1、使用JDBC連接Hive
1 import java.sql.Connection;
2 import java.sql.DriverManager;
3 import java.sql.PreparedStatement;
4 import java.sql.ResultSet;
5
6 public class HiveDemo {
7 public static void main(String[] args) throws Exception {
8 Class.forName("org.apache.hive.jdbc.HiveDriver");
9 //"jdbc:hive2://master:10000/test3"
10 Connection connection = DriverManager.getConnection("jdbc:hive2://master:10000/myhive");
11 String sql="select * from students";
12 PreparedStatement ps = connection.prepareStatement(sql);
13 ResultSet rs = ps.executeQuery();
14 while (rs.next()){
15 int id = rs.getInt(1);
16 String name = rs.getString(2);
17 int age = rs.getInt(3);
18 String gender = rs.getString(4);
19 String clazz = rs.getString(5);
20 System.out.println(id + "," + name + "," + age + "," + gender + "," + clazz);
21 }
22 rs.close();
23 ps.close();
24 connection.close();
25 }
26 }
2、Hive常用函式
1.關系運算
// 等值比較 = == <=>
// 不等值比較 != <>
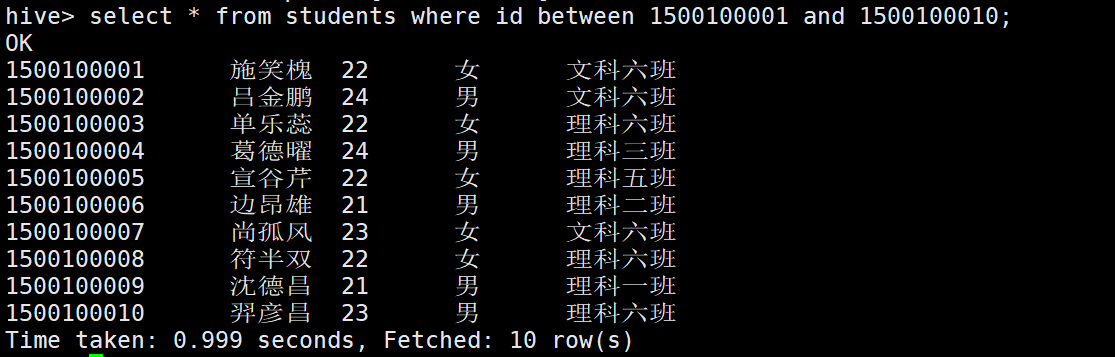
// 區間比較: select * from default.students where id between 1500100001 and 1500100010;
// 空值/非空值判斷:is null、is not null、nvl()、isnull()
|
運算子 |
支持的資料型別 |
描述 |
|
A=B |
基本資料型別 |
如果A等于B則回傳TRUE,反之回傳FALSE |
|
A<=>B |
基本資料型別 |
如果A和B都為NULL,則回傳TRUE,如果一邊為NULL,回傳False |
|
A<>B, A!=B |
基本資料型別 |
A或者B為NULL則回傳NULL;如果A不等于B,則回傳TRUE,反之回傳FALSE |
|
A<B |
基本資料型別 |
A或者B為NULL,則回傳NULL;如果A小于B,則回傳TRUE,反之回傳FALSE |
|
A<=B |
基本資料型別 |
A或者B為NULL,則回傳NULL;如果A小于等于B,則回傳TRUE,反之回傳FALSE |
|
A>B |
基本資料型別 |
A或者B為NULL,則回傳NULL;如果A大于B,則回傳TRUE,反之回傳FALSE |
|
A>=B |
基本資料型別 |
A或者B為NULL,則回傳NULL;如果A大于等于B,則回傳TRUE,反之回傳FALSE |
|
A [NOT] BETWEEN B AND C |
基本資料型別 |
如果A,B或者C任一為NULL,則結果為NULL,如果A的值大于等于B而且小于或等于C,則結果為TRUE,反之為FALSE,如果使用NOT關鍵字則可達到相反的效果, |
|
A IS NULL |
所有資料型別 |
如果A等于NULL,則回傳TRUE,反之回傳FALSE |
|
A IS NOT NULL |
所有資料型別 |
如果A不等于NULL,則回傳TRUE,反之回傳FALSE |
|
IN(數值1, 數值2) |
所有資料型別 |
使用 IN運算顯示串列中的值 |
|
A [NOT] LIKE B |
STRING 型別 |
B是一個SQL下的簡單正則運算式,也叫通配符模式,如果A與其匹配的話,則回傳TRUE;反之回傳FALSE,B的運算式說明如下:‘x%’表示A必須以字母‘x’開頭,‘%x’表示A必須以字母’x’結尾,而‘%x%’表示A包含有字母’x’,可以位于開頭,結尾或者字串中間,如果使用NOT關鍵字則可達到相反的效果, |
|
A RLIKE B, A REGEXP B |
STRING 型別 |
B是基于java的正則運算式,如果A與其匹配,則回傳TRUE;反之回傳FALSE,匹配使用的是JDK中的正則運算式介面實作的,因為正則也依據其中的規則,例如,正則運算式必須和整個字串A相匹配,而不是只需與其字串匹配, |
2 .數值計算
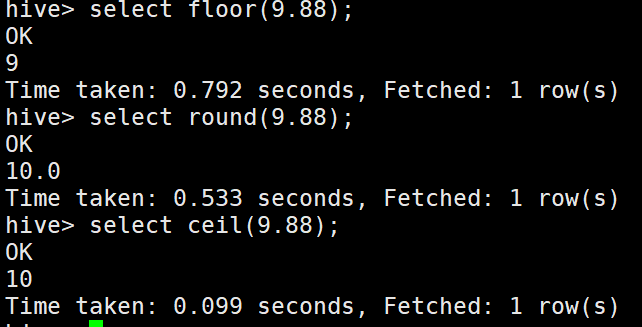
取整函式(四舍五入):round
向上取整:ceil
向下取整:floor
like、rlike、
(1)查找名字以A開頭的員工資訊
hive (default)> select * from emp where ename LIKE 'A%';
(2)查找名字中第二個字母為A的員工資訊
hive (default)> select * from emp where ename LIKE '_A%';
(3)查找名字中帶有A的員工資訊
hive (default)> select * from emp where ename RLIKE '[A]';
.
3.日期函式
1 select from_unixtime(1610611142,'YYYY/MM/dd HH:mm:ss'); 2unix_timestamp(),獲取當前時間的時間戳
3 select from_unixtime(unix_timestamp(),'YYYY/MM/dd HH:mm:ss');
4 // '2021年01月14日' -> '2021-01-14'
6 select from_unixtime(unix_timestamp('2021年01月14日','yyyy年MM月dd日'),'yyyy-MM-dd');
8 select from_unixtime(unix_timestamp("04-2021-16","MM-yyyy-dd"),"yyyy/MM/dd");
4.字串函式
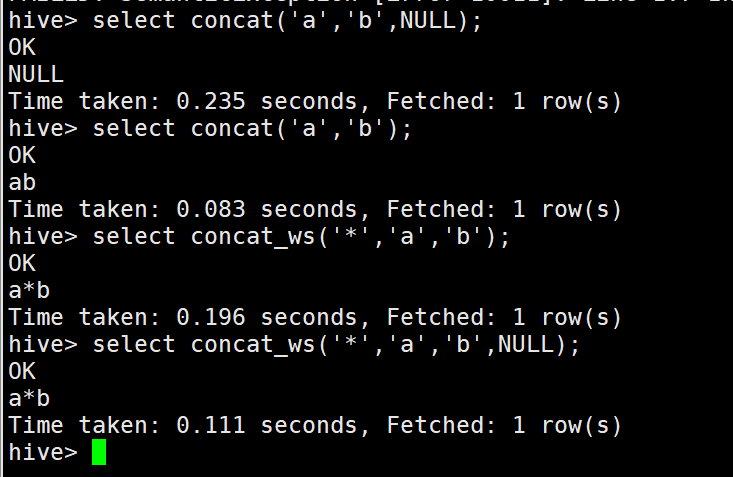
1)cancat()字串拼接 當有空值則為NULL
2)cancat_ws()指定可以指定分隔符,并且會自動忽略NULL
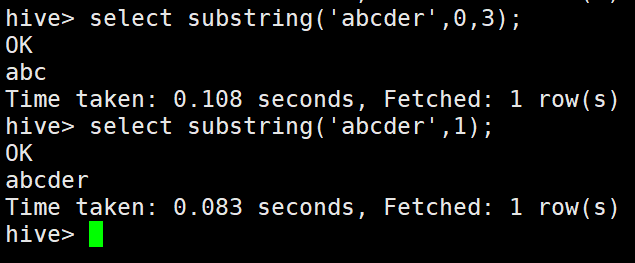
 3)substring字串的截取
3)substring字串的截取
4)split字串的切分
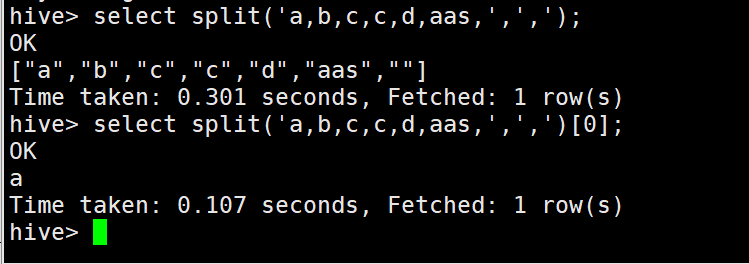
5)explode列轉行
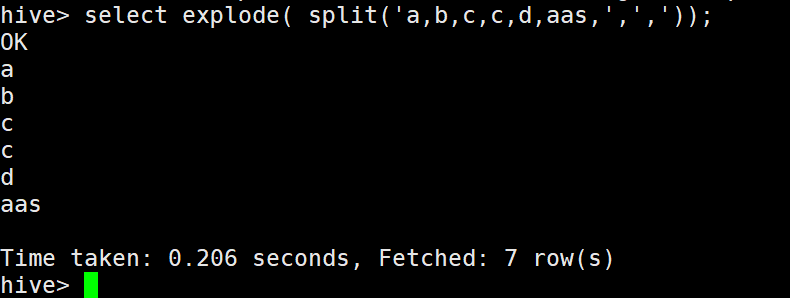
決議json格式的資料
select get_json_object
('{"name":"zhangsan",
"age":18,
"score":[{"course_name":"math","score":100},{"course_name":"english","score":60}]}',
"$.score[0].score");
6) Hive中的wordcount
create table words( words string )row format delimited fields terminated by '|'; // 資料 hello,java,hello,java,scala,python hbase,hadoop,hadoop,hdfs,hive,hive hbase,hadoop,hadoop,hdfs,hive,hive select word,count(*) from (select explode(split(words,',')) word from words) a group by a.word;
4.開窗函式
##### row_number:無并列排名
分組求TOPN
select * from (select *, row_number() over(partition by clazz order by score desc)as s from new_score)tt where tt.s<=3;
用法: select xxxx, row_number() over(partition by 分組欄位 order by 排序欄位 desc) as rn from tb group by xxxx
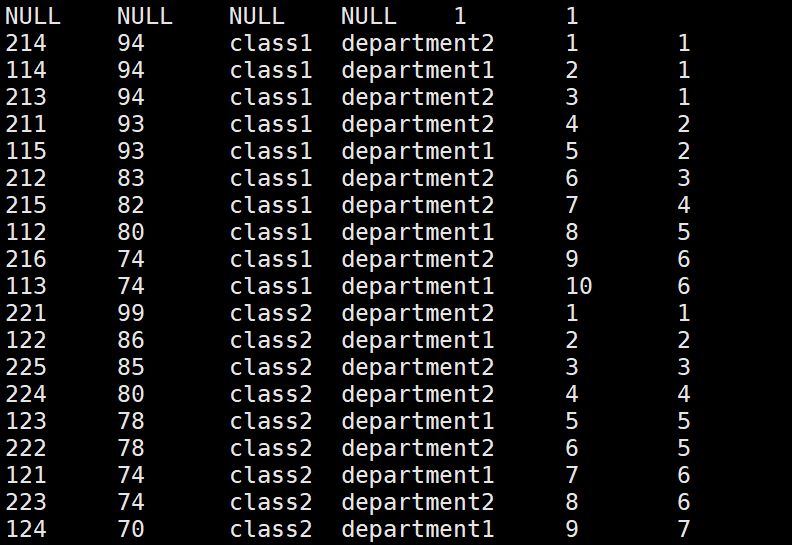
##### dense_rank:有并列排名,并且依次遞增
hive> select *, row_number() over(partition by clazz order by score desc)as s,
> dense_rank() over(partition by clazz order by score desc)as s from new_score;
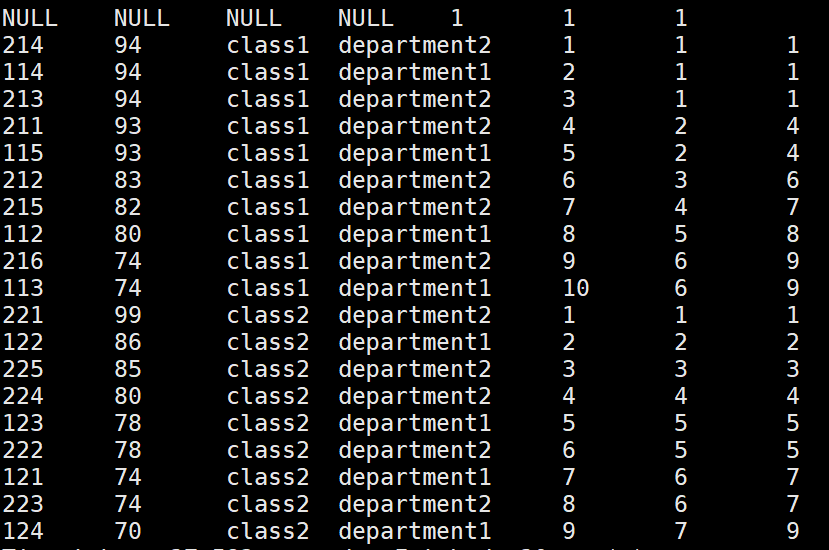
##### rank:有并列排名,不依次遞增
hive> select *, row_number() over(partition by clazz order by score desc)as s,
> dense_rank() over(partition by clazz order by score desc),
> rank() over(partition by clazz order by score desc)from new_score;
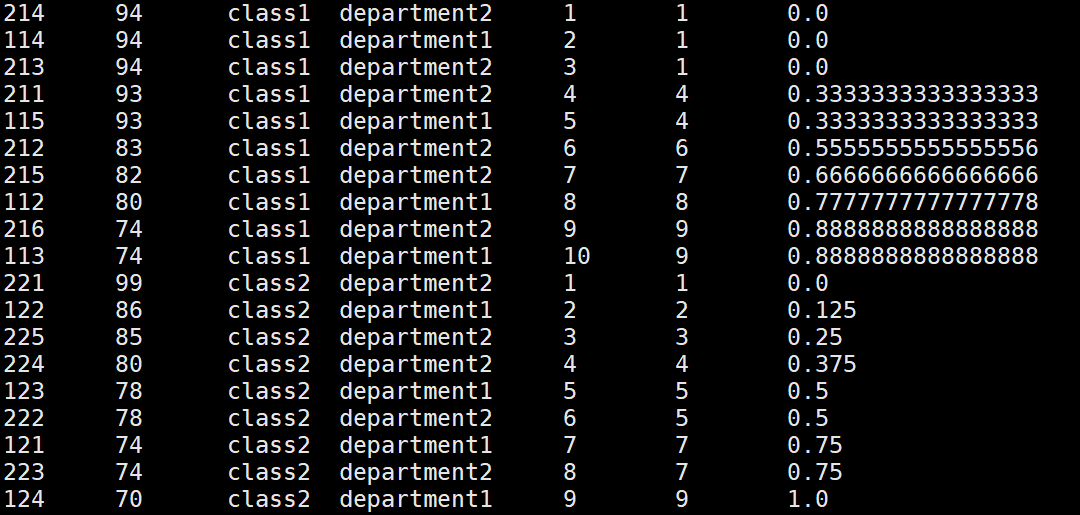
##### percent_rank:(rank的結果-1)/(磁區內資料的個數-1)
select *, row_number() over(partition by clazz order by score desc)as s,
> rank() over(partition by clazz order by score desc),
> percent_rank() over(partition by clazz order by score desc)from new_score;
##### cume_dist:計算某個視窗或磁區中某個值的累積分布,
select *, row_number() over(partition by clazz order by score desc)as s,
> rank() over(partition by clazz order by score desc),
> percent_rank() over(partition by clazz order by score desc),
> cume_dist() over(partition by clazz order by score desc) from new_score;
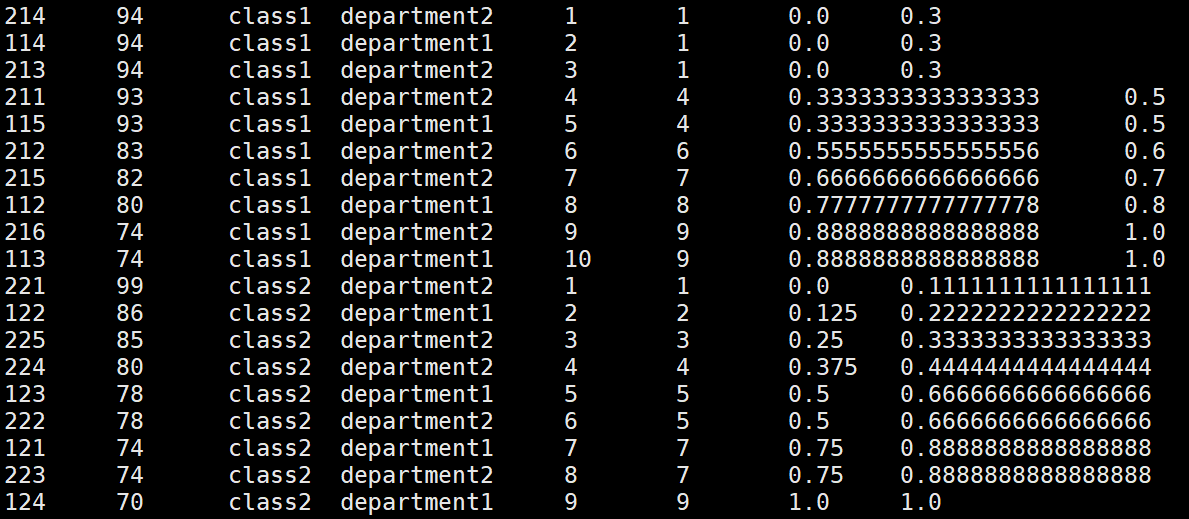
> 假定升序排序,則使用以下公式確定累積分布: 小于等于當前值x的行數 / 視窗或partition磁區內的總行數,其中,x 等于 order by 子句中指定的列的當前行中的值,
##### NTILE(n):對磁區內資料再分成n組,然后打上組號
##### max、min、avg、count、sum:基于每個partition磁區內的資料做對應的計算
5.視窗幀格式
格式1:按照行的記錄取值
ROWS BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
格式2:當前所指定值的范圍取值
RANGE BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
注意:
UNBOUNDED:無界限
CURRENT ROW:當前行
rows格式1:前2行+當前行+后兩行
sum(score) over (partition by clazz order by score desc rows between 2 PRECEDING and 2 FOLLOWING)
rows格式2:前記錄到最末尾的總和
sum(score) over (partition by clazz order by score desc rows between CURRENT ROW and UNBOUNDED FOLLOWING)
range格式1: 如果當前值在80,取值就會落在范圍在80-2=78和80+2=82組件之內的行
max(score) over (partition by clazz order by score desc range between 2 PRECEDING and 2 FOLLOWING)
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/304222.html
標籤:大數據
下一篇:MySQL優化之路