本文原始碼:GitHub || GitEE
一、Sqoop概述
Sqoop是一款開源的大資料組件,主要用來在Hadoop(Hive、HBase等)與傳統的資料庫(mysql、postgresql、oracle等)間進行資料的傳遞,
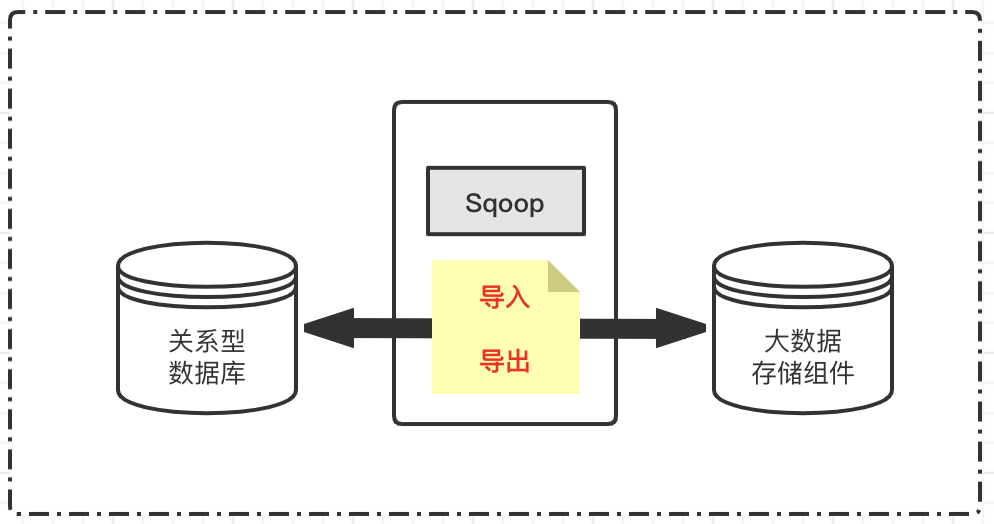
通常資料搬運的組件基本功能:匯入與匯出,
鑒于Sqoop是大資料技術體系的組件,所以關系型資料庫匯入Hadoop存盤系統稱為匯入,反過來稱為匯出,
Sqoop是一個命令列的組件工具,將匯入或匯出命令轉換成mapreduce程式來實作,mapreduce中主要是對inputformat和outputformat進行定制,
二、環境部署
在測驗Sqoop組件的時候,起碼要具備Hadoop系列、關系型資料、JDK等基礎環境,
鑒于Sqoop是工具類組件,單節點安裝即可,
1、上傳安裝包
安裝包和版本:sqoop-1.4.6
[root@hop01 opt]# tar -zxf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
[root@hop01 opt]# mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop1.4.6
2、修改組態檔
檔案位置:sqoop1.4.6/conf
[root@hop01 conf]# pwd
/opt/sqoop1.4.6/conf
[root@hop01 conf]# mv sqoop-env-template.sh sqoop-env.sh
配置內容:涉及hadoop系列常用組件和調度組件zookeeper,
[root@hop01 conf]# vim sqoop-env.sh
# 配置內容
export HADOOP_COMMON_HOME=/opt/hadoop2.7
export HADOOP_MAPRED_HOME=/opt/hadoop2.7
export HIVE_HOME=/opt/hive1.2
export HBASE_HOME=/opt/hbase-1.3.1
export ZOOKEEPER_HOME=/opt/zookeeper3.4
export ZOOCFGDIR=/opt/zookeeper3.4
3、配置環境變數
[root@hop01 opt]# vim /etc/profile
export SQOOP_HOME=/opt/sqoop1.4.6
export PATH=$PATH:$SQOOP_HOME/bin
[root@hop01 opt]# source /etc/profile
4、引入MySQL驅動
[root@hop01 opt]# cp mysql-connector-java-5.1.27-bin.jar sqoop1.4.6/lib/
5、環境檢查
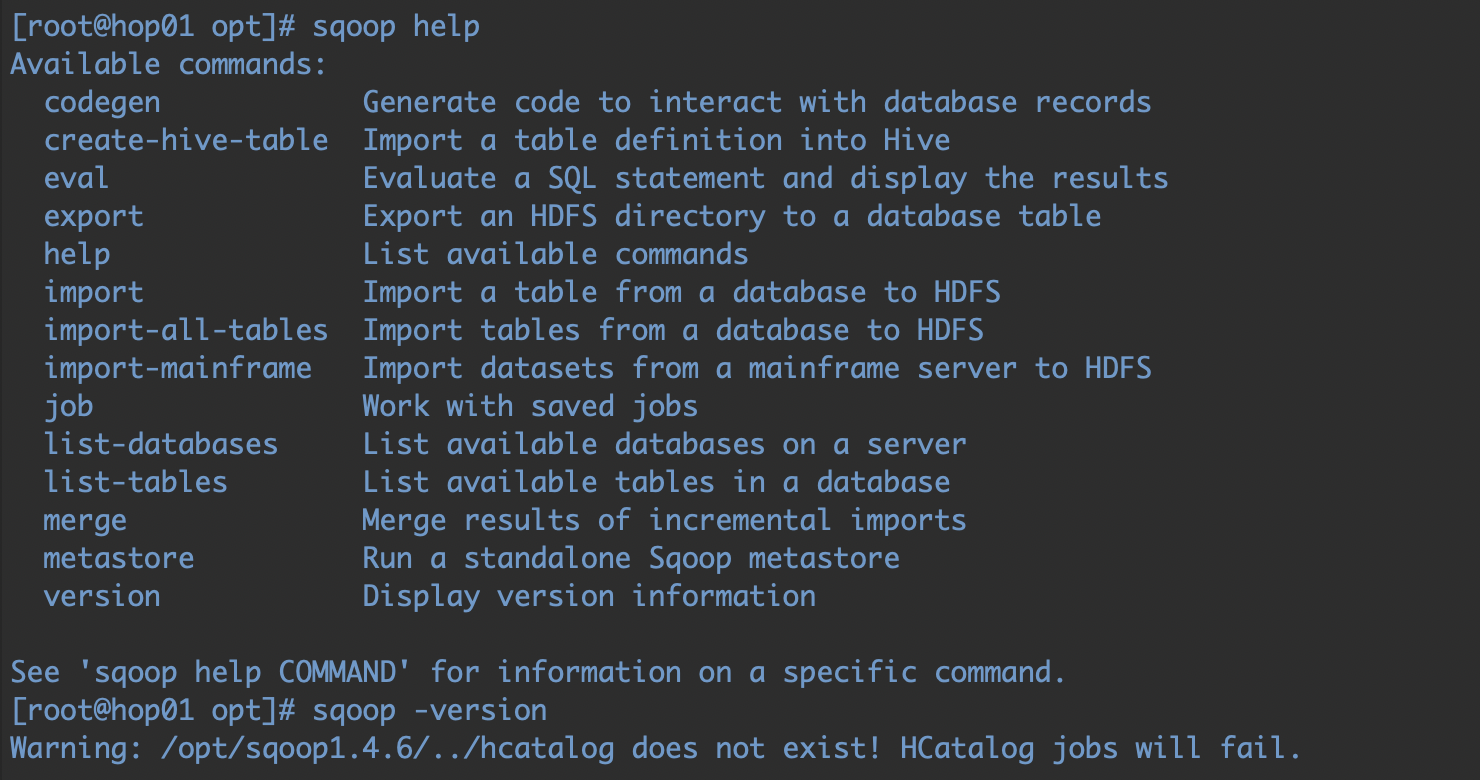
關鍵點:import與export
查看幫助命令,并通過version查看版本號,sqoop是一個基于命令列操作的工具,所以這里的命令下面還要使用,
6、相關環境
此時看下sqoop部署節點中的相關環境,基本都是集群模式:
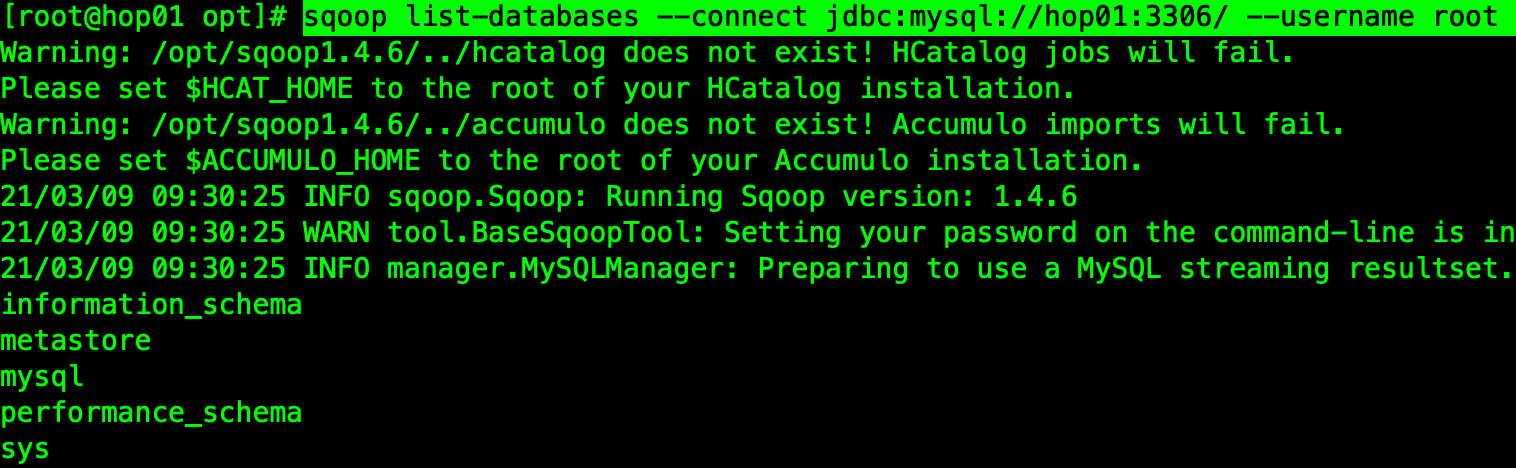
7、測驗MySQL連接
sqoop list-databases --connect jdbc:mysql://hop01:3306/ --username root --password 123456
這里是查看MySQL資料庫的命令,如圖結果列印正確:
三、資料匯入案例
1、MySQL資料腳本
CREATE TABLE `tb_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主鍵id',
`user_name` varchar(100) DEFAULT NULL COMMENT '用戶名',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用戶表';
INSERT INTO `sq_import`.`tb_user`(`id`, `user_name`) VALUES (1, 'spring');
INSERT INTO `sq_import`.`tb_user`(`id`, `user_name`) VALUES (2, 'c++');
INSERT INTO `sq_import`.`tb_user`(`id`, `user_name`) VALUES (3, 'java');
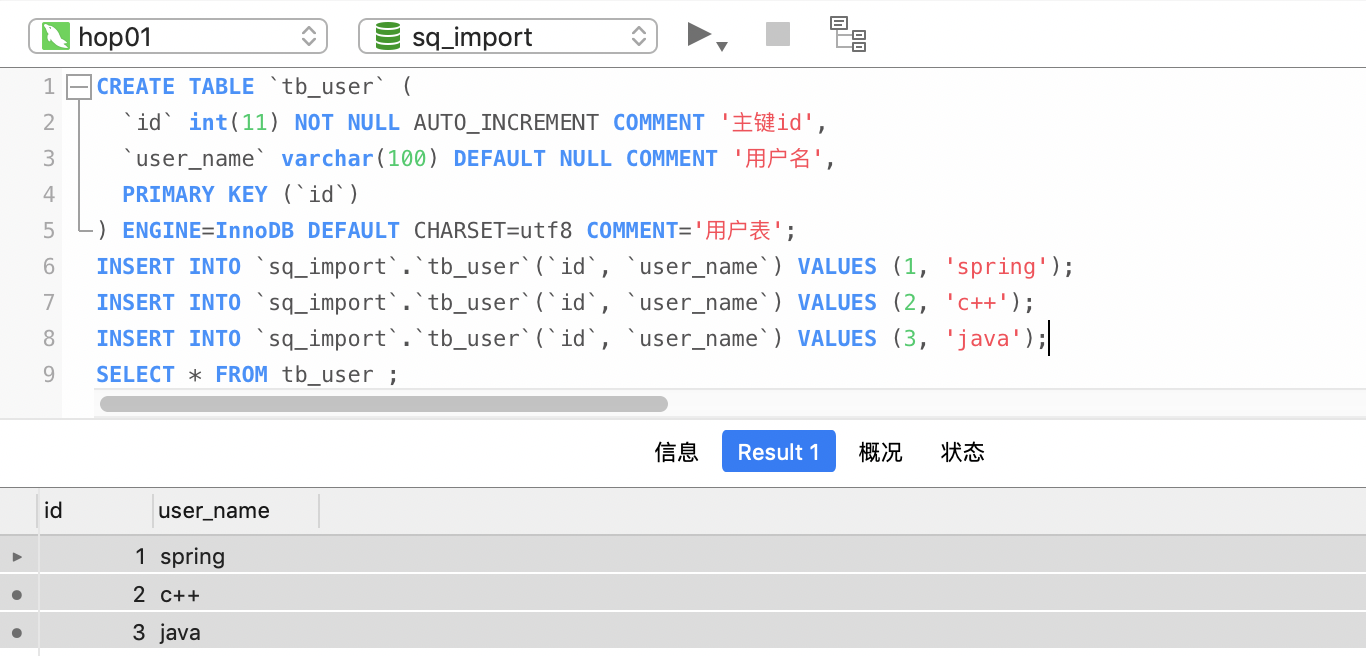
2、Sqoop匯入腳本
指定資料庫的表,全量匯入Hadoop系統,注意這里要啟動Hadoop服務;
sqoop import
--connect jdbc:mysql://hop01:3306/sq_import \
--username root \
--password 123456 \
--table tb_user \
--target-dir /hopdir/user/tbuser0 \
-m 1
3、Hadoop查詢
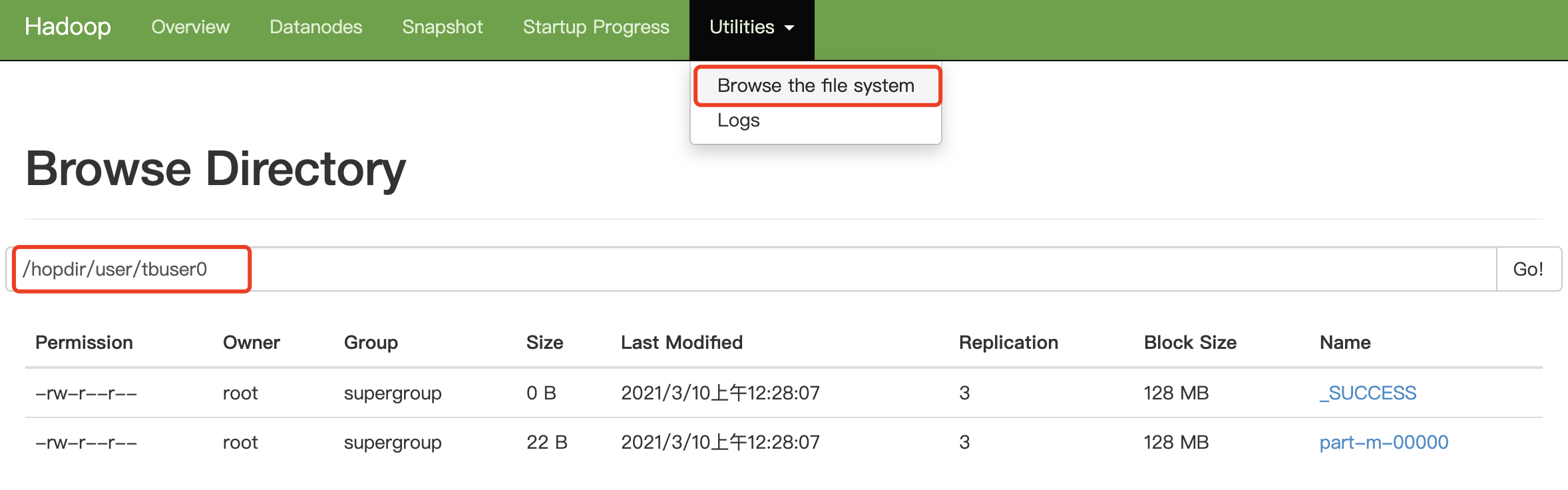
[root@hop01 ~]# hadoop fs -cat /hopdir/user/tbuser0/part-m-00000
4、指定列和條件
查詢的SQL陳述句中必須帶有WHERE$CONDITIONS:
sqoop import
--connect jdbc:mysql://hop01:3306/sq_import \
--username root \
--password 123456 \
--target-dir /hopdir/user/tbname0 \
--num-mappers 1 \
--query 'select user_name from tb_user where 1=1 and $CONDITIONS;'
查看匯出結果:
[root@hop01 ~]# hadoop fs -cat /hopdir/user/tbname0/part-m-00000
5、匯入Hive組件
在不指定hive使用的資料庫情況下,默認匯入default庫,并且自動創建表名稱:
sqoop import
--connect jdbc:mysql://hop01:3306/sq_import \
--username root \
--password 123456 \
--table tb_user \
--hive-import \
-m 1
執行程序,這里注意觀察sqoop的執行日志即可:
第一步:MySQL的資料匯入到HDFS的默認路徑下;
第二步:把臨時目錄中的資料遷移到hive表中;

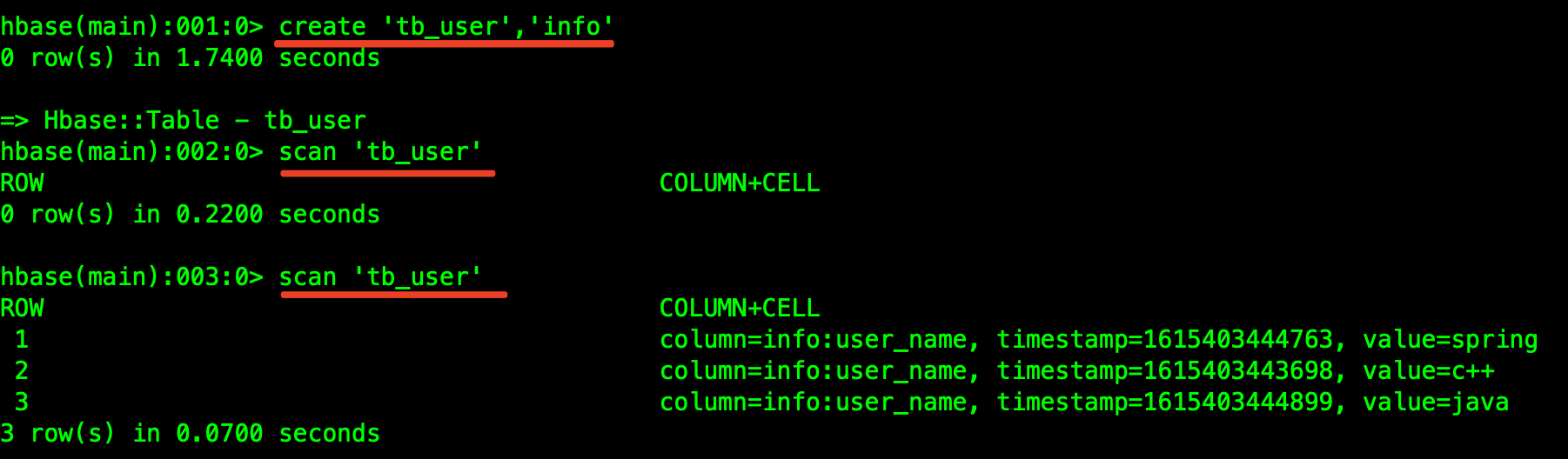
6、匯入HBase組件
當前hbase的集群版本是1.3,需要先創建好表,才能正常執行資料匯入:
sqoop import
--connect jdbc:mysql://hop01:3306/sq_import \
--username root \
--password 123456 \
--table tb_user \
--columns "id,user_name" \
--column-family "info" \
--hbase-table tb_user \
--hbase-row-key id \
--split-by id
查看HBase中表資料:
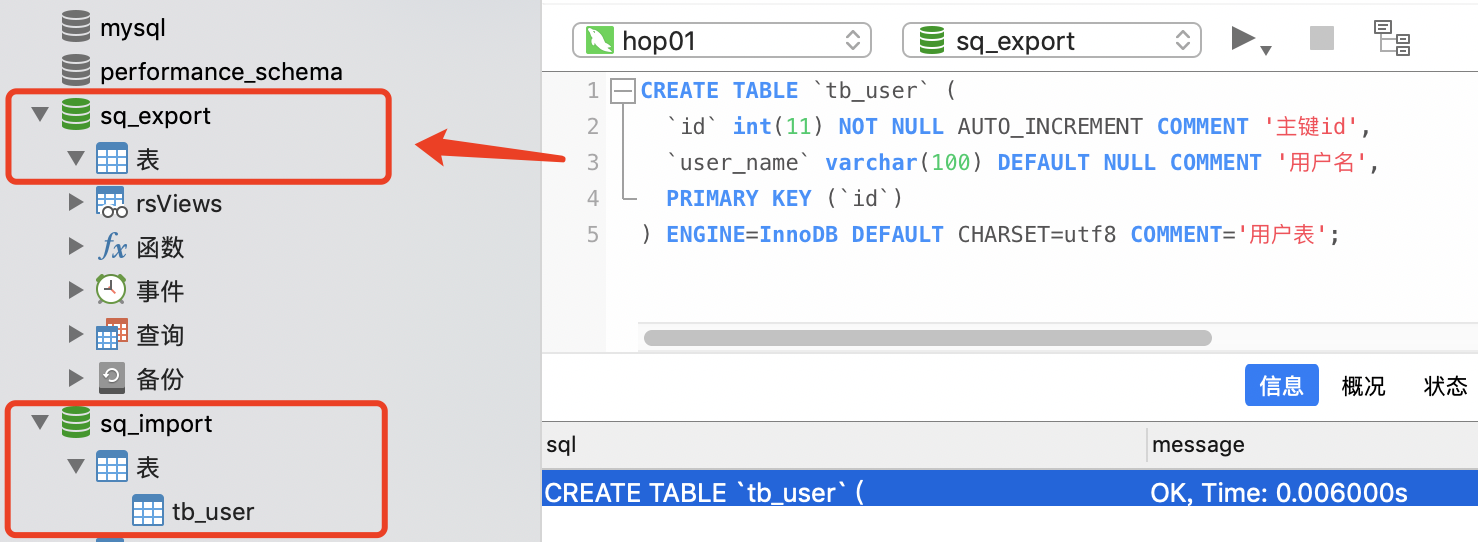
四、資料匯出案例
新建一個MySQL資料庫和表,然后把HDFS中的資料匯出到MySQL中,這里就使用第一個匯入腳本生成的資料即可:
sqoop export
--connect jdbc:mysql://hop01:3306/sq_export \
--username root \
--password 123456 \
--table tb_user \
--num-mappers 1 \
--export-dir /hopdir/user/tbuser0/part-m-00000 \
--num-mappers 1 \
--input-fields-terminated-by ","
再次查看MySQL中資料,記錄完全被匯出來,這里,是每個資料欄位間的分隔符號,語法規則對照腳本一HDFS資料查詢結果即可,
五、源代碼地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent
閱讀標簽
【Java基礎】【設計模式】【結構與演算法】【Linux系統】【資料庫】
【分布式架構】【微服務】【大資料組件】【SpringBoot進階】【Spring&Boot基礎】
【資料分析】【技術導圖】【 職場】

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/270977.html
標籤:大數據
上一篇:「視頻小課堂」Logstash如何成為鎮得住場面的資料管道(文字版)
下一篇:incubator-dolphinscheduler 如何在不寫任何新代碼的情況下,能快速接入到prometheus和grafana中進行監控