親愛的各位社區朋友:
Apache Kylin 在 2014 年 10 月開源并加入 Apache 軟體基金會的范訓器,一年后從范訓器畢業成為 Apache 頂級專案,從第一天起,Kylin 的標語是「Extreme OLAP Engine for Big Data」,五年來,Kylin 已經成為了大資料版圖中一個不可或缺的角色,幫助了全球上千家企業進行高效的大資料分析,
經過五年的發展,如今回頭看,我們發現 Kylin 已經不僅僅是一個 OLAP 分析引擎,它的完整能力已經被被廣大社區用戶證實超越了「OLAP Engine」的范疇,被廣泛應用于不同的場景,扮演更加全面的角色:
- 當年 eBay 發起 Kylin 專案時,寄希望它能夠將部分負載從昂貴的專有商業資料倉庫如 Teradata 遷移到廉價、開放的大資料平臺上,五年過去了,Kylin 憑借高性能和高可用性在 eBay 內部被廣泛使用,而 Teradata 逐步被替換,今天,Kylin 在 eBay 每天服務數百萬次查詢,且大多數查詢在 1 秒鐘內完成,
- 美團、攜程、京東、滴滴、小米、華為、丁香園,OLX 集團、汽車之家、Xactly 等許多公司都使用 Kylin 打造了他們的 DaaS(資料即服務)平臺,為成千上萬的分析師和租戶提供資料服務,
- 一些微軟 SSAS 的用戶也正在逐步遷移到 Kylin 上,以承載更大的資料容量和獲得更好的體驗,
- 中國銀聯和某頭部保險集團從 IBM Cognos 架構升級到 Hadoop + Kylin,因為分布式架構的優勢,Kylin 對傳統方案具備降維打擊的能力,在某些場景中,一個 Kylin Cube 取代了數百個 Cognos Cube,不但管理運維的復雜度大大降低,并且具有更好的構建性能和查詢性能,
- 建設銀行、農業銀行等已經使用 Kylin + Hadoop 來構建下一代大資料分析平臺,解決擴容難和并發低的難題,
從這些用戶案例可以看出,社區用戶們不僅僅把 Kylin 當作功能單一的引擎使用,而是使用 Kylin 來替換傳統分析型資料倉庫的作業,下面我們就來看一下什么是資料倉庫吧,
資料倉庫的定義有很多,下面是一個廣泛被接納的定義【1】:A data warehouse is a subject-oriented, integrated, time-variant and non-volatile collection of data in support of management’s decision-making process.
翻譯一下就是:資料倉庫是面向主題的、集成的、體現時間變化的,以及非易變的一組資料集合,以支持管理者做出關鍵決策,
對照到 Kylin 的能力:
- 在 Kylin 中,你可以為每個分析主題或場景,創建一個或多個OLAP Cube;每個 Cube 都是面向特定主題的,
- Kylin 與 Hadoop、 Hive、Spark、Kafka 等系統實作了無縫集成,你可以在大資料平臺上很容易地使用它,這也是為什么 Kylin 很容易被接納的原因之一,
- Kylin會按照時間來磁區加載資料,構建 Cube,然后保存為片段(也稱磁區);對于維度表,Kylin 每次會生成快照,這些資料在分析程序中是穩定的,不會隨意改變,
- 當你在分析(上滾、下鉆等)程序中,Kylin 的資料是穩定一致的,所有層級的匯總結果都嚴格一致,
- Kylin 提供了 SQL 查詢介面和 JDBC/ODBC/HTTP API,用戶將其與 BI/可視化工具(如 Tableau 等)輕松連接,
從這里可以看出,Kylin 的實作,與資料倉庫的關鍵特性不謀而合,事實上,當初設計 Kylin 的時候,團隊也是受了資料倉庫概念非常大的影響,
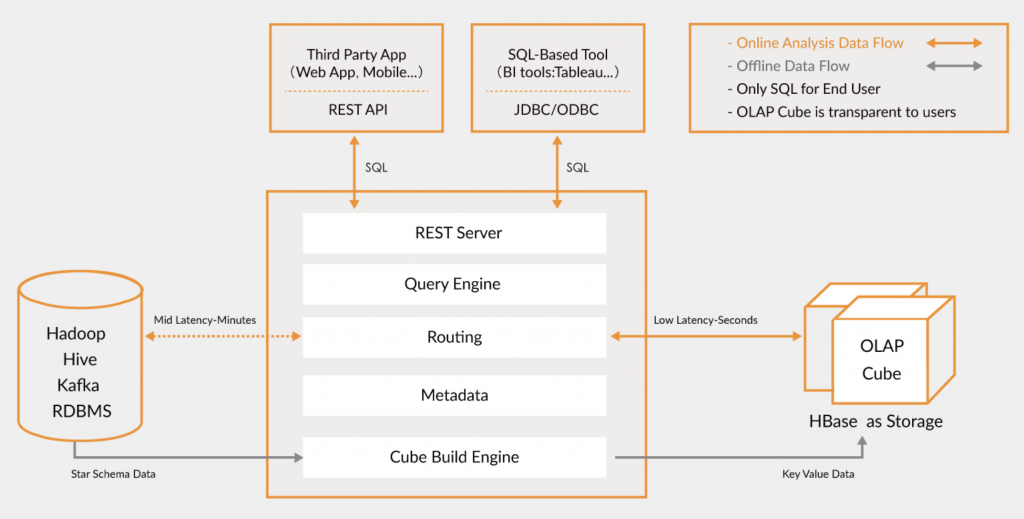
經過社區開發者們的不斷努力,如今 Kylin 不再只是一個加速器,它提供了豐富完整的能力:友好的 Web 界面,向導式的設計器,自動化的任務生成和資料加載,高性能的查詢和存盤引擎,完善的 API 介面,完整的用戶權限和安全控制等,結合 Hadoop 的分布式存盤和計算框架,它已經足以構成一個完整的分析型資料倉庫方案,在開源大資料技術中,Kylin 是獨一無二的,融合了傳統資料倉庫的經典理論和大資料的前沿技術;它設計優雅,架構可擴展可插拔,能夠適應從 GB 到 PB 甚至 EB 規模的資料,
2020 年 3 月,Kylin 社區通過討論,決定將 Kylin 的標語從「Extreme OLAP Engine for Big Data」更改為 「Analytical Data Warehouse for Big Data」【2】,以更加準確地描述 Kylin 的能力和定位,也更容易地讓用戶通過搜索引擎檢索到它,將它推介給更多用戶,應用于更多場景中,
一路走來,感謝各位的貢獻與支持,下一個五年,期待有更多創新!
史少鋒
Apache Kylin PMC Chair
相關閱讀:
【1】 https://walkerscott.co/2017/10/data-warehouse/
【2】 https://kylin.apache.org/
了解更多大資料資訊,點擊進入Kyligence官網
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/22828.html
標籤:大數據
上一篇:nifi processer介紹
下一篇:資料分析與挖掘