資料庫的集群或者是分布式,越來越成為一個趨勢,對于相對較為年輕的Redis或者MongoDB集群,集群在不需要任何第三方工具,本身就可以完成高可用(自動故障轉移),同時對應用程式非常友好,類似于Jedis、MongoCliet等客戶端,應用端以“智能化”地判斷讀集群中節點的讀寫屬性去訪問資料,而無需在服務端實作集群的對對外透明化處理,這種集群的作業模式對DBA在管理上來說還是輕松不少 , 回到MySQL,MySQL的集群實作自動故障轉移之后,如何友好地對應用程式提供服務,尤其是在單寫節點的故障轉移之后,以及故障恢復之后,這一程序完全對應用程式透明,是一個值得思考的問題,常規的套路有如下兩種
1,keepalived或者類似于VIP的機制
2,服務發現機制
這些方案可以完成應用程式對集群的故障轉移訪問,但是前者存在經典的腦裂問題;后者還是稍顯太重量級了,另外為了解決這個問題,新引進的中間件本身的可靠性也是一個問題,對于MySQL一直沒有類似于Redis/MongoDB集群下,通過類似于rediscluster或者jedis這種友好的訪問方式,如果在集群自動故障轉移后,連接層可以通過配置化實作資料庫集群故障轉移的識別,根本就不需要上述的兩種中間件,那是最好不過的了,截至目前位置,沒有一個很好的實作庫,
最開始是嘗試了官方的mysql-connector-python,https://github.com/mysql/mysql-connector-python/blob/master/lib/mysql/connector/__init__.py
看了下代碼,實作還是很感人的,基本上可以認為就是個擺設,MySQL故障轉移的實作邏輯極其簡單:
按照連接串中的優先級priority倒敘排序,依次向下找節點,如果沒找到,繼續向下找下一個節點,輪訓完成之后再找不到可用節點就報錯,
看起來是沒有問題的,其實細想一下,真的還不敢用,
1,嘗試連接主節點的時候,沒有一個嘗試次數,任何時候連接不上主節點,直接跳轉到下一個節點,這樣很容易在網路抖動的時候誤判,
2,連接主節點的時候,沒有進行可寫性判斷,只要找到第一個可用節點,就算是成功,如果在主節點,從節點接管之后,這種實作沒有問題,一旦原始主節點重新加入集群,此時(主節點是只讀的)就是把原始主節點當做最優先級的節點進行寫入,所以這里缺少一個節點讀寫屬性的判斷,
不過還是想走白嫖路線,又去找pymysql庫,然后發現竟然有人跟我有一模一樣的想法,真的志同道合了,想法還是非常好的:https://github.com/PyMySQL/PyMySQL/issues/470
然后作者并不打算實作這一功能,也闡述了原因,pymysql側重于連接的實作,故障轉移的功能應該在連接池層實作,可以基于pymysql在連接池層實作節點可用性判斷
Such a feature should be implemented in "connection pool", and this project focus on "connection". You can build connection pool on top of this project. Having higher level connection pool allows user can select low level driver. For example, mysqlclient and PyMySQL.
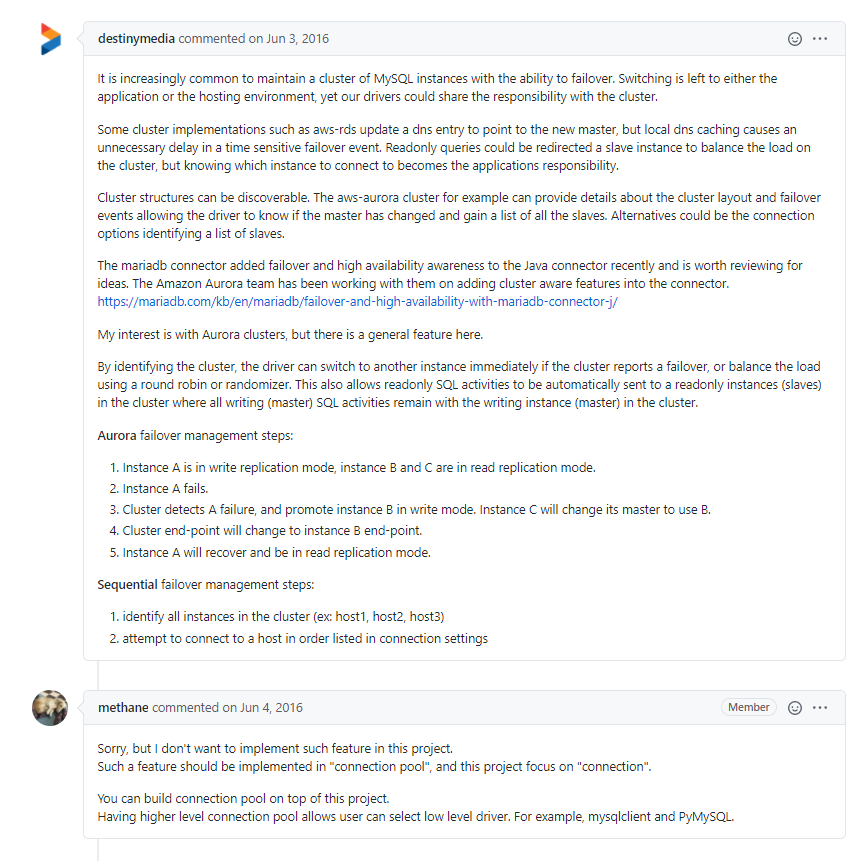
很早之前就有過這個想法,應該來說并不復雜,假設MySQL集群可以自動增確地完成故障轉移,客戶端訪問集群的大概步驟如下
0,正常情況下按照mysql connector的實作,按照優先級找可寫節點
1,例外情況下,對于failover的監測:增加主節點不可用之后探測次數以及sleep的時間,防止誤判
1.1,到達測探次數之后,按照proprity,再依次找下一個節點
1.2,按照優先級,拿到第一個可達節點,且屬性為可寫,說明MySQL服務端故障轉移完成
1.3,找到一個可用實體后,清理連接池中快取的連接,重新初始化連接池
3,如果宕機的主節點重新加入集群,此時再應用程式端的組態檔中,其priority是最高的,因此不但要按照優先級判斷,也需要判斷其是否可讀寫屬性
4,如果從節點宕機,但是主節點正常,可以把只讀連接池(如果有的話)清空,按照其priority繼續向下找可用實體,否則直接執向主節點
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/200893.html
標籤:其他
上一篇:MySQL資料庫性能優化
下一篇:MySQL資料庫性能優化