一、資料準備
1、users.dat
資料格式:2::M::56::16::70072,
資料條數:共有6040條資料
對應欄位:UserID BigInt, Gender String, Age Int, Occupation String, Zipcode String
欄位解釋:用戶id,性別,年齡,職業,郵政編碼
2、movies.dat
資料格式:2::Jumanji (1995)::Adventure|Children’s|Fantasy,
資料條數:共有3883條資料
對應欄位:MovieID BigInt, Title String, Genres String
欄位解釋:電影ID,電影名字,電影型別
3、ratings.dat
資料格式:1::1193::5::978300760,
資料條數:共有1000209條資料
對應欄位:UserID BigInt, MovieID BigInt, Rating Double, Timestamped String
欄位解釋:用戶ID,電影ID,評分,評分時間戳
二、需求分析
1、正確建表,匯入資料(三張表,三份資料),并驗證是否正確
(1)創建表
create table t_user( userid bigint, --用戶id gender string, --性別 age int, --年齡 occupation string, --職業 zipcode string) --郵政編碼 row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe' with serdeproperties('input.regex'='(.*)::(.*)::(.*)::(.*)::(.*)','output.format.string'='%1$s %2$s %3$s %4$s %5$s') stored as textfile; create table t_movie( movieid bigint, --電影ID title string, --電影名字 genres string) --電影型別 row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe' with serdeproperties('input.regex'='(.*)::(.*)::(.*)','output.format.string'='%1$s %2$s %3$s') stored as textfile; create table t_rating( userid bigint, --用戶ID movieid bigint, --電影ID rating double, --評分 timestamped String) --評分時間戳 row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe' with serdeproperties('input.regex'='(.*)::(.*)::(.*)::(.*)','output.format.string'='%1$s %2$s %3$s %4$s') stored as textfile;
(2)匯入資料
load data local inpath '/usr/mydir/data/users.dat' into table t_user; load data local inpath '/usr/mydir/data/movies.dat' into table t_movie; load data local inpath '/usr/mydir/data/ratings.dat' into table t_rating;
(3)驗證資料
select * from t_user; select count(1) from t_user ; --6040條資料 select * from t_movie; select count(1) from t_movie ; --3883條資料 select * from t_rating; select count(1) from t_rating ; --1000209條資料
user表:
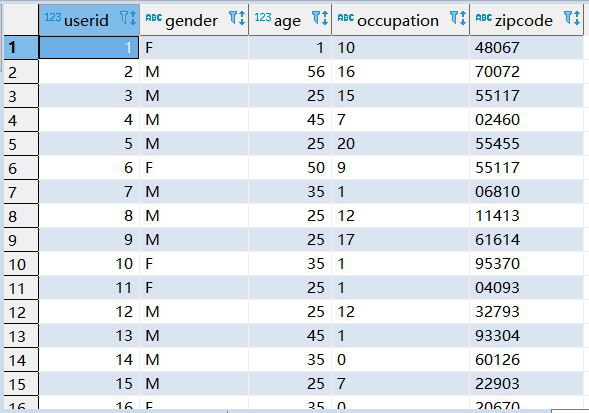
movie表:
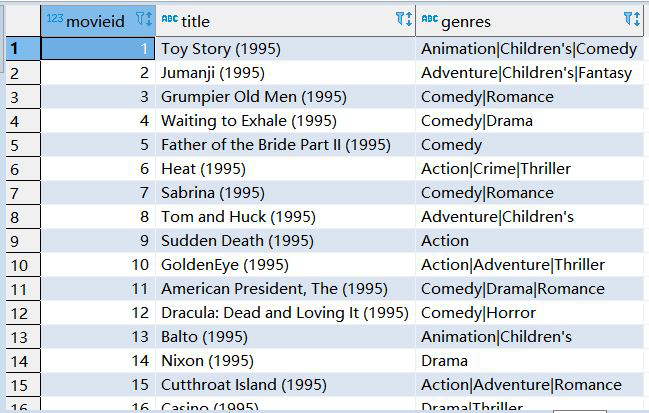
rating表:
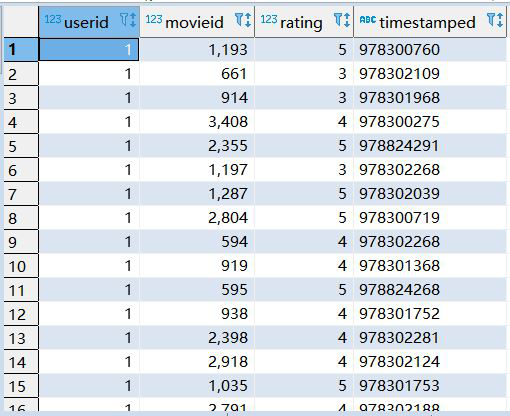
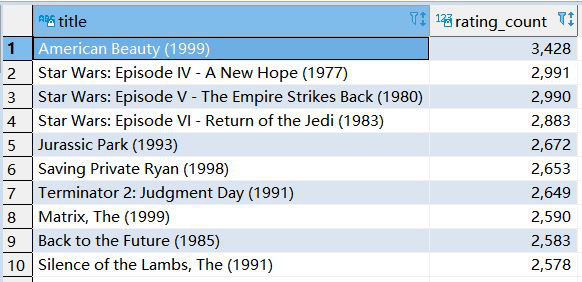
2、求被評分次數最多的10部電影,并給出評分次數(電影名,評分次數)
SELECT title, rating_count FROM (SELECT movieid, COUNT(rating) rating_count from t_rating group by movieid ) t1 left join t_movie t2 on t1.movieid = t2.movieid order by rating_count DESC LIMIT 10;
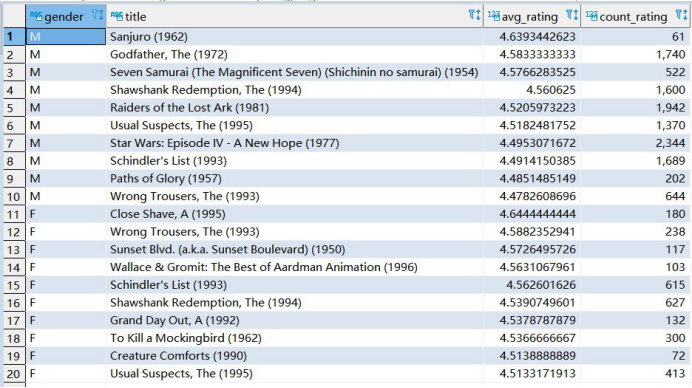
3、分別求男性,女性當中評分最高的10部電影(性別,電影名,影評分),評分人數大于等于50
SELECT * from (SELECT 'M' as gender, title, AVG(rating) avg_rating, count(rating) count_rating from (SELECT --三張表關聯,拿到性別,電影名,影評分 t2.gender, t3.title, t1.rating from t_rating t1 left join t_user t2 on t1.userid = t2.userid left join t_movie t3 on t1.movieid = t3.movieid where t2.gender = 'M' ) t4 group by title HAVING count_rating >= 50 order by avg_rating DESC LIMIT 10 ) a UNION ALL SELECT * from (SELECT 'F' as gender, title, AVG(rating) avg_rating, count(rating) count_rating from (SELECT --三張表關聯,拿到性別,電影名,影評分 t2.gender, t3.title, t1.rating from t_rating t1 left join t_user t2 on t1.userid = t2.userid left join t_movie t3 on t1.movieid = t3.movieid where t2.gender = 'F' ) t4 group by title HAVING count_rating >= 50 order by avg_rating DESC LIMIT 10 ) b
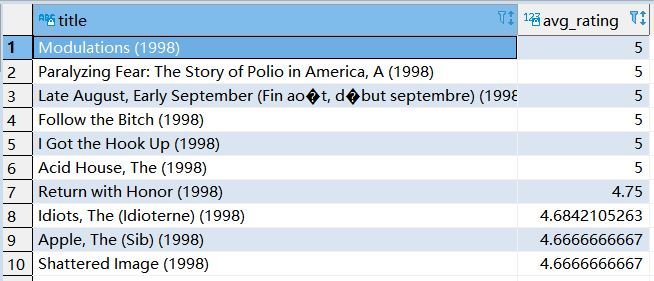
4、求好片(評分>=4.0)最多的那個年份的最好看的10部電影
SELECT title, avg_rating from (SELECT t1.title, SUBSTRING(t1.title,-5,4) year, avg(t2.rating) avg_rating from t_movie t1 left join t_rating t2 on t1.movieid = t2.movieid where t2.rating >= 4 group by t1.title ) t4 where year IN (SELECT year from (SELECT year, COUNT(year) count_year from (SELECT t1.title, SUBSTRING(t1.title,-5,4) year from t_movie t1 left join t_rating t2 on t1.movieid = t2.movieid where t2.rating >= 4 group by t1.title ) t3 group by year order by count_year DESC LIMIT 1) t5 ) order by avg_rating DESC limit 10;
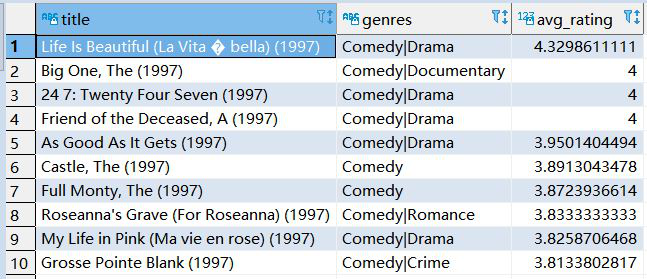
5、求1997年上映的電影中,評分最高的10部Comedy類電影
SELECT title, genres, AVG(rating) avg_rating from (SELECT t1.title, substr(t1.title,-5,4) year, t1.genres, t2.rating from t_movie t1 left join t_rating t2 on t1.movieid = t2.movieid ) t3 where year = '1997' and genres LIKE '%Comedy%' group by title,genres order by avg_rating DESC LIMIT 10;
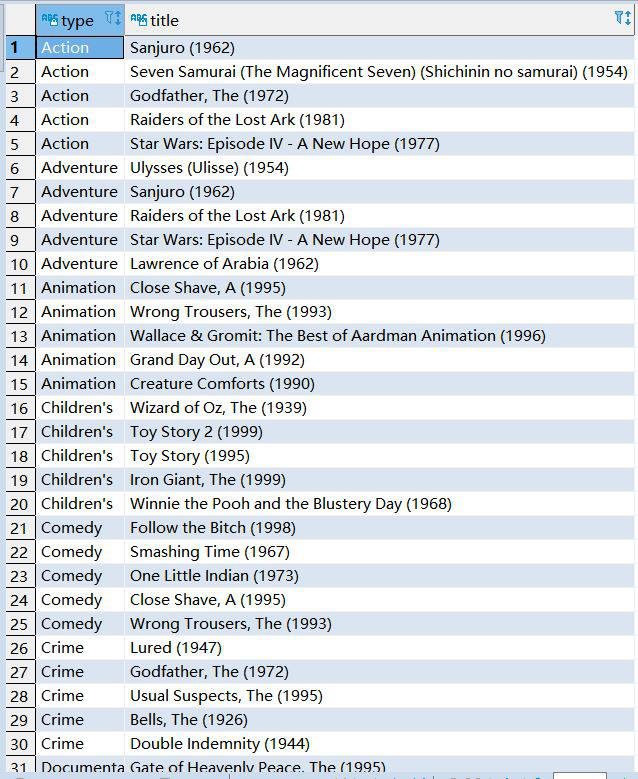
6、該影評庫中各種型別電影中評價最高的5部電影(型別,電影名,平均影評分)
SELECT type, title FROM (SELECT title, type, ROW_NUMBER() over(partition by type order by avg_rating DESC) rn from (SELECT title, type, AVG(rating) avg_rating from (select t2.genres, t2.title, t1.rating from t_rating t1 left join t_movie t2 on t1.movieid =t2.movieid ) t3 lateral view explode(split(t3.genres,"\\|")) tmp as type group by type,title ) t4 )t5 where rn <= 5;
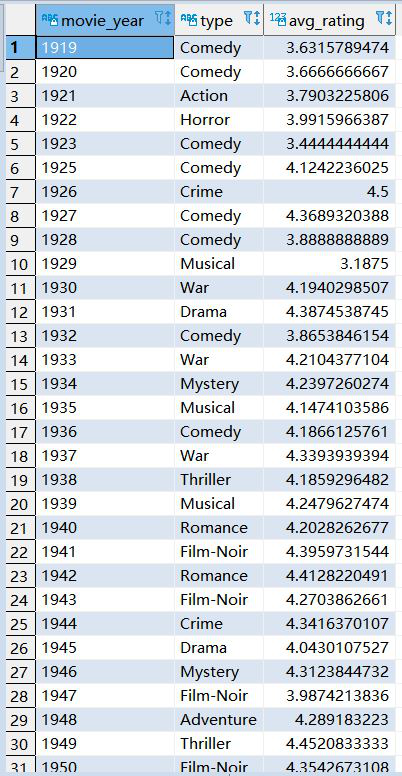
7、各年評分最高的電影型別(年份,型別,影評分)
with tmp as (SELECT title, type, rating, movie_year from (select t2.genres, t2.title, t1.rating, SUBSTRING(t2.title,-5,4) as movie_year from t_rating t1 left join t_movie t2 on t1.movieid =t2.movieid ) t3 lateral view explode(split(t3.genres,"\\|")) tmp as type ) select movie_year, type, avg_rating from (select movie_year, type, avg_rating, ROW_NUMBER() over(partition by movie_year order by avg_rating DESC) rn FROM (select movie_year, type, AVG(rating) avg_rating FROM tmp group by movie_year,type ) t1 ) t2 where rn = 1;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/207126.html
標籤:其他
上一篇:SQL 速查
下一篇:在杭州找pb程式員作業的面試經歷