會再作為詳細的案例來分析,
慢查詢
在 CPU 100% 這個問題已經發生之后,真實的慢查詢和因為 CPU 100% 導致被影響的普通查詢會混在一起,難以直觀的看 processlist 或者 slowlog 來發現元兇,這時候就需要一些比較明確的特征來進行甄別,
從前文的簡單分析可以看出來,查詢效率不高的慢查詢通常有以下幾種情況:
- 全表掃描:Handler_read_rnd_next 這個值會大幅度突增,且這一類查詢在 slowlog 中 row_examined 的值也會非常高,
- 索引效率不高,索引選錯了:Handler_read_next 這個值會大幅度的突增,不過要注意這種情況也有可能是業務量突增引起的,需要結合 QPS/TPS 一起看,這一類查詢在 slowlog 中找起來會比較麻煩,row_examined 的值一般在故障前后會有比較明顯的不同,或者是不合理的偏高,
比如資料傾斜的場景,一個小范圍的 range 查詢在某個特定的范圍內 row_examined 非常高,而其他的范圍時 row_examined 比較低,那么就可能是這個索引效率不高, - 排序比較多:order by,group by 這一類查詢通常不太好從 Handler 的指標直接判斷,如果沒有索引或者索引不好,導致排序操作沒有消除的話,那么在 processlist 和 slowlog 通常能看到這一類查詢陳述句出現的比較多,
當然,不想詳細的分析 MySQL 指標或者是情況比較緊急的話,可以直接在 slowlog 里面用 rows_sent 和 row_examined 做個簡單的除法,比如 row_examined/rows_sent > 1000 的都可以拿出來作為“嫌疑人”處理,這類問題一般在索引方面做好優化就能解決,
PS:1000 只是個經驗值,具體要根據實際業務情況來定,
計算量大
這一類問題通常是因為資料量比較大,即使索引沒什么問題,執行計劃也 OK,也會導致 CPU 100%,而且結合 MySQL one-thread-per-connection 的特性,并不需要太多的并發就能把 CPU 使用率跑滿,這一類查詢其實是是比較好查的,因為執行時間一般會比較久,在 processlist 里面就會非常顯眼,反而是 slowlog 里面可能找不到,因為沒有執行完的陳述句是不會記錄的,
這一類問題一般來說有三種比較常規的解決方案:
- 讀寫分離,把這一類查詢放到平時業務不怎么用的只讀從庫去,
- 在程式段拆分 SQL,把單個大查詢拆分成多個小查詢,
- 使用 HBASE,Spark 等 OLAP 的方案來支持,
高 QPS
這一類問題單純的就是硬體資源的瓶頸,不論是 row_examined/rows_sent 的比值,還是 SQL 的索引、執行計劃,或者是 SQL 的計算量都不會有什么明顯問題,只是 QPS 指標會比較高,而且 processlist 里面可能什么內容都看不到,例如:
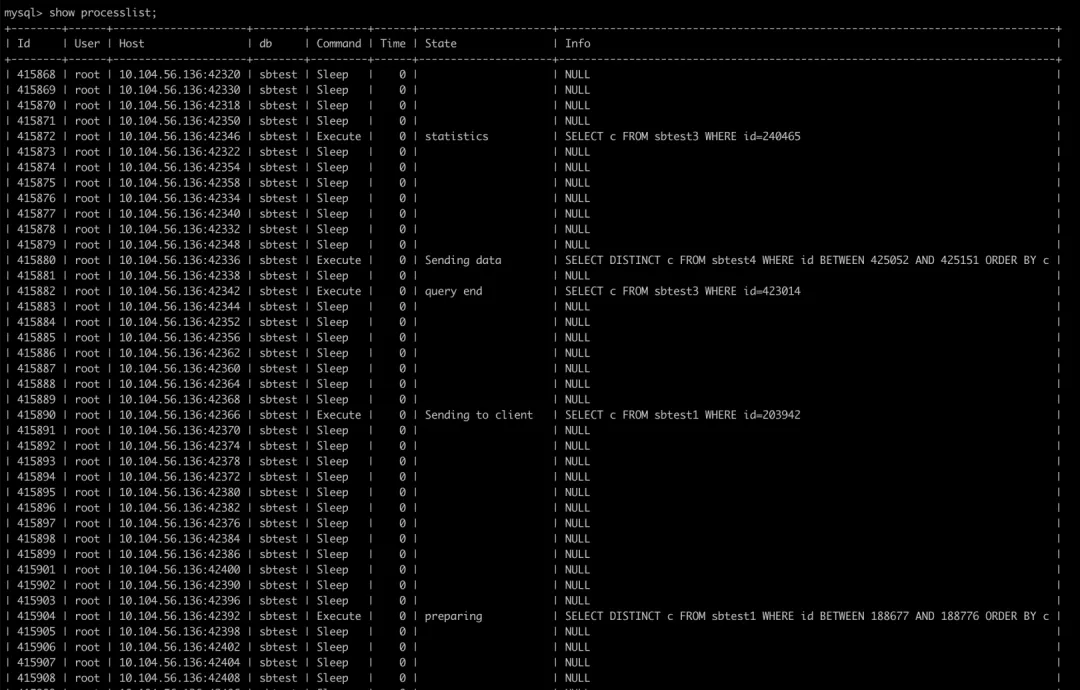
processlist
總結
實際上 CPU 100% 的問題其實不僅僅是單純的 %us,還會有 %io,%sys 等,這些會涉及到 MySQL 與 Linux 相關聯的一部分內容,展開來就會比較多了,本文僅從 %us 出發嘗試梳理一下排查&定位的思路和方法,在分析 %io,%sys 等方面的問題時,也可以用類似的思路,從這些指標的意義開始,結合 MySQL 的一些特性或者特點,逐步理清楚表象背后的原因,
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/196101.html
標籤:其他
上一篇:oracle常見視圖匯總