clickhouse 簡介
ck是一個列式存盤的資料庫,其針對的場景是OLAP,OLAP的特點是:
- 資料不經常寫,即便寫也是批量寫,不像OLTP是一條一條寫
- 大多數是讀請求
- 查詢并發較少,不適合放置先生高并發業務場景使用 , CK本身建議最大一秒100個并發查詢,
- 不要求事務
click的優點
為了增強壓縮比例,ck存盤的一列長度固,于是存盤的時候,不用在存盤該列的長度資訊
使用向量引擎 , vector engine ,什么是向量引擎?
https://www.infoq.cn/article/columnar-databases-and-vectorization/?itm_source=infoq_en&itm_medium=link_on_en_item&itm_campaign=item_in_other_langs
clickhouse的缺點
- 不能完整支持事務
- 不能很高吞吐量的修改或洗掉資料
- 由于索引的稀疏性,不適合基于key來查詢單個記錄
性能優化
為了提高插入性能,最好批量插入,最少批次是1000行記錄,且使用并發插入能顯著提高插入速度,
訪問介面
ck像es一樣暴露兩個埠,一個tcp的,一個http的,tcp默認埠:9000 ,http默認埠:8123,一般我們并不直接通過這些埠與ck互動,而是使用一些客戶端,這些客戶端可以是:
- Command-line Client 通過它可以鏈接ck,然后進行基本的crud操作,還可以匯入資料到ck ,它使用tcp埠鏈接ck
- http interface : 能像es一樣,通過rest方式,按照ck自己的語法,提交crud
- jdbc driver
- odbc driver
輸入輸出格式
ck能夠讀寫多種格式做為輸入(即insert),也能在輸出時(即select )吐出指定的格式,
比如插入資料時,指定資料源的格式為JSONEachRow
INSERT INTO UserActivity FORMAT JSONEachRow {"PageViews":5, "UserID":"4324182021466249494", "Duration":146,"Sign":-1} {"UserID":"4324182021466249494","PageViews":6,"Duration":185,"Sign":1}
讀取資料時,指定格式為JSONEachRow
SELECT * FROM UserActivity FORMAT JSONEachRow
值得注意的時指定這些格式應該是ck決議或生成的格式,并不是ck最終的的存盤格式,ck應該還是按自己的列式格式進行存盤,ck支持多種格式,具體看檔案
https://clickhouse.yandex/docs/en/interfaces/formats/#native
資料庫引擎
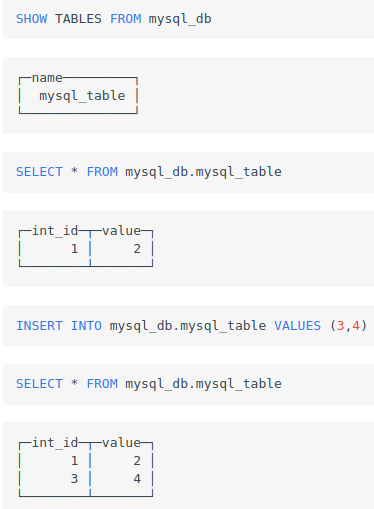
ck支持在其中ck中創建一個資料庫,但資料庫的實際存盤是Mysql,這樣就可以通過ck對該庫中表的資料進行crud, 有點像hive中的外表,只是這里外掛的是整個資料庫,
假設mysql中有以下資料
mysql> USE test;
Database changed
mysql> CREATE TABLE `mysql_table` (
-> `int_id` INT NOT NULL AUTO_INCREMENT,
-> `float` FLOAT NOT NULL,
-> PRIMARY KEY (`int_id`));
Query OK, 0 rows affected (0,09 sec)
mysql> insert into mysql_table (`int_id`, `float`) VALUES (1,2);
Query OK, 1 row affected (0,00 sec)
mysql> select * from mysql_table;
+--------+-------+
| int_id | value |
+--------+-------+
| 1 | 2 |
+--------+-------+
1 row in set (0,00 sec)
在ck中創建資料庫,鏈接上述mysql
CREATE DATABASE mysql_db ENGINE = MySQL('localhost:3306', 'test', 'my_user', 'user_password')
然后就可以在ck中,對mysql庫進行一系列操作
表引擎(table engine)—MergeTree 家族
表引擎定義一個表創建是時候,使用什么引擎進行存盤,表引擎控制如下事項
- 資料如何讀寫以及,以及存盤位置
- 支持的查詢能力
- 資料并發訪問能力
- 資料的replica特征
MergeTree 引擎
建表時,指定table engine相關配置
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr]
[SETTINGS name=value, ...]
- 該引擎會資料進行磁區存盤,
- 資料插入時,不同磁區的資料,會分為不同的資料段(data part), ck后臺再對這些data part做合并,不同的磁區的data part不會合到一起
- 一個data part 由有許多不可分割的最小granule組成
部分配置舉例
ENGINE MergeTree() PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate, intHash32(UserID)) SAMPLE BY intHash32(UserID) SETTINGS index_granularity=8192
granule
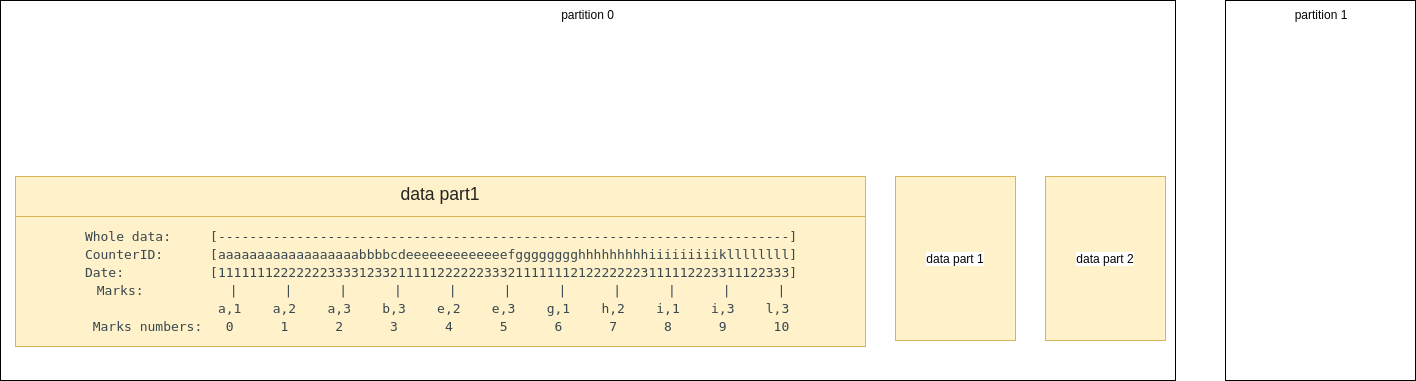
gruanule是按主鍵排序后,緊鄰在一起,不可再分割的資料集,每個granule 的第一行資料的主鍵作為這個資料作為這個資料集的mark ,比如這里的主鍵是(CounterID, Date),第一個granule排序的第一列資料,其主鍵為a,1 ,可以看到多一個gruanle中的多行資料,其主鍵可以相同,
同時為了方便索引,ck會對每個granule指定一個mark number, 方便實際使用的(通過編號,總比通過實際的主鍵值要好使用一點),
這種索引結構非常像跳表,也稱為稀疏索引,因為它不是對每一行資料做索引,而是以排序后的資料范圍做索引,
查詢舉例,如果我們想查詢CounterID in ('a', 'h'),ck服務器基于上述結構,實際讀取的資料范圍為[0, 3) and [6, 8)
可以在建表時,通過index_granularity指定,兩個mark之間存盤的行記錄數,也即granule的大小(因為兩個mark間就是一個granule)
TTL
可以對表和欄位進行過期設定
MergeTree 總結
MergeTree 相當于MergeTree家族表引擎的超類,它定義整個MergeTree家族的資料檔案存盤的特征,即
- 有資料合并
- 有稀疏索引,像跳表一樣的資料結構,來存盤資料集,
- 可以指定資料磁區
而在此資料基礎上,衍生出了一些列增對不同應用場景的子MergeTree,他們分別是
- ReplacingMergeTree 自動移除primary key相同的資料
- SummingMergeTree 能夠將相同主鍵的,數字型別欄位進行sum, 最后存為一行,這相當于預聚合,它能減少存盤空間,提升查詢性能
- AggregatingMergeTree 能夠將同一主鍵的資料,按一定規則聚合,減少資料存盤,提高聚合查詢的性能,相當于預聚合,
- CollapsingMergeTree 將大多數列內容都相同,但是部分列值不同,但是資料是成對的行合并,比如列的值是1和-1
ReplicatedMergeTree 引擎
ck中創建的表,默認都是沒有replicate的,為了提高可用性,需要引入replicate,ck的引入方式是通過集成zookeeper實作資料的replicate副本,
正對上述的各種預聚合引擎,也有對應的ReplicatedMergeTree 引擎進行支持
- ReplicatedMergeTree
- ReplicatedSummingMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedVersionedCollapsingMergeTree
- ReplicatedGraphiteMergeTree
表引擎(table engine)— Log Engine 家族
該系串列引擎正對的是那種會持續產生需要小表,并且各個表資料量都不大的日志場景,這些引擎的特點是:
- 資料存盤在磁盤上
- 以apeend方式新增資料
- 寫是加鎖,讀需等待,也即查詢性能不高
表引擎(table engine)— 外部資料源
ck建表時,還支持許多外部資料源引擎,他們應該是像hive 外表一樣,只是建立了一個表形態的鏈接,實際存盤還是源資料源,(這個有待確認)
這些外部資料源表引擎有:
- Kafka
- MySQL
- JDBC
- ODBC
- HDFS
Sql語法
sample 陳述句
在建表的時候,可以指定基于某個列的散列值做sample (之所以hash散列,是為了保證抽樣的均勻和隨機).這樣我們在查詢的時候,可以不用對全表資料做處理,而是基于sample抽樣一部分資料,進行結構計算就像,比如全表有100個人,如果要計算這一百個人的總成績,可以使用sample取十個人,將其成績求和后,乘以10,sample適用于那些不需要精確計算,并且對計算耗時非常敏感的業務場景,
安裝事宜
一些tips
生產環境關掉swap file
Disable the swap file for production environments.
記錄集群運行情況的一些表
system.metrics, system.events, and system.asynchronous_metrics tables.
安裝環境配置
cpu頻率控制
Linux系統,會根據任務的負荷對cpu進行降頻或升頻,這些調度升降程序會影響到ck的性能,使用以下配置,將cpu的頻率開到最大
echo 'performance' | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
linux系統頻率可能的配置如下:

運行超額分配記憶體
基于swap 磁盤機制,Linux系統可以支持應用系統對超過物理記憶體實際大小的,記憶體申請,基本原理是將一部分的不用的資料,swap到硬碟,騰出空間給正在用的資料,這樣對上層應用來看,仿佛擁有了很大的記憶體量,這種允許超額申請記憶體的行為叫:Overcommiting Memory
控制Overcommiting Memory行為的有三個數值
- 0: The Linux kernel is free to overcommit memory (this is the default), a heuristic algorithm is applied to figure out if enough memory is available.
- 1: The Linux kernel will always overcommit memory, and never check if enough memory is available. This increases the risk of out-of-memory situations, but also improves memory-intensive workloads.
- 2: The Linux kernel will not overcommit memory, and only allocate as much memory as defined in overcommit_ratio.
ck需要盡可能多的記憶體,所以需要開啟超額申請的功能,修改配置如下
echo 0 | sudo tee /proc/sys/vm/overcommit_memory
關閉透明記憶體
Huge Pages 作業系統為了提速處理,將部分應用記憶體頁放到了處理器中,這個頁叫hug pages,而為了透明化這一程序,linux啟用了khugepaged內核執行緒來專門負責此事,這種透明自動化的方式叫: transparent hugepages , 但自動化的方式會帶來記憶體泄露的風險,具體原因看參考鏈接,
所以CK安裝期望關閉該選項:
echo 'never' | sudo tee /sys/kernel/mm/transparent_hugepage/enabled
盡量用大的網路帶寬
如果是ipv6的話,需要增大 route cache
不要將zk和ck裝在一起
ck會盡可能的多占用資源來保證性能,所以如果跟zk裝在一起,ck會影響zk,使其吞吐量下降,延遲增高
開啟zk日志清理功能
zk默認不會洗掉過期的snapshot和log檔案,榷訓月累將是個定時炸彈,所以需要修改zk配置,啟用autopurge功能,yandex的配置如下:
zk配置zoo.cfg
# http://hadoop.apache.org/zookeeper/docs/current/zookeeperAdmin.html
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=30000
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=10
maxClientCnxns=2000
maxSessionTimeout=60000000
# the directory where the snapshot is stored.
dataDir=/opt/zookeeper/{{ cluster['name'] }}/data
# Place the dataLogDir to a separate physical disc for better performance
dataLogDir=/opt/zookeeper/{{ cluster['name'] }}/logs
autopurge.snapRetainCount=10
autopurge.purgeInterval=1
# To avoid seeks ZooKeeper allocates space in the transaction log file in
# blocks of preAllocSize kilobytes. The default block size is 64M. One reason
# for changing the size of the blocks is to reduce the block size if snapshots
# are taken more often. (Also, see snapCount).
preAllocSize=131072
# Clients can submit requests faster than ZooKeeper can process them,
# especially if there are a lot of clients. To prevent ZooKeeper from running
# out of memory due to queued requests, ZooKeeper will throttle clients so that
# there is no more than globalOutstandingLimit outstanding requests in the
# system. The default limit is 1,000.ZooKeeper logs transactions to a
# transaction log. After snapCount transactions are written to a log file a
# snapshot is started and a new transaction log file is started. The default
# snapCount is 10,000.
snapCount=3000000
# If this option is defined, requests will be will logged to a trace file named
# traceFile.year.month.day.
#traceFile=
# Leader accepts client connections. Default value is "yes". The leader machine
# coordinates updates. For higher update throughput at thes slight expense of
# read throughput the leader can be configured to not accept clients and focus
# on coordination.
leaderServes=yes
standaloneEnabled=false
dynamicConfigFile=/etc/zookeeper-{{ cluster['name'] }}/conf/zoo.cfg.dynamic
對應的jvm引數
NAME=zookeeper-{{ cluster['name'] }}
ZOOCFGDIR=/etc/$NAME/conf
# TODO this is really ugly
# How to find out, which jars are needed?
# seems, that log4j requires the log4j.properties file to be in the classpath
CLASSPATH="$ZOOCFGDIR:/usr/build/classes:/usr/build/lib/*.jar:/usr/share/zookeeper/zookeeper-3.5.1-metrika.jar:/usr/share/zookeeper/slf4j-log4j12-1.7.5.jar:/usr/share/zookeeper/slf4j-api-1.7.5.jar:/usr/share/zookeeper/servlet-api-2.5-20081211.jar:/usr/share/zookeeper/netty-3.7.0.Final.jar:/usr/share/zookeeper/log4j-1.2.16.jar:/usr/share/zookeeper/jline-2.11.jar:/usr/share/zookeeper/jetty-util-6.1.26.jar:/usr/share/zookeeper/jetty-6.1.26.jar:/usr/share/zookeeper/javacc.jar:/usr/share/zookeeper/jackson-mapper-asl-1.9.11.jar:/usr/share/zookeeper/jackson-core-asl-1.9.11.jar:/usr/share/zookeeper/commons-cli-1.2.jar:/usr/src/java/lib/*.jar:/usr/etc/zookeeper"
ZOOCFG="$ZOOCFGDIR/zoo.cfg"
ZOO_LOG_DIR=/var/log/$NAME
USER=zookeeper
GROUP=zookeeper
PIDDIR=/var/run/$NAME
PIDFILE=$PIDDIR/$NAME.pid
SCRIPTNAME=/etc/init.d/$NAME
JAVA=/usr/bin/java
ZOOMAIN="org.apache.zookeeper.server.quorum.QuorumPeerMain"
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
JMXLOCALONLY=false
JAVA_OPTS="-Xms{{ cluster.get('xms','128M') }} \
-Xmx{{ cluster.get('xmx','1G') }} \
-Xloggc:/var/log/$NAME/zookeeper-gc.log \
-XX:+UseGCLogFileRotation \
-XX:NumberOfGCLogFiles=16 \
-XX:GCLogFileSize=16M \
-verbose:gc \
-XX:+PrintGCTimeStamps \
-XX:+PrintGCDateStamps \
-XX:+PrintGCDetails
-XX:+PrintTenuringDistribution \
-XX:+PrintGCApplicationStoppedTime \
-XX:+PrintGCApplicationConcurrentTime \
-XX:+PrintSafepointStatistics \
-XX:+UseParNewGC \
-XX:+UseConcMarkSweepGC \
-XX:+CMSParallelRemarkEnabled"
資料備份
資料除了存盤在ck之外,可以在hdfs中保留一份,以防止ck資料丟失后,無法恢復,
組態檔
ck的默認組態檔為/etc/clickhouse-server/config.xml,你可以在其中指定所有的服務器配置,
當然你可以將各種不同的配置分開,比如user的配置,和quota的配置,單獨放一個檔案,其余檔案放置的路徑為
/etc/clickhouse-server/config.d
ck最侄訓將所有的配置合在一起生成一個完整的配置file-preprocessed.xml
各個分開的配置,可以覆寫或洗掉主配置中的相同配置,使用replace或remove屬性就行,比如
<query_masking_rules>
<rule>
<name>hide SSN</name>
<regexp>\b\d{3}-\d{2}-\d{4}\b</regexp>
<replace>000-00-0000</replace>
</rule>
</query_masking_rules>
同時ck還可以使用zk做為自己的配置源,即最終組態檔的生成,會使用zk中的配置,
默認情況下:
users, access rights, profiles of settings, quotas這些設定都在users.xml
一些最佳實踐
一些最佳配置實踐:
1.寫入時,不要使用distribution 表,怕出現資料不一致
2.設定background_pool_size ,提升Merge的速度,因為merge執行緒就是使用這個執行緒池
3.設定max_memory_usage和max_memory_usage_for_all_queries,限制ck使用物理記憶體的大小,因為使用記憶體過大,作業系統會將ck行程殺死
4.設定max_bytes_before_external_sort和max_bytes_before_external_group_by,來使得聚合的sort和group在需要大記憶體且記憶體超過上述限制時,不至于失敗,可以轉而使用硬碟進行處理
一些踩坑處理:
1.Too many parts(304). Merges are processing significantly slower than inserts 問題是因為插入的太平凡,插入速度超過了后臺merge的速度,解決版本辦法是,增大background_pool_size和降低插入速度,官方建議“每秒不超過1次的insert request”,實際是每秒的寫入影響不要超過一個檔案,如果寫入的資料涉及多個磁區檔案,很可能還是出現這個問題,所以磁區的設定一定要合理
2.DB::NetException: Connection reset by peer, while reading from socket xxx ,很有可能是沒有配置max_memory_usage和max_memory_usage_for_all_queries,導致記憶體超限,ck server被作業系統殺死
3.Memory limit (for query) exceeded:would use 9.37 GiB (attempt to allocate chunk of 301989888 bytes), maximum: 9.31 GiB ,是由于我們設定了ck server的記憶體使用上線,那些超限的請求被ck殺死,但ck本身并沒有掛,這個時候就要增加max_bytes_before_external_sort和max_bytes_before_external_group_by配置,來利用上硬碟
4.ck的副本和分片依賴zk,所以zk是個很大的性能瓶頸,需要對zk有很好的認識和配置,甚至啟用多個zk集群來支持ck集群
5.zk和ck建議都使用ssd,提升性能
對應文章:https://mp.weixin.qq.com/s/egzFxUOAGen_yrKclZGVag
參考資料
https://clickhouse.yandex/docs/en/operations/tips/
http://engineering.pivotal.io/post/virtual_memory_settings_in_linux_-_the_problem_with_overcommit/
https://blog.nelhage.com/post/transparent-hugepages/
https://wiki.archlinux.org/index.php/CPU_frequency_scaling
歡迎關注我的個人公眾號"西北偏北UP",記錄代碼人生,行業思考,科技評論
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/228951.html
標籤:大數據
上一篇:女士品茶和佛系推廣
下一篇:Python網路爬蟲(一)