
隨著互聯網的發展,“程式員”這個名字逐漸為人們所關注到,其所代表的標簽印象也變得更加多樣 —— 改變世界?Debug專業戶?格子衫代言人?……事實上,有那么一群人,比如騰訊資料庫工程師,他們將自己定義為“數字的工匠”,初心如一地用代碼創造產品、解決問題,為國產資料庫發展助力,而對于我們來說,有他們的努力,數字世界也不再是虛無縹緲的資料,而像冰山盤亙在海面一樣,深邃而沉穩,
在“1024”程式員節到來之際,我們推出本期特別分享,邀請騰訊6位資料庫技術工程師,講述了他們對代碼技術的理解,

“我是騰訊云資料庫技術負責人雷海林,2007年大學畢業加入騰訊,負責過計費、支付底層各大模塊的開發,包括分布式Cache系統‘Hold(厚德)’等,以及騰訊金融級安全可控分布式資料庫研發,我在騰訊,為資料庫國產化發展助力,”

“我是騰訊云資料庫高級工程師賴錚,2018年加入騰訊,曾經在MySQL資料庫官方團隊作業,現在負責騰訊云資料庫內核開發,我在騰訊,為資料庫國產化發展助力,”

“我是騰訊IEG資料庫專家工程師陳福榮,2011年加入騰訊,曾經做過Tendb Cluster和Tendis專案,現在騰訊IEGCROS團隊負責騰訊游戲云存盤開發,我在騰訊,為資料庫國產化發展助力,”

“我是騰訊云資料庫高級工程師陳再妮,2019年加入騰訊,從事資料多活、Oracle兼容、讀寫分離等專案開發,我在騰訊,為資料庫國產化發展助力,”

“我是騰訊云資料庫工程師張風嘯,2019年加入騰訊,從事多源同步和資料校驗模塊的設計與開發,我在騰訊,為國產資料庫發展助力,”

“我是騰訊云資料庫高級工程師陳松威,2018年加入騰訊,從事云資料庫內核研發,開發過的功能包括企業級列加密函式、資料恢復工具、異步審計,資料預熱等,我在騰訊,為國產資料庫發展助力,”
你為什么從事資料庫底層研發
雷海林:
個人興趣更喜歡與計算機打交道,通過code去解決問題;而一般來說,越是偏低層的系統軟體,技術挑戰也越大,而資料庫領域在性能優化、高可用、擴展性、資料一致性等方面一直有無限的可能,技術上可以做各種嘗試、各種創新探索,同時驅動更廣泛的技術生態創新突破,

賴錚:
資料庫系統作為基礎的系統軟體,是很多應用系統的核心,它涉及到的知識領域非常廣泛,包括作業系統、事務系統、并發處理等等,可以說是軟體領域的明珠、人類智慧的結晶,能從事這個領域的研發作業,會有一種使命感,同時,如果做出了一點點成績,也會給自己帶來巨大的滿足感,尤其是在資料爆炸的時代,對于資料的存盤和管理技術越來越成為計算機領域的關鍵性技術,能在這樣快速變化的大潮中奮發搏擊,也是一件幸事,
陳福榮:
應該說比較幸運,研究生階段就是從事資料庫方面的學習和研究,第一份作業是跟著導師做國產資料庫,積累了一些經驗,后來加入了騰訊游戲的DBA團隊,所以,從學生到現在超過10年了,一直都是做資料庫相關的開發作業,也很慶幸一直做著自己比較喜歡的作業,
陳再妮:
最早在業務系統的后臺開發時,底層資料存盤使用到了資料庫,發現很多大段的業務邏輯代碼,一條SQL就可以搞定,這使得我對資料庫產生了濃厚的興趣,開始進入這個領域,進入后發現資料庫底層確實是復雜的東西,做起來特別有挑戰,但一旦完成后也會讓我產生更多的成就感,這也驅動了我一直從事下去,
張風嘯:
才開始接觸技術是寫Java Web的,參與了校內小專案的開發,做了有一年多,在開始覺得只是用框架,不夠深入有點無聊,后來通過社區接觸了很多之前沒接觸的新技術,對一些基礎組件的底層實作產生了比較濃厚的興趣,后來進入騰訊實習期間,調研了解了一些新的DB技術,從而對資料庫的興趣更加濃烈,后來面試的時候也和面試官表達了想去做資料庫的意愿,沒想到真的遇上了,
陳松威:
資料庫是三大系統軟體之一,涉及到的模塊眾多,是非常有深度、值得探索的領域,能從事資料庫底層研發,是一件非常榮幸的事情,特別是在我們團隊,有多位在資料庫內核領域深耕多年的技術大牛,他們總能知無不言言無不盡地幫助我,使我快速成長,這我更加堅信從事資料庫內核研發的選擇是正確的,
作為程式員,你做過覺得罪有成就感的三個業務或者事情是什么?
雷海林:
我覺得最有成就感的事情是技術上比較追求完美地做出一些組件或者產品,解決難以解決的BUG,或者性能上的每一次超越和升級:
a) 比如封裝zkapi,能讓大家用起來更方便,屏蔽很難處理的一些細節問題,實作一個基本無鎖化的記憶體池組件,解決偶發的毛刺問題等等;
b) 比如花一個星期以上的時間,構造數十億的請求去解決某個難以重現的資料一致性BUG;
c) 負責騰訊國產分布式資料庫的研發,支撐各行業對分布式資料庫的需求,
賴錚:
a)在InnoDB存盤引擎中實作了透明加密功能;
b)在InnoDB存盤引擎中實作了基于R樹的空間索引;
c)通過優化熱點更新大幅度提升了秒殺場景下的系統性能,

陳福榮:
作為程式員,最有成就感的事情應該就是做的一些核心功能或者優化,能夠真正在業務上落地并且發揮作用,舉三個例子:
第一個是在資料庫上增加了在線加欄位的能力,這應該是我個人加入騰訊做的第一個比較大的功能點,需要對Innodb底層存盤格式進行優化,當時做的時候技術上挑戰很大,但完成后,它對業務減少停服時間的收益也特別明顯,當第一個Demo做出來并且在第一個業務(當年應該是斗戰神)上線時,還是很有成就感的,
第二個是研發互娛的分布式解決方案TenDBCluster,解決了原來資料庫無法水平擴展的問題,順應了手游時代的爆發,大約在2015年,第一款業務從單機資料庫切換到TenDB Cluster時,我跟另外一個同事一直堅守了凌晨兩三點,最終業務順利切換,雖然比較晚了,但心里還是感到非常興奮,
第三個是TendisX冷熱混合存盤在騰訊云商業化,通過騰訊云對外開放,

陳再妮:
a)資料庫多中心多活模塊研發:保障企業資料庫的高可用,為客戶業務系統實作7×24小時不間斷高效平穩運行發揮了重要作用;
b)Oracle兼容特性研發,助力Oracle兼容版本的資料庫產品功能順利上線,極大提升了騰訊云資料庫助力行業技術國產化的優勢;
c)完成騰訊自研分布式HTAP國產資料庫開源,
張風嘯:
a)一個是實作了資料庫遷移中異構資料遷移和同步的資料校驗模塊,解決了據遷移中的一致性校驗問題,
b)進一步完善了資料庫異構多源同步的功能,提升了產品的易用性,
c)最關鍵的是大學期間教女孩子寫計算機的大作業,最后變成了女朋友,
陳松威:
a)原創了業界唯一的資料恢復工具,能夠從損壞的表檔案中恢復用戶資料,保障資料安全,
b)設計并實作了異步審計,將審計性能影響降至3%,在業界遙遙領先,
c)原創了資料庫主從切換前,備機的資料預熱功能,
你認為對程式員來說最重要的非技術因素是什么?
雷海林:
尋根問底的精神,比如程式出現了某個罕見的例外現象,那也一定是在代碼層面出現了問題,我們要盡全力找到并解決它,不能因為它非常偶發而忽視,
賴錚:
保持好奇,
陳福榮:
第一,需要刨根問底的精神,對于一個技術問題,如果這個問題是自己的主要作業,或者是某個待解決問題的關鍵路徑,必須把這些問題完全搞清楚,不能似懂非懂,對于底層技術而言,對更多底層問題的鉆研,會發現這些問題的解決思路其實是類似的,漸漸會建立自己的方法論,因此不要輕易放過一個問題或者bug,
第二,對最終結果負責,不能僅僅滿足于功能開發完成,這點特別重要,一個任務,一定不僅僅是希望這個功能跑起來,更多是希望真正能夠解決業務問題和痛點,如果開發人員僅僅把自己定位成代碼撰寫者,是不夠的,
第三,可以有一點點代碼潔癖,這樣會讓自己寫出風格更好的代碼,
陳再妮:
做事嚴謹,就像計算機的世界非0即1;態度認真負責,值得信賴,

張風嘯:
我覺得是對感興趣的事情的喜愛和追求,技術和其他方面都一樣,一定是有興趣、有追求,才能做得更好,
陳松威:
我覺得是,要有一種“空杯心態”,
厲害的程式員都有哪些特別的能力 ?
雷海林:
a)學習能力,個人很渺小,要不斷地虛心學習,看書、看文章論文、多掌握原理性質的東西;
b)熱愛閱讀開源社區好的代碼,通過學習別人的代碼提升自己的編程能力;
c)對自己有信心,遇事不妥協,高標準要求自己,喜歡去解決作業領域各種技術上的挑戰,
陳福榮:
第一是學習能力,開發這個領域新技術是層出不窮,如果不具備很好的學習能力,很容易會出現一些力不從心的狀態,當然,如果有比較好的計算機基礎理論的背景,學習起來是可以觸類旁通的,
第二個是抗壓能力,線上bug是不可避免的,如果出現線上故障壓力一定是很大的,但此時最重要的是優先恢復業務,因此,一定要頂住壓力,保持思路清晰,尋找最高效的解決辦法,
第三個是心態調整能力,厲害的程式員都會表現出干勁十足,精神飽滿,除了本身對作業的熱愛外,還需要自己心態上的調整,以及適當的泄壓方式包括鍛煉身體等,
陳再妮:
a)極客精神:對未知技術保持好奇之心,并持續學習;
b)看待問題可以通過表象直到問題根源;
c)有趣的靈魂:代碼注釋寫的讓人如沐晨風,比如讓模塊運行起來:
/* Do the modulemagic dance */
PG_MODULE_MAGIC;
賴錚:
思維縝密,邏輯性極強,
張風嘯:
專注, 細致,心思縝密,思考全面;以及對問題刨根究底的態度,深入鉆研,
陳松威:
邏輯性強、創造力強、思維嚴謹、良好的溝通能力,
對資料庫未來發展趨勢,有什么看法或建議
雷海林:
資料庫必定還是會往分布式資料庫的方向繼續發展,整體來看,則將在資料庫彈性擴展、跨地域進行分布調度、6個9(99.9999%)以上的可用性、HTAP融合、SQL智能診斷與優化、極致的性能等方向持續發展——最后回歸資料庫的本質:當某個業務獲取到一個資料庫的域名地址,資料庫就是一個黑盒子以極致的性能提供SQL讀寫服務,不用再關心容量、SQL調優、容災等細節,
賴錚:
資料庫未來會操作面向云計算的方向發展,云原生資料庫將會成為主流,彈性擴展、TP+AP、海量資料等特點將會充分顯示出云原生資料庫的優勢,
陳福榮:
1)分布式,未來的資料庫一定主要是使用分布式的架構,無論是share nothing還是share disk,都能較好解決資料庫的容量問題,便于彈性擴縮容;
2)軟硬結合,未來資料庫一定會結合軟硬一體化的設計理念,充分發揮硬體的性能,滿足企業級用戶的需求,如更快的回應時間、更高的安全性、更大的容量、更低的成本等;
3)智能化,未來的資料庫會結合資料庫的運行狀態以及AI的能力,提升資料庫管理的智能化水平,包括故障診斷、故障預測、自動擴縮容、更優的執行計劃等,
陳再妮:
未來資料庫一定會依據新型硬體做架構層面的改良,舉個例子:傳統資料庫是基于存盤不可靠以及存盤性能差設計的(WAL、REDO、UNDO、DO、CHECKPOINT),是基于當前CPU運算速度設計的(32位事務ID,64位事務ID),但是好多理論隨著硬體的快速發展會被徹底顛覆:比如基于云原生資料庫(接近于基于存盤可靠的設計),云原生記憶體資料庫(資料全部存盤于記憶體,主要解決網路問題 RDMA、DPDK、SPDK 等)、量子資料庫等,這些基于新硬體新理論才是資料庫的未來,

張風嘯:
一方面是,當前業界關于資料庫的架構、存盤結構等很多方面的研究已經很多且比較完善了,而存盤介質等硬體方面的變化,可能給會給存盤的架構設計帶來很大的變化,所以我們可以多關注新型存盤產品的出現帶來的一些變化,
另一方面是我很贊同的觀點:性能不是唯一的肌肉,穩定性、產品化、運營體系等方面,才是當前國產資料庫面對最突出的幾個挑戰,資料庫要發展好,發展優秀的生態和做好產品化是至關重要的,
陳松威:
資料庫未來趨勢是云原生,在未來的產業互聯網中,資料庫的彈性擴展能力、自我診斷快速運維能力、個性化服務能力將非常重要,

推薦一段值得稱道或簡短代碼片段?
雷海林:
Linux內核的list.h組件,實作簡單,通用性好:
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
#ifndef CONFIG_DEBUG_LIST
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
#else
extern void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next);
#endif
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
賴錚:
存盤引擎里位元組序轉換函式代碼,簡單明了,非常精巧,
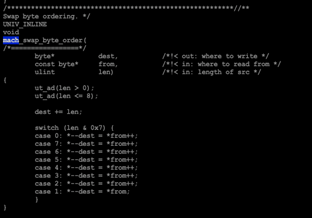
陳再妮:
/*
* TransactionIdPrecedes --- is id1 logically < id2?
*/
bool
TransactionIdPrecedes(TransactionId id1, TransactionId id2)
{
/*
* If either ID is a permanent XID then we can just do unsigned
* comparison. If both are normal, do a modulo-2^32 comparison.
*/
int32 diff;
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2))
return (id1 < id2);
diff = (int32) (id1 - id2);
return (diff < 0);
}
這段代碼乍一看平平無奇,但要結合PG事務環來看,這個演算法設計得很巧妙的,而且剛好在PG這種事務環下才是有效的,它在半個事務環的限制下,巧妙的運行 2 的補碼,實作無符號事務ID的比較:
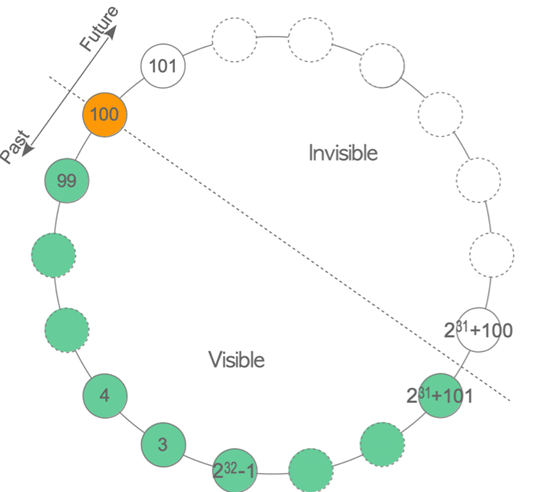
張風嘯:
世界上最簡單的資料庫可以只用2個bash函式實作,這是在書籍《DesigningData-IntensiveApplication》中截取的,也非常推薦大家去閱讀,
#!/bin/bash
db_set () {
echo"$1,$2" >> database
}
db_get () {
grep"^$1," database | sed -e "s/^$1,//" | tail -n 1
}
陳松威:
想推薦一個存盤引擎里實作中的一個頁面校驗函式:btr_validate_level,這個函式將所有可能的校驗條件都一一列舉,包括頁面在區中的狀態校驗、頁面本身校驗、相鄰頁面指標校驗、父子節點指標校驗、父子節點相鄰節點指標環校驗等等,代碼非常嚴謹,對我啟發很大,
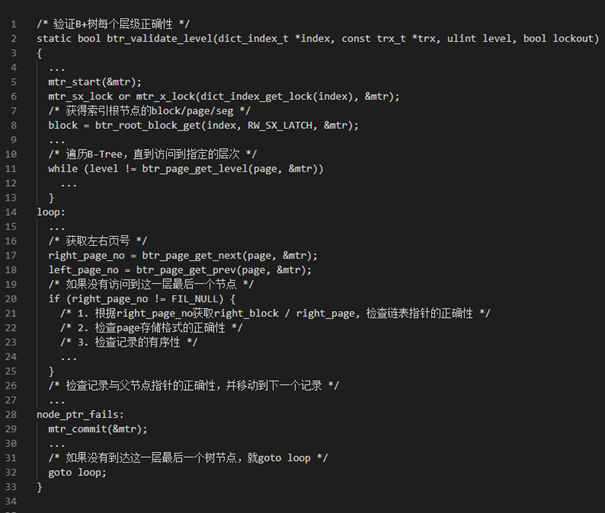
陳福榮:
簡短代碼片段意義不是很大,一個片段不管有多好,也不是一個可服務的載體,相對于代碼片段,一個完整系統的設計與實作顯得更重要,如果是C語言,推薦redis;如果是C++,推薦LevelDB或RocksDB,如果把成熟的開源軟體代碼認真看一遍,對個人的提升還是很大的,
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/196103.html
標籤:其他