Hadoop是一個由Apache基金會所開發的分布式基礎架構,Hadoop的框架最核心的設計就是:HDFS和MapReduce,HDFS為海量的資料提供了存盤,而MapReduce則為海量的資料提供了計算,特點是:高可靠性,高擴展性,高效性,高容錯性,
Hadoop與Google三篇論文
- Google-File-System :http://blog.bizcloudsoft.com/wp-content/uploads/Google-File-System%E4%B8%AD%E6%96%87%E7%89%88_1.0.pdf
- Google-Mapreduce:http://blog.bizcloudsoft.com/wp-content/uploads/Google-MapReduce%E4%B8%AD%E6%96%87%E7%89%88_1.0.pdf
- Google-Bigtable:http://blog.bizcloudsoft.com/wp-content/uploads/Google-Bigtable%E4%B8%AD%E6%96%87%E7%89%88_1.0.pd
Hadoop架構
Hadoop1.x與Hadoop2.x的區別:
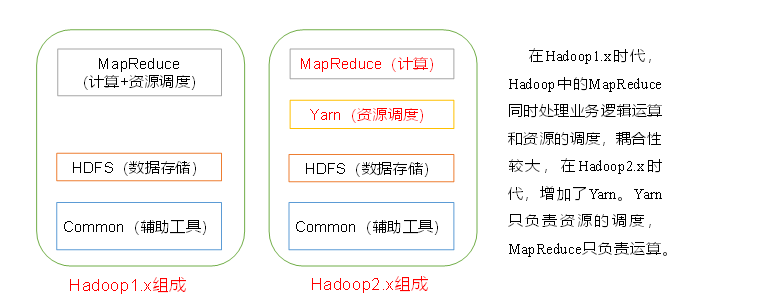
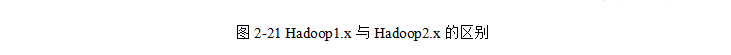
Hadoop整體框架來看:
Hadoop1.0由分布式存盤系統HDFS和分布式計算框架MapReduce組成,其中HDFS由一個NameNode和多個DateNode組成,MapReduce由一個JobTracker和多個TaskTracker組成,
1.x與2.x區別
HDFS角度來看:
- Hadoop2.x新增了HDFS HA增加了standbynamenode進行熱點備份,解決了1.x的單點故障
- Hadoop2.x新增了HDFS federation,解決了 HDFS的水平擴展能力,

Mapreduce角度來看:
2.x相比與1.x新增了YRAN框架,Mapreduce的運行環境發生了變化
在1.0中:由一個JobTracker和若干個TaskTracker兩類服務組成,其中JobTracker負責資源管理和所有作業的控制,TaskTracker負責接收來自JobTracker的命令并執行它,所以MapReduce即是任務調度框架又是計算框架,1.0中會出現JobTracker大包大攬任務過重,而且存在單點故障問題,并且容易出現OOM問題,資源分配不合理等問題,
在2.0中:MASTER端由ResourceManager進行資源管理調度,有ApplicationMaster進行任務管理和任務監控,SLAVE端由NodeManager替代TaskTracker進行具體任務的執行,所以MapReduce2.0只是一個計算框架,具體資源調度全部交給Yarn框架,
2.X和3.X最主要區別:
|
對比 |
2.X特性 |
3.X特性 |
|
License |
Hadoop 2.x - Apache 2.0,開源 |
Hadoop 3.x - Apache 2.0,開源 |
|
支持的最低Java版本 |
java的最低支持版本是java 7 |
java的最低支持版本是java 8 |
|
容錯 |
可以通過復制(浪費空間)來處理容錯, |
可以通過Erasure編碼處理容錯, |
|
資料平衡 |
對于資料,平衡使用HDFS平衡器, |
對于資料,平衡使用Intra-data節點平衡器,該平衡器通過HDFS磁盤平衡器CLI呼叫, |
|
存盤Scheme |
使用3X副本Scheme |
支持HDFS中的擦除編碼, |
|
存盤開銷 |
HDFS在存盤空間中有200%的開銷, |
存盤開銷僅為50%, |
|
存盤開銷示例 |
如果有6個塊,那么由于副本方案(Scheme),將有18個塊占用空間, |
如果有6個塊,那么將有9個塊空間,6塊block,3塊用于奇偶校驗, |
|
YARN時間線服務 |
使用具有可伸縮性問題的舊時間軸服務, |
改進時間線服務v2并提高時間線服務的可擴展性和可靠性, |
|
默認埠范圍 |
在Hadoop 2.0中,一些默認埠是Linux臨時埠范圍,所以在啟動時,他們將無法系結, |
但是在Hadoop 3.0中,這些埠已經移出了短暫的范圍, |
|
工具 |
使用Hive,pig,Tez,Hama,Giraph和其他Hadoop工具, |
可以使用Hive,pig,Tez,Hama,Giraph和其他Hadoop工具, |
|
兼容的檔案系統 |
HDFS(默認FS),FTP檔案系統:它將所有資料存盤在可遠程訪問的FTP服務器上, Amazon S3(簡單存盤服務)檔案系統Windows Azure存盤Blob(WASB)檔案系統, |
它支持所有前面以及Microsoft Azure Data Lake檔案系統, |
|
Datanode資源 |
Datanode資源不專用于MapReduce,我們可以將它用于其他應用程式, |
此處資料節點資源也可用于其他應用程式, |
|
MR API兼容性 |
與Hadoop 1.x程式兼容的MR API,可在Hadoop 2.X上執行 |
此處,MR API與運行Hadoop 1.x程式兼容,以便在Hadoop 3.X上執行 |
|
支持Microsoft Windows |
它可以部署在Windows上, |
它也支持Microsoft Windows, |
|
插槽/容器 |
Hadoop 1適用于插槽的概念,但Hadoop 2.X適用于容器的概念,通過容器,我們可以運行通用任務, |
它也適用于容器的概念, |
|
單點故障 |
具有SPOF的功能,因此只要Namenode失敗,它就會自動恢復, |
具有SPOF的功能,因此只要Namenode失敗,它就會自動恢復,無需人工干預就可以克服它, |
|
HDFS聯盟 |
在Hadoop 1.0中,只有一個NameNode來管理所有Namespace,但在Hadoop 2.0中,多個NameNode用于多個Namespace, |
Hadoop 3.x還有多個名稱空間用于多個名稱空間, |
|
可擴展性 |
我們可以擴展到每個群集10,000個節點, |
更好的可擴展性, 我們可以為每個群集擴展超過10,000個節點, |
|
更快地訪問資料 |
由于資料節點快取,我們可以快速訪問資料, |
這里也通過Datanode快取我們可以快速訪問資料, |
|
HDFS快照 |
Hadoop 2增加了對快照的支持, 它為用戶錯誤提供災難恢復和保護, |
Hadoop 2也支持快照功能, |
|
平臺 |
可以作為各種資料分析的平臺,可以運行事件處理,流媒體和實時操作, |
這里也可以在YARN的頂部運行事件處理,流媒體和實時操作, |
|
群集資源管理 |
對于群集資源管理,它使用YARN, 它提高了可擴展性,高可用性,多租戶, |
對于集群,資源管理使用具有所有功能的YARN, |
3.x的新特性參考:https://www.cnblogs.com/smartloli/p/9028267.html ;https://www.cnblogs.com/smartloli/p/8827623.html
HDFS(Hadoop Distributed File System)架構概述
- NameNode(NN):存盤檔案的元資料,如檔案名,檔案目錄結構,檔案屬性(生成時間,副本數,檔案權限),以及每個檔案的塊串列和所在的DataNode等,
- DataNode(DN):在本地檔案系統存盤的檔案資料,以及塊資料的校驗和,
- Secondary NameNode(2NN):用來監控HDFS狀態的輔助后臺程式,每隔一段時間獲取HDFS元資料的快照,
YARN架構概述
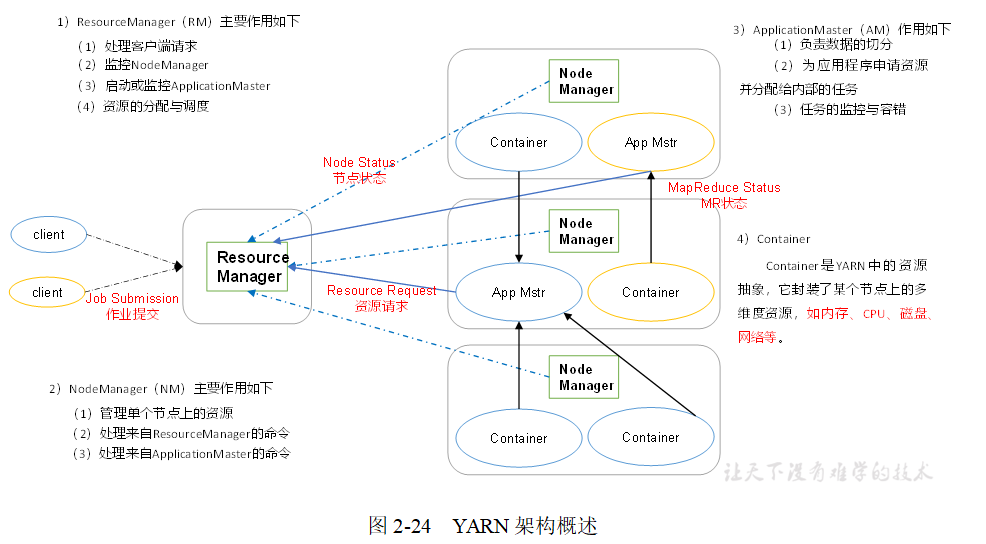
MapReduce將計算程序分為兩個階段:Map和Reduce,如圖2-25所示
1)Map階段并行處理輸入資料
2)Reduce階段對Map結果進行匯總
大資料技術生態體系
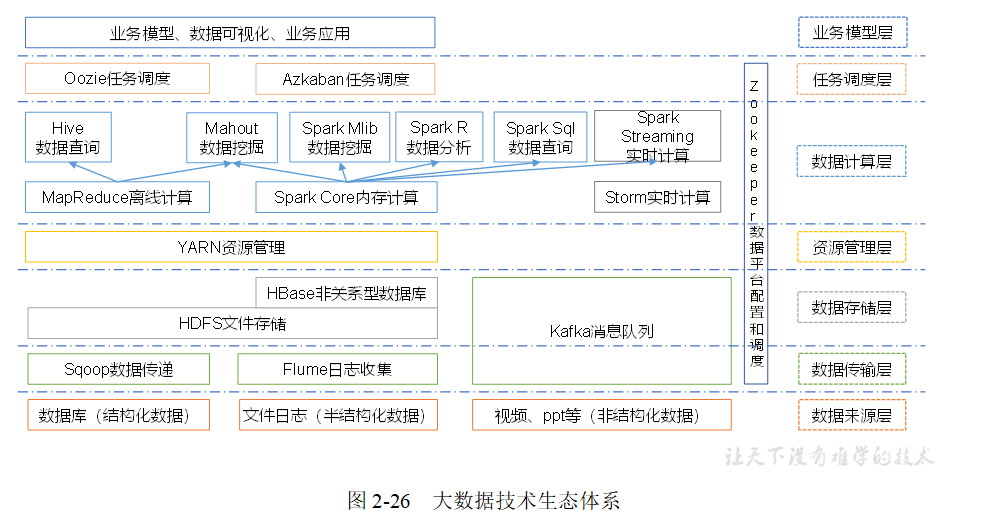
圖中涉及的技術名詞解釋如下:
1)Sqoop:Sqoop是一款開源的工具,主要用于在Hadoop、Hive與傳統的資料庫(MySql)間進行資料的傳遞,可以將一個關系型資料庫(例如 :MySQL,Oracle 等)中的資料導進到Hadoop的HDFS中,也可以將HDFS的資料導進到關系型資料庫中,
2)Flume:Flume是Cloudera提供的一個高可用的,高可靠的,分布式的海量日志采集、聚合和傳輸的系統,Flume支持在日志系統中定制各類資料發送方,用于收集資料;同時,Flume提供對資料進行簡單處理,并寫到各種資料接受方(可定制)的能力,
3)Kafka:Kafka是一種高吞吐量的分布式發布訂閱訊息系統,有如下特性:
(1)通過O(1)的磁盤資料結構提供訊息的持久化,這種結構對于即使數以TB的訊息存盤也能夠保持長時間的穩定性能,
(2)高吞吐量:即使是非常普通的硬體Kafka也可以支持每秒數百萬的訊息,
(3)支持通過Kafka服務器和消費機集群來磁區訊息,
(4)支持Hadoop并行資料加載,
4)Storm:Storm用于“連續計算”,對資料流做連續查詢,在計算時就將結果以流的形式輸出給用戶,
5)Spark:Spark是當前最流行的開源大資料記憶體計算框架,可以基于Hadoop上存盤的大資料進行計算,
6)Oozie:Oozie是一個管理Hdoop作業(job)的作業流程調度管理系統,
7)Hbase:HBase是一個分布式的、面向列的開源資料庫,HBase不同于一般的關系資料庫,它是一個適合于非結構化資料存盤的資料庫,
8)Hive:Hive是基于Hadoop的一個資料倉庫工具,可以將結構化的資料檔案映射為一張資料庫表,并提供簡單的SQL查詢功能,可以將SQL陳述句轉換為MapReduce任務進行運行, 其優點是學習成本低,可以通過類SQL陳述句快速實作簡單的MapReduce統計,不必開發專門的MapReduce應用,十分適合資料倉庫的統計分析,
10)R語言:R是用于統計分析、繪圖的語言和操作環境,R是屬于GNU系統的一個自由、免費、源代碼開放的軟體,它是一個用于統計計算和統計制圖的優秀工具,
11)Mahout:Apache Mahout是個可擴展的機器學習和資料挖掘庫,
12)ZooKeeper:Zookeeper是Google的Chubby一個開源的實作,它是一個針對大型分布式系統的可靠協調系統,提供的功能包括:配置維護、名字服務、 分布式同步、組服務等,ZooKeeper的目標就是封裝好復雜易出錯的關鍵服務,將簡單易用的介面和性能高效、功能穩定的系統提供給用戶,
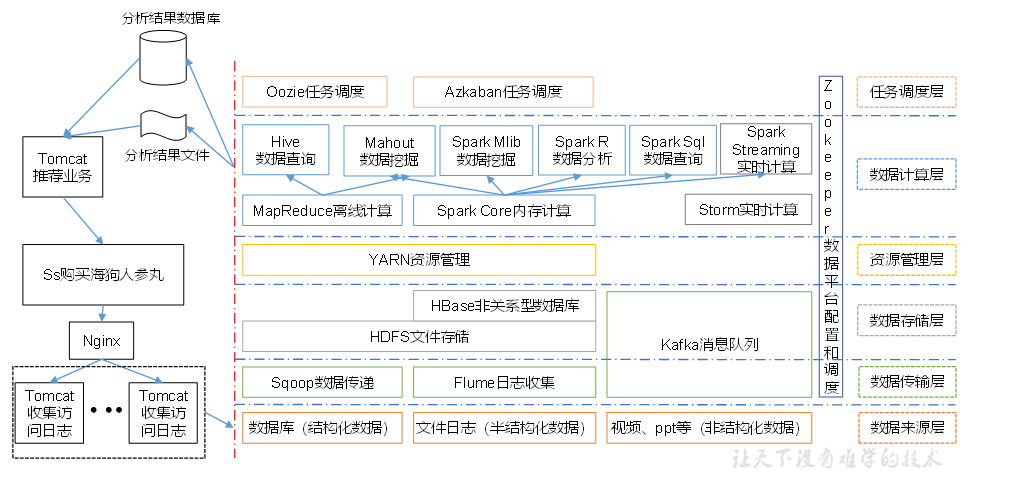
推薦系統框架圖
Hadoop集群搭建
虛擬機環境準備 -----/etc/hosts:
- 克隆虛擬機
- 修改克隆虛擬機的靜態IP
- 修改主機名
- 關閉防火墻
- 創建用戶gll
- 配置gll用戶具有root權限
- 在/opt目錄下創建檔案夾
(1)在/opt目錄下創建module、software檔案夾 [atguigu@hadoop101 opt]$ sudo mkdir module [atguigu@hadoop101 opt]$ sudo mkdir software (2)修改module、software檔案夾的所有者cd [atguigu@hadoop101 opt]$ sudo chown atguigu:atguigu module/ software/ [atguigu@hadoop101 opt]$ ll 總用量 8 drwxr-xr-x. 2 atguigu atguigu 4096 1月 17 14:37 module drwxr-xr-x. 2 atguigu atguigu 4096 1月 17 14:38 software
安裝JDK
卸載現有JDK
(1)查詢是否安裝Java軟體: [atguigu@hadoop101 opt]$ rpm -qa | grep java (2)如果安裝的版本低于1.7,卸載該JDK: [atguigu@hadoop101 opt]$ sudo rpm -e 軟體包 (3)查看JDK安裝路徑: [atguigu@hadoop101 ~]$ which java
在Linux系統下的opt目錄中查看軟體包是否匯入成功
[atguigu@hadoop101 opt]$ cd software/ [atguigu@hadoop101 software]$ ls hadoop-2.7.2.tar.gz jdk-8u144-linux-x64.tar.gz
解壓JDK到/opt/module目錄下
[atguigu@hadoop101 software]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
配置JDK環境變數
(1)先獲取JDK路徑 [atguigu@hadoop101 jdk1.8.0_144]$ pwd /opt/module/jdk1.8.0_144 (2)打開/etc/profile檔案 [atguigu@hadoop101 software]$ sudo vi /etc/profile 在profile檔案末尾添加JDK路徑 #JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_144 export PATH=$PATH:$JAVA_HOME/bin (3)保存后退出 :wq (4)讓修改后的檔案生效 [atguigu@hadoop101 jdk1.8.0_144]$ source /etc/profile 測驗JDK是否安裝成功 atguigu@hadoop101 jdk1.8.0_144]# java -version java version "1.8.0_144" 注意:重啟(如果java -version可以用就不用重啟) [atguigu@hadoop101 jdk1.8.0_144]$ sync [atguigu@hadoop101 jdk1.8.0_144]$ sudo reboot
安裝Hadoop
1.進入到Hadoop安裝包路徑下 [atguigu@hadoop101 ~]$ cd /opt/software/ 2.解壓安裝檔案到/opt/module下面 atguigu@hadoop101 software]$ tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/ 3.查看是否解壓成功 [atguigu@hadoop101 software]$ ls /opt/module/ hadoop-2.7.2 4.將Hadoop添加到環境變數 (1)獲取Hadoop安裝路徑 [atguigu@hadoop101 hadoop-2.7.2]$ pwd /opt/module/hadoop-2.7.2 (2)打開/etc/profile檔案 [atguigu@hadoop101 hadoop-2.7.2]$ sudo vi /etc/profile 在profile檔案末尾添加JDK路徑:(shitf+g) ##HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-2.7.2 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin (3)保存后退出 :wq (4)讓修改后的檔案生效 [atguigu@ hadoop101 hadoop-2.7.2]$ source /etc/profile 5. 測驗是否安裝成功 [atguigu@hadoop101 hadoop-2.7.2]$ hadoop version Hadoop 2.7.2
6. 重啟(如果Hadoop命令不能用再重啟)
[atguigu@ hadoop101 hadoop-2.7.2]$ sync
[atguigu@ hadoop101 hadoop-2.7.2]$ sudo reboot
查看Hadoop目錄
[atguigu@hadoop101 hadoop-2.7.2]$ ll
總用量 52
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 bin
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 etc
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 include
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 lib
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 libexec
-rw-r--r--. 1 atguigu atguigu 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 atguigu atguigu 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 atguigu atguigu 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 sbin
drwxr-xr-x. 4 atguigu atguigu 4096 5月 22 2017 share
2、重要目錄
(1)bin目錄:存放對Hadoop相關服務(HDFS,YARN)進行操作的腳本
(2)etc目錄:Hadoop的組態檔目錄,存放Hadoop的組態檔
(3)lib目錄:存放Hadoop的本地庫(對資料進行壓縮解壓縮功能)
(4)sbin目錄:存放啟動或停止Hadoop相關服務的腳本
(5)share目錄:存放Hadoop的依賴jar包、檔案、和官方案例
集群搭建-Hadoop運行環境搭建
記憶體4G,硬碟50G
1. 安裝好linux
/boot 200M
/swap 2g
/ 剩余
2. *安裝VMTools
3. 關閉防火墻
sudo service iptables stop
sudo chkconfig iptables off
4. 設定靜態IP,改主機名
改ip: 編輯vim /etc/sysconfig/network-scripts/ifcfg-eth0
改成
DEVICE=eth0 TYPE=Ethernet ONBOOT=yes BOOTPROTO=static NAME="eth0" IPADDR=192.168.1.101 PREFIX=24 GATEWAY=192.168.1.2 DNS1=192.168.1.2
改用戶名:
編輯vim /etc/sysconfig/network
改HOSTNAME=那一行
NETWORKING=yes
HOSTNAME=hadoop101
5. 配置/etc/hosts
vim /etc/hosts
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108
192.168.1.109 hadoop109
6. 創建一個一般用戶gll,給他配置密碼
useradd gll
passwd gll
7. 配置這個用戶為sudoers
vim /etc/sudoers
在root ALL=(ALL) ALL
添加gll ALL=(ALL) NOPASSWD:ALL
保存時wq!強制保存
8. *在/opt目錄下創建兩個檔案夾module和software,并把所有權賦給gll
mkdir /opt/module /opt/software
chown gll:gll /opt/module /opt/software
9. 關機,快照,克隆
從這里開始要以一般用戶登陸
10. 克隆的虛擬機;改物理地址
[root@hadoop101 桌面]# vim /etc/udev/rules.d/70-persistent-net.rules
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:5f:8e:d9", ATTR{type}=="1", KERNEL=="eth*",
NAME="eth0"
11. 搞一個分發腳本 cd ~ vim xsync 內容如下:
#!/bin/bash #xxx /opt/module if (($#<1)) then echo '引數不足' exit fi fl=$(basename $1) pdir=$(cd -P $(dirname $1); pwd) for host in hadoop102 hadoop103 do rsync -av $pdir/$fl $host:$pdir done
修改檔案權限,復制移動到/home/gll/bin目錄下
chmod +x xsync
12. 配置免密登陸
1. 生成密鑰對 [gll@hadoop101 ~]$ cd .ssh [gll@hadoop101 .ssh]$ ssh-keygen -t rsa ssh-keygen -t rsa 三次回車
2. 發送公鑰到本機 ssh-copy-id hadoop101 輸入一次密碼
3. 分別ssh登陸一下所有虛擬機 ssh hadoop102 exit ssh hadoop103 exit
4. 把/home/gll/.ssh 檔案夾發送到集群所有服務器 xsync /home/gll/.ssh ##發送.ssh/是不會成功的;不要加最后的/
13. 在一臺機器上安裝Java和Hadoop,并配置環境變數,并分發到集群其他機器
拷貝檔案到/opt/software,兩個tar包 sudo vim /etc/profile 配置環境變數; 在檔案末尾添加 #JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_144 export PATH=$PATH:$JAVA_HOME/bin #HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-2.7.2 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin 保存 5. source /etc/profile 6. 將組態檔分發到其他集群中: [gll@hadoop101 module]$ sudo xsync /etc/profile sudo:xsync:找不到命令 [gll@hadoop101 module]$ sudo scp /etc/profile root@hadoop102:/etc/profile [gll@hadoop101 module]$ sudo scp /etc/profile root@hadoop103:/etc/profile 在hadoop102/hadoop103各執行 source/etc/profile 7. 在其他機器分別執行source /etc/profile 所有組態檔都在$HADOOP_HOME/etc/hadoop
14. 首先配置hadoop-env.sh,yarn-env.sh,mapred-env.sh檔案,配置Java_HOME
在每個檔案第二行添加 export JAVA_HOME=/opt/module/jdk1.8.0_144
15. 配置Core-site.xml
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop101:9000</value> </property> <!-- 指定Hadoop運行時產生檔案的存盤目錄 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property>
16. 配置hdfs-site.xml
<!-- 資料的副本數量 --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定Hadoop輔助名稱節點主機配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop103:50090</value> </property>
17. 配置yarn-site.xml
<!-- Site specific YARN configuration properties --> <!-- Reducer獲取資料的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop102</value> </property> <!-- 日志聚集功能使能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留時間設定7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
18. 配置mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 歷史服務器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop103:10020</value> </property> <!-- 歷史服務器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop103:19888</value> </property>
啟動歷史服務器:mr-jobhistory-daemon.sh start historyserver
19. 配置slaves;配置時多一個空格/空行都不可以;
hadoop101
hadoop102
hadoop103
20. 分發組態檔
xsync /opt/module/hadoop-2.7.2/etc
21. 格式化Namenode 在hadoop102
在hadoop101上啟動 hdfs namenode -format
22. 啟動hdfs
在hadoop101上啟動 start-dfs.sh
23. 在配置了Resourcemanager機器上執行
在Hadoop102上啟動start-yarn.sh
24 關 stop-dfs.sh stop-yarn.sh
mr-jobhistory-daemon.sh stop historyserver
Hadoop運行模式:
Hadoop運行模式:本地模式,偽分布式模式,完全分布式模式,
本地模式:
- 可運行的程式只有Mapreduce程式,而yarn(cpu,記憶體),HDFS(磁盤)均為了Mapreduce提供運行的環境,
- 本地運行存盤不是HDFS,而是本地的磁盤,調度系統也是本地的作業系統,
- 主要用于開發和除錯,
偽分布式模式:
即在一臺服務器上搭建集群,HDFS分3個組建NameNode、DataNode、Secondary NameNode; yarn是分4個組建,實際只搭2個ResourceManage和NodeManager,
既是NameNode也是DataNode;既是ResourceManager也是NodeManager,這些行程都跑在一臺機器上,
###所有組態檔都在$HADOOP_HOME/etc/hadoop
hadoop-env.sh、mapred-env.sh、yarn-env.sh三個檔案中配置:JAVA_HOME 在每個檔案第二行添加 export JAVA_HOME=/opt/module/jdk1.8.0_144 core-site.xml 指定HDFS中NameNode的地址;指定Hadoop運行時產生檔案的存盤目錄 hdfs-site.xml 指定HDFS資料的副本數量 為3,就3臺機器; 這些副本肯定分布在不同的服務器上;指定hadoop輔助名稱節點(secondaryNameNode)主機配置; mapred-site.xml 指定歷史服務器地址;歷史服務器web端地址,指定MR運行在YARN上; yarn-site.xml Reducer獲取資料的方式;指定YARN的ResourceManager的地址(服務器);日志的配置 hdfs namenode -format 格式化HDFS,在hadoop101上; 首次啟動格式化 hadoop-daemon.sh start namenode 單獨啟動NameNode hadoop-daemon.sh start datanode 單獨啟動DataNode start-dfs.sh 啟動hdfs start-yarn.sh 啟動yarn 啟動前必須保證NameNode和DataNode已經啟動 啟動ResourceManager; 啟動NodeManager hadoop fs -put wcinput/ / 往集群的跟目錄中上傳一個wcinput檔案 158 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wcinput /output
分發腳本配置和ssh配置程序
[gll@hadoop100 hadoop-2.7.2]$ dirname /opt/module/hadoop-2.7.2/ /opt/module [gll@hadoop100 hadoop-2.7.2]$ dirname hadoop-2.7.2 . [gll@hadoop100 hadoop-2.7.2]$ cd -P . [gll@hadoop100 hadoop-2.7.2]$ pwd /opt/module/hadoop-2.7.2 遍歷所有的主機名 ##########集群分發腳本 #!/bin/bash #xxx /opt/module if (($#<1)) then echo '引數不足' exit fi fl=$(basename $1) #檔案名 basename /opt/module/hadoop-2.7.2/-->>hadoop-2.7.2 pdir=$(cd -P $(dirname $1); pwd) 父目錄 dirname /opt/module/hadoop-2.7.2/ --->> /opt/module for host in hadoop102 hadoop103 hadoop104 do rsync -av $pdir/$fl $host:$pdir done
scp安全拷貝、rsync遠程同步工具
scp拷貝:可以實作服務器與服務器之間的資料拷貝
rsync拷貝:主要用于備份和鏡像,具有速度快、避免復制相同內容和支持符號鏈接的優點,
rsync和scp區別:用rsync做檔案的復制要比scp的速度快,rsync只對差異檔案做更新,scp是把所有檔案都復制過去,
[atguigu@hadoop101 /]$ scp -r /opt/module root@hadoop102:/opt/module //-r是遞回; 要拷貝的-->目的地
[atguigu@hadoop103 opt]$ scp -r atguigu@hadoop101:/opt/module root@hadoop104:/opt/module //可在不同服務之間傳輸;
[atguigu@hadoop101 opt]$ rsync -av /opt/software/ hadoop102:/opt/software //rsync只能從本機到其他 ;-a歸檔拷貝、-v顯示復制程序
用scp發送
scp -r hadoop100:/opt/module/jdk1.8.0_144 hadoop102:/opt/module/
用rsync發送
[gll@hadoop100 module]$ rsync -av hadoop-2.7.2/ hadoop102:/opt/module/ 把當前目錄下的全發過去了;-a歸檔拷貝、-v顯示復制程序;
[gll@hadoop102 module]$ ls
bin include jdk1.8.0_144 libexec NOTICE.txt README.txt share
etc input lib LICENSE.txt output sbin wcinput
[gll@hadoop102 module]$ ls | grep -v jdk
過濾洗掉只剩jdk的
[gll@hadoop102 module]$ ls | grep -v jdk | xargs rm -rf
[gll@hadoop100 module]$ ll
總用量 12
drwxr-xr-x. 12 gll gll 4096 1月 15 14:55 hadoop-2.7.2
drwxr-xr-x. 8 gll gll 4096 7月 22 2017 jdk1.8.0_144
-rw-rw-r--. 1 gll gll 223 1月 15 17:13 xsync
[gll@hadoop100 module]$ chmod +x xsync
[gll@hadoop100 module]$ ll
總用量 12
drwxr-xr-x. 12 gll gll 4096 1月 15 14:55 hadoop-2.7.2
drwxr-xr-x. 8 gll gll 4096 7月 22 2017 jdk1.8.0_144
-rwxrwxr-x. 1 gll gll 223 1月 15 17:13 xsync
[gll@hadoop100 module]$
[gll@hadoop100 module]$ ./xsync /opt/module/jdk1.8.0_144
注意:拷貝過來的/opt/module目錄,別忘了在hadoop101、hadoop102、hadoop103上修改所有檔案的,所有者和所有者組,sudo chown gll:gll -R /opt/module
拷貝過來的組態檔別忘了source一下/etc/profile
SSH免密登錄配置:
無密鑰配置:
免密登錄原理:
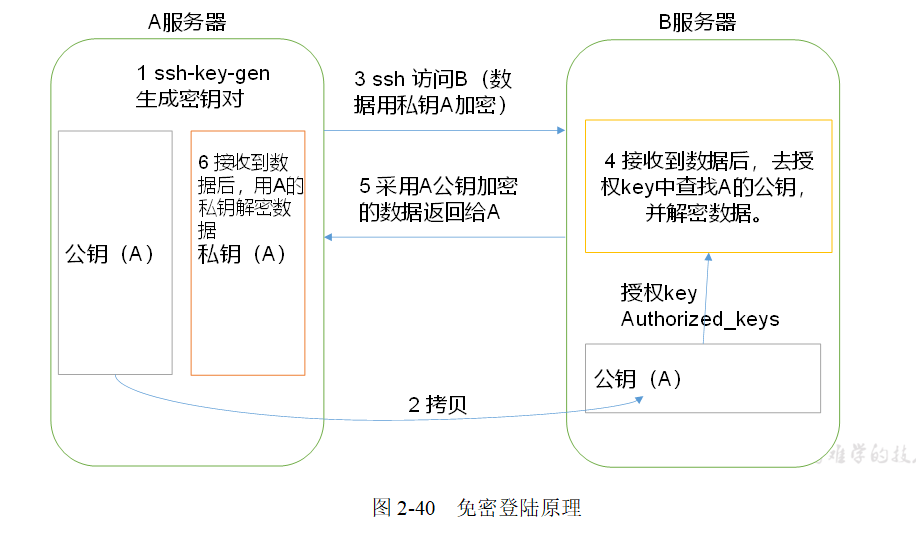
[gll@hadoop100 module]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/gll/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/gll/.ssh/id_rsa. Your public key has been saved in /home/gll/.ssh/id_rsa.pub. The key fingerprint is: fd:15:a4:68:6e:88:c3:a1:f4:64:1b:aa:95:12:02:4a gll@hadoop100 The key's randomart image is: +--[ RSA 2048]----+ |.E . | |+ . o | |o . . = o . . | | . o O = = . | | . = * S + . | | + . . . . | | . . | | | | | +-----------------+ [gll@hadoop100 module]$ ssh-copy-id hadoop100 #給自己也發一份 [gll@hadoop100 module]$ ssh-copy-id hadoop101 [gll@hadoop100 module]$ ssh-copy-id hadoop102 [gll@hadoop100 module]$ ssh-copy-id hadoop103 [gll@hadoop100 module]$ ssh-copy-id hadoop104 100給100、101、102、103、104都賦權了;100<==>100雙向通道已經建立,我能到自己了;可以把這個雙向通道copy給其他的; [gll@hadoop100 .ssh]$ ll 總用量 16 -rw-------. 1 gll gll 396 1月 15 18:45 authorized_keys 把公鑰放在已授權的keys里邊,它跟公鑰里邊內容是一樣的; -rw-------. 1 gll gll 1675 1月 15 18:01 id_rsa 秘鑰 -rw-r--r--. 1 gll gll 396 1月 15 18:01 id_rsa.pub 公鑰 -rw-r--r--. 1 gll gll 2025 1月 15 17:37 known_hosts [gll@hadoop102 .ssh]$ ll 總用量 4 -rw-------. 1 gll gll 396 1月 15 18:04 authorized_keys [gll@hadoop100 module]$ ./xsync /home/gll/.ssh #給其他賬戶發送.ssh ;發送 .ssh/ sending incremental file list .ssh/ .ssh/id_rsa .ssh/id_rsa.pub .ssh/known_hosts sent 4334 bytes received 73 bytes 8814.00 bytes/sec total size is 4096 speedup is 0.93 sudo cp xsync /bin #copy到bin目錄,就可全域使用; [gll@hadoop100 module]$ xsync /opt/module/hadoop-2.7.2/
.ssh檔案夾下(~/.ssh)的檔案功能解釋
表2-4
|
known_hosts |
記錄ssh訪問過計算機的公鑰(public key) |
|
id_rsa |
生成的私鑰 |
|
id_rsa.pub |
生成的公鑰 |
|
authorized_keys |
存放授權過得無密登錄服務器公鑰 |
群起集群
1.配置slaves
/opt/module/hadoop-2.7.2/etc/hadoop/slaves
[gll@hadoop102 hadoop]$ vi slaves
在該檔案中增加如下內容:
hadoop102
hadoop103
hadoop104
注意:該檔案中添加的內容結尾不允許有空格,檔案中不允許有空行,
同步所有節點組態檔
[gll@hadoop102 hadoop]$ xsync slaves
2.啟動集群
(1)如果集群是第一次啟動,需要格式化NameNode(注意格式化之前,一定要先停止上次啟動的所有namenode和datanode行程,然后再洗掉data和log資料)
[gll@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -format
(2)啟動HDFS
[gll@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[gll@hadoop102 hadoop-2.7.2]$ jps
4166 NameNode
4482 Jps
4263 DataNode
[gll@hadoop103 hadoop-2.7.2]$ jps
3218 DataNode
3288 Jps
[gll@hadoop104 hadoop-2.7.2]$ jps
3221 DataNode
3283 SecondaryNameNode
3364 Jps
(3)啟動YARN
[gll@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一臺機器,不能在NameNode上啟動 YARN,應該在ResouceManager所在的機器上啟動YARN,
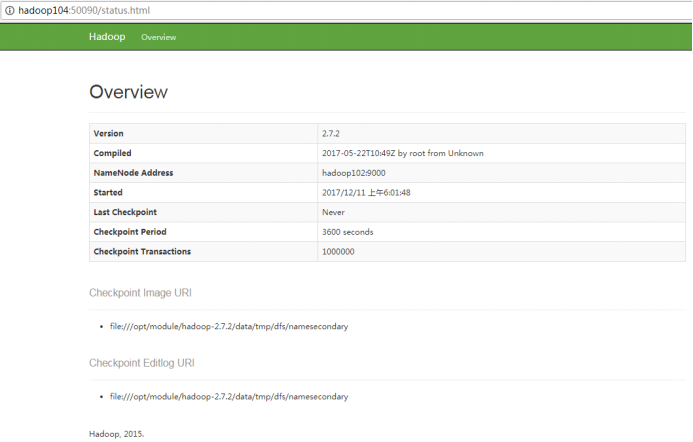
(4)Web端查看SecondaryNameNode
(a)瀏覽器中輸入:http://hadoop104:50090/status.html
(b)查看SecondaryNameNode資訊,如圖2-41所示,
集群基礎測驗:
(1)上傳檔案到集群
上傳小檔案
[gll@hadoop102 hadoop-2.7.2]$ hdfs dfs -mkdir -p /user/gll/input
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfs -put wcinput/wc.input /user/atguigu/input
上傳大檔案
[gll@hadoop102 hadoop-2.7.2]$ bin/hadoop fs -put
/opt/software/hadoop-2.7.2.tar.gz /user/gll/input
(2)上傳檔案后查看檔案存放在什么位置
(a)查看HDFS檔案存盤路徑
[gll@hadoop102 subdir0]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-938951106-192.168.10.107-1495462844069/current/finalized/subdir0/subdir0
(b)查看HDFS在磁盤存盤檔案內容
[gll@hadoop102 subdir0]$ cat blk_1073741825
hadoop yarn
hadoop mapreduce
gll
gll
(3)拼接
-rw-rw-r--. 1 gll gll 134217728 5月 23 16:01 blk_1073741836
-rw-rw-r--. 1 gll gll 1048583 5月 23 16:01 blk_1073741836_1012.meta
-rw-rw-r--. 1 gll gll 63439959 5月 23 16:01 blk_1073741837
-rw-rw-r--. 1 gll gll 495635 5月 23 16:01 blk_1073741837_1013.meta
[gll@hadoop102 subdir0]$ cat blk_1073741836>>tmp.file
[gll@hadoop102 subdir0]$ cat blk_1073741837>>tmp.file
[gll@hadoop102 subdir0]$ tar -zxvf tmp.file
(4)下載
[gll@hadoop102 hadoop-2.7.2]$ bin/hadoop fs -get
/user/gll/input/hadoop-2.7.2.tar.gz ./
集群時間同步:
配置集群是必須集群間時間同步得,所有得機器與這臺集群時間進行定時得同步,比如,每隔十分鐘,同步一次時間 ,

配置時間同步具體實操:
1.時間服務器配置(必須root用戶)
(1)檢查ntp是否安裝
[root@hadoop102 桌面]# rpm -qa|grep ntp
ntp-4.2.6p5-10.el6.centos.x86_64
fontpackages-filesystem-1.41-1.1.el6.noarch
ntpdate-4.2.6p5-10.el6.centos.x86_64
(2)修改ntp組態檔
[root@hadoop102 桌面]# vi /etc/ntp.conf
修改內容如下
a)修改1(授權192.168.1.0-192.168.1.255網段上的所有機器可以從這臺機器上查詢和同步時間)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap為
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域網中,不使用其他互聯網上的時間)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst為
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(當該節點丟失網路連接,依然可以采用本地時間作為時間服務器為集群中的其他節點提供時間同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改/etc/sysconfig/ntpd 檔案
[root@hadoop102 桌面]# vim /etc/sysconfig/ntpd
增加內容如下(讓硬體時間與系統時間一起同步)
SYNC_HWCLOCK=yes
(4)重新啟動ntpd服務
[root@hadoop102 桌面]# service ntpd status
ntpd 已停
[root@hadoop102 桌面]# service ntpd start
正在啟動 ntpd: [確定]
(5)設定ntpd服務開機啟動
[root@hadoop102 桌面]# chkconfig ntpd on
2.其他機器配置(必須root用戶)
(1)在其他機器配置10分鐘與時間服務器同步一次
[root@hadoop103桌面]# crontab -e
撰寫定時任務如下:
*/10 * * * * /usr/sbin/ntpdate hadoop102
(2)修改任意機器時間
[root@hadoop103桌面]# date -s "2017-9-11 11:11:11"
(3)十分鐘后查看機器是否與時間服務器同步
[root@hadoop103桌面]# date
說明:測驗的時候可以將10分鐘調整為1分鐘,節省時間,
自己配置得常用腳本
關閉所有機器:haltall.sh
for i in `cat /opt/module/hadoop-2.7.2/etc/hadoop/slaves` do ssh $i 'source /etc/profile&&sudo halt' done
查看所有機器行程:jpsall:
#!/bin/bash
for((host=100;host<103;host++))
do
echo "==========szhzysdsjfx$host$i =========="
ssh ScflLinux$host$i 'source /etc/profile&&jps'
done
Windows中hosts的配置:
在windows系統中,HOST檔案位于系統盤C:\Windows\System32\drivers\etc中
Hosts是一個沒有擴展名的系統檔案,其作用就是將一些常用的網址域名與其對應的IP地址建立一個關聯“資料庫”,
- hosts檔案能加快域名決議,對于要經常訪問的網站,我們可以通過在Hosts中配置域名和IP的映射關系,提高域名決議速度,
- hosts檔案可以方便局域網用戶在很多單位的局域網中,可以分別給這些服務器取個容易記住的名字,然后在Hosts中建立IP映射,這樣以后訪問的時候,只要輸入這個服務器的名字就行了,
- hosts檔案可以屏蔽一些網站,對于自己想屏蔽的一些網站我們可以利用Hosts把該網站的域名映射到一個錯誤的IP或本地計算機的IP,這樣就不用訪問了,
- 根據這個HOSTS檔案的作用看的出來 ,如果是別有用心的病毒把你的HOSTS檔案修改了!(例如把一個正規的網站改成一個有病毒的網站的IP),那么你就會打開一個帶有病毒的網站,你可想而知你的后果了吧!
查看Windows IP 配置
C:\Users\Administrator>ipconfig /displaydns
修改hosts后生效的方法:Windows 開始 -> 運行 -> 輸入cmd -> 在CMD視窗輸入 ipconfig /flushdns
Linux 終端輸入: sudo rcnscd restart
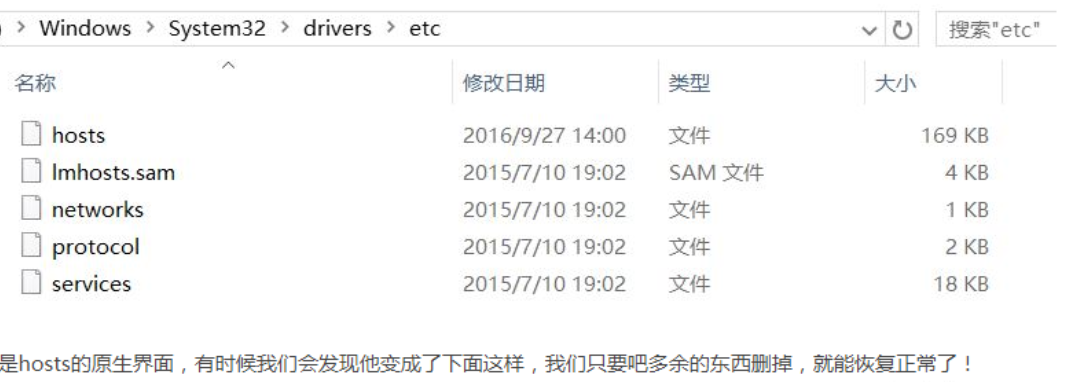
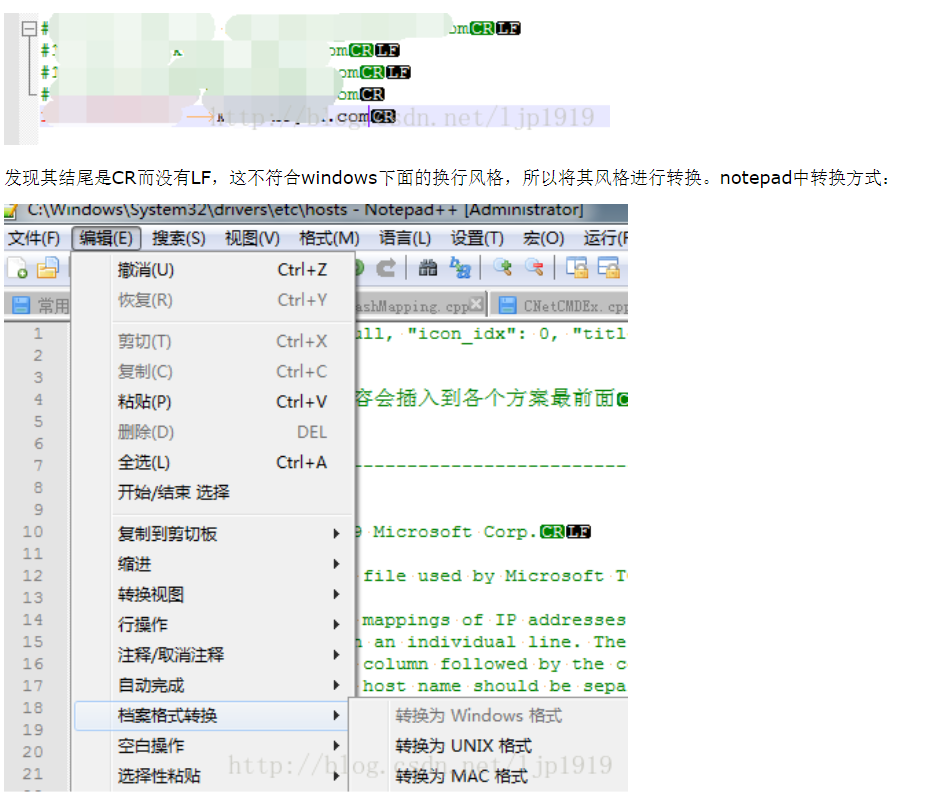
host中的配置沒有被識別到,那么是否是因為字符或者換行等原因呢?于是:
查看了host檔案的字符:

Hadoop默認埠及含義:
常見錯誤和解決問題
1)防火墻沒關閉、或者沒有啟動YARN
INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
2)主機名稱配置錯誤
3)IP地址配置錯誤
4)ssh沒有配置好
5)root用戶和atguigu兩個用戶啟動集群不統一
6)組態檔修改不細心
7)未編譯原始碼
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/05/22 15:38:58 INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
8)不識別主機名稱
java.net.UnknownHostException: hadoop102: hadoop102
at java.net.InetAddress.getLocalHost(InetAddress.java:1475)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:146)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
解決辦法:
(1)在/etc/hosts檔案中添加192.168.1.102 hadoop102
(2)主機名稱不要起hadoop hadoop000等特殊名稱
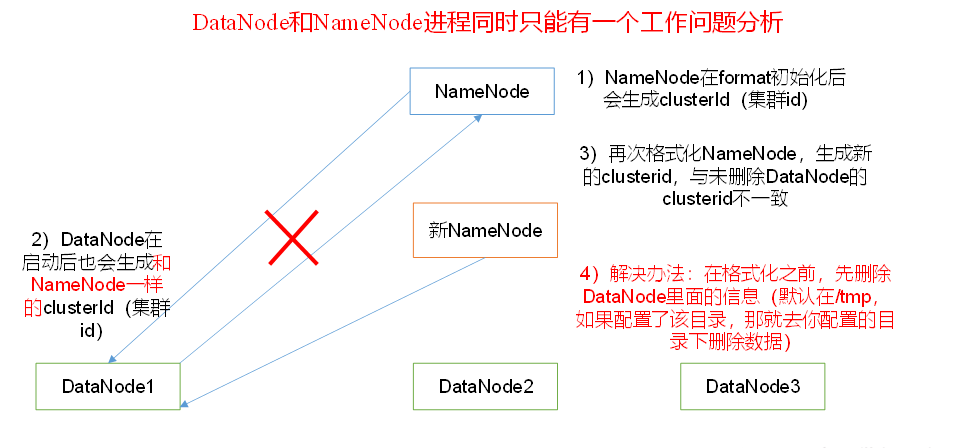
9)DataNode和NameNode行程同時只能作業一個,
10)執行命令不生效,粘貼word中命令時,遇到-和長–沒區分開,導致命令失效
解決辦法:盡量不要粘貼word中代碼,
11)jps發現行程已經沒有,但是重新啟動集群,提示行程已經開啟,原因是在linux的根目錄下/tmp目錄中存在啟動的行程臨時檔案,將集群相關行程洗掉掉,再重新啟動集群,
12)jps不生效,
原因:全域變數hadoop java沒有生效,解決辦法:需要source /etc/profile檔案,
13)8088埠連接不上
[atguigu@hadoop102 桌面]$ cat /etc/hosts
注釋掉如下代碼
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 hadoop102
集群安裝程序錯誤及解決方法:
1)發現有些行程沒有啟動起來:
解決: * 先嘗試單點啟動行程, * 如果單點啟動失敗:先關閉所有行程;洗掉hadoop下得data,logs;再重新格式化namenode;再重啟所有行程, * 如果還是失敗,查看那個行程沒有起來,看對應的組態檔是否配置成功,更改后,記得分發給其他機器,
2)jdk版本問題:
解決:
在安裝時記得查看是否有舊版本,并洗掉,安裝后配置/etc/profile,記得source /etc/profile檔案才能成功,每個機器都要做此操作,
3)格式化HDFS 到達hadoop的bin目錄下 執行
$hadoop namenode -format
報了這個錯(namenode 無法啟動)
ERROR namenode.NameNode: java.io.IOException: Cannot create directory /export/home/dfs/name/current
解決:原因是 沒有設定 /opt/hadoop 的權限沒有設定, 將之改為:
$ chown –R gll:gll /opt/hadoop
$ sudo chmod -R a+w /opt/hadoop
4)啟動Hadoop,執行 start-all.sh 當前用戶對hadoop安裝目錄無足夠權限
hm@hm-ubuntu:/usr/hadoop-1.1.2/bin$ start-all.sh
mkdir: cannot create directory /usr/hadoop-1.1.2/libexec/../logs': Permission denied
chown: cannot access/usr/hadoop-1.1.2/libexec/../logs’: No such file or directory
starting namenode, logging to /usr/hadoop-1.1.2/libexec/../logs/hadoop-hm-namenode-hm-ubuntu.out
/usr/hadoop-1.1.2/bin/hadoop-daemon.sh: line 136: /usr/hadoop-1.1.2/libexec/../logs/hadoop-hm-namenode-hm-ubuntu.out: No such file or directory
head: cannot open `/usr/hadoop-1.1.2/libexec/../logs/hadoop-hm-namenode-hm-ubuntu.out’ for reading: No such file or directory
hm@localhost’s password:
解決:
執行 chown 命令為當前用戶賦予對目錄可寫的權限
sudo chown -hR Eddie(當前用戶名) hadoop-xxx(當前版本)
5)hadoop執行stop-all.sh的時候總是出現 “no namenode to stop”
解決:
這個原因其實是因為在執行stop-all.sh時,找不到pid檔案了,
在 HADOOP_HOME/conf/ hadoop-env.sh 里面,修改配置如下:
export HADOOP_PID_DIR=/home/hadoop/pids
pid檔案默認在/tmp目錄下,而/tmp是會被系統定期清理的,所以Pid檔案被洗掉后就no namenode to stop”
6)當在格式化namenode時出現cannot create directory /usr/local/hadoop/hdfs/name/current的時候
解決:
請將hadoop的目錄權限設為當前用戶可寫sudo chmod -R a+w /usr/local/hadoop,授予hadoop目錄的寫權限
7)當碰到 chown:changing ownership of 'usr/local/hadoop ../logs':operation not permitted時
解決:
可用sudo chown -R gll /usr/local/hadoop來解決,即將hadoop主目錄授權給當前grid用戶
8)如果slaves機上通過jps只有TaskTracker行程,沒有datanode行程
解決:
請查看日志,是不是有“could only be replicated to 0 nodes,instedas of 1”有這樣的提示錯誤,如果有,可能就是沒有關閉防火墻所致,服務器和客戶機都關閉(sudo ufw disable)后,所有行程啟動正常,瀏覽器查看狀態也正常了(ub untu防火墻關閉)
9)要在服務器機上把masters和slavs機的IP地址加到/etc/hosts:當然這個不影響start-all.sh啟動,只是瀏覽器jobtacker上找不到節slaves節點
10).ssh免密碼登陸時,注意檔案authorized_keys和.ssh目錄權限,如果從masters機上scp authorized_keys到slaves機上出現拒絕問題
解決:
那就在salves機上也ssh-keygen,這樣目錄和檔案就不會有權限問題了,就可以實作ssh免密碼登陸了,或直接將.ssh目錄拷過去,在slaves機上新建.ssh目錄權限好像和masters機的目錄權限不一樣
運行正常后,可以用wordcount例子來做一下測驗:
bin/hadoop dfs –put /home/test-in input //將本地檔案系統上的 /home/test-in 目錄拷到 HDFS 的根目錄上,目錄名改為 input
bin/hadoop jar hadoop-examples-0.20.203.0.jar wordcount input output
#查看執行結果:
# 將檔案從 HDFS 拷到本地檔案系統中再查看:
$ bin/hadoop dfs -get output output
$ cat output/*
# 也可以直接查看
$ bin/hadoop dfs -cat output/*
11)如果在reduce程序中出現"Shuffle Error:Exceeded,MAX_FAILED_UNIQUE_FETCHES;bailing-out"錯誤
解決:
原因有可能是/etc/hosts中沒有將IP映射加進去,還有可能是關于打開檔案數限制的問題,需要改vi /etc/security/limits.conf
12)error:call to failed on local exception:java.io.EOFException
解決:
原因如下:eclipse-plugin和Hadoop版本對不上(因為剛開始不想換hadoop版本,就直接把那個插件(hadoop-plugin-0.20.3-snapshot.jar)拷到0.20.203版本里跑了一下,結果報上面的錯,后來將hadoop版本換成hadoop0.20.2就好了)
參考資料:
http://lucene.472066.n3.nabble.com/Call-to-namenode-fails-with-java-io-EOFException-td2933149.html ;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/29364.html
標籤:大數據