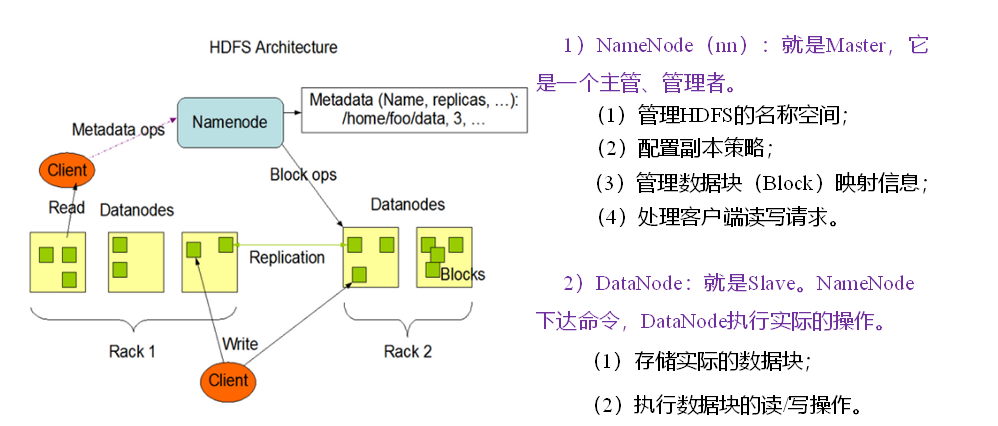
HDFS(Hadoop Distributed File System) 分布式檔案系統,HDFS是一個高度容錯性的系統,適合部署在廉價的機器上,HDFS能提供高吞吐量的資料訪問,非常適合大規模資料集上的應用.由NameNode,若干DataNode,以及Secondary NameNode組成,
HDFS組成架構

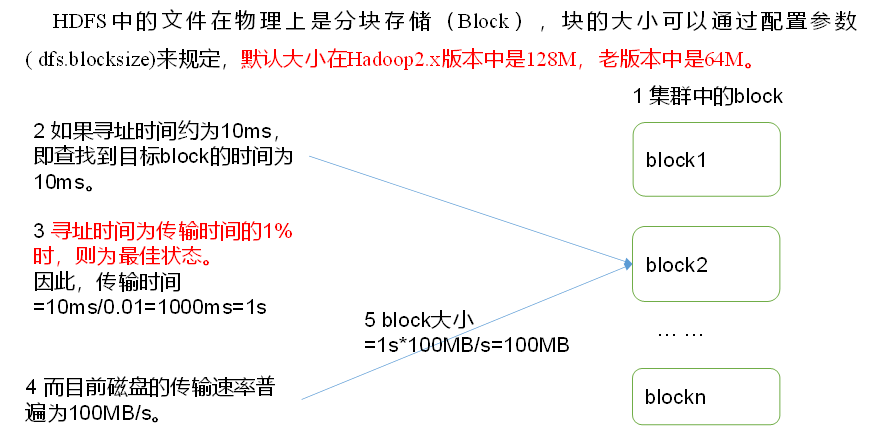
HDFS檔案塊大小:

HDFS客戶端Shell操作
常用命令實操 (0)啟動Hadoop集群(方便后續的測驗) [atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh [atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh (1)-help:輸出這個命令引數 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -help rm (2)-ls: 顯示目錄資訊 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -ls / (3)-mkdir:在HDFS上創建目錄 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -mkdir -p /sanguo/shuguo (4)-moveFromLocal:從本地剪切粘貼到HDFS [atguigu@hadoop102 hadoop-2.7.2]$ touch kongming.txt [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo (5)-appendToFile:追加一個檔案到已經存在的檔案末尾 [atguigu@hadoop102 hadoop-2.7.2]$ touch liubei.txt [atguigu@hadoop102 hadoop-2.7.2]$ vi liubei.txt 輸入 san gu mao lu [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt (6)-cat:顯示檔案內容 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -cat /sanguo/shuguo/kongming.txt (7)-chgrp 、-chmod、-chown:Linux檔案系統中的用法一樣,修改檔案所屬權限 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -chown atguigu:atguigu /sanguo/shuguo/kongming.txt (8)-copyFromLocal:從本地檔案系統中拷貝檔案到HDFS路徑去 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -copyFromLocal README.txt / (9)-copyToLocal:從HDFS拷貝到本地 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./ (10)-cp :從HDFS的一個路徑拷貝到HDFS的另一個路徑 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt (11)-mv:在HDFS目錄中移動檔案 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -mv /zhuge.txt /sanguo/shuguo/ (12)-get:等同于copyToLocal,就是從HDFS下載檔案到本地 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -get /sanguo/shuguo/kongming.txt ./ (13)-getmerge:合并下載多個檔案,比如HDFS的目錄 /user/atguigu/test下有多個檔案:log.1, log.2,log.3,... [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -getmerge /user/atguigu/test/* ./zaiyiqi.txt (14)-put:等同于copyFromLocal [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -put ./zaiyiqi.txt /user/atguigu/test/ (15)-tail:顯示一個檔案的末尾 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -tail /sanguo/shuguo/kongming.txt (16)-rm:洗掉檔案或檔案夾 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -rm /user/atguigu/test/jinlian2.txt (17)-rmdir:洗掉空目錄 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -mkdir /test [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -rmdir /test (18)-du統計檔案夾的大小資訊 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -du -s -h /user/atguigu/test 2.7 K /user/atguigu/test [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -du -h /user/atguigu/test 1.3 K /user/atguigu/test/README.txt 15 /user/atguigu/test/jinlian.txt 1.4 K /user/atguigu/test/zaiyiqi.txt (19)-setrep:設定HDFS中檔案的副本數量 [atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt

圖3-3 HDFS副本數量
這里設定的副本數只是記錄在NameNode的元資料中,是否真的會有這么多副本,還得看DataNode的數量,因為目前只有3臺設備,最多也就3個副本,只有節點數的增加到10臺時,副本數才能達到10,
HDFS讀寫流程
HDFS寫流程(上傳檔案)
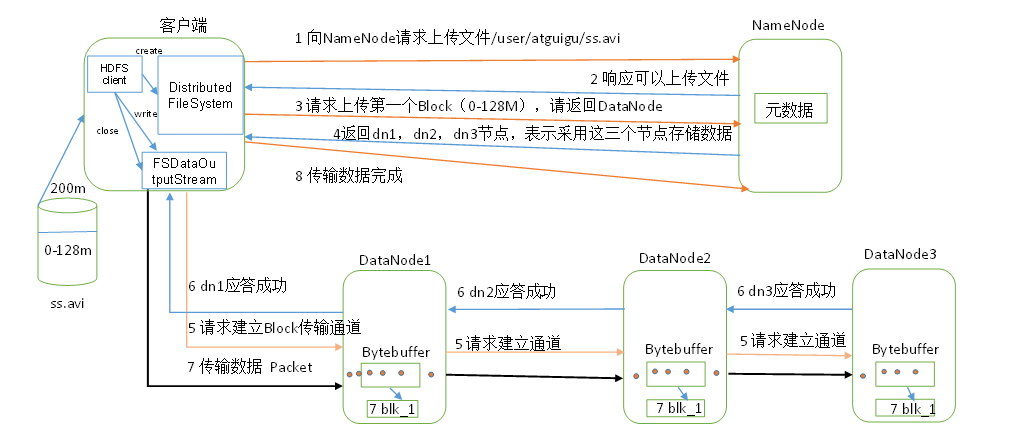
1)客戶端通過Distributed FileSystem模塊向NameNode請求上傳檔案,NameNode檢查目標檔案是否已存在,父目錄是否存在,
2)NameNode回傳是否可以上傳,
3)客戶端請求第一個 Block上傳到哪幾個DataNode服務器上,
4)NameNode回傳3個DataNode節點,分別為dn1、dn2、dn3,
5)客戶端通過FSDataOutputStream模塊請求dn1上傳資料,dn1收到請求會繼續呼叫dn2,然后dn2呼叫dn3,將這個通信管道建立完成,
6)dn1、dn2、dn3逐級應答客戶端,
7)客戶端開始往dn1上傳第一個Block(先從磁盤讀取資料放到一個本地記憶體快取),以Packet為單位,dn1收到一個Packet就會傳給dn2,dn2傳給dn3;dn1每傳一個packet會放入一個應答佇列等待應答,
8)當一個Block傳輸完成之后,客戶端再次請求NameNode上傳第二個Block的服務器,(重復執行3-7步),
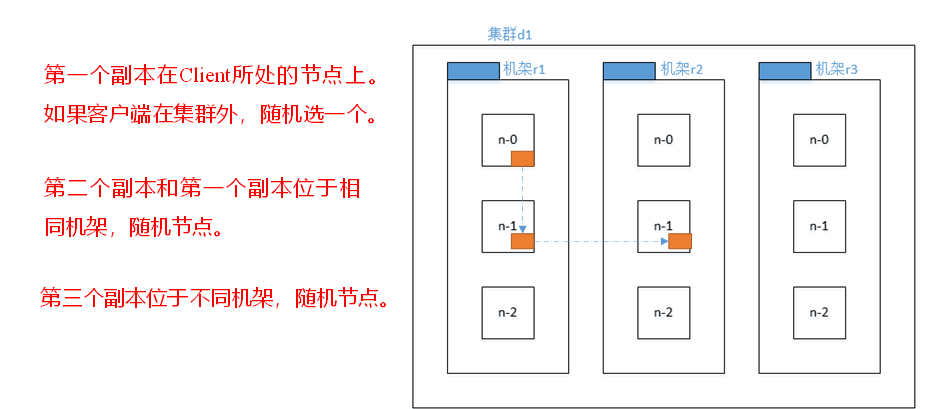
在HDFS寫資料的程序中,NameNode會選擇距離待上傳資料最近距離的DataNode接收資料,那么這個最近距離怎么計算呢?
節點距離:兩個節點到達最近的共同祖先的距離總和,
DN1是最近的,DN2和DN3是根據第一個節點DN1選出來的;
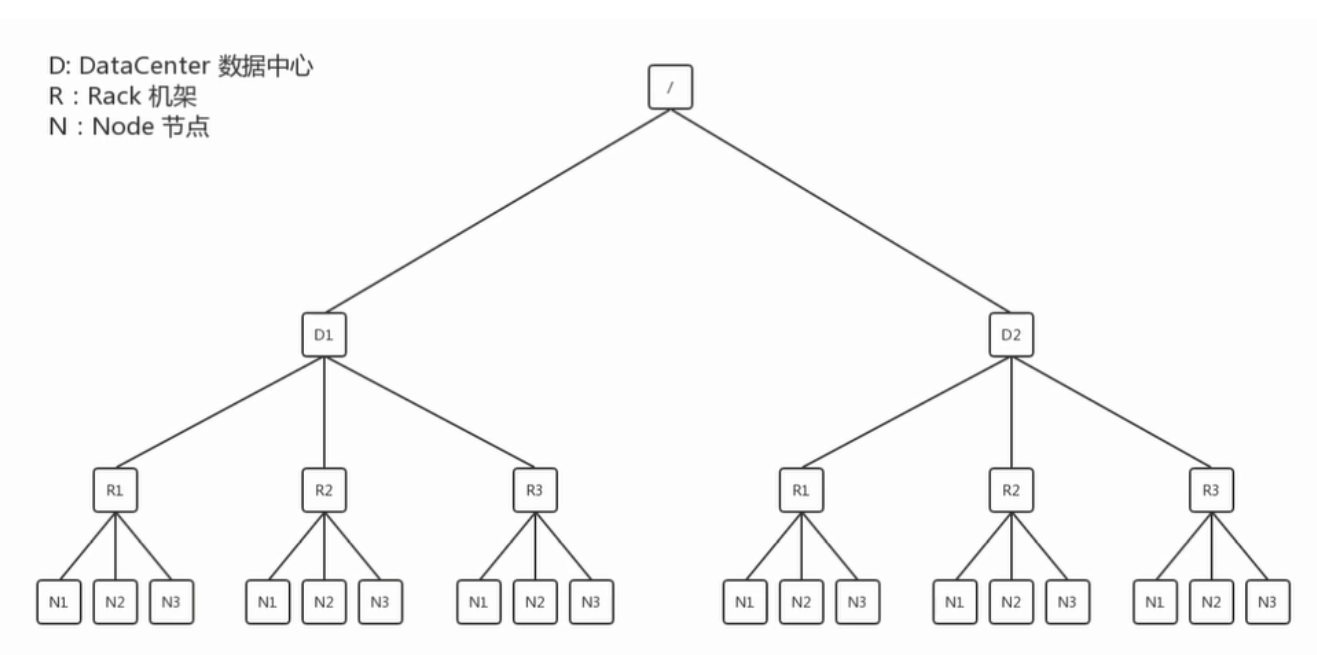
第二次的DN4、DN5、DN6可能跟第一次傳輸的DN一樣,也可能不一樣取決于內部集群的狀況;兩次回傳的DN都是獨立的,
N1與N2之間的距離為2;(找線條數)
假設N1、N2、N3三臺機器,從N1上傳資料,則最短的節點就是它本身0;
后兩個的選擇是根據機架感知來選:
HDFS讀資料流程(下載)
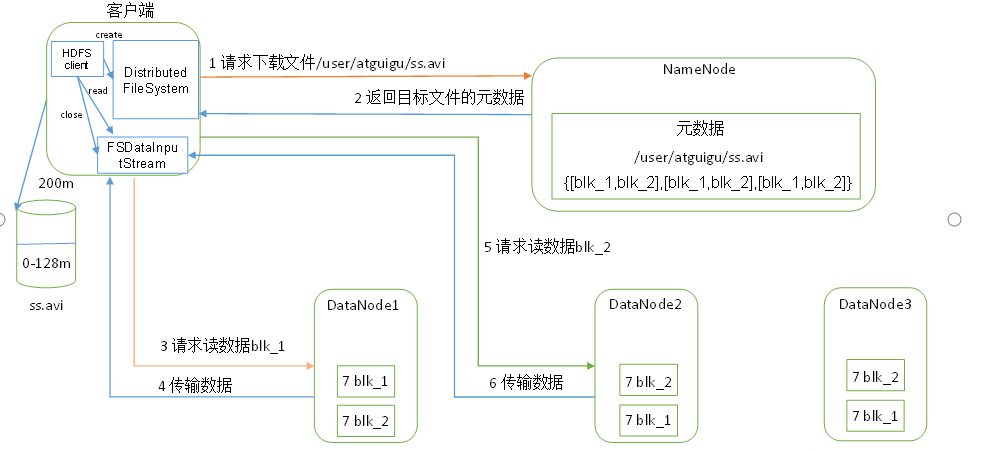
1)客戶端通過Distributed FileSystem向NameNode請求下載檔案,NameNode通過查詢元資料,找到檔案塊所在的DataNode地址,
2)挑選一臺DataNode(就近原則,然后隨機)服務器,請求讀取資料,
3)DataNode開始傳輸資料給客戶端(從磁盤里面讀取資料輸入流,以Packet為單位來做校驗),
4)客戶端以Packet為單位接收,先在本地快取,然后寫入目標檔案,
NameNode和SecondaryNameNode
NN和2NN作業機制
思考NameNode存盤在哪里?
如果將NameNode節點元資料存于磁盤中,因為需要經常進行隨機訪問,且還回應客戶端的請求,效率低下,因此,要將元資料防于記憶體中,但是如果斷電,記憶體中的資料就會丟失,集群無法作業了,因此在磁盤中備份元資料的FsImage,
但是這樣會帶來新的問題就是,在更新記憶體中的資料同時,還要同時更新FsImage,這樣效率低下,因此,引入Edits檔案(只進行追加操作,效率很高),每當元資料有更新或者添加元資料時,修改記憶體中的元資料并追加到Edits中,這樣,一旦NameNode節點斷電,可以通過FsImage和Edits的合并,合成元資料,
但是如果長時間添加資料到Edits中,導致檔案過大,如果某天斷電,那么回復元資料時間很長,因此,需要定期合并FsImage和Edits檔案,但是這個操作由NameNode節點完成,效率低下,因此引入新節點SecondaryNameNode,專門用于FsImage和Rdits定期合并,
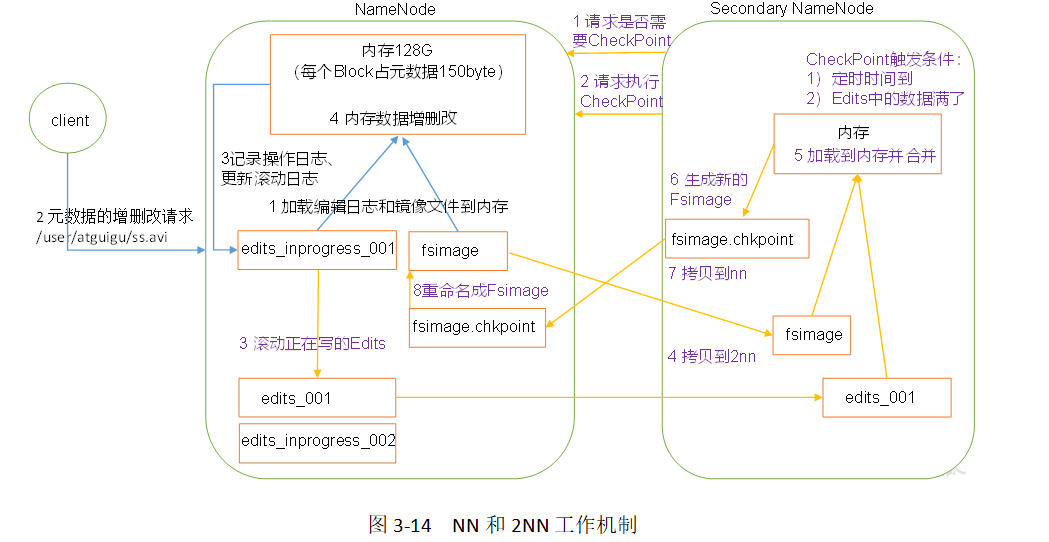
NN和2NN作業機制如圖所示:
Fsimage:NameNode記憶體中元資料序列化后形成的檔案,包含HDFS檔案系統的所有目錄和檔案inode的序列化資訊;是HDFS檔案系統元資料的永久性檢查點;
Edits:記錄客戶端更新--增刪改元資料資訊的每一步操作,
NameNode啟動時,先滾動Edits并生成一個空的edits.inprogress,然后加載Edits和Fsimage到記憶體中,此時NameNode記憶體就持有最新的元資料資訊,
1. 第一階段:NameNode啟動
(1)第一次啟動NameNode格式化后,創建Fsimage和Edits檔案,如果不是第一次啟動,直接加載編輯日志和鏡像檔案到記憶體,
(2)客戶端對元資料進行增刪改的請求,
(3)NameNode記錄操作日志,更新滾動日志,
(4)NameNode在記憶體中對元資料進行增刪改,
2. 第二階段:Secondary NameNode作業
(1)Secondary NameNode詢問NameNode是否需要CheckPoint,直接帶回NameNode是否檢查結果,
(2)Secondary NameNode請求執行CheckPoint,
(3)NameNode滾動正在寫的Edits日志,
(4)將滾動前的編輯日志和鏡像檔案拷貝到Secondary NameNode,
(5)Secondary NameNode加載編輯日志和鏡像檔案到記憶體,并合并,
(6)生成新的鏡像檔案fsimage.chkpoint,
(7)拷貝fsimage.chkpoint到NameNode,
(8)NameNode將fsimage.chkpoint重新命名成fsimage,
NN和2NN作業的詳解:
Fsimage:NameNode記憶體中元資料序列化后形成的檔案,
Edits:記錄客戶端更新元資料資訊的每一步操作(可通過Edits運算出元資料),
NameNode啟動時,先滾動Edits并生成一個空的edits.inprogress,然后加載Edits和Fsimage到記憶體中,此時NameNode記憶體就持有最新的元資料資訊,Client開始對NameNode發送元資料的增刪改的請求,
這些請求的操作首先會被記錄到edits.inprogress中(查詢元資料的操作不會被記錄在Edits中,因為查詢操作不會更改元資料資訊),如果此時NameNode掛掉,重啟后會從Edits中讀取元資料的資訊,
然后,NameNode會在記憶體中執行元資料的增刪改的操作,由于Edits中記錄的操作會越來越多,Edits檔案會越來越大,導致NameNode在啟動加載Edits時會很慢,所以需要對Edits和Fsimage進行合并
(所謂合并,就是將Edits和Fsimage加載到記憶體中,照著Edits中的操作一步步執行,最終形成新的Fsimage),SecondaryNameNode的作用就是幫助NameNode進行Edits和Fsimage的合并作業,
SecondaryNameNode首先會詢問NameNode是否需要CheckPoint(觸發CheckPoint需要滿足兩個條件中的任意一個,定時時間到和Edits中資料寫滿了),直接帶回NameNode是否檢查結果,
SecondaryNameNode執行CheckPoint操作,首先會讓NameNode滾動Edits并生成一個空的edits.inprogress,滾動Edits的目的是給Edits打個標記,以后所有新的操作都寫入edits.inprogress,
其他未合并的Edits和Fsimage會拷貝到SecondaryNameNode的本地,然后將拷貝的Edits和Fsimage加載到記憶體中進行合并,生成fsimage.chkpoint,然后將fsimage.chkpoint拷貝給NameNode,
重命名為Fsimage后替換掉原來的Fsimage,NameNode在啟動時就只需要加載之前未合并的Edits和Fsimage即可,因為合并過的Edits中的元資料資訊已經被記錄在Fsimage中,
Fsimage和Edits決議

查看FsImage檔案
[gll@hadoop101 current]$ ll 總用量 7256 -rw-rw-r--. 1 gll gll 1048576 1月 17 17:10 edits_0000000000000000001-0000000000000000001 -rw-rw-r--. 1 gll gll 42 1月 18 11:08 edits_0000000000000000002-0000000000000000003 -rw-rw-r--. 1 gll gll 1048576 1月 18 17:12 edits_0000000000000000004-0000000000000000020 -rw-rw-r--. 1 gll gll 1048576 1月 18 18:27 edits_0000000000000000021-0000000000000000021 -rw-rw-r--. 1 gll gll 42 1月 18 18:29 edits_0000000000000000022-0000000000000000023 -rw-rw-r--. 1 gll gll 3869 1月 18 19:29 edits_0000000000000000024-0000000000000000074 -rw-rw-r--. 1 gll gll 922 1月 18 20:29 edits_0000000000000000075-0000000000000000090 -rw-rw-r--. 1 gll gll 1048576 1月 18 20:37 edits_0000000000000000091-0000000000000000107 -rw-rw-r--. 1 gll gll 42 1月 19 11:28 edits_0000000000000000108-0000000000000000109 -rw-rw-r--. 1 gll gll 42 1月 19 12:28 edits_0000000000000000110-0000000000000000111 -rw-rw-r--. 1 gll gll 42 1月 19 13:28 edits_0000000000000000112-0000000000000000113 -rw-rw-r--. 1 gll gll 1276 1月 19 14:28 edits_0000000000000000114-0000000000000000127 -rw-rw-r--. 1 gll gll 42 1月 19 15:28 edits_0000000000000000128-0000000000000000129 -rw-rw-r--. 1 gll gll 42 1月 19 16:28 edits_0000000000000000130-0000000000000000131 -rw-rw-r--. 1 gll gll 1048576 1月 19 16:28 edits_0000000000000000132-0000000000000000132 -rw-rw-r--. 1 gll gll 1048576 1月 19 20:45 edits_0000000000000000133-0000000000000000133 -rw-rw-r--. 1 gll gll 14290 1月 20 12:24 edits_0000000000000000134-0000000000000000254 -rw-rw-r--. 1 gll gll 42 1月 20 13:24 edits_0000000000000000255-0000000000000000256 -rw-rw-r--. 1 gll gll 42 1月 20 14:24 edits_0000000000000000257-0000000000000000258 -rw-rw-r--. 1 gll gll 1048576 1月 20 14:24 edits_inprogress_0000000000000000259 -rw-rw-r--. 1 gll gll 2465 1月 20 13:24 fsimage_0000000000000000256 -rw-rw-r--. 1 gll gll 62 1月 20 13:24 fsimage_0000000000000000256.md5 -rw-rw-r--. 1 gll gll 2465 1月 20 14:24 fsimage_0000000000000000258 -rw-rw-r--. 1 gll gll 62 1月 20 14:24 fsimage_0000000000000000258.md5 -rw-rw-r--. 1 gll gll 4 1月 20 14:24 seen_txid -rw-rw-r--. 1 gll gll 206 1月 20 11:36 VERSION [gll@hadoop101 current]$ [gll@hadoop101 current]$ cat seen_txid //檔案保存的是一個數字,就是最后一個edit_數字 [gll@hadoop101 current]$ hdfs oiv -p XML -i fsimage_0000000000000000258 -o /opt/module/hadoop-2.7.2/fsimage.xml [gll@hadoop101 current]$ sz /opt/module/hadoop-2.7.2/fsimage.xml
CheckPoint時間設定
1)通常情況下,SecondaryNameNode每隔一小時執行一次,
2)一分鐘檢查一次操作次數;
3 )當操作次數達到1百萬時,SecondaryNameNode執行一次,
NameNode故障處理
方法一:將SecondaryNameNode中資料拷貝到NameNode存盤資料的目錄:但是這樣處理,2nn的資料有部分沒有合并,會不全,資料丟失,
1. kill -9 NameNode行程 2. 洗掉NameNode存盤的資料(/opt/module/hadoop-2.7.2/data/tmp/dfs/name) [atguigu@hadoop102 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/* 3. 拷貝SecondaryNameNode中資料到原NameNode存盤資料目錄 [atguigu@hadoop102 dfs]$ scp -r atguigu@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/* ./name/ 4. 重新啟動NameNode [atguigu@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
方法二:使用-importCheckpoint選項啟動NameNode守護行程,從而將SecondaryNameNode中資料拷貝到NameNode目錄中,
1.修改hdfs-site.xml中的 <property> <name>dfs.namenode.checkpoint.period</name> <value>120</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp/dfs/name</value> </property> 2. kill -9 NameNode行程 3. 洗掉NameNode存盤的資料(/opt/module/hadoop-2.7.2/data/tmp/dfs/name) [atguigu@hadoop102 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/* 4. 如果SecondaryNameNode不和NameNode在一個主機節點上,需要將SecondaryNameNode存盤資料的目錄拷貝到NameNode存盤資料的平級目錄,并洗掉in_use.lock檔案 [atguigu@hadoop102 dfs]$ scp -r atguigu@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary ./ [atguigu@hadoop102 namesecondary]$ rm -rf in_use.lock [atguigu@hadoop102 dfs]$ pwd /opt/module/hadoop-2.7.2/data/tmp/dfs [atguigu@hadoop102 dfs]$ ls data name namesecondary 5. 匯入檢查點資料(等待一會ctrl+c結束掉) [atguigu@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -importCheckpoint 6. 啟動NameNode [atguigu@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
集群安全模式

集群處于安全模式,不能執行重要操作(寫操作),集群啟動完成后,自動退出安全模式, (1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式狀態) (2)bin/hdfs dfsadmin -safemode enter (功能描述:進入安全模式狀態) (3)bin/hdfs dfsadmin -safemode leave (功能描述:離開安全模式狀態) (4)bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式狀態)
DataNode作業機制
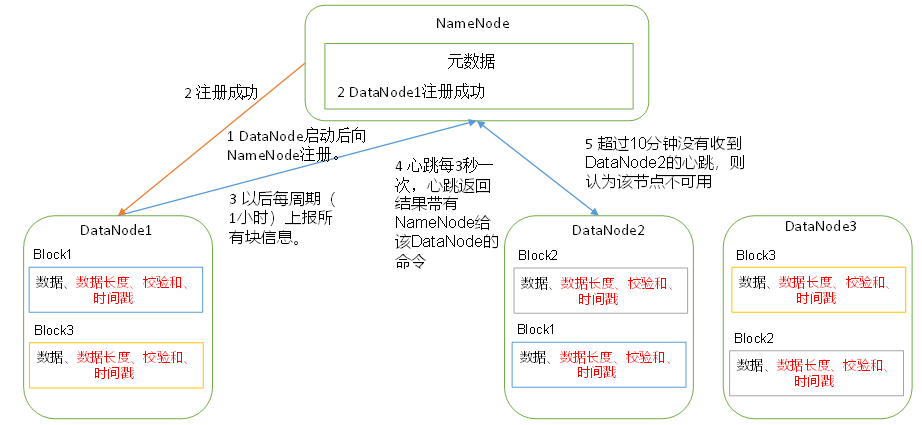
1)一個資料塊在DataNode上以檔案形式存盤在磁盤上,包括兩個檔案,一個是資料本身,一個是元資料包括資料塊的長度,塊資料的校驗和,以及時間戳,
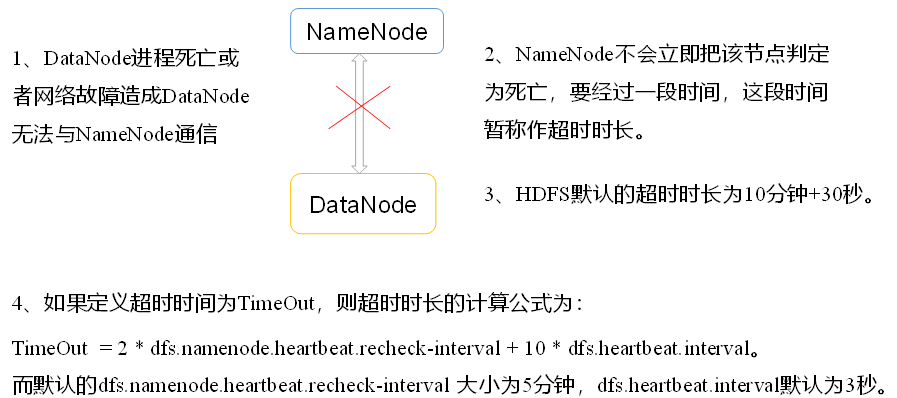
2)DataNode啟動后向NameNode注冊,通過后,周期性(1小時)的向NameNode上報所有的塊資訊,
3)心跳是每3秒一次,心跳回傳結果帶有NameNode給該DataNode的命令如復制塊資料到另一臺機器,或洗掉某個資料塊,如果超過10分鐘沒有收到某個DataNode的心跳,則認為該節點不可用,
4)集群運行中可以安全加入和退出一些機器,
DataNode資料完整性
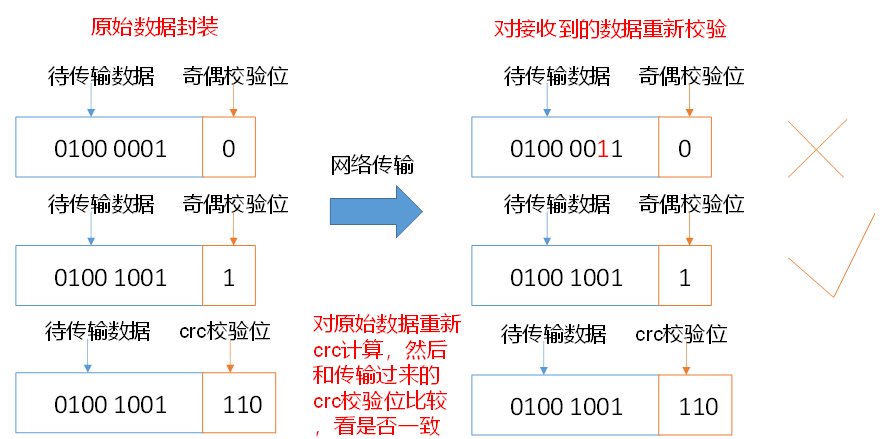
1)當DataNode讀取Block的時候,它會計算CheckSum,
2)如果計算后的CheckSum,與Block創建時值不一樣,說明Block已經損壞,
3)Client讀取其他DataNode上的Block,
4)DataNode在其檔案創建后周期驗證CheckSum,如圖3-16所示,
DataNode掉線時限引數設定
服役新資料節點
隨著公司業務的增長,資料量越來越大,原有的資料節點的容量已經不能滿足存盤資料的需求,需要在原有集群基礎上動態添加新的資料節點
1. 環境準備
(1)在hadoop104主機上再克隆一臺hadoop105主機
(2)修改IP地址和主機名稱
(3)洗掉原來HDFS檔案系統留存的檔案(/opt/module/hadoop-2.7.2/data和log)
(4)source一下組態檔
[atguigu@hadoop105 hadoop-2.7.2]$ source /etc/profile
2. 服役新節點具體步驟
(1)直接啟動DataNode,即可關聯到集群
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
(2)在hadoop105上上傳檔案
[atguigu@hadoop105 hadoop-2.7.2]$ hadoop fs -put /opt/module/hadoop-2.7.2/LICENSE.txt /
(3)如果資料不均衡,可以用命令實作集群的再平衡
[atguigu@hadoop102 sbin]$ ./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-atguigu-balancer-hadoop102.out
退役舊資料節點
添加白名單
添加到白名單的主機節點,都允許訪問NameNode,不在白名單的主機節點,都會被退出,
配置白名單的具體步驟如下:
(1)在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目錄下創建dfs.hosts檔案 [atguigu@hadoop102 hadoop]$ pwd /opt/module/hadoop-2.7.2/etc/hadoop [atguigu@hadoop102 hadoop]$ touch dfs.hosts [atguigu@hadoop102 hadoop]$ vi dfs.hosts 添加如下主機名稱(不添加hadoop105) hadoop102 hadoop103 hadoop104 (2)在NameNode的hdfs-site.xml組態檔中增加dfs.hosts屬性 <property> <name>dfs.hosts</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value> </property> (3)組態檔分發 [atguigu@hadoop102 hadoop]$ xsync hdfs-site.xml (4)重繪NameNode [atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes Refresh nodes successful (5)更新ResourceManager節點 [atguigu@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes 17/06/24 14:17:11 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033
黑名單退役
在黑名單上面的主機都會被強制退出
1.在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目錄下創建dfs.hosts.exclude檔案
[atguigu@hadoop102 hadoop]$ pwd /opt/module/hadoop-2.7.2/etc/hadoop [atguigu@hadoop102 hadoop]$ touch dfs.hosts.exclude [atguigu@hadoop102 hadoop]$ vi dfs.hosts.exclude 添加如下主機名稱(要退役的節點) hadoop105
2.在NameNode的hdfs-site.xml組態檔中增加dfs.hosts.exclude屬性
<property> <name>dfs.hosts.exclude</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value> </property>
3.重繪NameNode、重繪ResourceManager
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[atguigu@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033
4. 檢查Web瀏覽器,退役節點的狀態為decommission in progress(退役中),說明資料節點正在復制塊到其他節點,如圖3-17所示

5.等待退役節點狀態為decommissioned(所有塊已經復制完成),停止該節點及節點資源管理器,注意:如果副本數是3,服役的節點小于等于3,是不能退役成功的,需要修改副本數后才能退役,如圖3-18所示

[atguigu@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh stop datanode stopping datanode [atguigu@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager stopping nodemanager
6. 如果資料不均衡,可以用命令實作集群的再平衡
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-balancer.sh starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-atguigu-balancer-hadoop102.out Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
注意:不允許白名單和黑名單中同時出現同一個主機名稱,
DataNode多級目錄配置
1. DataNode也可以配置成多個目錄,每個目錄存盤的資料不一樣,即:資料不是副本
2.具體配置如下
hdfs-site.xml <property> <name>dfs.datanode.data.dir</name> <value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value> </property>
HDFS2.x新特性
集群間資料拷貝
1.scp實作兩個遠程主機之間的檔案復制
scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt // 推 push
scp -r root@hadoop103:/user/atguigu/hello.txt hello.txt // 拉 pull
scp -r root@hadoop103:/user/atguigu/hello.txt root@hadoop104:/user/atguigu //是通過本地主機中轉實作兩個遠程主機的檔案復制;如果在兩個遠程主機之間ssh沒有配置的情況下可以使用該方式,
2.采用distcp命令實作兩個Hadoop集群之間的遞回資料復制
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop distcp
hdfs://haoop102:9000/user/atguigu/hello.txt hdfs://hadoop103:9000/user/atguigu/hello.txt
小檔案存檔

案例實操
(1)需要啟動YARN行程
[atguigu@hadoop102 hadoop-2.7.2]$ start-yarn.sh
(2)歸檔檔案
把/user/atguigu/input目錄里面的所有檔案歸檔成一個叫input.har的歸檔檔案,并把歸檔后檔案存盤到/user/atguigu/output路徑下,
[atguigu@hadoop102 hadoop-2.7.2]$ bin/hadoop archive -archiveName input.har –p /user/atguigu/input /user/atguigu/output
(3)查看歸檔
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -lsr /user/atguigu/output/input.har
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -lsr har:///user/atguigu/output/input.har
(4)解歸檔檔案
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -cp har:/// user/atguigu/output/input.har/* /user/atguigu
HDFS HA高可用
HA概述
1)所謂HA(High Available),即高可用(7*24小時中段服務)
2)實作高可用最關鍵的策略是消除單點故障,HA嚴格來說應該分成各個組件的HA機制:HDFS的HA和YARN的HA,
3)Hadoop2.0之前,在HDFS集群中NameNode存在單點故障(SPOF),
4) NameNode主要在以下兩個方面影響HDFS集群
- NameNode機器發生意外,如宕機,集群將無法使用,直到管理員重啟
- NameNode機器需要升級,包括軟體、硬體升級,此時集群也將無法使用
HDFS HA功能通過配置Active/Standby兩個NameNodes實作在集群中對NameNode的熱備來解決上述問題,如果出現故障,如機器崩潰或機器需要升級維護,這時可通過此種方式將NameNode很快的切換到另外一臺機器,
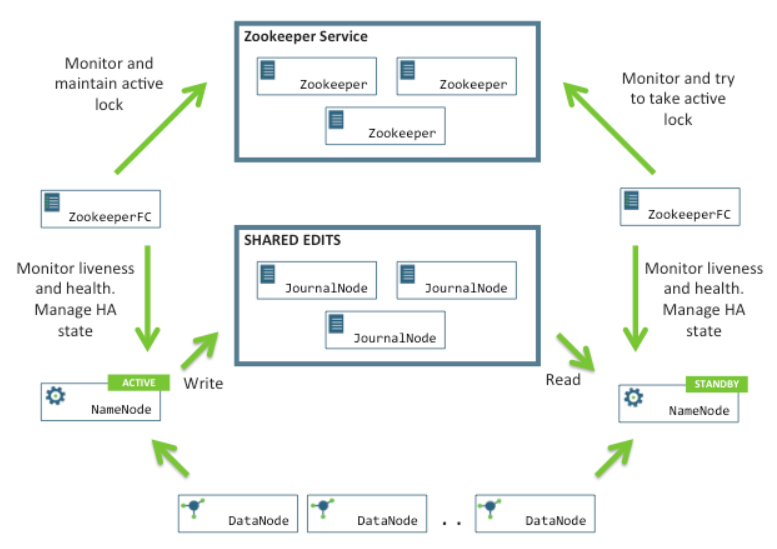
HDFS-HA作業機制
通過雙NameNode消除單點故障
HDFS-HA作業要點
1. 元資料管理方式需要改變
記憶體中各自保存一份元資料;
Edits日志只有Active狀態的NameNode節點可以做寫操作;
兩個NameNode都可以讀取Edits;
共享的Edits放在一個共享存盤中管理(qjournal和NFS兩個主流實作);
2. 需要一個狀態管理功能模塊
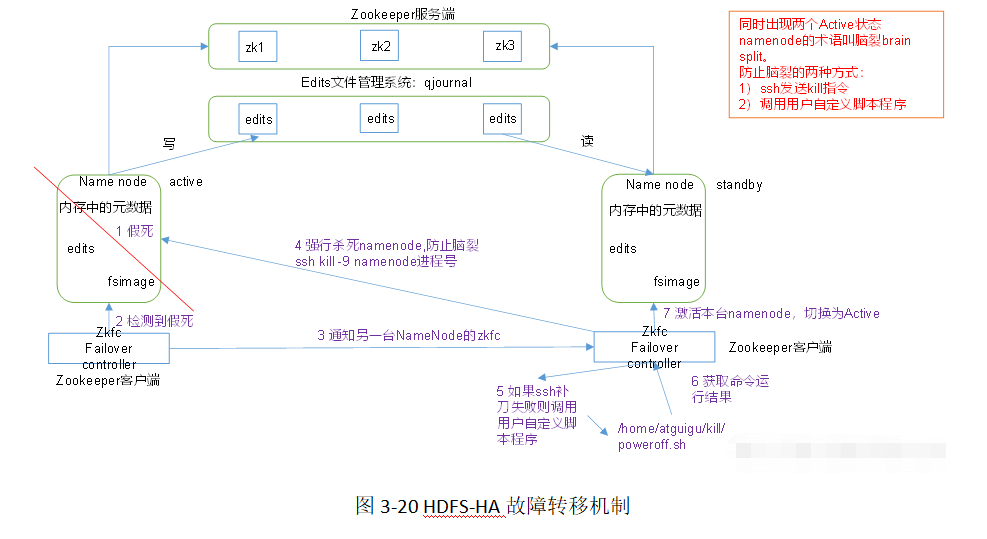
實作了一個zkfailover,常駐在每一個namenode所在的節點,每一個zkfailover負責監控自己所在NameNode節點,利用zk進行狀態標識,當需要進行狀態切換時,由zkfailover來負責切換,切換時需要防止brain split現象的發生,
3. 必須保證兩個NameNode之間能夠ssh無密碼登錄
4. 隔離(Fence),即同一時刻僅僅有一個NameNode對外提供服務
HDFS-HA自動故障轉移機制
故障轉移增加了zookeeper和ZKFS行程
Zookeeper:維護少量協調資料,通知客戶端這些資料的改變和監視客戶端故障的高可用服務
HA依賴zookeeper的一下功能:
1)故障檢測:集群中的每個NameNode在ZooKeeper中維護了一個持久會話,如果機器崩潰,ZooKeeper中的會話將終止,ZooKeeper通知另一個NameNode需要觸發故障轉移,
2)現役NameNode選擇:ZooKeeper提供了一個簡單的機制用于唯一的選擇一個節點為active狀態,如果目前現役NameNode崩潰,另一個節點可能從ZooKeeper獲得特殊的排外鎖以表明它應該成為現役NameNode,
ZKFC是自動故障轉移中的另一個新組件,是ZooKeeper的客戶端,也監視和管理NameNode的狀態,每個運行NameNode的主機也運行了一個ZKFC行程,ZKFC負責:
1)健康監測:ZKFC使用一個健康檢查命令定期地ping與之在相同主機的NameNode,只要該NameNode及時地回復健康狀態,ZKFC認為該節點是健康的,如果該節點崩潰,凍結或進入不健康狀態,健康監測器標識該節點為非健康的,
2)ZooKeeper會話管理:當本地NameNode是健康的,ZKFC保持一個在ZooKeeper中打開的會話,如果本地NameNode處于active狀態,ZKFC也保持一個特殊的znode鎖,該鎖使用了ZooKeeper對短暫節點的支持,如果會話終止,鎖節點將自動洗掉,
3)基于ZooKeeper的選擇:如果本地NameNode是健康的,且ZKFC發現沒有其它的節點當前持有znode鎖,它將為自己獲取該鎖,如果成功,則它已經贏得了選擇,并負責運行故障轉移行程以使它的本地NameNode為Active,故障轉移行程與前面描述的手動故障轉移相似,首先如果必要保護之前的現役NameNode,然后本地NameNode轉換為Active狀態,
ZKFC:是zookeeper的客戶端,讓它聯系zookeeper,HA是hadoop2.0才有的,namenode在1.0時就有了,但是為了保持NameNode的健壯性,未把ZKFC加入NameNode中,但是兩個行程是相互系結的,有ZKFC監視NameNode,
將狀態匯報給zookeeper,
主Namenode處理所有的操作請求(讀寫),而Standby只是作為slave,維護盡可能同步的狀態,使得故障時能夠快速切換到Standby,為了使Standby Namenode與Active Namenode資料保持同步,兩個Namenode都與一組Journal Node進行通信,當主Namenode進行任務的namespace操作時,都會確保持久會修改日志到Journal Node節點中的大部分,Standby Namenode持續監控這些edit,當監測到變化時,將這些修改應用到自己的namespace
當進行故障轉移時,Standby在成為Active Namenode之前,會確保自己已經讀取了Journal Node中的所有edit日志,從而保持資料狀態與故障發生前一致,
腦裂現象(split brain): 當兩臺Namenode都認為自己的Active Namenode時,會同時嘗試寫入資料(不會再去檢測和同步資料):zookeeper會根據自身通知機制,確認主機,防止腦裂,
如果一臺出現了假死,當前NameNode監控的ZKFX檢測到假死,會通知從機的ZKFC,從而殺死假死的NameNode的行程,激活從機為Active,同時通知zookeeper服務端將從機注冊為Active,
現在合并fsimage是由standby來完成的,沒有secondaryNameNode;
Journal Nodes為了防止腦裂,只讓一個Namenode寫入資料,內部通過維護epoch數來控制,從而安全地進行故障轉移,有兩種方式共享edits log:
- 使用NFS共享edit log(存盤在NAS/SAN)
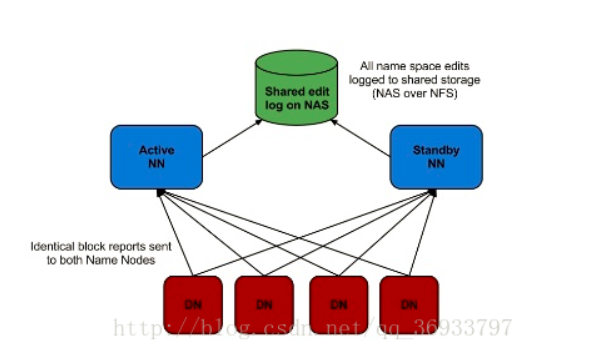
如圖所示,NFS作為主備Namenode的共享存盤,這種方案可能會出現腦裂(split-brain),即兩個節點都認為自己是主Namenode并嘗試向edit log寫入資料,這可能會導致資料損壞,通過配置fencin腳本來解決這個問題,fencing腳本用于:
將之前的Namenode關機
禁止之前的Namenode繼續訪問共享的edit log檔案
使用這種方案,管理員就可以手工觸發Namenode切換,然后進行升級維護,但這種方式存在以下問題:
- 只能手動進行故障轉移,每次故障都要求管理員采取措施切換,
- NAS/SAN設定部署復雜,容易出錯,且NAS本身是單點故障,
- Fencing 很復雜,經常會配置錯誤,
- 無法解決意外(unplanned)事故,如硬體或者軟體故障,
因此需要另一種方式來處理這些問題:
- 自動故障轉移(引入ZooKeeper達到自動化)
- 移除對外界軟體硬體的依賴(NAS/SAN)
- 同時解決意外事故及日常維護導致的不可用
- 使用QJM共享edit log:Quorum-based 存盤 + ZooKeeper
QJM(Quorum Journal Manager)是Hadoop專門為Namenode共享存盤開發的組件,其集群運行一組Journal Node,每個Journal 節點暴露一個簡單的RPC介面,允許Namenode讀取和寫入資料,資料存放在Journal節點的本地磁盤,當Namenode寫入edit log時,它向集群的所有Journal Node發送寫入請求,當多數節點回復確認成功寫入之后,edit log就認為是成功寫入,例如有3個Journal Node,Namenode如果收到來自2個節點的確認訊息,則認為寫入成功,
而在故障自動轉移的處理上,引入了監控Namenode狀態的ZookeeperFailController(ZKFC),ZKFC一般運行在Namenode的宿主機器上,與Zookeeper集群協作完成故障的自動轉移,整個集群架構圖如下:
Namenode使用QJM 客戶端提供的RPC介面與Namenode進行互動,寫入edit log時采用基于仲裁的方式,即資料必須寫入JournalNode集群的大部分節點,
在Journal Node節點上(服務端)
服務端Journal運行輕量級的守護行程,暴露RPC介面供客戶端呼叫,實際的edit log資料保存在Journal Node本地磁盤,該路徑在配置中使用dfs.journalnode.edits.dir屬性指定,
Journal Node通過epoch數來解決腦裂的問題,稱為JournalNode fencing,具體作業原理如下:
1)當Namenode變成Active狀態時,被分配一個整型的epoch數,這個epoch數是獨一無二的,并且比之前所有Namenode持有的epoch number都高,
2)當Namenode向Journal Node發送訊息的時候,同時也帶上了epoch,當Journal Node收到訊息時,將收到的epoch數與存盤在本地的promised epoch比較,如果收到的epoch比自己的大,則使用收到的epoch更新自己本地的epoch數,如果收到的比本地的epoch小,則拒絕請求,
3)edit log必須寫入大部分節點才算成功,也就是其epoch要比大多數節點的epoch高,
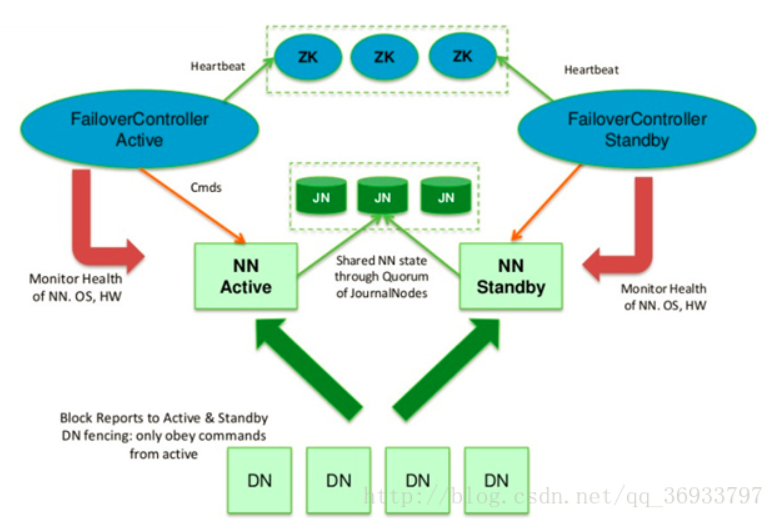
這種方式解決了NFS方式的3個問題:
不需要額外的硬體,使用原有的物理機
Fencing通過epoch數來控制,避免出錯,
自動故障轉移:Zookeeper處理該問題,
HDFS-HA故障轉移參考:https://blog.csdn.net/qq_36933797/article/details/78826713
HDFS-HA集群配置
環境準備
1. 修改IP
2. 修改主機名及主機名和IP地址的映射
3. 關閉防火墻
4. ssh免密登錄
5. 安裝JDK,配置環境變數等
規劃集群
|
hadoop102 |
hadoop103 |
hadoop104 |
|
NameNode |
NameNode |
|
|
JournalNode |
JournalNode |
JournalNode |
|
DataNode |
DataNode |
DataNode |
|
ZK |
ZK |
ZK |
|
|
ResourceManager |
|
|
NodeManager |
NodeManager |
NodeManager |
配置HDFS-HA集群
在opt目錄下創建一個ha檔案夾 mkdir ha
將/opt/app/下的 hadoop-2.7.2拷貝到/opt/ha目錄下 cp -r hadoop-2.7.2/ /opt/ha/
配置hadoop-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_144
配置core-site.xml
<configuration> <!-- 把兩個NameNode)的地址組裝成一個集群mycluster --> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!-- 指定hadoop運行時產生檔案的存盤目錄 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/ha/hadoop-2.7.2/data/tmp</value> </property> </configuration>
配置hdfs-site.xml
<configuration> <!-- 完全分布式集群名稱 --> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!-- 集群中NameNode節點都有哪些 --> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>hadoop102:9000</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>hadoop103:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>hadoop102:50070</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>hadoop103:50070</value> </property> <!-- 指定NameNode元資料在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/mycluster</value> </property> <!-- 配置隔離機制,即同一時刻只能有一臺服務器對外回應 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔離機制時需要ssh無秘鑰登錄--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/atguigu/.ssh/id_rsa</value> </property> <!-- 宣告journalnode服務器存盤目錄--> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/ha/hadoop-2.7.2/data/jn</value> </property> <!-- 關閉權限檢查--> <property> <name>dfs.permissions.enable</name> <value>false</value> </property> <!-- 訪問代理類:client,mycluster,active配置失敗自動切換實作方式--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> </configuration>
拷貝配置好的hadoop環境到其他節點
啟動HDFS-HA集群
1. 在各個JournalNode節點上,輸入以下命令啟動journalnode服務 sbin/hadoop-daemon.sh start journalnode 2. 在[nn1]上,對其進行格式化,并啟動 bin/hdfs namenode -format sbin/hadoop-daemon.sh start namenode 3. 在[nn2]上,同步nn1的元資料資訊 bin/hdfs namenode -bootstrapStandby 4. 啟動[nn2] sbin/hadoop-daemon.sh start namenode 5. 在[nn1]上,啟動所有datanode sbin/hadoop-daemons.sh start datanode 6. 將[nn1]切換為Active bin/hdfs haadmin -transitionToActive nn1 7. 查看是否Active bin/hdfs haadmin -getServiceState nn1
配置HDFS-HA自動故障轉移
1. 具體配置
(1)在hdfs-site.xml中增加
<property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
(2)在core-site.xml檔案中增加
<property> <name>ha.zookeeper.quorum</name> <value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value> </property>
2. 啟動
(1)關閉所有HDFS服務:
sbin/stop-dfs.sh
(2)啟動Zookeeper集群:
bin/zkServer.sh start
(3)初始化HA在Zookeeper中狀態:
bin/hdfs zkfc -formatZK
(4)啟動HDFS服務:
sbin/start-dfs.sh
3.驗證
(1)將Active NameNode行程kill kill -9 namenode的行程id
(2)將Active NameNode機器斷開網路 service network stop
YARN-HA配置
YARN-HA作業機制,如圖3-23所示:
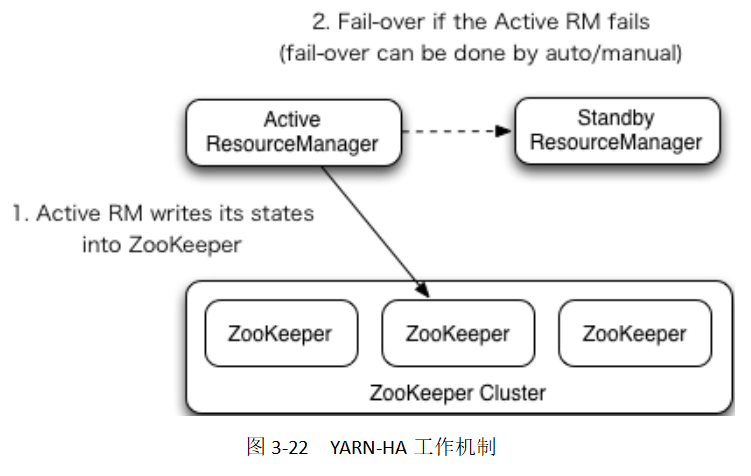
具體配置
(1)yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--啟用resourcemanager ha--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--宣告兩臺resourcemanager的地址--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop102</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop103</value> </property> <!--指定zookeeper集群的地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value> </property> <!--啟用自動恢復--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--指定resourcemanager的狀態資訊存盤在zookeeper集群--> <property> <name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> </configuration>
啟動hdfs
(1)在各個JournalNode節點上,輸入以下命令啟動journalnode服務: sbin/hadoop-daemon.sh start journalnode (2)在[nn1]上,對其進行格式化,并啟動: bin/hdfs namenode -format sbin/hadoop-daemon.sh start namenode (3)在[nn2]上,同步nn1的元資料資訊: bin/hdfs namenode -bootstrapStandby (4)啟動[nn2]: sbin/hadoop-daemon.sh start namenode (5)啟動所有DataNode sbin/hadoop-daemons.sh start datanode (6)將[nn1]切換為Active bin/hdfs haadmin -transitionToActive nn1
啟動YARN
(1)在hadoop102中執行: sbin/start-yarn.sh (2)在hadoop103中執行: sbin/yarn-daemon.sh start resourcemanager (3)查看服務狀態,如圖3-24所示 bin/yarn rmadmin -getServiceState rm1
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/29373.html
標籤:大數據
上一篇:Hadoop架構及集群